






Cloud cost optimization usually becomes urgent only after something breaks. Spend jumps, forecasts miss, and suddenly FinOps is expected to explain numbers that engineering never actively managed.
This playbook focuses on cloud cost optimization strategies that actually hold up in real environments. First, you stabilize cloud spend so it becomes predictable. Then you optimize infrastructure and usage without impacting performance. Finally, you put guardrails in place so savings do not disappear over time.
What you will learn in this piece:
- Which cloud cost optimization strategies matter most at each stage
- How to prioritize fast savings versus structural improvements
- Where teams commonly lose savings after the first quarter
- How to apply these strategies across AWS, Azure, and GCP
- How governance and tooling fit without slowing teams down
This guide is written for FinOps practitioners, platform teams, and cloud leaders who need repeatable cost control, not one-off reductions.
How cloud cost optimization strategies evolved beyond cost cutting
If you’ve been in FinOps for more than a minute, you’ve seen this shift firsthand. Cloud cost optimization did not start as a discipline. It started as cleanup. Someone looked at the bill, found a few obvious problems, fixed them, and hoped the numbers would calm down.
That still happens. It just does not scale anymore.
Modern cloud environments move too fast for optimization to be a once-in-a-while exercise. Usage changes daily, architectures evolve constantly, and costs show up in places that never existed when most “cloud cost optimization best practices” were written. That is why optimization strategies had to evolve from trimming spend to managing how cloud usage behaves over time.
From reducing cloud bills to managing cloud economics
Early on, optimization was about deleting things. Idle instances, unused volumes, forgotten snapshots. You could usually point to a handful of resources and say, “That is the problem.”
Today, the problem is rarely that simple. Costs grow because systems scale automatically, services talk to each other more than expected, and teams make reasonable engineering decisions that have invisible cost side effects. You can rightsize everything and still watch spend climb.
At that point, optimization stops being about the bill itself. It becomes about cloud economics: how architecture, scaling behavior, and usage patterns translate into spend, and whether that spend is intentional.
Why cloud cost optimization fails without ownership and context
This is where most efforts stall: plenty of teams have dashboards, fewer have clarity.
You can usually see where the money went. What is much harder is answering who owns it and why it exists. Without that context, every optimization discussion turns into a debate. FinOps flags an issue, engineering asks what will break, but nobody feels comfortable making the call.
When cloud costs are not clearly tied to workloads and owners, optimization defaults to short-term cleanup. Things get turned off, savings appear, and a month later the same patterns come back. Without ownership and context, cloud cost optimization strategies never really stick.
How FinOps changed expectations for cost optimization strategies
FinOps raised the bar by making this everyone’s problem, not just a monthly review exercise. The goal is no longer to “save money this quarter,” but to keep spend predictable, explainable, and intentional as the environment changes.
That shift changed what good optimization looks like. Strategies are now expected to work continuously, survive team changes, and scale across accounts and cloud providers. If a cost optimization strategy only works once, it is not a strategy. It is a cleanup task.
A phased framework for cloud cost optimization strategies
Teams jump straight into deep optimization while spend is still unstable, ownership is unclear, and yesterday’s decisions are still affecting today’s bill.
Cloud cost optimization framework is described as a lifecycle: Inform, Optimize, and Operate. On paper, that makes sense. In real environments, it rarely unfolds in that order or with clean boundaries.
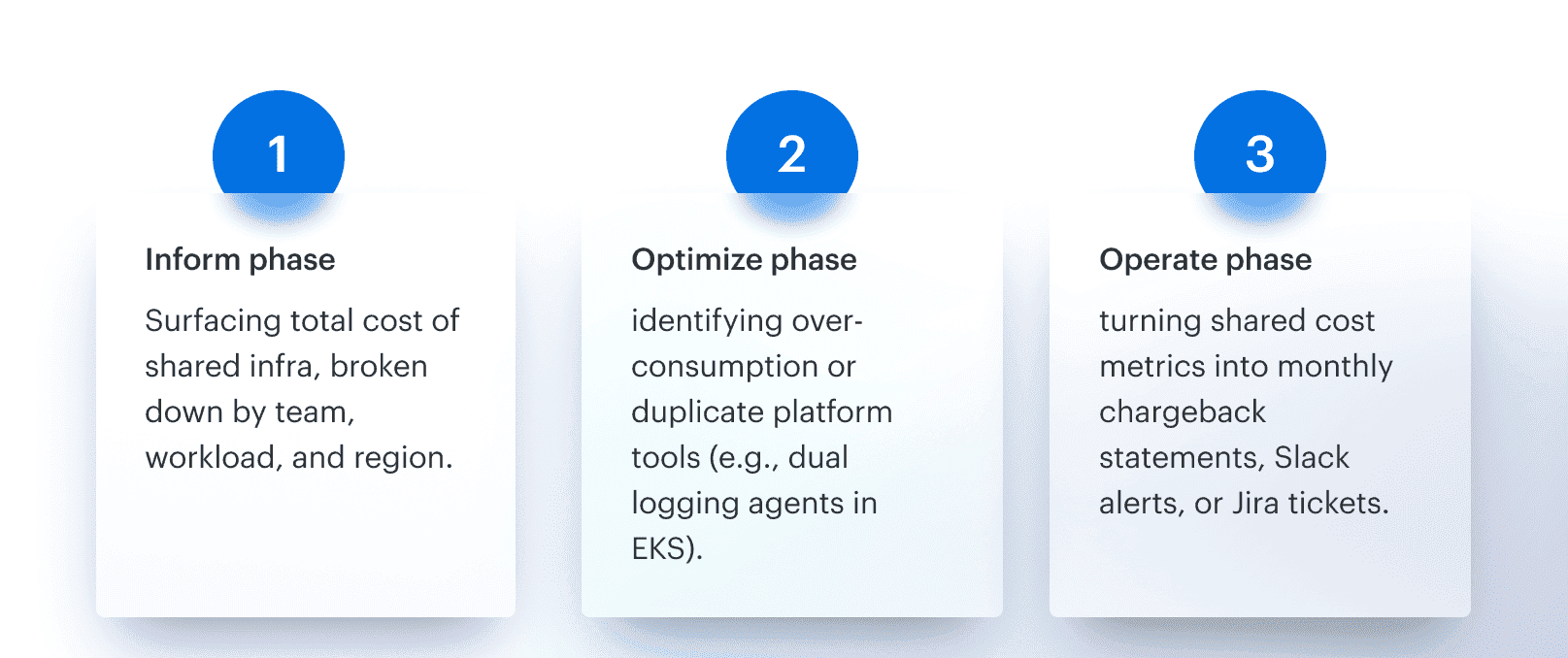
Most FinOps teams experience the lifecycle through urgency. Something breaks, spend spikes, or forecasts miss. The work starts messy and reactive, then slowly becomes more structured as visibility and trust improve. The underlying FinOps principles stay the same, but how they show up day to day looks different.
This playbook uses a practical lens on the FinOps lifecycle. Not to rename it, but to make it easier to operate. The phases below map directly to Inform, Optimize, and Operate, while reflecting how teams actually apply cloud cost optimization strategies in practice.
Triage: stop uncontrolled cloud spend quickly
This phase aligns closely with the early Inform stage of the FinOps lifecycle. At this point, nobody has perfect data. Ownership is incomplete, some reports are trusted, others are not. And the goal here is to stop things from getting worse.
FinOps teams focus on obvious signals: spend that jumps without explanation, resources that are clearly unused, usage patterns that do not match what teams think is running. You fix what you can fix safely and ignore what needs deeper investigation.
Triage is not optimization at all, it’s about restoring enough clarity that better decisions become possible.
Stabilize: establish control before deeper optimization
Stabilization usually happens somewhere between Inform and Operate, and this is where many efforts stall.
In this phase, teams focus on attribution and trust. Costs are mapped to workloads and owners. Allocation improves. Budgets and alerts are tuned so they are actionable, not ignored. Engineering understands which costs they influence and which ones they do not.
Optimize and prevent: turn savings into a repeatable process
This phase aligns with Optimize and Operate, and only once spend is stable does deeper optimization make sense.
Rightsizing, autoscaling refinement, commitment strategies, and architectural improvements can be applied without constantly fighting fires. Just as important, governance and automation ensure that new resources follow the same rules as existing ones.
At this point, cloud cost optimization strategies become part of how the platform operates. Costs get predictable, explainable, and intentional.
Triage best practices to eliminate immediate cloud waste
Here teams usually focus on actions that are easy to explain, easy to roll back, and unlikely to cause incidents. The aim is to remove obvious waste and regain enough visibility to understand what is driving the bill.
Step 1. Identifying idle compute, orphaned storage, and unused services
Idle resources are still one of the fastest ways to reduce unnecessary cloud spend early on. Almost every environment shows the same patterns:
- Unattached disks and volumes left behind after instances were terminated
- Stopped instances that were never cleaned up
- Load balancers with no traffic
- Old snapshots and backups with no clear purpose
- Managed services created for short experiments
Finding these resources is rarely the challenge, but deciding whether they are safe to remove is.
Billing data alone does not provide that answer. You need to know what a resource is connected to, which workload it supports, and who owns it. Without that context, cleanup becomes guesswork.
Cloudaware helps by discovering cloud resources and mapping them into a CMDB with relationships. FinOps teams can see whether a resource is linked to an active service, environment, or application and route decisions to the right owner before acting.
Step 2. Detecting short-lived environments that never shut down
Temporary environments often turn into long-term spend. Dev, test, preview, and sandbox setups are created, then quietly forgotten.
During triage, the focus is on surfacing environments that were meant to be short-lived but are still running. Useful signals include:
- Resource age relative to the environment’s purpose
- Missing or inconsistent ownership tags
- Non-production environments with production-level spend
- Usage patterns that have not changed for months
Cloudaware combines tags, resource metadata, and CMDB relationships to make these environments easier to identify and discuss with the owning teams.
Common early mistakes that increase cloud costs instead of reducing them
Many teams run into trouble during triage. Cleanup actions taken too quickly often lead to rollbacks, emergency fixes, or new work that wipes out the savings.
| Lower-risk triage actions | Higher-risk triage actions |
|---|---|
| Unattached storage | Shared networking resources |
| Long-stopped instances | Aggressive production rightsizing |
| Clearly unused snapshots | Decisions based on short-term metrics |
| Resources with no owners | Cleanup without dependency context |
A safer pattern is to pause before acting and make sure you understand how things are connected. Once you can see what depends on what, decisions get a lot easier.
Cloudaware’s relationship mapping helps here by showing how resources tie back to services and environments. Even without automating anything, that visibility reduces the chances of taking something down that should have been left alone.
Stabilizing cloud spend with governance and visibility
Triage usually calms things down for a few weeks. Stabilization is what stops the same issues from coming back every month under a different name.
This phase is less about saving money and more about removing friction from decision-making. When teams can explain where spend comes from and who is responsible for it, cost conversations stop dragging on and optimization becomes possible without escalation.
Step 1. Fix accountability gaps that tagging alone cannot solve
Tags help, but anyone who has operated a real cloud environment knows they are never as clean as the policy says they should be. They drift, they get copied forward, and they often describe infrastructure details instead of ownership.
What actually matters here is reducing the amount of spend that no one feels responsible for.
In practice, that usually means agreeing on a small set of ownership-oriented tags, checking coverage often enough to catch drift early, treating shared resources as shared instead of forcing them onto a random team, and having a backup way to resolve ownership when tags are missing.
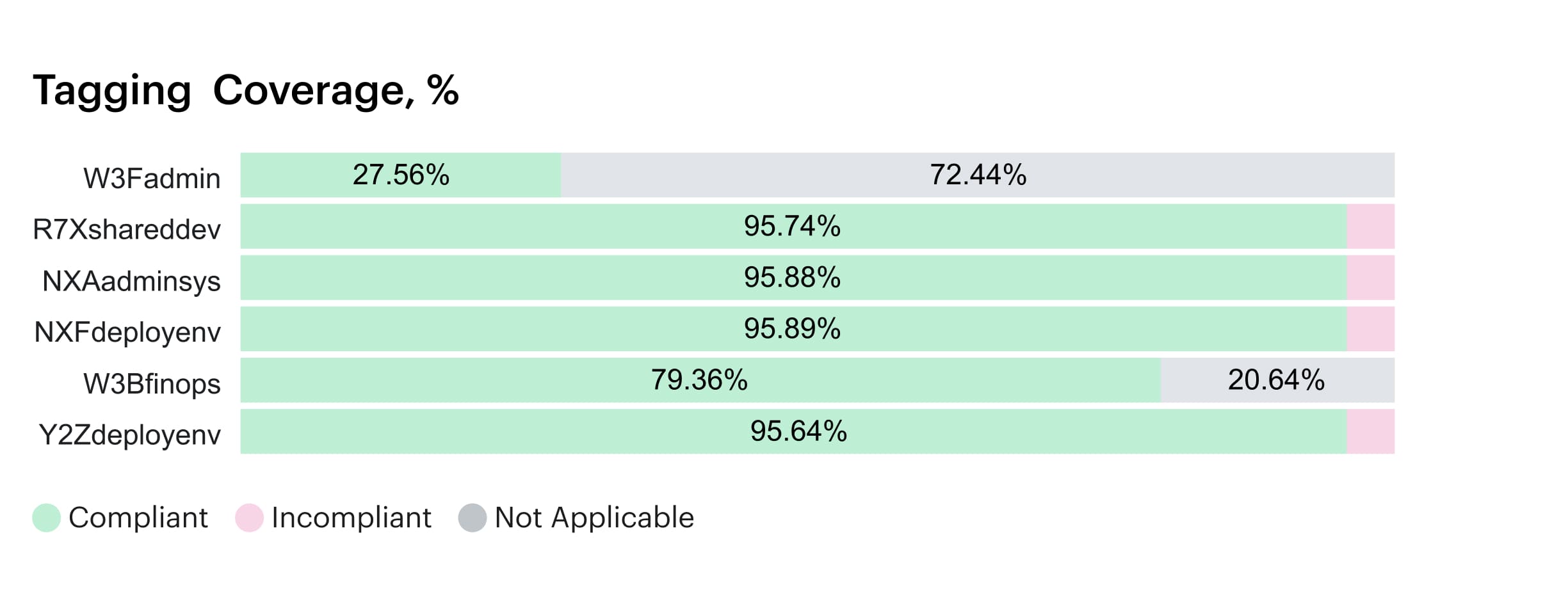
Cloudaware helps by analyzing tag coverage and using CMDB relationships to resolve ownership when tags do not tell the full story. That reduces the amount of manual cleanup FinOps teams do just to make reports usable.
Step 2. Map cloud costs to services and workloads people actually own
Cost reports start working once engineering can look at them and immediately understand what they are seeing.
Teams that get through stabilization usually separate shared infrastructure early, accept that the first version will be imperfect, and revisit the mapping regularly as systems change instead of treating it as a one-time setup.

See how this works in action. Schedule a demo.
Cloudaware supports this by linking billing and usage data to CMDB objects and relationships, so costs can be viewed by service, environment, cluster, or application instead of only by account and SKU.
Step 3. Set budgets and anomaly alerts that people will not ignore
Alerts tend to fail when they are configured before anyone understands what “normal” looks like. Too many rules fire, nobody trusts them, and they quietly get ignored.
Stabilization works better when alerts are limited to the biggest cost drivers, focus on unexpected change rather than absolute spend, and go directly to the team that can act. Thresholds usually need adjustment over time as usage patterns settle.
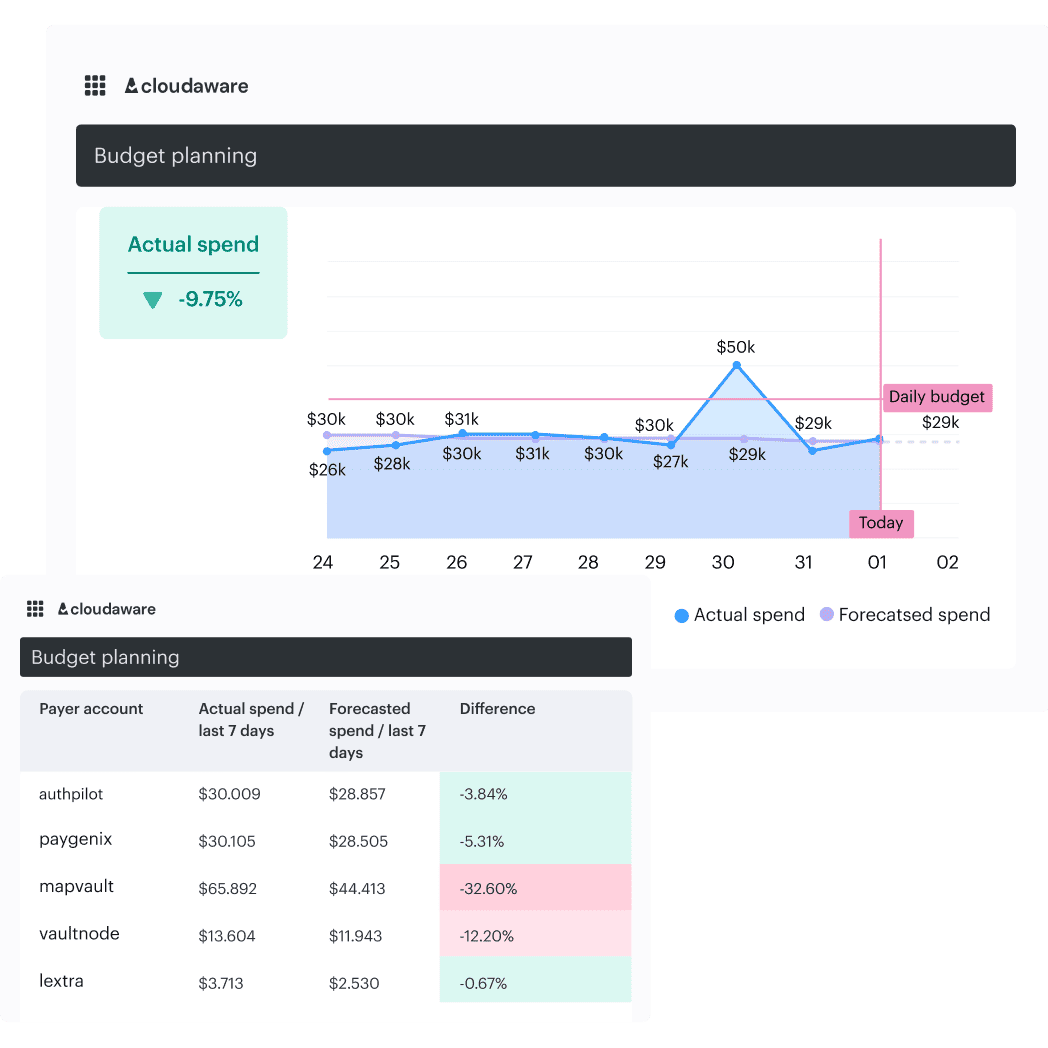
With daily cost data tied to services and owners, Cloudaware makes it easier to see which changes matter and which ones are just normal background movement
Core cloud infrastructure cost optimization strategies
If you are reading this playbook, you already know the basics. Rightsizing can reduce spend. Autoscaling can help. Storage is usually cheaper than compute. None of that is controversial.
What tends to cause problems is timing and scope. The strategies below focus on how infrastructure optimization actually plays out once environments are live, shared, and changing.
Strategy 1: Rightsize only what behaves predictably
Rightsizing works best when workload behavior is stable and well understood. Services with steady usage and clear performance expectations are usually safe candidates.
It starts to break down when resizing decisions are based on short observation windows, when CPU averages are treated as the whole story, or when shared components get touched without reviewing dependencies. In those cases, the change may look reasonable on paper but create side effects elsewhere.
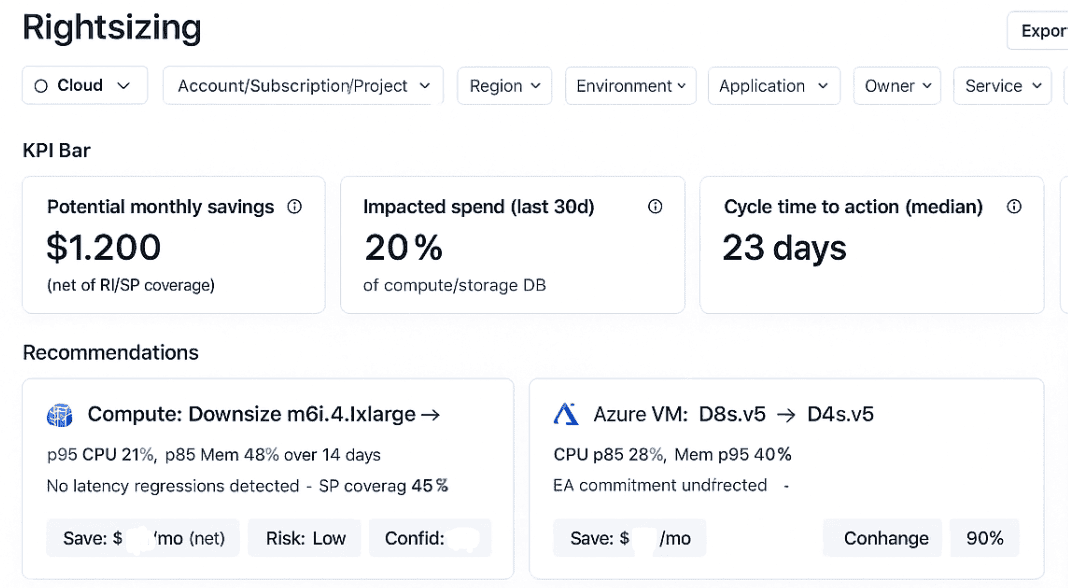
Example of the Cloudaware rightsizing dashboard. Schedule a demo.
In practice, the changes that stick are usually small and deliberate, made with enough time to observe what actually happens and with an easy way back if something goes wrong. When a team struggles to explain why a workload looks oversized, resizing it almost always causes more trouble than it solves.
Read also: 12 FinOps Use Sases + Solutions for Multi-Cloud Spend
Strategy 2: Treat autoscaling as a cost control system, not a safety net
Autoscaling does not reduce costs by default; it shifts control from people to configuration.
It becomes useful only when boundaries exist, such as minimums and maximums that reflect real demand, signals tied to workload behavior instead of raw resource pressure, and regular review of how scaling behaves under real traffic.
In Kubernetes-heavy environments, this matters even more. One service scaling up often triggers others to scale in response, and the resulting cost growth is easy to miss because no single team sees the full chain. Autoscaling settings that have not been revisited since they were created are more likely to amplify spend than control it.
Read also: 10 Battle-Tested FinOps Best Practices from the Pros
Strategy 3: Use storage tiering and lifecycle rules deliberately
Storage optimization feels low risk, which is why teams tend to apply it broadly and then forget about it.
Tiering and lifecycle policies work when data is clearly classified by purpose, access patterns are understood, and retention requirements are explicit. They tend to fail quietly when rules are applied without validating how data is actually used, with the savings appearing first and the problems showing up later during audits, incident response, or recovery.
Teams that manage storage costs well treat lifecycle rules as something to review periodically, not as a one-time cleanup task.
Read also: Cloud Cost Forecasting: Build a Reliable Cloud Budget (Methods, Software, Examples)
Know when optimization creates more risk than value
Not every optimization is worth doing immediately, especially when systems are still changing.
Warning signs usually include decisions driven by averages instead of trends, changes applied across shared infrastructure, or automation introduced before workload behavior is well understood. In those situations, the technical change may be correct in isolation, but the surrounding context is missing.
| Pattern | What usually happens |
|---|---|
| Small changes with review | Savings hold |
| Broad changes based on snapshots | Rollbacks |
| Autoscaling with limits | Predictable spend |
| Autoscaling without limits | Volatility |
Network and data transfer cost optimization strategies
Network costs are where cloud spend starts behaving in ways that feel disconnected from day-to-day changes. Compute and storage usually move because someone resized something or deployed a new service. Network costs often move because systems start talking to each other differently.
That makes them easy to miss and hard to explain after the fact. The strategies below focus on shaping data movement deliberately, instead of reacting once the bill arrives.
Strategy 1: Treat data transfer as an architectural cost driver
Data transfer costs tend to spike without obvious infrastructure changes because they follow behavior, not capacity. A new dependency between services, a shift in request patterns, or a change in where data gets processed can push traffic up while instance counts stay flat.
This usually shows up in a few familiar ways:
- Services calling each other more often than expected
- Data pipelines processing the same data in multiple places
- Workloads moving closer to users while data remains centralized
This strategy works when traffic patterns are reviewed alongside architectural changes. It falls apart when data transfer is treated as a billing detail instead of a signal that system behavior has changed.
Read also: 9 Cloud Cost Management Strategies for 2026
Strategy 2: Minimize cross-zone and cross-region traffic by intent, not accident
Cross-zone and cross-region costs grow fastest when availability decisions are implicit. Services get spread across zones, replication gets enabled by default, and traffic starts taking expensive paths without anyone explicitly choosing them.
Teams that manage these costs usually pause to answer a few basic questions:
- Which services genuinely need cross-zone traffic to meet availability goals
- Which data actually needs to exist in more than one region
- Where traffic originates and where it most often ends
Optimization holds when placement, routing, and replication are intentional. Costs tend to drift when high availability is assumed to require constant cross-region movement instead of clearly defined failover paths.
Read also: FinOps Maturity Model: 7 Expert Moves You Can Steal
Strategy 3: Control egress by understanding who generates it and why
Egress usually grows as cloud environments connect to more external systems. APIs, SaaS platforms, analytics tools, and customer-facing downloads all contribute, often in uneven ways across teams.
Egress optimization becomes manageable once outbound traffic is attributed to real services and owners. At that point, teams can focus on changes that actually move the needle:
- Caching frequently accessed data closer to consumers
- Batching or compressing outbound requests
- Shifting processing to avoid repeated data movement
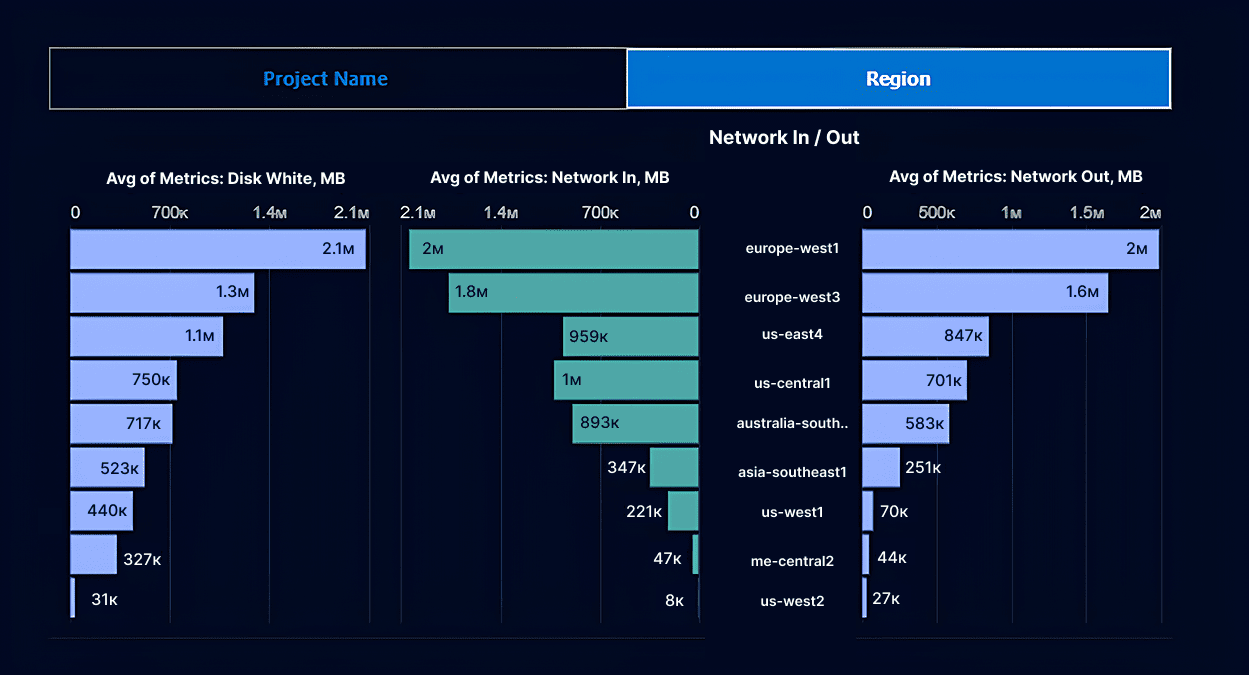
Example of Cloudaware dashboard. Schedule a demo.
Egress is hardest to control when it is treated as a shared tax. Once it is understood as behavior driven by specific services and usage patterns, it becomes something teams can reason about and improve.
Read also: 7 Cloud Cost Management Challenges and How to Fix Them
Commitment-based cloud cost optimization strategies
Commitments are usually the point where cost optimization stops feeling mechanical and starts feeling risky. They can lock in meaningful savings, but they also lock assumptions about how workloads will behave months down the line, long after today’s context has changed.
Most FinOps teams know how Savings Plans, Reserved Instances, and committed use discounts work on paper. What causes trouble is timing, not mechanics, especially when commitments are used to chase savings before usage has settled.
Strategy 1: Use commitments only when usage has settled
Commitments tend to work when they mirror how the platform already behaves, not when they are used to push it in a certain direction.
They usually make sense for things that do not change much over time, such as long-running production services with steady demand, shared platform components that evolve slowly, or baseline capacity that exists regardless of traffic patterns.
They start disappointing when workloads are still being rightsized, architectures are in motion, migrations are underway, or ownership is still being debated. In those cases, the commitment often survives longer than the workload it was meant to cover.
A practical test many teams learn the hard way is this: if no one can clearly explain why a service consumes the capacity it does today, committing to that usage almost always comes too early.
Read also: Cloud Cost Analysis Tools: Features & Pricing Comparison
Strategy 2: Avoid committing before ownership and allocation are solid
Most commitment failures are sequencing problems rather than pricing mistakes.
Pressure often builds when leadership sees projected savings and wants action, even though allocation is incomplete and usage is still shifting. That is usually the moment commitments start creating work instead of removing it.
Signs that it is too early to commit tend to look familiar:
- Large portions of spend without a clear owner
- Services that scale unpredictably or get retired frequently
- Regular effort spent rebalancing usage just to keep commitments utilized
In those situations, commitments reduce flexibility faster than they reduce cost, and teams end up managing unused coverage instead of improving efficiency. They work far better once spend has settled and ownership questions are no longer open.
Read also: 7 Best Cost Allocation Software 2025: Tools, Features & Pricing
Managing commitments across AWS, Azure, and GCP
Once multiple providers are involved, commitments become harder to reason about. Each cloud uses different models, rules, and discount mechanics, which makes copying the same approach everywhere risky.
Teams that avoid surprises usually stop thinking in terms of individual purchases and start thinking in terms of coverage over time. They separate baseline commitments from growth capacity, review utilization regularly, and adjust decisions as usage changes instead of locking everything in upfront.
Cloud cost optimization strategies for enterprises and small businesses
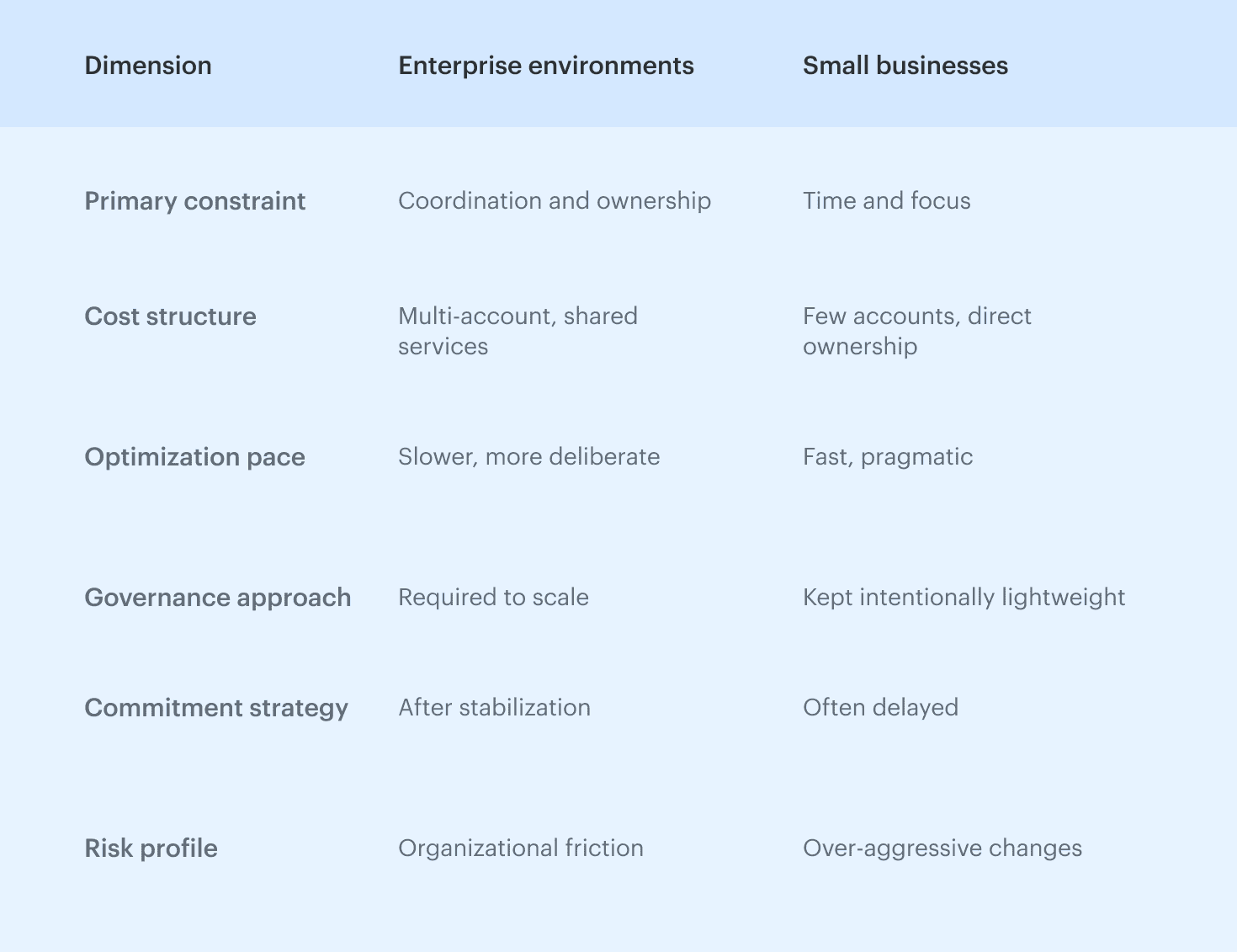
Cloud cost optimization looks very different depending on the size of the organization. The mechanics might be the same, but the constraints are not.
Enterprise FinOps teams usually struggle with scale and coordination. Smaller teams struggle with time and attention. Applying the same strategies to both groups rarely works, even if the tooling is identical.
How cost optimization strategies differ by organization size
The real divider is not cloud maturity, but how much coordination the organization can realistically handle.
Larger organizations trade speed for consistency, aiming to build controls that survive reorganizations, migrations, and new teams. Smaller organizations make the opposite trade-off, prioritizing fast results because the same people handling FinOps are also shipping product and keeping systems running.
Analyst research, including Gartner, consistently points out that cloud cost overruns are more often caused by operating model mismatch than by missing tools.
Analyst research reflects this split. Gartner repeatedly points out that cloud cost overruns are less about tooling gaps and more about operating model mismatch, especially in organizations that try to apply enterprise governance patterns too early, or skip them entirely at scale.
Enterprise challenges: multi-account sprawl and shared services
Enterprise cloud environments rarely fail in obvious ways. Costs usually drift.
As accounts and platforms multiply, ownership becomes harder to trace. Shared services grow because they are useful, not because they were carefully designed. Over time, networking layers, data platforms, security tooling, and core clusters end up supporting many teams without clearly belonging to any one of them.
Optimization slows as dependencies pile up and approval paths lengthen, and whatever savings teams manage to create often disappear after reorganizations or large migrations. The issue is rarely effort. Coordination becomes the limiting factor.
Read also: The Bridge to AI Readiness eGuide for MSPs - Is Your Cloud Foundation AI-Ready?
Small business priorities: fast savings with minimal process overhead
Smaller teams tend to have the opposite experience. Ownership is usually clear, but there is very little time to think about cost work consistently.
Cost optimization competes directly with shipping features and keeping systems running, so teams gravitate toward actions that show results quickly. Cleanup, simple reporting, and delaying commitments often work better than formal governance early on.
The risk is going too far. Turning things off too aggressively or locking into commitments too early can create outages or long-term constraints that end up costing more than the savings.
Cloud cost optimization tools and platforms compared
At some point, every FinOps team runs into the same question: how much of this can we realistically do with native tools, and where does it make sense to add something else.
There is no single right answer. The value of a tool depends less on feature checklists and more on how complex the environment has become.
What to expect from native cloud cost management tools
Teams usually rely on native tools for:
- High-level spend tracking and trend analysis
- Basic budgets and alerts
- Viewing costs by account, project, or subscription
- Validating invoices and billing anomalies
Native tools are necessary, but they stop at billing structure. Operating cost optimization requires ownership and architectural context.
How Cloudaware supports enforceable cloud cost optimization strategies
Cloudaware centralizes cloud billing from AWS, Azure, GCP, Oracle, and Alibaba into a single CMDB-enriched cost model, so every dollar is tied to real configuration items such as services, applications, environments, and owning teams.
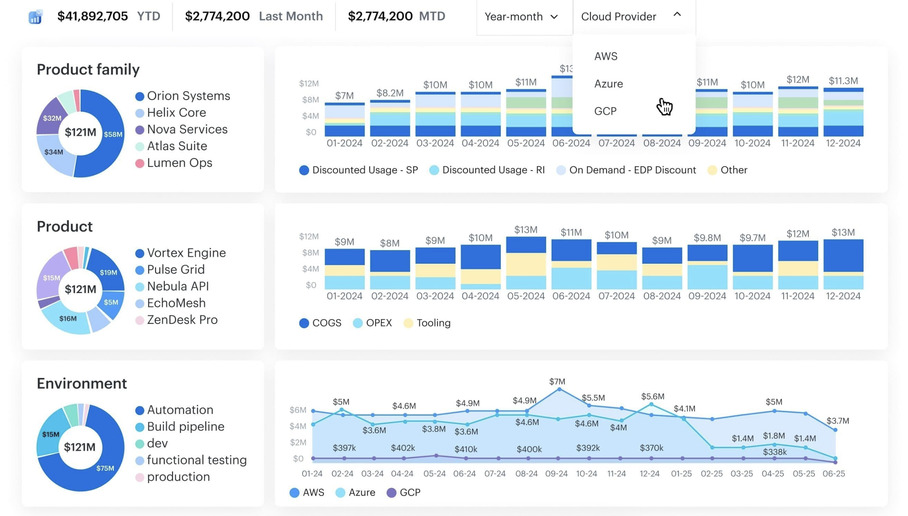
- Ownership resolution beyond tagging: Uses tags where they exist, then falls back to service and application relationships when they don’t, so ownership does not disappear the moment tagging drifts.
- Cost mapped to services and workloads: Costs roll up to services, apps, environments, or clusters, which means teams see spend in terms they actually use, not just accounts or SKUs.
- Shared infrastructure cost handling: Shared platforms like networks and clusters are treated as shared on purpose, instead of being pushed onto one team just to make reports work.
- Dependency and relationship visibility: Shows what depends on what across infrastructure and services, which matters before anyone starts cleaning things up.
- Network and data transfer context: Network and egress costs make sense when you can see where traffic flows in the architecture, not just where the charges landed.