






FinOps personas are the people-shaped cornerstones of your cloud cost playbook — the finance brains, engineering hands, and product visionaries who keep your financial management machine running without grinding the gears.
In addition to job titles, they’re the specific roles that make sure your FinOps processes actually deliver results. Before you map it out, it helps to revisit what FinOps is and how it reshapes responsibilities across engineering, finance, and product.
When the right personas show up at the right time, you move from firefighting spend spikes to steering the ship with confidence.
- So… who should own cost allocation when tags are messy?
- Who gets the final word in commitment planning?
- Whose responsibility is anomaly triage before the CFO sees the variance?
- And how do you make sure rate optimization isn’t happening in isolation from usage optimization?
In this article, we’ll map the key FinOps personas to the processes they own, show you where overlaps create bottlenecks, and give you the clarity you need to make your cloud and FinOps practice hum like it’s meant to.
Do you have the minimum data to make persona decisions?
You’d be surprised how often teams try to assign FinOps personas without the raw ingredients to make it work. The conversations start strong — “Finance owns chargeback, Engineering owns optimization” — and then stall when no one can pull a clean cost view or prove which service is actually bleeding money. Core processes like commitment planning, anomaly triage, and rate optimization crumble without a solid data foundation.
Here’s your persona readiness gut-check:
1️⃣ Billing – AWS CUR, Microsoft Azure billing exports, and GCP Billing export all feeding into one central store. How to confirm: Check last export timestamps; ensure refresh ≤24h.
2️⃣ Context – Required tags (application__c, environment__c, owner_email__c) consistently applied in production. How to confirm: Run a tag compliance report; aim for ≥95% coverage.
3️⃣ Visibility – Amortized vs. blended/unblended views in dashboards; anomaly alerts wired to owners. How to check: Switch between cost views and create a fake surge in spending to check if alarms get to Slack or Jira.
If gaps exist, close them fast:
- No central store? Create S3/Blob/Cloud Storage bucket; wire exports (1–2 days).
- Missing tags? Enforce in CI/CD; retro-tag via API (3–5 days).
- No alerts? Connect Cloudaware anomaly pings to Slack/Jira (same day).
You can check Tagging Quality scores in Cloudaware before you even assign a persona. Switch between Blended and Unblended spend in seconds and find problems while they're still small, which gives you the confidence to assign responsibility and let teams work together.
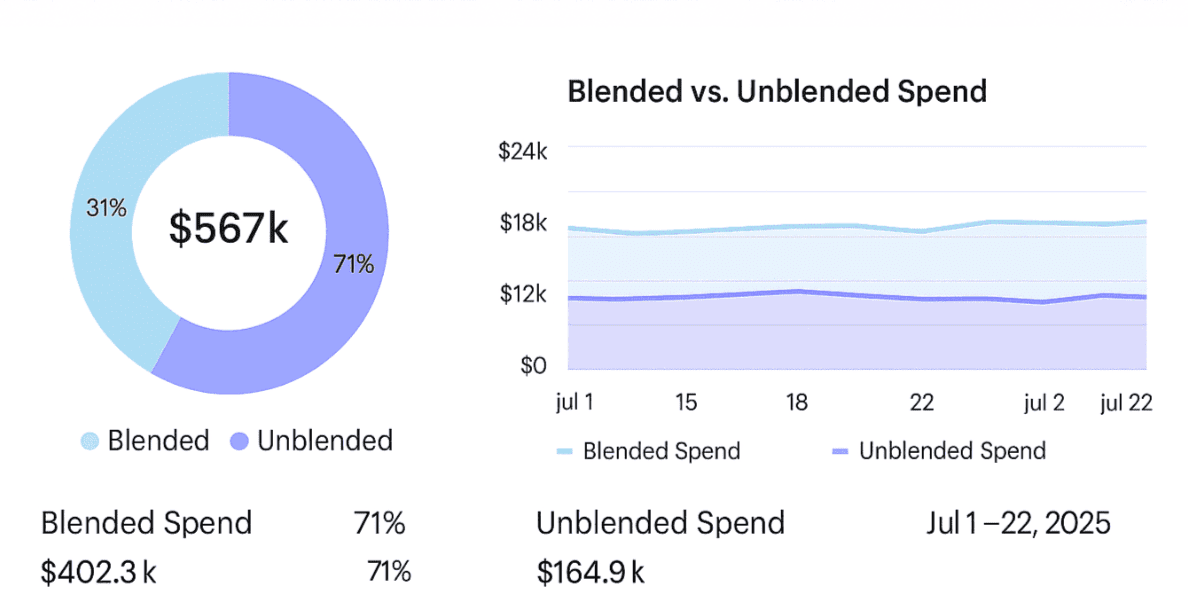
Element of the blended and unblended dashboard in CLoudaware. Schedule a demo to it live.
6 core personas + when to pull in allies
When you cut through job titles, what you’ve really got are core personas — the key roles that actually move the needle on cloud cost decisions. And if you want a FinOps culture that doesn’t melt down at the end of the month, you need each role’s key responsibilities nailed down, plus a clean handoff to the next owner.
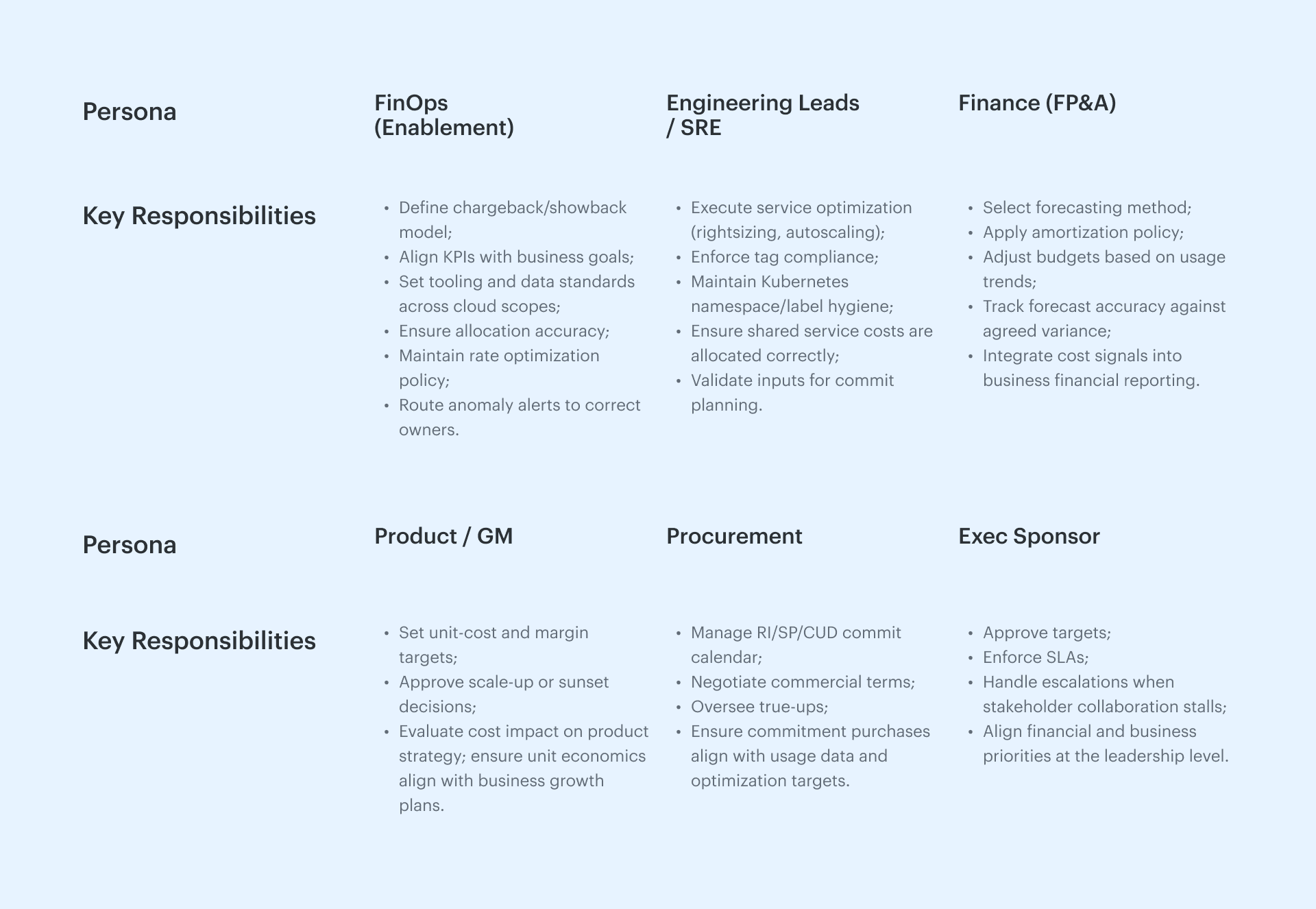
- FinOps (Enablement) – Think of them as the ruleset keepers. Their job? Define the chargeback/showback model, lock down KPI definitions that actually match business goals, and set tooling standards across all cloud scopes. They own allocation accuracy, rate optimization policies, and making sure anomaly alerts land in the right Slack or Jira, not in some abandoned inbox.
- Engineering Leads/SRE – This is where service optimization actually happens. They rightsize workloads, tune autoscaling, enforce tag compliance, and keep Kubernetes namespaces/labels in shape so shared service costs hit the right ledger.
- Finance (FP&A) – They’re the cost translators. Usage patterns come in, budgets and forecasts go out. They pick the forecasting method, apply the amortization policy, and track accuracy so your ±15% target isn’t just a number in a slide deck.
- Product/GM – Here’s where unit economics live. They set unit-cost targets, call the shots on scale or sunset decisions, and guard margins like it’s their own P&L.
- Procurement – The commit tacticians. They run the RI/SP/CUD calendar, negotiate commercial terms, and manage true-ups so they don’t blindside the business.
- Exec Sponsor – The tie-breaker. They approve targets, enforce SLAs, and step in when stakeholder collaboration stalls.
- Allies – These folks drop in by scope. ITAM for asset reconciliation before commit buys, Security when compliance changes configs, Sustainability when carbon goals drive optimization, and Data Platform when shared pipelines mess with allocation.
And once every persona has their own source of truth, the real magic is locking in how those decisions get made. It’s about decision rights, escalation paths, and knowing exactly who’s accountable when cost signals show up.
That’s where a lean, ready-to-use RACI comes in.
The FinOps decision map: RACI, SLAs, and Escalation paths you can use today
Once your core personas are defined, the next leap is locking in decision rights. Not as a corporate formality — but as your safety net when a cost signal demands action. Without it, anomalies get batted around, rate optimizations stall, and allocation disputes waste days. With it, everyone knows their lane, their timing, and their part in keeping cloud financial management sharp.
Think of this RACI-Lite as your quick-start framework for stakeholder collaboration. Each capability ties directly to clear FinOps responsibilities, the right key roles, and the moments that trigger escalation. This way, when the system flags something, the right personas move immediately — no duplicate effort, no finger-pointing.
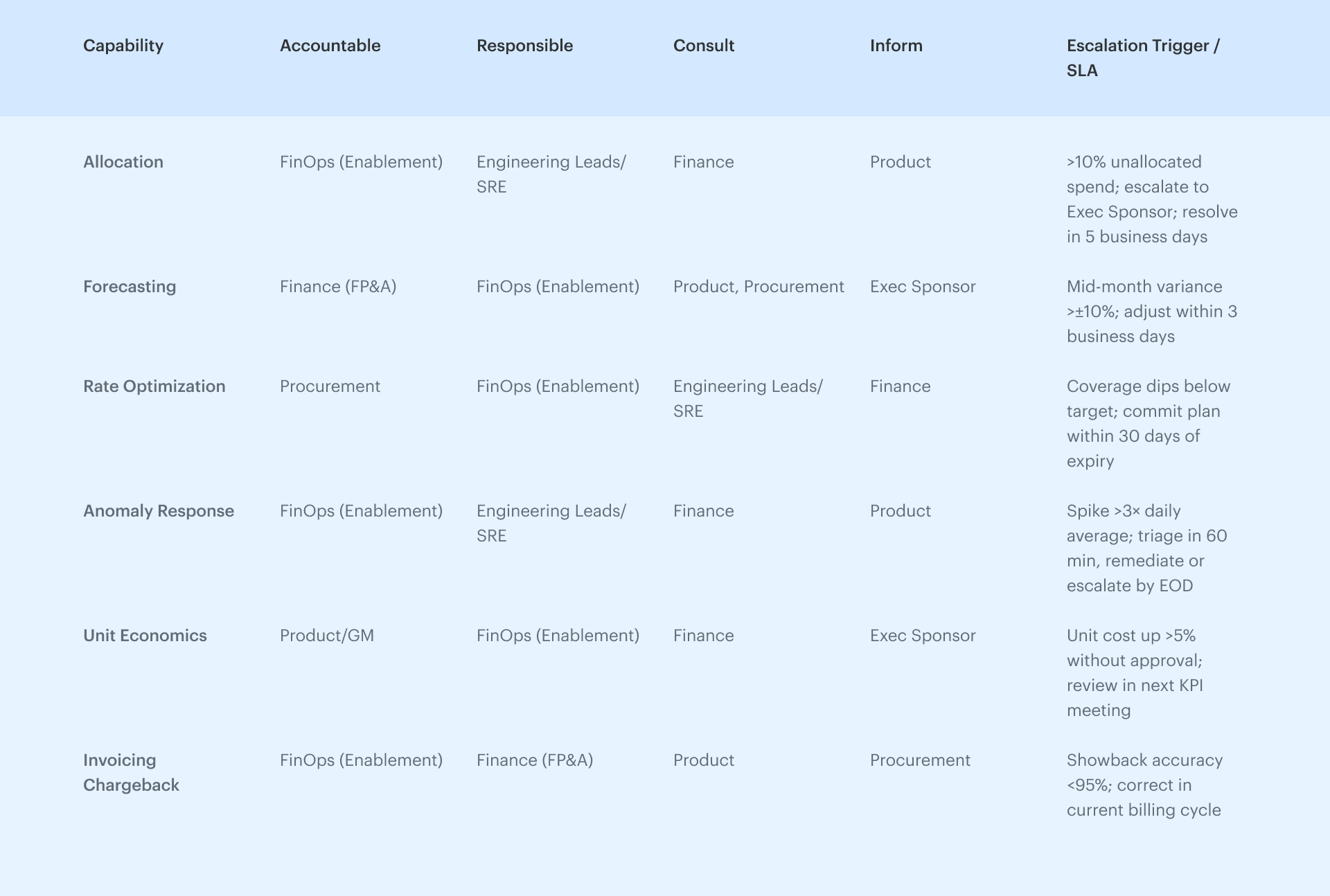
The table works best when each persona can see the right view at the right time — tagging compliance for allocation, utilization patterns for rate optimization, forecast variance for finance. That alignment turns service optimization from a best-effort activity into a predictable business process.
Review this table quarterly. Teams shift, priorities change, and your core decisions need to keep pace with both the business and the signals coming out of your tooling.
IaaS/PaaS, Kubernetes, and Data/AI need different owners & metrics
You’ve nailed decision rights. Now comes the move that saves real money: matching personas to the scope they can actually influence.
Same cloud, different physics.
IaaS/PaaS, Kubernetes, and Data/AI each demand different owners, signals, and thresholds so your FinOps team can turn noise into action without the weekly fire drill.
Allocation, utilization, anomaly detection, and rate optimization behave differently across these stacks. When ownership doesn’t shift with the terrain, coverage stalls, idle waste creeps up, and forecasts drift.
The fix is a lightweight playbook that names who leads, what “good” looks like, and when to step in — so collaboration stays tight and your financial management doesn’t chase its tail.
IaaS / PaaS
Steady fleets belong under commitments; variable fleets live on schedules and spot. That split alone unlocks cleaner coverage and makes rightsizing less political.
What good looks like
- Commitment coverage sits in the 60–85% band for steady workloads; commitment utilization holds at ≥90%.
- Idle waste trends down sprint over sprint; storage TTLs are actually adopted in production.
Start by normalizing to vCPU/RAM per region and instance family. Track pre-expiry 30 days out, use exchange windows for convertible RIs, and keep a small buffer for seasonality. In sprints, work CPU, then memory, then disk — measured by realized savings, not tickets closed.
On the data layer, enforce lifecycle policies (IA/Archive), snapshot retention by tier, and automated cleanup of unattached volumes.
When to step in: If coverage drops below target for two consecutive weeks or idle waste exceeds 5% of monthly cost, ping Engineering to implement a rightsizing/scheduling set within the next sprint and re-check trendlines after deployment.
Kubernetes (cloud compute)
K8s spends money where labels point. If labels are sloppy, your showback is guesswork and commitment planning misses.
What good looks like
- Namespace/workload costs attribute cleanly to teams and environments.
- Request/limit efficiency lands at ≥80%; node groups fit RI/SP families with minimal idle capacity.
Enforce a label taxonomy (team, app, env) with admission policies; block merges on missing keys. Shape node groups by pricing model — on-demand, spot, committed — and use taints/tolerations to pin latency-sensitive pods. Tune HPA/VPA, watch CPU throttling and OOM kills, and consolidate under-utilized nodes to reduce fragmentation.
Keep an eye on bin-packing efficiency, pending pods, and scale-up latency to catch early warning signs.
When to step in: Escalate if request/limit drift grows by >10% week-over-week or idle nodes remain >1 per cluster for 24 hours. Before scaling any node group that would fall outside commitment families, coordinate with FinOps to keep coverage intact.
Data / AI
(Databricks, Snowflake, Bedrock, OpenAI — billed through your cloud provider)
Here, unit economics rule. Define the unit, guard the unit, and let everything else line up behind it.
What good looks like
- Unit metrics (cost per job, query, or token) are defined, tracked, and reviewed.
- Warehouses/runtimes are sized to demand with autosuspend set in minutes; quotas and concurrency limits prevent runaway spend.
For Databricks, choose job vs. all-purpose clusters intentionally, cap node families, standardize runtime versions, and evaluate Photon where it makes sense. Tag jobs with project/account codes and aggregate infra + DBU to the unit metric you publish.
In Snowflake, right-size warehouses, set multi-cluster rules, tag queries, govern credits, and pick materialization strategies that balance runtime and spend. For LLMs, set token ceilings per workspace, allowlist models by use case, tune retry/streaming policies, and track cache hit rates to cut repeat tokens.
When to step in: If your unit metric exceeds target by >10% for two cycles or quota saturation breaches your SLO, trigger a sizing and routing review with Product and Finance before the next release window.
Scope sets the stage. Owners act. Now we measure.
With personas aligned per scope, turn FinOps decisions into numbers the business can trust: coverage, utilization, forecast variance, idle waste, unit cost.
This makes your financial management cadence tight and your collaboration repeatable — across core service optimization work and beyond.
Make it measurable: KPI targets by persona (with realistic bands)
We’ve set scope and owners. Now we turn intent into outcomes. The move: give each KPI a tight definition, a clear trigger, a small action, and simple proof so the FinOps rhythm feels like muscle memory — not meeting theater. Keep it light here; if anyone wants the deep math, point them to the full breakdown: 27 FinOps KPIs to Get the Most from Your Cloud Spend
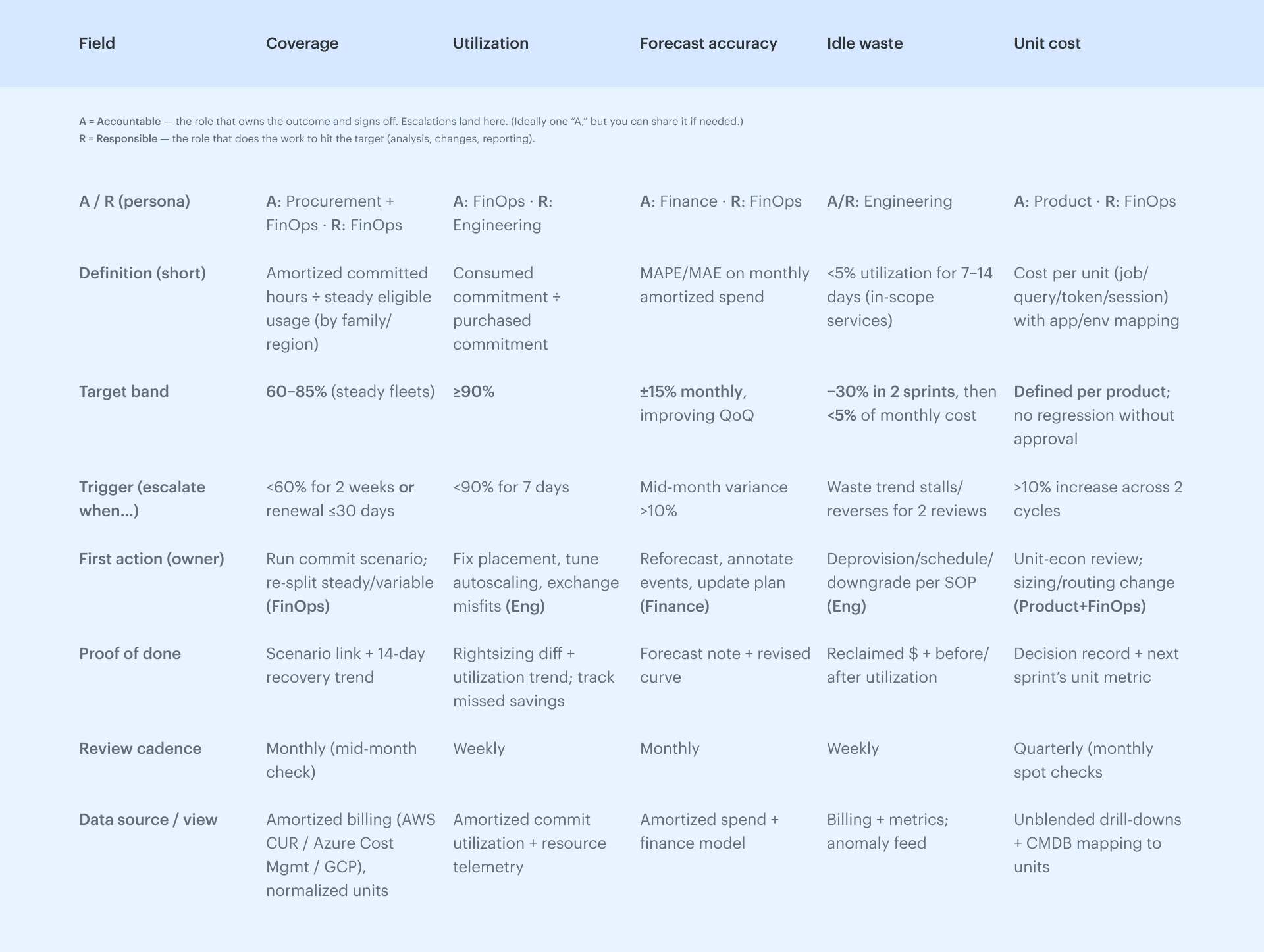
Coverage — Procurement + FinOps
We measure coverage on amortized data by instance family and region over the last 30 days. The band for steady fleets is 60–85%.
- Trigger → dips below 60% for two weeks or a big renewal window is 30 days out.
- Action → run a commitment planning scenario, re-split steady vs. variable, publish a buy/hold call.
- Proof → scenario link + 14-day trend showing recovery.
Side-note: keep this tied to allocation policy and showback/chargeback, so savings actually reach the business.
Utilization — Engineering
Target ≥90% of purchased commits; define as consumed commitments ÷ purchased commitments.
- Trigger → utilization sags below target for a week.
- Action → fix placement (family/region), adjust autoscaling thresholds, or exchange misfit commits.
- Proof → rightsizing diff + utilization trend; track “missed savings” alongside utilization so we don’t “win” by under-buying.
This is day-to-day service optimization paired with the rightsizing workflow.
Forecast accuracy — Finance
Aim for ±15% monthly, improving QoQ; we use a single method (MAPE or MAE), plus a standing variance review.
- Trigger → mid-month variance exceeds 10%.
- Action → re-forecast on amortized data, annotate one-off events (launches, migrations), update the plan.
- Proof → forecast note + revised curve; roll the learning into next month’s management cadence.
Idle waste — Engineering
Definition is explicit: 7–14 days under 5% utilization, in-scope services listed.
Targets: -30% in the first two sprints, then <5% of monthly spend steady-state.
- Trigger → trend stalls or reverses for two reviews.
- Action → deprovision, schedule, or downgrade; close the loop via the anomaly response and deprovisioning SOP.
- Proof → reclaimed dollars and before/after utilization.
Unit cost — Product + FinOps
Unit metric is defined per product (what’s in: infra, platform, data egress). No regressions without approval recorded in the change advisory checkpoint.
- Trigger → >10% increase across two cycles.
- Action → unit economics review with Product, Finance, and FinOps: sizing, routing, or architecture changes with an owner and a date.
- Proof → decision record + next sprint’s unit metric trend.
Measurement hygiene that saves hours of Slack debate. Amortized for coverage/utilization; unblended for drill-downs. Normalize to vCPU/RAM across cloud providers. Exclude refunds/credits unless you’re closing the month. Log exceptions with a one-liner: owner, reason, next review.
Anti-gaming guardrails (so the number stays honest). No committing burst pools just to lift coverage. Don’t pause buys to look efficient; show missed savings. Forecasts must annotate demand shocks. Unit-cost volume bumps need shipped value.
Cadence and calibration. Weekly for waste/rightsizing, monthly for coverage/forecast, quarterly for unit economics. Bands are seasonal — tighten when stable, loosen when the platform shifts. That’s how personas stay aligned, collaboration stays quick, and financial signals stay clean for FinOps practitioners running at core scale and cost pressure.
The operating rhythm that prevents “end-of-month panic”
We’ve set owners. We’ve set KPI bands. Now we give the work a beat. In the cloud, rhythm keeps a single cost signal from freezing three teams. Short cycles. Clear SLAs. Clean handoffs. That’s how your financial management stays calm when spend moves.
- Weekly Eng–FinOps. Fifteen minutes. Anomaly feed. K8s efficiency snapshot. Rightsizing backlog. Anything noisy gets an owner and a timestamp. Anomaly response opens a Jira within 24 hours — rollback path included. Tag gaps slide into the rightsizing workflow. Autoscaling thresholds and node group plans get a fast check so fixes land in the next sprint. Simple. Visible. Done.
- Biweekly Optimization. Every other week, we clear the runway. Rightsizing burn-down. Storage TTL and scheduling adoption. Reclaimed spend review. The bar: ≥70% of optimization tasks completed, with change notes tied to impact. Expectations meet delivery. Engineering shows exactly what shipped. Everyone sees the lift.
- Monthly Commit Planning. Five business days before renewal, the room is Finance, Procurement, and Engineering. We walk coverage/utilization, the forecasting update, and the scenario call by family/region (including AWS). One more pass over cloud cost allocation rules so realized savings hit chargeback cleanly. The reporting pack captures what changed — not just totals.
- Quarterly Product/Exec. Unit economics and KPI reset. Product brings demand signals. Finance validates the envelope. FinOps maps target bands and the review cadence. Any structural shifts — new region, new architecture — get a short change-advisory note so the next quarter starts grounded.
Two glue moves keep this pulse steady. First, a tiny “owner + next review date” tag on each metric so FinOps personas don’t lose the thread. Second, policy checks that enforce compliance on required tags and schedule rules. We also keep a thin sustainability line item — storage class adoption and idle runtime policy — so environmental guardrails ride with the same process.
One more nudge for execution hygiene: schedule report subscriptions to the right people and auto-create Jira tickets from alerts. No extra clicks. No stalled costs. The drumbeat holds, and the same playbook you designed actually lands in production.
Dashboards that each persona actually uses (widgets you can replicate)
We’ve got the cadence down. Now comes the part your team opens first thing — views that turn signals into decisions. Build them once in Cloudaware, wire the filters, and reuse them across reviews without rebuilding the wheel.
In the cloud, that’s how your FinOps rhythm stays fast when a new cost spike shows up and your financial management narrative needs to hold.
Engineering — “Can we fix it this sprint?”
Their home base is a simple stack: Idle/Underutilized, RI/SP Fit by Family, K8s efficiency, and DB/Storage TTL hits.
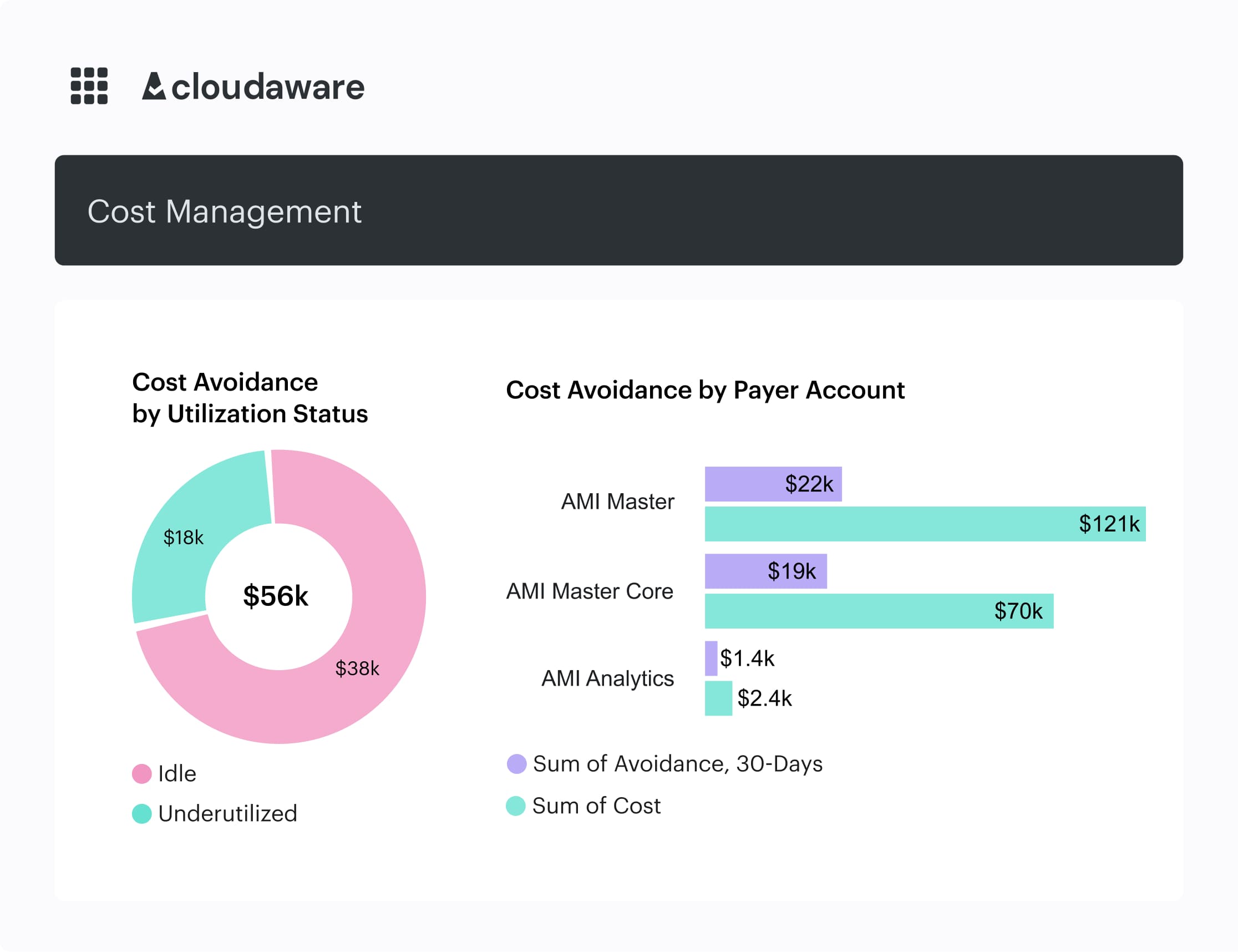
Idle resources dashboard in Cloudaware. Schedule a demo to it live.
From there, they run the rightsizing workflow, check autoscaling policy thresholds, validate tag/label hygiene, and push storage lifecycle adoption.
For Engineering, responsibilities include proposing concrete changes with an owner and date — so every noisy widget becomes an actionable diff.
Finance — “Does the story reconcile?”
They live in the Amortized trend and flip the blended vs. unblended toggle to sanity-check rates before a forecasting and variance review.
Element of the blended and unblended dashboard in Cloudaware. Schedule a demo to it live.
Two more tiles close the loop: showback accuracy % and a compact variance drivers view.
That’s what feeds chargeback, accruals, and close notes without Slack archaeology.
Product — “Are unit economics on track?”
One panel tells the truth: unit metric per session/API/feature keyed by application__c and environment__c, alongside margin by plan. When the unit line drifts, they open an unit economics review and, if needed, record an approval in the change advisory checkpoint before any regression ships.
Exec — “Are we within the guardrails?”
A single rollup — coverage, utilization, savings realized, forecast accuracy — plus a top risks list.
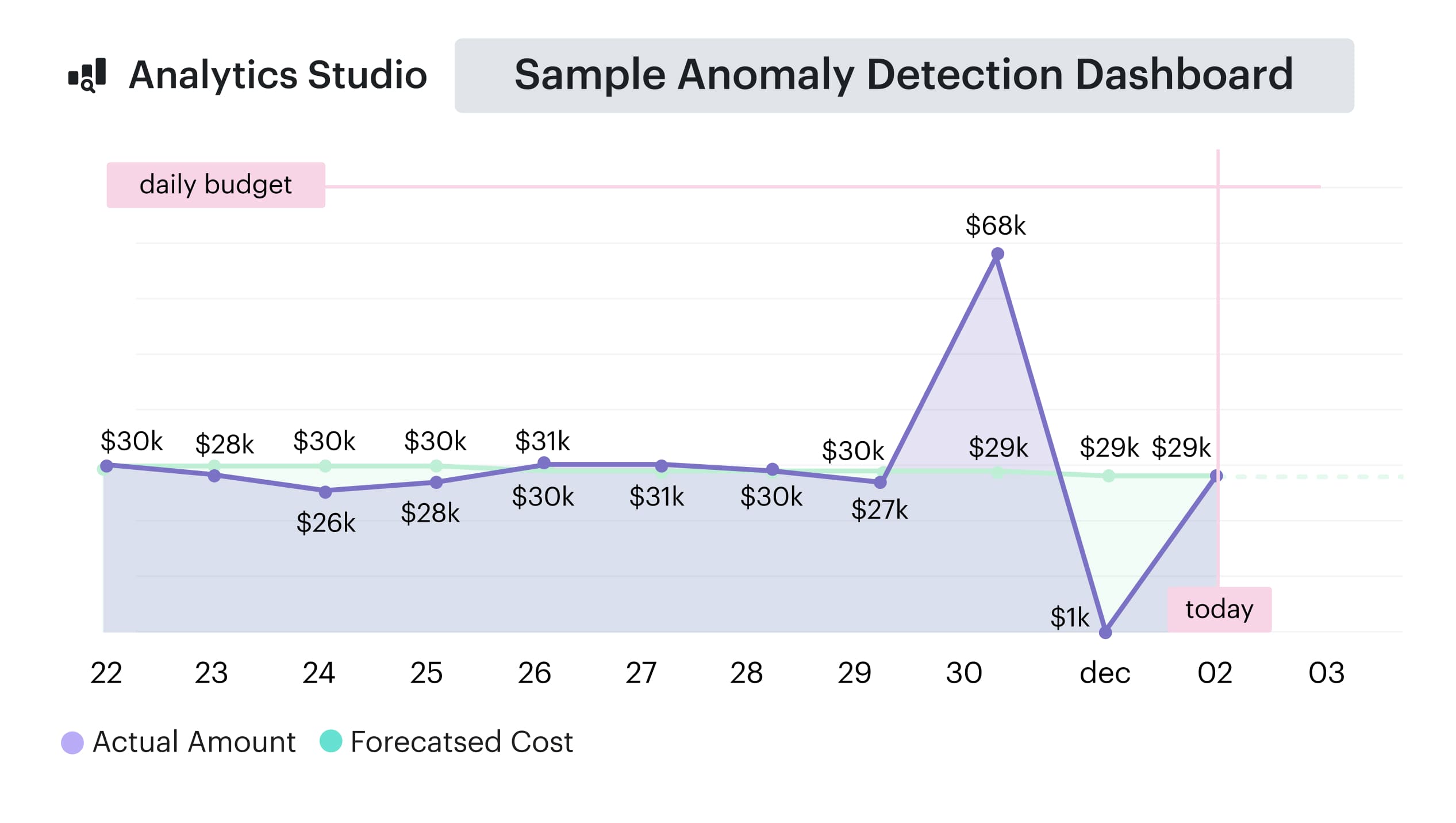
Cost forecast element in Cloudaware. Schedule a demo to it live.
This drives the quarterly target reset and the short risk register that ties back to actions already in flight.
You’ll notice the seams are clean: Engineering’s diffs feed Finance’s variance notes; Product’s unit decisions reflect in Exec’s rollup. That’s responsibilities intersecting by design — each widget supports a specific process, and every process leaves a trail your auditors and reviewers can follow.
Handoffs that don’t break: data contracts and approval gates
We’ve got the cadence; now we make the passes stick. After a few cycles, the choke points are obvious — changes cross team lines and slow down. The fix is small, deliberate agreements your FinOps personas can live with: minimum inputs, fast approvals, and traceable outcomes across the cloud, so the next step is automatic.
Tiny, explicit promises keep management flow tight: the pipeline knows what to check, the board knows what to approve, and owners know when to act.
Three gates, three outcomes — no ceremony, just momentum.
- Pre-deploy cost check (CI/CD gate). Before anything ships to prod, the pipeline validates three inputs: required tags (
application__c,environment__c,owner_email__c), a capacity plan (expected footprint, autoscaling, on/off schedule), and a rollback path (who/when/how). The change record links to chargeback ownership so allocation and reporting line up on day one. That single pass lets FinOps trace impact without chasing context later. - Commit purchase gate (RI/SP/CUD board). When a renewal window opens, the board asks for pinning proof (workload stability by family/region), the coverage target, and a scenario table that shows buy/hold outcomes. Dual sign-off (Engineering + Finance) lands the decision with an effective date and recheck. Forecast notes attach here so the financial narrative and commitment plan never drift.
- Anomaly SOP (detect → decide → act). Signals route to an owner in 15 minutes, triage in 60, and by end of day you either remediate (rightsizing, schedule, policy) or escalate with an RFO and next step. Each action binds to a ticket so the improvement shows up in the next review without rework. Clear times, clear owners, clear finish.
Lock these gates and your cloud financial posture stays predictable, cloud costs bend the right way, and every stakeholder can follow the thread from signal to decision to result — a small system that scales, and a quiet marker of success for your whole cost program.
Anti-patterns you’ll hit by q2 — and the fast fix
By quarter two, the gremlins show up in the cloud and slow down decisions you thought were nailed. Keep FinOps close to delivery and these patterns won’t stick.
1️⃣ “Cost cops outside squads.” Reviews land late, tickets bounce, savings stall. Embed cost work in sprint rituals and keep a living rightsizing backlog that’s reviewed with standups. A rotating chair from the FinOps team keeps time and assigns owners in the room.
2️⃣ “Tagging campaigns with no teeth.” Great emails, zero behavior change. Block merges on missing application__c, environment__c, owner_email__c and publish a retro-tag play for existing fleets. Every missing key hides real cost and breaks allocation.
3️⃣ “Commits bought on last quarter’s graph.” Renewals get rubber-stamped and coverage misses by family or region. Tie the commit calendar to roadmap milestones and require dual sign-off from Engineering and Finance with a scenario table attached. That keeps your financial narrative steady at renewal.
4️⃣ “Monthly report theater.” Pretty PDFs, no owners, no change. Swap to weekly action SLAs and name a dashboard steward who prunes stale cards and assigns next steps. That makes management cadence real, not ceremonial.
5️⃣ “K8s showback without labels.” Mystery spend, angry teams. Publish namespace/label standards, enforce via admission policy, and audit request/limit hygiene so showback mirrors reality. This is where a FinOps practitioner earns trust by fixing taxonomy, not just slides.
Do these five and the run stays smooth. A single FinOps persona can shepherd the loop without heroics when the inputs, owners, and gates are obvious. The playbook scales because FinOps practitioners keep the habits light and the feedback tight.
30/60/90 day rollout: from “good intentions” to operational personas
We’ve cleaned up the anti-patterns and tightened the handoffs; now we lock it in with a simple rollout you can actually run. In the cloud, momentum beats ceremony, so we’ll stack small wins until the engine hums.
Day 1–30 — Stand up the signal
Connect billing exports (AWS CUR, Azure Cost Management, GCP Billing) into one store and publish two truth-tellers: Tagging Quality and Waste. Kick off a weekly Eng–FinOps pack where three things happen fast: the anomaly response queue gets owners, the rightsizing workflow gains a living backlog, and allocation gaps from the tag report get routed to teams with clear due dates.
Add a lightweight variance review note so everyone sees what changed week over week.
Day 31–60 — Turn signal into plans
Run your first commitment planning session using the utilization watchlist and pre-expiry alerts; require a scenario table and dual sign-off from Engineering and Finance. Tune autoscaling policy, land the first rightsizing set, and verify reclaimed spend shows up in showback.
You now see cost movement within days, not weeks, and the roadmap aligns to the commit calendar without surprise escalations.
Day 61–90 — Make it leadership-proof
Add the Exec KPI Rollup so coverage, utilization, forecast accuracy, idle waste, and unit metrics are visible on one page. Enforce the pre-deploy cost check in CI/CD (required tags, capacity plan, rollback path) so allocations and policies hold at the gate.
Sit with Product for a unit economics review, close the loop on decisions, and publish owner + next review on each KPI. The quarterly readout ties into the financial story leadership already tracks, and the cadence becomes part of change management instead of a side project.
By day 90, you’ve got stable reviews, clear owners, and decisions landing where the work lives.
How Cloudaware FinOps optimizes your multi-cloud infrastructure
Cloudaware ingests AWS CUR, Azure Cost Management exports, Alibaba, Oracle, and GCP Billing data, enriches it with CMDB context (application__c, environment__c, owner_email__c), and routes the right view to the right owner.
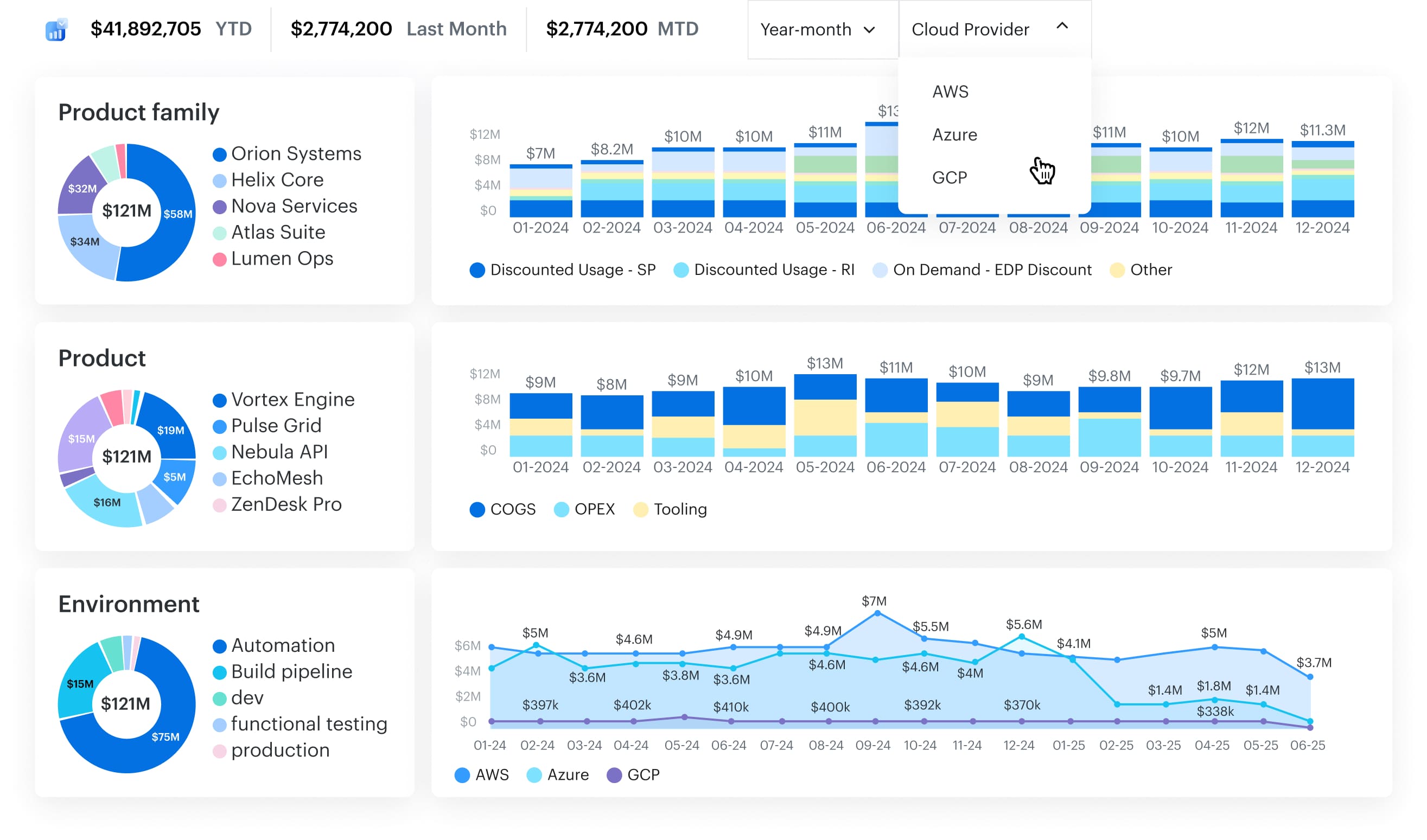
FinOps managers use it for commitment planning, forecasting, showback/chargeback, anomaly response, and governance. Engineering leads use it for rightsizing, autoscaling reviews, and tag compliance. Finance uses it for amortized vs. blended/unblended views and variance reviews. Product leaders use it to watch unit-economics trends tied to services.
Cloudaware gives you one pane of glass for spend + inventory + ownership. It turns raw billing lines into decisions: who acts, what changes, and where savings land. Dashboards are role-tuned, reports are schedule-ready, alerts open tickets, and every change ties back to the CI or service that owns it.
FinOps features that map to your process
- Commitment Planning & Tracking. Coverage and utilization by family/region; renewal reminders; scenario tables you can publish with buy/hold calls.
- Forecasting & Variance Review. Amortized trends, blended vs. unblended toggles, variance drivers; monthly and mid-month checks.
- Anomaly Detection & Routing. Day-over-day spikes, owner fields, and Slack/Jira delivery with timestamps; triage/decision SLA tracking.
- Waste & Rightsizing. Idle/underutilized views, storage TTL adoption, schedule candidates; rightsizing backlog you can burn down in sprints.
- Showback/Chargeback. Allocation using tags + CMDB fields; policy exceptions logged and aged; export-ready for finance close.
- Agentless Inventory + Normalization. Cloud assets roll into a single CMDB with app/team/env classification you can rely on.
- Tagging Quality. Coverage scoring for
application__c,environment__c,owner_email__c; non-compliant resources and aging exceptions surfaced.