






When you run Kubernetes across multiple accounts and clusters, workload security rarely fails in one obvious place. It fails when a “temporary” exception becomes default, when a registry tag drifts from what CI produced, when a build runner gets more access than production, or when a privileged workload ships because nobody wanted to block the release.
If you keep seeing the same findings come back, spend more time arguing about scan noise than fixing issues, or cannot prove what actually ran in production, this guide is for you.
This piece is written by Cloudaware experts Valentin (Software Developer) and Igor (DevOps Engineer). They operate container platforms in a multi-account environment and own the release path from build through runtime.
Container security in 2026: why the same failures keep repeating
In 2026, service incidents keep recurring because the same shortcuts persist across build, registry, admission, and runtime. A single “temporary” exception, a mutable tag promoted under pressure, or a build that bypasses CI is enough to ship risk at scale across accounts and clusters.
By the time runtime alerts fire, the blast radius is already locked in, so risk becomes noise. In a multi-cloud org, it works when artifact provenance, identity, and policy are enforced as continuous gates and tracked through normal governance workflows, so software promotion stays explainable.
The 3 patterns behind most incidents
Use these as routing rules as the fastest way to decide where platform controls belong and what ownership needs to track:
- Drift means the running state diverged from what CI/admission approved, so fix it at the registry promotion and admission enforcement.
- Privileges mean the workload can do more than intended, so fix it in the defaults and admission policy.
- Secrets mean sensitive values escaped the secret store boundary, so fix it in build and runtime handling.
Threat model for workloads: the layers attackers target
Use this method to answer a practical question: “Where do we put a control so the same incident doesn’t repeat?” These layers are based on common platform guidance. For example, NIST discusses risks and controls across images, registries, orchestration, and runtime components, so this structure works well for organizing prevention work.
Pattern: if ownership is unclear, fixes never land
A finding without an owner becomes backlog noise. Tie ownership to the artifact and the environment boundary so that routing can assign work automatically, and software promotion does not stall on “who owns this?” debates.
Top 8 container security vulnerabilities and what prevents them
We see the same set of issues because container risk does not “live” in one place. The eight container vulnerability cases in this guide are the ones that repeatedly break platform control programs in production.
They are also predictable: each maps to a missing control point and a concrete prevention move you can enforce with your existing scanning tools.
High-impact misconfigurations attackers still exploit
Before we cover vulnerabilities, start with the misconfigurations that blow up the blast radius. If any of those production blockers reach production, your baseline protection is missing at build, registry, or admission, and containment gets harder:
- Privileged mode or extra capabilities
- docker.sock or daemon permission paths
- Root-by-default execution
- Promotion by tag instead of digest
Vulnerability 1: untrusted images and unknown provenance
A scan answers “what’s inside,” not “where did this come from,” so clean container images can still be swapped between CI and production. This shows up through mutable tags, manual pushes, or multiple identities publishing container images into the same registry path, and that turns security into a trust problem rather than a CVE problem.
Container images policy
Most platform teams formalize this as a container image policy: a policy-as-code rule set that defines which images are allowed to run and why.
“Only verified” has to be objective: who built the image, what checks ran, and what decision was recorded. Signing and attestations make provenance enforceable at admission. Treat that gate as security testing with a stored decision record that management can validate later without reconstructing pipeline logs.
Fix: admission rules that block only production-breaking risk
Admission rules should be environment-scoped: strict in production, lighter in dev and stage, otherwise teams will bypass them. Keep the blocker class small and explicit, then run the rest in audit or warn mode until you have stable signals and low false positives.
Treat policy exceptions as first-class objects with an owner and an expiry, and require a recheck before the next promotion.
Vulnerability 2: known vulnerabilities shipped because scanning is noisy
Teams ship known vulnerabilities when known vulnerabilities output becomes a blanket release gate. Severity does not map cleanly to exploitability in your containers, so teams either block too much and drown in exceptions or unblock everything and ignore the signal.
Fix: vulnerability scanning thresholds that don’t kill delivery
Set thresholds by environment and risk: strict blockers in production, data collection in dev and stage.
Keep security actionable by deduping findings into one work item and enforcing exception TTLs. Without that, security turns into debates and bypasses, not remediation. Make the thresholds and exception rules part of normal governance.
Fix: patch cadence for base images and dependencies that actually works
Set a rebuild rhythm for base images and dependency layers, plus “must rebuild” triggers for high-impact updates. That keeps software current without emergency patching, and it is the only scalable way to stay continuous as image patterns fan out across clusters.
Vulnerability 3: privileged containers and dangerous Linux capabilities
When limits are not explicit in Dockerfiles and manifests, platforms drift toward maximum privilege defaults like root execution, extra capabilities, and writable filesystems. This is where container hardening must be enforced as defaults. Otherwise, security becomes runtime cleanup, and management loses a consistent baseline.
Fix: hardening baseline plus an exception process with expiry
Start with a baseline that works by default: non-root, drop capabilities, read-only FS where possible, and no privileged modes.
Allow exceptions only with an owner, justification, and expiry, and revalidate before promotion. That is how you protect production without turning release flow into a negotiation on every release.
Vulnerability 4: exposed Docker daemon or docker.sock access
The Docker Daemon is a control plane for the host. If a workload can reach docker.sock or the daemon API, it can often break out to the node level, build new privileged workloads, or read artifacts and credentials that were never meant to be exposed. This risk is amplified in CI runners and build environments, where “just mount the socket” is a common shortcut.
Fix: lock down daemon access and block socket mounts in production
Block socket mounts and daemon API usage in production via admission rules, then isolate builds so the build path does not have node-admin equivalence. Where daemon access is truly required (legacy), keep it narrow, time-bound, and scoped to dedicated runners.
Vulnerability 5: CI/CD identity and build runners as a production backdoor
CI/CD identity is often the most privileged actor in the system. When a runner is compromised, the attacker does not need to break production directly; they can ship through the pipeline and everything downstream treats it as legitimate.
This vulnerability shows up when runners have broad permissions, long-lived tokens, shared credentials, or the ability to publish artifacts outside a controlled path. If the pipeline can publish anything, the artifact becomes trusted by default.
Container runtime exposure paths and runtime security signals
The common chain is runner compromise → stolen registry creds → artifact swap → legitimate deployment, so test runners like critical infrastructure.
Example: a job prints environment variables, leaks a token, then uses it for registry permissions; treat this as security testing of pipeline behavior, not just the image.
Fix: isolate builds and enforce guardrails at runner and registry level
Isolate runners, use short-lived credentials, and lock publishing to CI-only identities, then reject unverified artifacts at the registry boundary. This is the fastest way to protect the supply chain and gives management a clean enforcement point.
Vulnerability 6: secrets leakage in builds, layers, logs, and env vars
Secrets usually leak as side effects of builds: Dockerfile literals, build args, ENV, pipeline logs, image layers, artifact caches, and repo history. Once a secret lands in any of those places, it gets replicated through promotion and becomes hard to revoke cleanly across containers.
Access to CI logs or a registry can become equivalent to permission to production systems, because the secret is now reachable outside the secret store boundary.
Fix: access controls and secret handling that survive audits
Minimize “places a secret can land”: never bake it into Dockerfiles or images, never print it to logs, prefer short-lived credentials, and block secret patterns from entering build artifacts.
For auditability, tie secret issuance and use to the release decision, so application security controls are provable and consistent with how software is promoted.
Vulnerability 7: weak cluster RBAC and over-permissioned service accounts
In Kubernetes, “default power” often lives in service accounts and namespace roles. Shared accounts and wildcard permissions become the baseline, so incidents expand fast through API usage, secret mounts, and cross-namespace pivots.
In multi cloud setups, RBAC often maps to account identities and external policies, so one mis-scoped binding can leak privileges beyond the cluster boundary. This is a security boundary problem. When permissions exceed workload intent, triage slows, and containment gets messy.
Fix: least-privilege RBAC, scoped service accounts, and namespace boundaries
Scope permissions to the workload, not the team. Use per-service accounts, avoid wildcards, and enforce namespace/env boundaries that match ownership.
Example: fail admission if a service account requests cluster-admin, wildcard verbs/resources, or cross-namespace secret reads. That keeps security enforceable and gives management a clean routing path from finding to the owner.
Vulnerability 8: registry and environment access drift across cloud accounts
The registry is an artifact vault and, in a multi-account org, a shared trust boundary across accounts and clusters. This vulnerability shows up when push and pull permissions drift between environments, inherited roles expand, or temporary cross-account rights become permanent, so production can pull artifacts outside the intended path.
Tag drift is the other failure mode. Mutable tags let bytes change without a manifest change, so the same deployment reference can resolve to different digests over time, and the wrong artifact spreads across containers.
Fix: least-privilege access with environment-scoped policies
Scope permissions by environment: dev can iterate within guardrails, production stays narrow and predictable, and cross-env promotion stays explicit.
Example: only allow the prod deploy identity to pull digests from an approved repo path and block tag-based pulls; this keeps delivery fast while keeping permissions tightly bound.
Vulnerability 9: mutable runtime config and drift (“unknown change”)
Even with a trusted artifact, the runtime state can diverge from what was approved. Manual kubectl changes, emergency patches, or quick reconfigurations that skip review create drift.
Fix: runtime evidence for drift and “unknown change”
Capture what changed, when it changed, who changed it, and which workload, namespace, and environment were affected. Once you can answer those questions, an incident stops being an argument and becomes a traceable sequence you can tie back to a release, a policy decision, and an owner.
Vulnerability 10: weak defaults at runtime
Weak defaults mean workloads run without explicit constraints, so each team invents a baseline, and exceptions accumulate across clusters. Standardize one container runtime baseline, enforce it by default, and treat deviations as approved, time-bound exceptions tied to the change record, so management can reason about risk as software moves.
Fix: baseline that teams can’t silently bypass
Make the baseline enforceable. If a team needs an exception, require an owner, a reason, and an expiry, and validate it at admission so it cannot drift into production by accident.
This keeps security consistent and reduces triage time. It also keeps management focused on a small set of controlled deviations instead of endless one-off configurations.
Container signal checklist: how to tell these vulnerabilities are hurting you
At the end of the day, security testing needs to drive enforcement decisions, and ownership needs a consistent way to route work.
Use this checklist to confirm impact and make decisions:
- Check exceptions and TTL. If exceptions have no expiry, they turn into permanent bypass. Track exception count per environment and block new exceptions without an owner and an end date
- Check tag-based deployments. If production references tags, verify that the same tag resolves to the same digest across environments
- Check the time to triage and routing. If triage is slow, validate that findings route to a single owner by service, namespace, and environment
- Check recurring base findings. If the same base layers trigger findings every sprint, your rebuild cadence is broken, and fixes are not reaching the artifact supply chain
- Check the drift between approved and running. If you cannot answer who changed what in runtime, you have an “unknown change” path that will keep resurfacing
Reporting: trends, regressions, and what to stop measuring
Security reporting has one job: make the next action obvious for the owner, the environment, and the release.
In practice, that means reporting what your release path can enforce. Keep evidence automatic by tying changes to cloud reality with release identifiers, so you can answer what commit introduced the risk and whether production drifted.
We cover the full checklist of gates, drift controls, and evidence patterns in “10 DevSecOps Best Practices That Actually Survive Production.”
DevSecOps toolchain: connect findings, policies, and evidence
In a multi-account org, a toolchain scales only when every release produces one decision record: what was built, what was checked, what was signed, what was allowed, and what actually ran.
We run DevSecOps by making the pipeline the control point where policy decides automatically, then attaching that decision to the change record. This keeps management consistent across environments, keeps release flow predictable, and keeps software promotion traceable, even when the same workload runs across clusters. For a deeper reference architecture and control points by pipeline stage, learn more in our DevSecOps toolchain guide.
For a deeper reference architecture and control points by pipeline stage, learn more in our DevSecOps toolchain guide.
One evidence trail per release approach
This is a standard supply chain approach. SLSA treats provenance as verifiable metadata attached to an artifact so downstream systems can validate what produced it and decide if it is allowed.
Example: prod deploy is pinned to a digest and admitted only with a signed attestation. Later drift is detected. The ticket includes the digest, the policy decision ID, and the drift diff, so remediation is a rollback to the last approved state plus a policy update.
DevSecOps rollout plan for production security
This rollout works for most teams because it follows control points that exist in the container's delivery path, regardless of tooling. It is grounded in widely used practices:
- Phased enforcement modes in Kubernetes Pod Security Admission for warn/audit/enforce
- Policy engines that support Audit to Enforce progression
- GitOps drift detection against a desired state
 Use this rollout as a baseline, then adapt the enforcement point to your stack. The sequence stays stable because it is tied to artifacts, promotion decisions, and runtime state, so it scales across clusters and accounts without rewriting the model for every platform.
Use this rollout as a baseline, then adapt the enforcement point to your stack. The sequence stays stable because it is tied to artifacts, promotion decisions, and runtime state, so it scales across clusters and accounts without rewriting the model for every platform.
How Cloudaware makes controls auditable at scale
DevSecOps stalls when the release decision is scattered across CI logs, tickets, and cluster state. Cloudaware tightens the loop by turning change data into an enforceable promotion path, with an audit trail attached, so you can stop non-compliant changes from reaching production.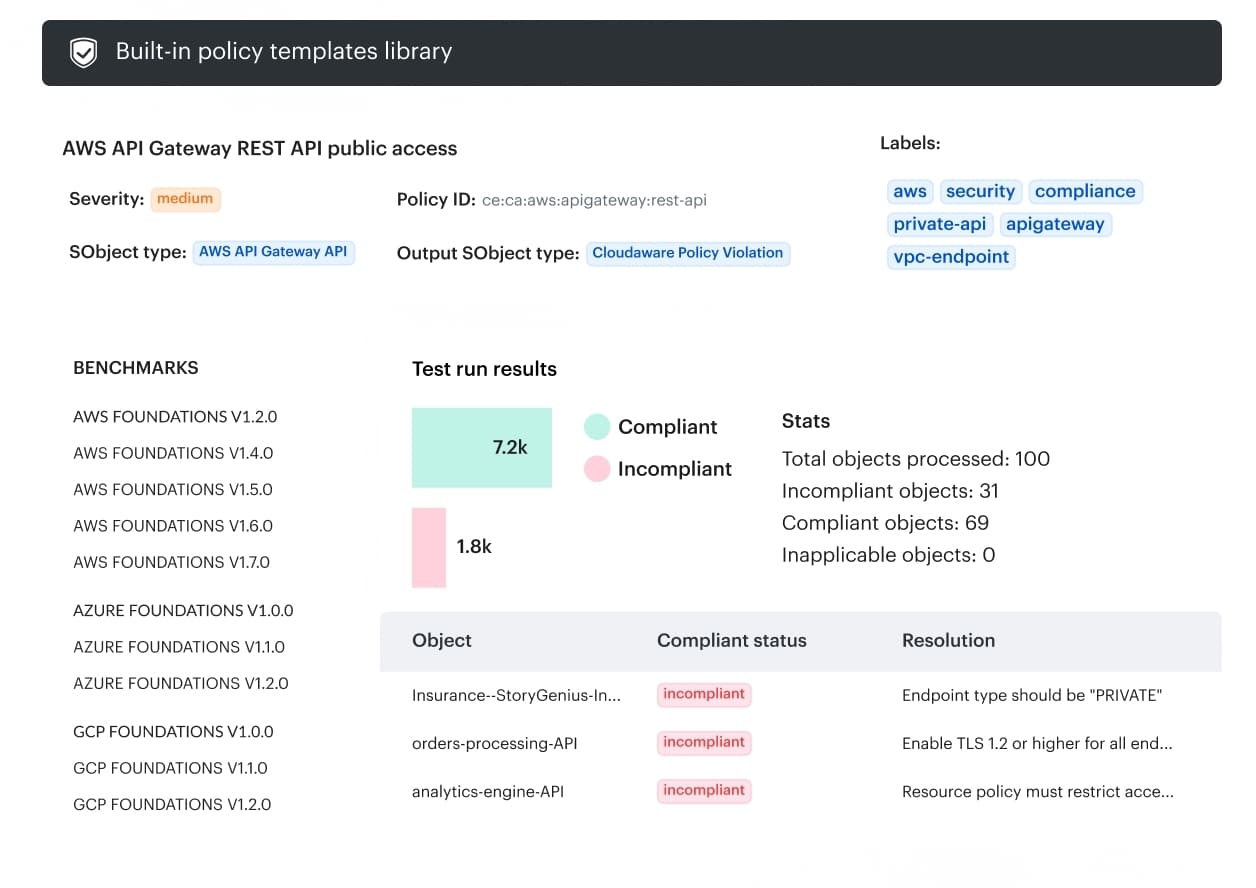 What Cloudaware does for the container security flow you have been building:
What Cloudaware does for the container security flow you have been building:
- 100% change visibility across hybrid environments, including who changed what and when.
- Real-time change review to keep control while maintaining rapid deployment speeds.
- Custom policies to block the changes that matter at promotion points.
- Approvals routed by account, user group, or environment, so prod rules stay strict without blocking dev.
- A configuration audit trail so that drift and out-of-band changes do not become “unknown change” during incidents.