Pull request is ready. The security review queue is not. Prod has a change window, and someone pings, “Can we just approve it?” At that moment, the true manifestation of DevSecOps culture emerges, not from a PowerPoint presentation.
This piece gives you culture rules you can enforce as defaults, the anti-patterns that quietly create bypasses, and a measurable rollout that keeps flow moving with guardrails, not heroics, while protecting developer experience and security enablement inside continuous delivery.
Now for the voices: together with Cloudaware DevSecOps experts Valentin, Software Developer, and Igor, a DevOps Engineer, we unpack DevSecOps culture and mindset as an operating system.
- Who owns the decision when risk spikes?
- What gets auto-approved, what gets gated, and why?
- Where does shared responsibility break first?
- Which metrics prove progress next month: approval time, drift rate, exception expiry, or change failure rate?
TL;DR
- If security feedback arrives after deployment, you didn’t “miss shift-left.” You created guaranteed rework. Late findings force context switching, meeting scheduling, and hotfix risk. PR-time checks keep fixes cheap because the author still remembers the change.
- “More approvals” is almost always a trust failure, not a control strategy. When teams don’t trust the system, every change becomes a meeting. The cure is evidence in the pipeline, not another checkbox.
- Your fastest culture win is routing, not training. The moment every alert, violation, and change lands on a real service owner, half the “culture problem” disappears because work stops bouncing between queues.
- Risk-based approvals aren’t “less security.” They’re how you stop rubber-stamping. Auto-approve low-risk diffs that passed checks. Escalate only changes that expand blast radius, privilege, or exposure, with a clear owner and a time-bound decision.
- Drift is the silent culture killer. When runtime diverges from what was approved, everyone starts arguing from different realities. Baselines + drift detection restore trust because the conversation becomes a difference, not a debate.
- Alert fatigue is a math problem, not a motivation problem. If most alerts don’t lead to action, people will mute them. Track alert action rate and kill noisy rules until signal-to-noise improves.
- Security debt behaves like interest, so treat it like finance. “Warn” without an SLA is just noise. The combination of a deadline and escalation transforms findings into actual work.
- Human approvals don’t scale as your primary control layer. Delivery either stutters to a halt or teams circumvent controls to proceed. The only stable setup is automated deterministic checks plus humans for ambiguous, high-impact calls.
- You can’t manage DevSecOps culture with feelings; you manage it with timestamps. Feedback latency, manual approval rate, exception expiry adherence, drift time-to-own, and repeat violations. Trend them for 6-8 weeks, and you’ll know if culture is improving.
- Audits reveal your real operating system. If evidence collection is a “project,” your culture is still manual. When traceability from commit to deploy is automatic, compliance becomes boring, and boring is the goal.
What does “DevSecOps culture” mean?
DevSecOps culture is the shared way Dev, Sec, and Ops build and run software where security is treated as everyone’s job, baked into the workflow, and supported by automation instead of last-minute heroics. That framing is consistent with how major vendors describe DevSecOps: an approach that blends culture, automation, and platform design so security becomes a shared responsibility across the lifecycle.
Now zoom in to what that means on a real Tuesday. Culture isn’t what your leadership deck says. It’s the default decisions people make under pressure: who approves, what blocks, what gets auto-approved, what gets ignored, and what gets escalated at 6:47 p.m. because the prod window closes at 7.
That’s why the biggest trap is thinking that “we added tools” equals “we changed behavior.” Effective DevSecOps requires more than tooling, because the cultural shifts are what move security earlier and keep delivery from slowing down.
So instead of trying to measure vibes, look for signals you can literally observe in tickets and logs.
1️⃣ Ownership is obvious. If your ownership model is working, security findings don’t bounce between “not my service” comments. Alerts route to a real team, tied to a repo, a service, an environment, and an on-call rotation. In logs, you’ll see the same pattern: the same owners consistently triage and close classes of issues because the system knows who should act.
2️⃣ Security feedback is fast. A healthy security feedback loop looks like minutes or hours, not weeks. The evidence is right there in timestamps:
PR opened → check ran → comment posted → fix pushed → merge
When feedback is slow, people optimize around it by batching risky changes, slipping “temporary” bypasses into the pipeline, or waiting until the end when the rework hurts most.
3️⃣ Exceptions expire. Real culture has discipline around exception management. If a control is bypassed, it comes with a reason, an owner, and an expiration date that forces a revisit. In practice, you’ll see fewer temporary waivers living for 9 months “until we refactor" and more short-lived, reviewed exceptions that either get closed, renewed with justification, or turned into a proper fix.
From there, you can create a seamless culture by providing teams with a well-defined path. Golden paths are how you turn “please do the secure thing” into “the secure thing is the easiest thing,” because the defaults are pre-built and documented.
And once the defaults exist, you can tighten the dial using risk-based controls so you only block what creates compounding risk, while everything else stays visible with clear SLAs.
3 friction patterns people mistake for “culture problems”
Here’s why the confusion happens: when releases get tense, people reach for the biggest label available. “It’s a DevSecOps culture issue” becomes shorthand for a workflow that keeps forcing humans to negotiate risk in real time, with incomplete context, and usually in someone’s Slack DMs. Fix the defaults, and the “culture problem” often shrinks fast.

1. The blame loop of Dev vs Sec
Red Hat calls out the blame-game dynamic as a common symptom: Dev thinks security slows everything down, security thinks Dev cuts corners, and both teams start protecting themselves instead of the system. That’s when security gatekeeping sneaks in. Not because anyone wants it, but because the organization never agreed on a clean definition of “safe enough” for this service, this environment, and this data class.
Under the hood, there are two root causes: mismatched incentives (speed vs risk) and missing decision criteria. Without a shared threshold, every debate turns personal, and every hotfix becomes a referendum on competence.
And once trust takes a hit, the process reacts in the most predictable way possible: it adds more approvals.
2. Manual review inflation
This is the snowball. One manual sign-off becomes two. Then three. After that, it’s a standing meeting “so we can move faster,” which is how you get approval fatigue wrapped in a calendar invite.
The real cost isn’t only time. It’s toil: people re-checking the same evidence, re-reading the same diffs, and re-asking for the same screenshots, because the system didn’t capture intent and risk in a reusable way.
That’s how your change failure rate can climb even while you’re “being careful.” Teams batch risky changes to avoid the queue, approvals become rubber stamps, and production gets surprises anyway.
A Cloudaware PS lead put it bluntly, and it lands because it’s true in every enterprise pipeline:
Then comes the part that breaks focus for everyone, including security.
3. Alert overload turns security into interruption-as-a-service
Checkmarx describes the cultural mismatch well: dev teams need long stretches of uninterrupted maker time, while security gets bombarded by alerts that interrupt work. When the stream is noisy, alert fatigue becomes rational. People mute channels. Triage gets delayed. High-signal issues hide inside the noise.
It also messes with behavior: teams learn that alerts don’t reliably map to action, so they stop treating them as decisions. That’s not a motivation problem. It’s a signal-to-noise problem.
The mindset shift that unlocks DevSecOps culture
After the blame loop, the approval snowball, and the alert firehose, it’s tempting to “fix culture” by running workshops. That never sticks. What sticks is a mindset shift that changes what teams optimize for, because it rewires the defaults that created the friction in the first place.
Security is a product quality property, not a phase
Security can’t live at the end of the line, wedged between “ready to ship” and “prod change window.” The moment it becomes a phase, it becomes negotiable. Deadlines win, approvals get rushed, and the work shows up later as rework, outages, or uncomfortable audit conversations.
Treat it like product quality instead. Same category as reliability, performance, and correctness. If a change breaks an SLO, you don’t ask, “Can we just approve it?” You fix it because the product isn’t ready. Security deserves that same status. A misconfigured IAM policy, public exposure, or an over-permissive network path is a quality defect with a blast radius.
This is where DevSecOps stops being “security vs delivery” and turns into shared responsibility with guardrails that protect developer experience. In practical terms, it means security checks are part of the definition of done, not a separate gate. Your pipeline enforces the boring, deterministic stuff automatically. Humans step in for the genuinely ambiguous calls. That’s how you keep continuous delivery moving while making security outcomes predictable.
Read also: Six Pillars of DevSecOps - How to Implement them in a Pipeline
“Enablement” beats “enforcement”
Enforcement looks clean on paper: add a gate, assign an appr over, and call it “control.” Then the org scales. Release volume climbs, context fragments, and that gate turns into a queue everyone resents. You don’t get safer; you get security gatekeeping as a coping mechanism.
Checkmarx puts language to the real mismatch. Developers need uninterrupted maker time, security gets bombarded by alerts, and the only way those worlds meet peacefully is if security moves at DevOps speed instead of showing up later as a blocker.
Gartner, DevSecOps Maturity Model for Secure Software Development, 29 August 2024
That’s the gap you feel in every “can we just approve it?” ping.
Enablement is how you close it without turning your pipeline into a courtroom. Make the safe path the easiest path. Ship hardened templates, pre-approved patterns, and automated checks that run where developers already work. Save humans for the genuinely messy judgment calls, not the repeatable ones.
When feedback lands in minutes, people fix issues while the change is still in their heads. When it lands in days, it becomes archaeology, and you can predict the bypass behavior before it happens.
Read also: DevSecOps Maturity Model - Scorecard You Can Measure
Teams need shared measures, not shared feelings
Culture arguments don’t get resolved by sincerity. They get resolved by receipts. If Dev says, “Security slows us down,” and Sec says, “Dev is reckless,” you can’t mediate that with a workshop. You need a scoreboard that both sides trust, because DevSecOps culture and mindset only become real when people can see the same system behavior and agree on what “better” looks like.
That’s the bridge from enablement to alignment.
Once you’ve stopped relying on humans as the primary control layer, you still need a way to prove you’re not trading safety for speed. This is where shared measurements do the heavy lifting. They replace debates with trends, and trends are harder to gaslight.
So what can both sides agree on? Metrics that capture outcomes, not opinions.
- Start with security velocity: how quickly a security signal turns into a fix. Not “number of findings,” but time from detection to remediation, split by severity and environment.
- Pair it with delivery health so nobody can “win” by breaking the other team: change failure rate, rollback frequency, and time-to-recover when something slips through.
- Add two leading indicators that expose cultural drift early: the percentage of changes requiring manual approval and adherence to exception expiry, as permanent bypasses represent cultural debt with interest.
- Then make it teachable. If a metric is trending the wrong way, the action shouldn’t be “try harder.” It should trigger security education that’s specific to the failure mode: a short playbook, a template update, a policy tweak, or a golden path improvement.
That’s how you turn measurement into continuous improvement instead of a monthly blame ritual.
7 operating rules of a healthy DevSecOps culture
Once you stop treating culture like a soft-skills problem and start treating it like an operating system, the work gets refreshingly concrete. These rules come from the Cloudaware DevSecOps bench, the people who live in the messy middle of hybrid cloud, regulated environments, and pipelines that ship every day.
So let’s start where most culture problems actually begin: the moment feedback arrives too late to be useful.
Rule 1: Make security feedback instant (shift-left, but for infra too)
This rule is the fastest way to change behavior without asking anyone to “care more.” If security feedback shows up while the author still has the pull request (PR) context in their head, fixes feel cheap. When it arrives after deployment, you’ve turned a small correction into a cross-team incident response, complete with blame and calendar invites.
That’s why “shift left” can’t stop at application code. Infrastructure changes need the same treatment, because most real-world blast radius comes from misconfigured identity, network exposure, storage permissions, and logging gaps.
So the principle is simple: turn security into a first-class PR signal. Use policy as a code to express what is allowed, run pre-deploy checks automatically, and keep humans out of the loop unless the change truly increases risk.
The cultural effect is immediate. Developers stop seeing security as a surprise. Security stops being the department of “no.” Your pipeline becomes the neutral referee.
Now make it tangible with one example you can implement in a week.
Example: IaC policy checks run at PR time, not after deploy
A Terraform change adds an S3 bucket, an IAM role, and a security group. In a healthy setup, the PR gets a comment within minutes: bucket encryption missing, role is too permissive, inbound rule exposes a port to the world.
The author fixes it, pushes a commit, the checks go green, and you merge. Nobody had to schedule a review. Nobody had to remember a checklist. That’s IaC security acting like product quality, not like a phase.
To make that happen reliably, you need a clear “this is good” standard that teams can recognize instantly.
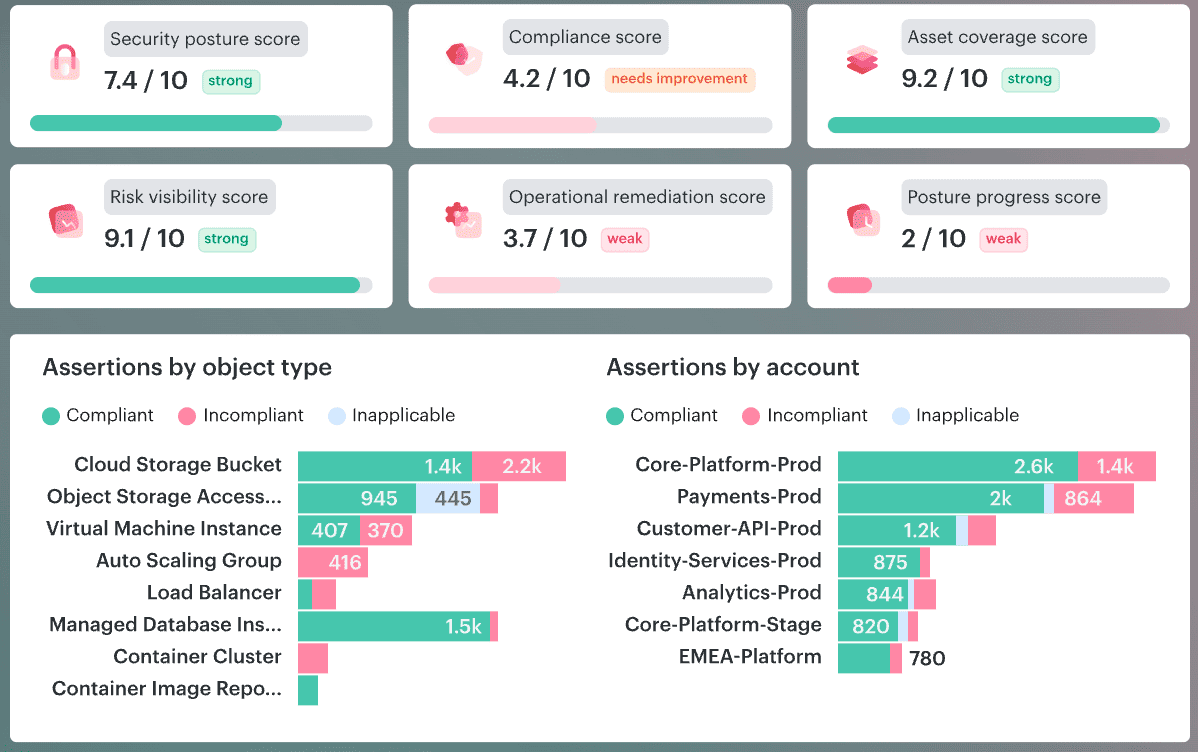
If you nail this rule, the rest of DevSecOps gets easier because you’ve proven the core promise: security can be fast, predictable, and largely automated.
Read also: 10 DevSecOps Best Practices That Actually Survive Production
Rule 2: Approve only the changes that matter
Instant feedback is great, but it’s not the endgame. The real win is what it unlocks: you stop treating every change like a potential disaster. When approvals are everywhere, they turn into background noise, people get numb, and “review” becomes a rubber stamp. Real control gets weaker, not stronger.
So this rule is blunt on purpose: reserve human attention for changes that actually move risk. That’s risk-based approvals in practice. You let low-risk changes flow when the evidence is already there, and you slow down only when the blast radius, privilege, or exposure meaningfully shifts.
Here’s the operating pattern that works in grown-up pipelines:
- Auto-approve low-risk changes that pass tests and policy checks
- Route high-risk changes to the person who can own the consequence, not the person who happens to be on a security rota
- Schedule sensitive moves inside planned change windows, so you’re not debating risk in Slack at the worst possible time
Now put it in a real scenario. 👇
A team updates Terraform for a production AWS account: one PR tweaks an IAM role and opens an outbound rule. Most diffs are harmless, but this one touches privileges and network reachability, so the pipeline flags it as high-risk.
Instead of stopping everything, the system creates structured approval routing: it goes to the service owner for that account and environment, with security looped in for the specific policy delta. The approver gets a tight packet, not a vague request:
- What changed?
- Which checks passed?
- Which policy tripped?
- What resources are affected?
- What does the rollback look like?
That’s also where modern change control stops being “who is allowed to approve” and becomes “what signals trigger a decision.” In Cloudaware client setups, this routing is often driven by account, group, and environment ownership, with notifications landing where work already happens.
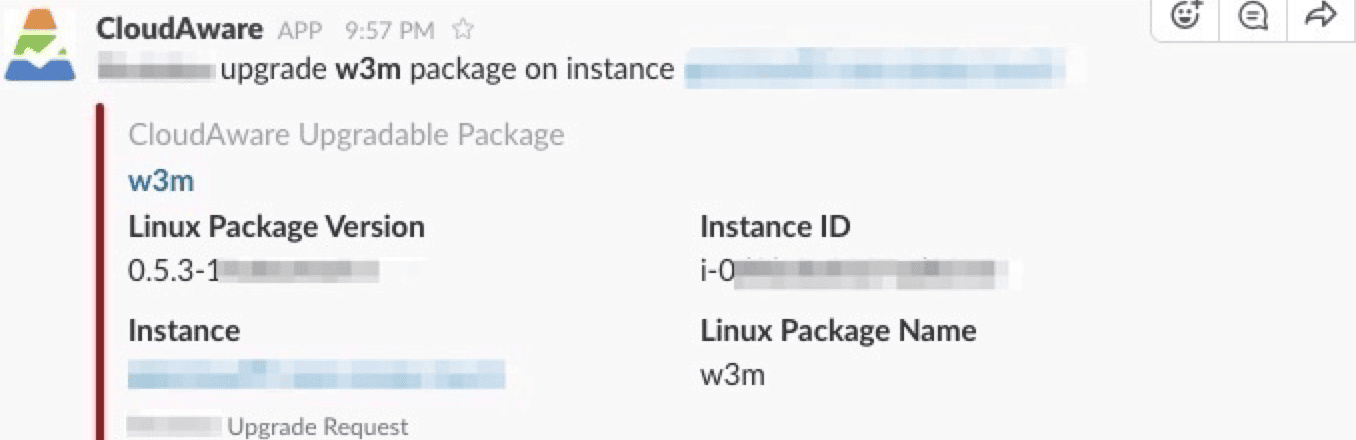
A Slack ping for fast eyes, a Jira ticket if it needs tracking, a ServiceNow change record when it’s production and regulated. Nothing dramatic. Just a decision that’s fast, attributable, and easy to audit.
Do this well, and two things happen quietly. Approval volume drops because most changes don’t deserve a meeting. The approvals that remain get better because they’re focused on the handful of changes that actually matter.
Rule 3: Integrate tools so collaboration happens without meetings
If Rule 2 is about who should approve, this rule is about where the conversation should happen. In healthy teams, collaboration doesn’t require a weekly sync to “get aligned.” It’s baked into the toolchain, so work speaks for itself, in real time, with the right people automatically pulled in.
SAIC calls this out as “rapid collaboration” and gets specific: wire CI/CD tools (like Jenkins and GitHub) into project tools such as Jira and ChatOps so routine actions trigger automated communication across teams.
When a developer opens a PR, reviewers get pinged instantly. When a scrum master creates a Jira story, Slack notifies the developer. When monitoring sees a server nearin g a critical state, support gets alerted via ChatOps before it becomes an outage.
Now here’s the part that makes it operational instead of inspirational. Turn those integrations into a simple, repeatable template you can apply to almost any security or delivery workflow:
- Event: PR opened, policy check failed, prod drift detected, vuln crosses severity threshold
- Notification: Slack message, Jira update, ServiceNow task, PR comment
- Owner: routed by service/team/environment, not by “whoever is online”
- Decision: approve, block, warn-with-SLA, or request change with specific evidence
- Audit record: the decision and context are captured automatically (ticket + PR + timestamps)
That’s what workflow automation is doing for culture: it replaces “can someone look at this?” with a predictable path from signal to action. The side effect is the thing leaders actually want, even if they don’t phrase it this way. You get continuous collaboration without constant meetings, because the system keeps everyone in the loop at the moment it matters, not three days later in a status update.
Rule 4: Treat drift as a cultural issue
Tool integrations can move decisions fast. They don’t guarantee everyone is talking about the same reality. That’s where teams get burned, because the fastest way to restart the blame loop is hearing “we didn’t change anything” while production is clearly different.
That gap is configuration drift, and it’s not just a technical nuisance. It’s a trust problem. If what’s running doesn’t match what you believe is running, every security conversation turns into speculation. Reviews get tighter, approvals multiply, and nobody can tell whether a control worked or got quietly bypassed.
So you create baselines, and you measure against them. A baseline is your agreed “this is normal” snapshot for an environment or cluster, tied to ownership and reviewed on purpose. Once it exists, drift stops being an argument. It becomes a diff with a timestamp and an owner.
In practice, teams do this by continuously comparing live configuration to approved baselines and flagging unexpected changes across cloud accounts and Kubernetes clusters.
Rule 5: Reduce security debt without blocking everything
After you’ve started catching drift, the next instinct is predictable: block more. It feels like progress. Then delivery slows, teams route around controls, and your security debt quietly grows anyway because the process becomes impossible to follow under pressure.
So you need a simpler operating model that makes risk decisions boring and repeatable. Some things are urgent, and some things matter.
Start with three outcomes, and make them explicit in the pipeline:
| Outcome | Trigger | Pipeline action | Notes |
|---|---|---|---|
| Block | High-risk boundary crossed (public exposure, privileged access, sensitive data path) | Fail gate / stop promotion | Keep rule set small and deterministic |
| Warn | Policy violation below block threshold | Pass gate + emit warning | Used for rule tuning and early visibility |
| Fix-by-SLA | Warning created | Create tracked item + deadline + escalation | SLA by severity/environment; enforce expiry/escalation |
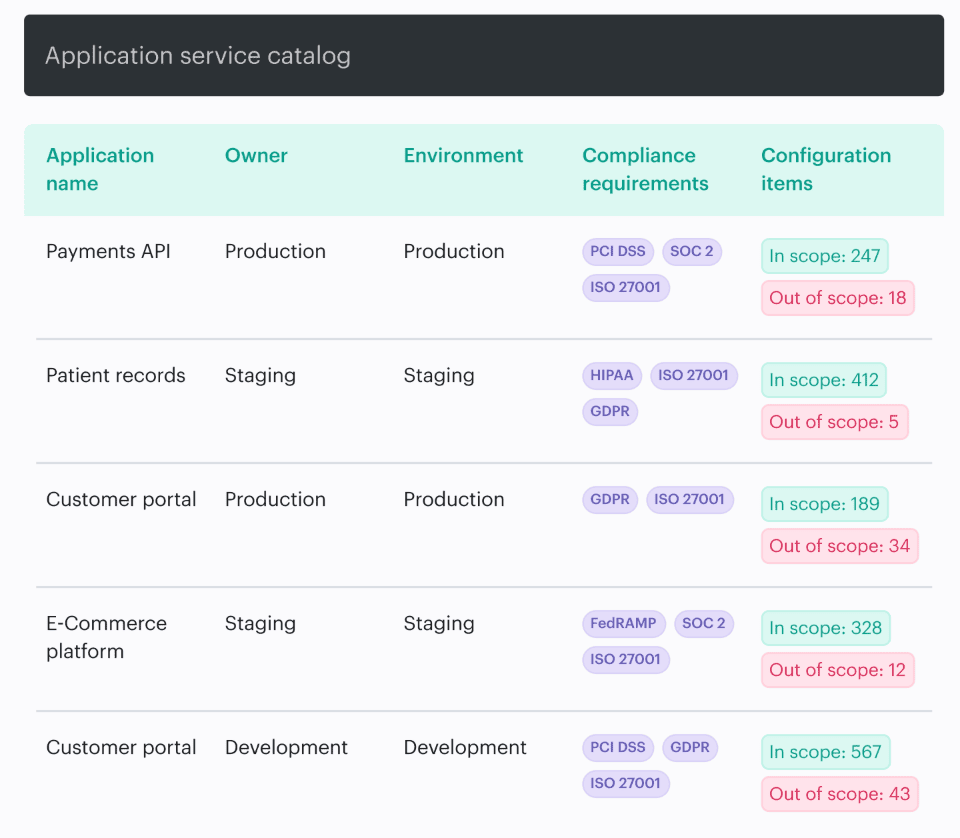
Here’s what this looks like when teams implement it cleanly. During promotion, the pipeline checks current violations and decides whether the change can move forward. In some Cloudaware client workflows, that decision is driven by violations data already aggregated across accounts and clusters.
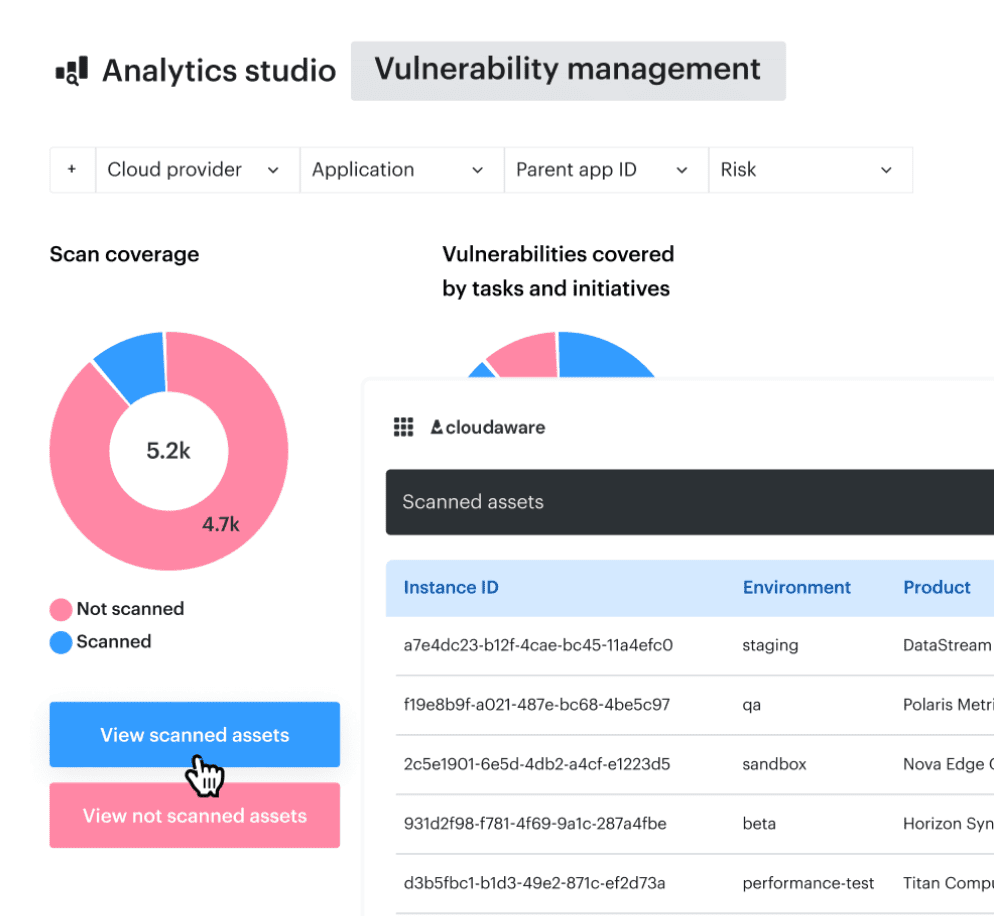
Cloudaware DevSecOps report element. Schedule a demo to see it live
The promotion step uses that signal for precise gating: if the change introduces a high-risk violation, it doesn’t ship. If it’s lower risk, it ships with a warning and an SLA-backed ticket so the debt gets paid down on schedule, not “when things calm down.”
Read also: 15 DevSecOps Tools - Software Features & Pricing Review
Rule 6: Empower teams and protect psychological safety
After you’ve made risk decisions predictable, the next bottleneck is human. If public blame for the cost prevents people from surfacing mistakes early, no amount of automation can remedy this. Psychological safety is what keeps the feedback loop honest, because the fastest way to create shadow changes is to punish the first person who admits something went sideways.
On the ground, the result becomes a few concrete behaviors you can bake into the system. Run blameless reviews that focus on broken controls and missing context, not on who clicked what. Keep shared runbooks that any on-call engineer can follow at 2 a.m., then iterate them after every meaningful failure so the org gets smarter instead of just tired.
One more move makes it stick: rotate security champions inside product teams, not as mini-police, but as translators who improve the paved path. That’s enablement at scale. The champion helps turn “security said no” into “here’s the approved pattern,” and your pipeline stops depending on hero reviewers to keep quality up.
Rule 7: Make audits boring by collecting evidence continuously
By the time you’ve nailed ownership, approvals, and drift, there’s one last culture test: what happens when an audit shows up? If your audit trail lives in screenshots, tribal memory, and a frantic spreadsheet week, you don’t have a compliance program. You have a seasonal panic.
The mindset shift is simple. Turn compliance into a side effect of the pipeline. Every meaningful control should leave a breadcrumb automatically, right where work already happens. A PR gets checks. A merge triggers a build. A deploy updates an environment. Those events are already real, so you use them to create traceability from “what changed” to “what ran” without asking humans to narrate history.
That’s what continuous evidence looks like in practice: policy results captured at PR time, approvals recorded with context, deployment metadata attached to the change, and exceptions tracked with expiry. When an auditor asks, “Prove this control worked,” you don’t schedule interviews. You export a report.
In some Cloudaware client workflows, this becomes routine because evidence is collected continuously and stitched together from commit to deploy into audit-ready reporting.
Cloudaware DevSecOps report element. Schedule a demo to see it live
The goal isn’t to impress anyone. It’s to make SOC 2 and ISO 27001 questions feel like querying a system of record, not reliving the last six months in Slack.
How to measure DevSecOps culture without surveys
Surveys tell you how people feel this week. While surveys can be useful at times, they do not serve as a reliable measurement system. If you want to prove that DevSecOps culture and mindset are improving, pull the data your teams already produce every day, because your delivery system is basically a black box flight recorder.
In Cloudaware client environments, the most reliable signals come from “pipeline exhaust” and operational workflows: PR timestamps and check results, CI/CD run logs, Jira/ServiceNow ticket lifecycles, Slack/ChatOps events, cloud config change history, Kubernetes audit events, plus policy evaluation outcomes and exception records.
Nobody has to remember to fill anything in. The system writes the story for you.
That unlocks a scorecard you can review monthly without turning it into a therapy session:
- Ownership routing coverage: % of alerts/tickets/violations that land on a real service owner (not “Security Queue”)
- Security feedback latency: median time from PR open → first actionable security signal (comment/check result)
- Manual approval rate: % of changes requiring a human decision, split by env (dev/stage/prod)
- High-risk approval SLA adherence: % of high-risk changes approved/rejected within your target window
- Exception expiry adherence: % of exceptions that expire on time vs silently living forever.
- Drift time-to-own: time from drift detected → assigned to an owner → first action taken
- Alert action rate: % of alerts converted into a tracked decision (ticket, accepted risk, tuned rule)
- Repeat violation rate: how often the same policy breach returns on the same service after “fix”
30/60/90-day rollout plan of the DevSecOps culture
If you try to “change culture” in one quarter by doing everything, you’ll get noise, burnout, and a slide deck full of aspirations. The better move is to use a maturity ladder that you can prove with data. This plan is built for leaders who need DevSecOps culture and mindset to show up as defaults in delivery, not as a quarterly theme.

0-30 days: agree on ownership + definitions
Start with the boring stuff that quietly fixes half the friction. Lock in an ownership map that’s real enough to route work: every critical service is tied to a team, an on-call, and an environment boundary. Then standardize definitions that keep debates from restarting every sprint.
- What counts as “prod”?
- What’s high-risk?
- What’s “safe enough” for identity, network, and data exposure?
Once those definitions exist, your guardrails can be predictable instead of emotional.
From there, you can stop negotiating and start wiring the system.
31-60 days: automate collaboration + evidence
This is where the enablement team earns its keep. You integrate signals into where people already work, so collaboration happens without meetings. A policy check fails, and the PR gets an actionable comment. A high-risk change routes to the right owner with context. A drift event becomes a ticket with a clear assignee.
While you’re doing that, collect evidence as a side effect: approvals, policy outcomes, deployments, exception expiries.
That’s the start of standardization that doesn’t feel like bureaucracy because it removes toil. And once the machine is producing reliable signals, you can tighten the loop.
61-90 days: tighten feedback loops
Now you tune for speed and trust.
- Promote the checks that truly matter from warn to block, and demote the noisy ones so teams don’t drown.
- Put deadlines on exceptions and enforce expiry so “temporary” doesn’t become a permanent risk.
- Review your scorecard monthly and act on it like a product: if manual approvals spike, fix the guardrails. If drift keeps returning, fix the baseline process.
This is what real maturity looks like: fewer debates, faster decisions, and measurable improvement that doesn’t depend on heroics.
Make DevSecOps culture stick when nobody has time to “be cultural”
A healthy DevSecOps culture isn’t powered by motivation. It’s powered by defaults that hold up on a bad day. Cloudaware’s value in this story is simple: it turns the “right behaviors” into repeatable workflows across cloud and Kubernetes, so security doesn’t depend on hero reviewers or tribal memory.
- Start with the place culture usually breaks first. Approvals. Instead of routing everything to “Security,” Cloudaware helps teams route decisions by environment, account, and owning team, with notifications landing where work already happens, whether that’s Slack, Jira, or ServiceNow.
Low-risk changes flow when evidence is green. High-risk changes get a real decision with context, not a hand wave. - From there, controls become something you can automate. Policy outcomes can gate the few changes that create compounding risk, while the rest stay visible as warnings with SLAs, so delivery keeps moving.
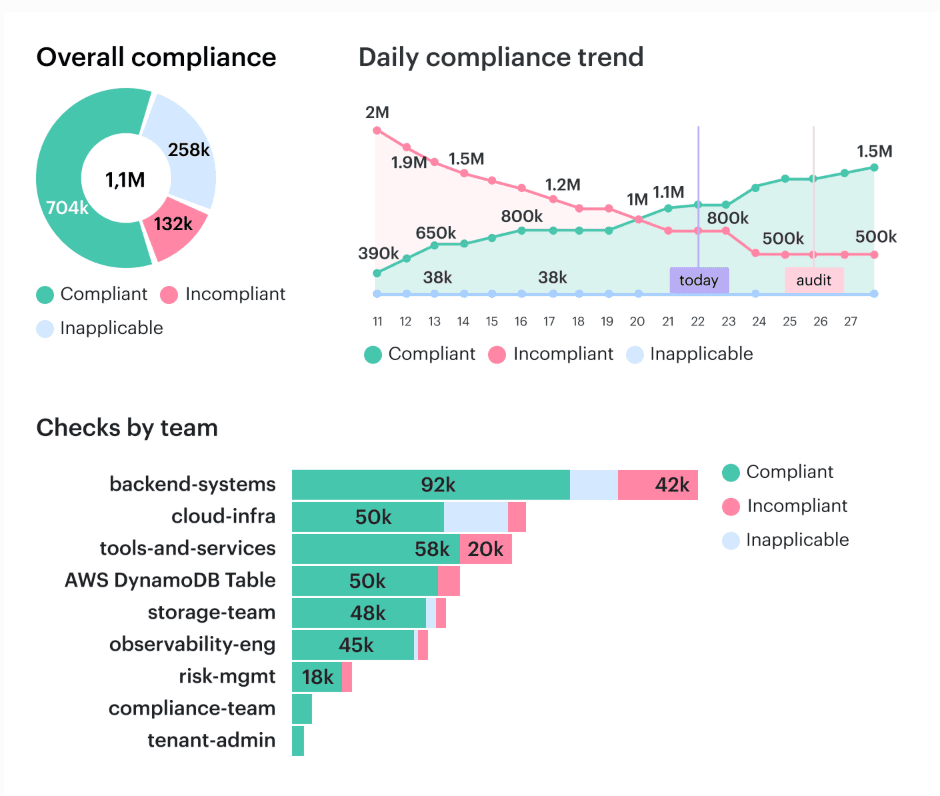
That’s how you reduce bypass behavior without turning your pipeline into a parking lot. - Then reality steps in after deployment, because someone always fixes something in the console at 2 a.m. Cloudaware helps establish baselines and flag drift across cloud and Kubernetes, so “we didn’t change anything” turns into a timestamped diff with an owner.

Trust goes up. Noise goes down. Reviews get lighter because you’re no longer guessing. - Finally, ITAM audits stop being a seasonal emergency. With traceability from commit to deploy and continuous evidence captured along the way, you can answer “prove this control worked” with an audit-ready report instead of a spreadsheet marathon.