






Someone asks, “Does this block the release?” and the room goes quiet for a second longer than it should.
The pipeline already ran, a security check failed, and the team is trying to remember whether this finding was waived last time, whether policy actually covers it, or whether someone needs to make a call before production moves forward, which is usually the moment when DevSecOps implementation starts to feel fragile instead of reliable.
At that point, the delivery system is producing signals without being able to turn them into decisions. The usual response is to add more security tooling in the hope that coverage will create certainty, even though it almost always leads to more findings, more exceptions, and the same uncertainty at release time.
What’s missing is structure: a shared model for how security decisions are made, enforced, and revisited as systems change. This guide focuses on building that structure directly into the delivery system, so release decisions are clear before the pipeline runs, rather than negotiated after it finishes.
What DevSecOps implementation actually means
DevSecOps implementation starts to make sense when the team looks at the moment a change is promoted and asks where the system decides whether risk is acceptable, because that decision is the only point where security actually changes an outcome.
Usually, pipelines move artifacts forward reliably while security findings arrive alongside the flow rather than inside it. This forces engineers to interpret results manually and decide what to do under time pressure, often with incomplete context and inconsistent outcomes from one release to the next.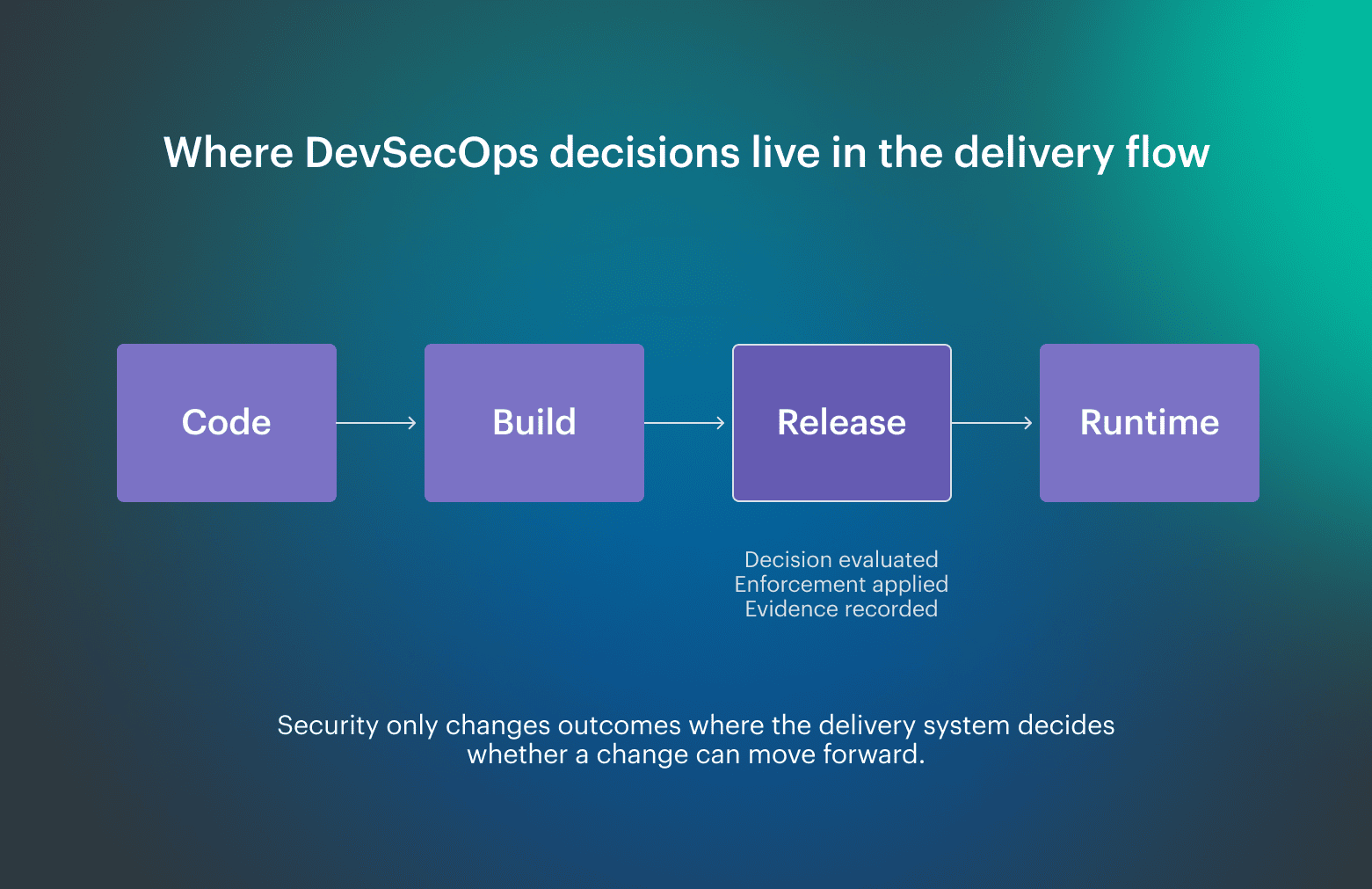 This way, security checks stop acting as suggestions and start acting as controls, which reduces last-minute debates and makes release behavior predictable instead of negotiable.
This way, security checks stop acting as suggestions and start acting as controls, which reduces last-minute debates and makes release behavior predictable instead of negotiable.
At a practical level, this means the delivery system knows where decisions are enforced, who owns remediation when something fails, and how runtime behavior feeds back into future rules.
Read also: Inside the DevSecOps Lifecycle - Decisions, Gates, and Evidence
Why DevSecOps implementation fails in practice
Failure shows up at release time, not during design. The pipeline ran, the tools reported what they saw, and the system still cannot apply a decision on its own, which pushes teams into manual judgment calls right when time pressure is highest.
A common pattern is that security controls are added faster than ownership and enforcement are defined, so findings accumulate while responsibility stays vague, and teams quietly create exceptions to keep shipping.
Another recurring issue is that runtime signals never make it back into delivery rules, so the same misconfigurations reappear across releases even after incidents or audit findings. Teams fix symptoms in production, but the pipeline never learns, so the cost shows up again at the next promotion.
When these gaps exist, the pipeline can report risk but can’t act on it, which is why delivery ends up negotiating decisions manually under pressure.
Сore principles behind a successful DevSecOps implementation
A successful DevSecOps implementation survives real delivery pressure because it treats security as part of the decision flow, not as an overlay of checks, which gives a consistent way to ship without renegotiating risk on every release.
Automated security decisions at promotion time
The first principle is automated decision-making, where risk thresholds are defined upfront and evaluated by the delivery system itself at promotion points, so releases behave consistently regardless of timing, urgency, or who is on call.
This model aligns with continuous authorization practices used in regulated environments, including guidance from the U.S. Department of Defense, where more security decisions become automatable, enforceable, and auditable over time.
Explicit ownership for risk and remediation
The second principle is explicit ownership, because controls without owners decay quickly as exceptions accumulate and accountability fades. When ownership is clearly assigned, failed checks result in updated rules or remediation paths rather than temporary workarounds that quietly become permanent.
Continuous evidence instead of after-the-fact audits
The third principle is continuous evidence, where every decision is recorded as part of normal delivery, allowing audits to validate how the system operates in real time instead of forcing teams to reconstruct intent months later.
Together, these principles make DevSecOps implementation predictable, auditable, and scalable.
DevSecOps implementation architecture (from pipeline to runtime)
DevSecOps implementation architecture becomes relevant the moment teams realize that most security failures are not caused by missing checks, but by broken connections between build, release, and runtime, where decisions are made in one place and consequences surface somewhere else.
Usually, the pipeline evaluates changes in isolation, which creates a gap where approved intent and actual behavior slowly diverge without triggering enforcement.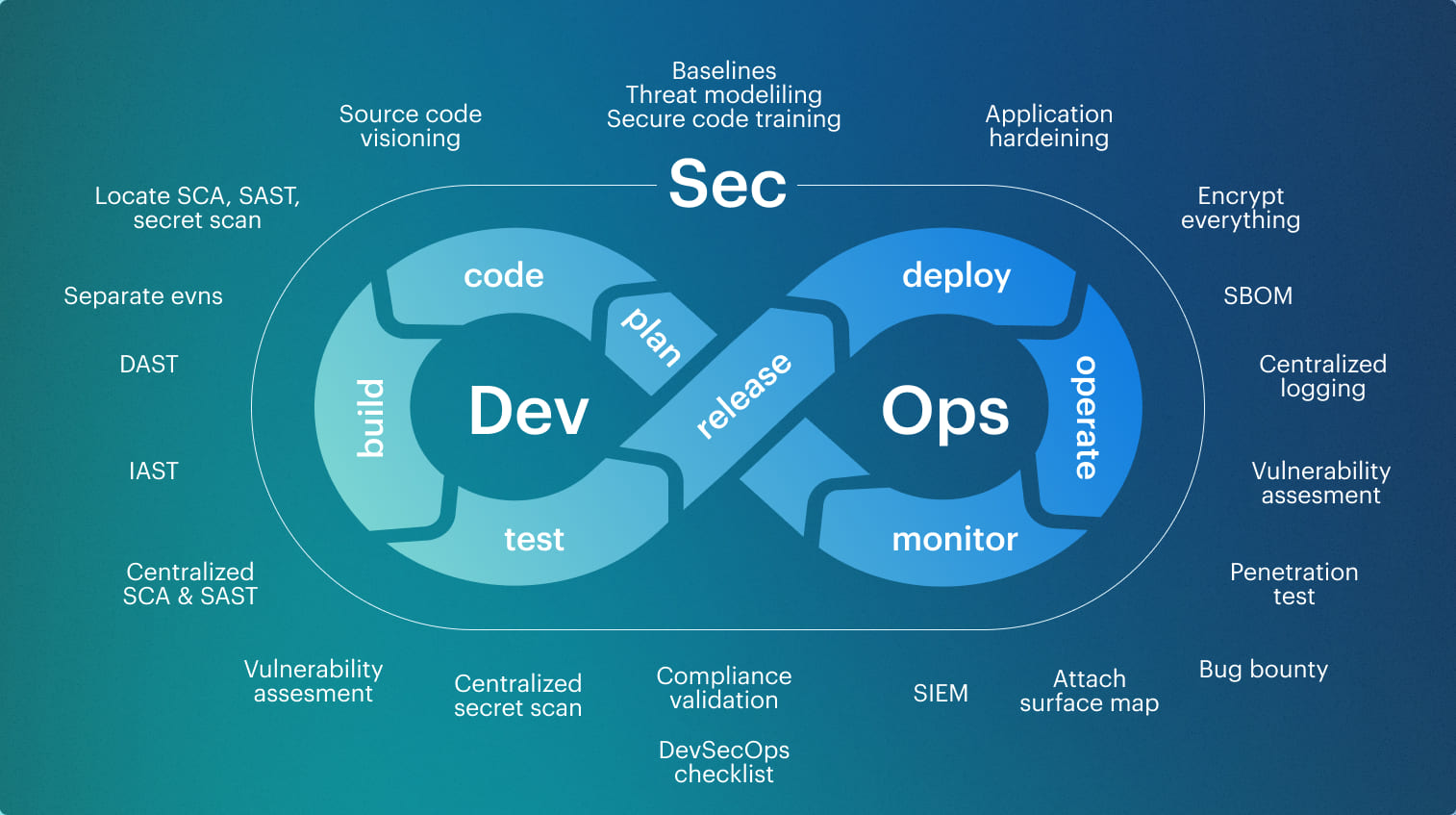 This is what DevSecOps often looks like in practice: comprehensive coverage, constant scanning, and very little clarity about which signals actually block a release.
This is what DevSecOps often looks like in practice: comprehensive coverage, constant scanning, and very little clarity about which signals actually block a release.
A resilient DevSecOps implementation architecture closes that gap by treating the pipeline and runtime as a single decision system, where promotion events, environment changes, and configuration updates all pass through shared control points that apply the same risk thresholds and record outcomes as evidence.
Pipeline enforcement tied to promotion
Build and release stages enforce defined risk thresholds at promotion points, so artifacts move forward only when conditions are met, and decisions are applied automatically instead of escalated.
Runtime feedback connected to delivery rules
Runtime signals such as drift, exposure, or incident patterns feed back into pipeline rules, which allows the system to learn from production instead of repeating the same failures.
When this gap exists:
- Approved intent drifts silently
- Enforcement weakens over time
- Audits surface surprises instead of assurance
Continuous evidence across stages
Every decision is logged at the moment it happens, which means audits validate live system behavior rather than reconstructed history.
Read also: DevSecOps Architecture (A Practical Reference Model Teams Actually Use)
How to implement DevSecOps in practice
DevSecOps implementation works when teams stop trying to “secure everything” and instead focus on building a baseline that actually holds during real releases.
A practical starting point is to walk a real application through its delivery path and mark the moments where people already hesitate, ask for approval, or request exceptions, such as promoting an image, opening an environment, or applying a risky configuration. These pauses already exist, which means the decision is real even if the system doesn’t enforce it yet.
Once those decision points are visible, make those decisions explicit and attach enforcement directly to the points where releases already slow down. Enforcement is then attached directly to those moments, which removes late-stage negotiation and makes outcomes consistent.
Runtime behavior has to feed back into the same rules, because fixing issues only in production without updating delivery decisions guarantees repetition.
Done this way, DevSecOps implementation grows as a minimally viable baseline that teams can extend over time, instead of a fragile program that collapses under scale.
DevSecOps implementation guide for engineering teams
Implementation becomes real for engineering teams when it stops being framed as a transformation program and starts behaving like a baseline that makes day-to-day delivery easier rather than harder. You already know where things break, because those are the moments when releases slow down or someone asks for an exception without being sure who can grant it.
A practical guide starts by mapping applications to owners and delivery paths, not for documentation’s sake, but to make it clear who is responsible when a decision blocks a change. Without that mapping, security tasks float between teams and enforcement quietly turns optional.
Once ownership is visible, teams can agree on a minimal baseline that applies to every service, even if the depth of controls differs between a startup workload and a regulated enterprise system.
That baseline centers on a small set of enforceable release decisions the delivery system can apply the same way every time.
From there, the guide grows incrementally. Controls are added based on observed failures, not theoretical coverage, and runtime behavior is monitored to validate whether assumptions still hold. This approach keeps DevSecOps implementation usable for engineers, adaptable across teams, and resilient as delivery speed increases, instead of collapsing under its own weight.
Read also: How to Build a Secure DevSecOps Toolchain Without Alert Fatigue
Building a DevSecOps implementation plan
A DevSecOps implementation plan works when it answers a few uncomfortable questions upfront instead of promising maturity later, because teams rarely fail due to missing ambition and almost always fail due to unclear scope, ownership, and enforcement.
The plan starts by defining where decisions will be enforced and who owns them, because security rules without scope or owners degrade into suggestions as soon as delivery pressure increases. From there, risk thresholds are expressed in terms the delivery system can evaluate on its own, so enforcement does not depend on meetings, tickets, or availability.
The final element is a feedback loop from runtime into delivery, because plans that do not adapt to real production behavior stop being relevant quickly.
Built this way, the plan stays reviewable, enforceable, and usable as teams scale.
Step-by-step DevSecOps implementation roadmap
Most DevSecOps rollouts break because teams try to do everything at once, so controls spread across the pipeline before anyone agrees which ones actually matter. You end up with checks everywhere and decisions nowhere, which means every release turns into a discussion.
The roadmap below exists to prevent that by locking down one decision at a time, starting with ownership and blocking rules, then expanding only after the system behaves predictably under real release pressure.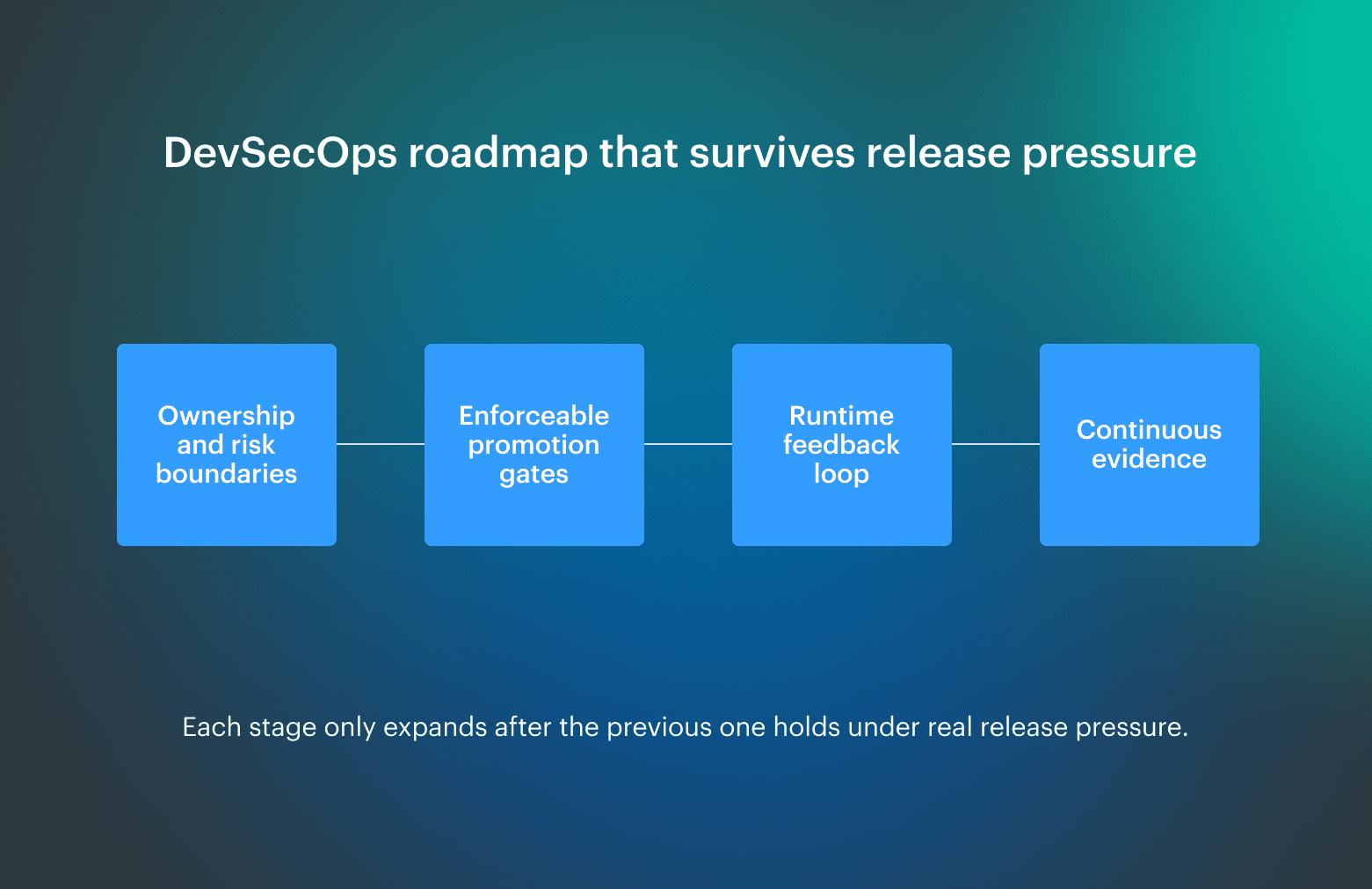
Step 1. Define ownership and risk boundaries
Start by assigning explicit risk ownership per service or workload, because without a named owner, every failed gate turns into a Slack discussion instead of an enforced decision. Teams also need to agree on what is production-blocking versus acceptable risk, so promotion gates reflect real tolerance rather than informal precedent.
Step 2. Instrument the pipeline with enforceable controls
Next, attach controls to concrete promotion gates in CI and CD, where some checks hard-block progression, and others emit signals for triage. Mature teams are deliberate about this split because treating every finding as blocking quickly leads to bypasses, waivers, and broken trust in the pipeline.
Step 3. Integrate runtime security feedback
Runtime signals such as configuration drift, exposed services, and incident patterns must feed back into pipeline policy; the same classes of issues reappear release after release. Fixing production symptoms without updating delivery rules leaves the system blind to its own failures.
Step 4. Establish continuous evidence for audits
Finally, decisions and gate outcomes are logged as evidence at execution time, which keeps the system audit-ready without turning audits into manual evidence collection. This reflects continuous authorization practices, where approval is an ongoing state rather than a periodic event.
Read also: 15 DevSecOps Tools - Software Features & Pricing Review
DevSecOps implementation checklist
This checklist is for teams who already run CI/CD and keep hearing that DevSecOps is “mostly in place,” while releases still rely on judgment calls and late exceptions. It reflects the gaps practitioners consistently call out when implementations look complete but fail under pressure.
- A minimal security baseline is defined and enforced, instead of trying to cover every possible risk from day one, because teams that skip a baseline usually end up with controls everywhere and authority nowhere
- Risk ownership is explicit per service, so blocking decisions and exceptions do not bounce between the platform, app, and security teams during a release
- Production-blocking conditions are narrow and intentional, which prevents pipelines from being overloaded with gates that teams learn to bypass
- Failed gates cannot be silently overridden, and exceptions are time-bound and visible. A useful signal here is
bypass_rate = bypassed_blocks / blocked_promotions. If this stays high, enforcement exists only on paper - Runtime incidents and drift feed back into delivery rules, because fixing issues only in production without updating the pipeline guarantees repetition
- Decisions are recorded as evidence at execution time, not reconstructed later.
evidence_latency = time_evidence_available - time_decision_madeshould be near zero, or audits will remain manual
If this checklist exposes gaps, it usually means the baseline was never enforced consistently. The safest next step is to pick one release path, enforce a minimal set of blocking rules there, and expand only after the system behaves predictably under real release pressure.
DevSecOps audit checklist and requirements
Audits surface DevSecOps gaps quickly because they force teams to explain not only what controls exist, but whether those controls are applied consistently under normal delivery pressure. When explanations rely on screenshots, Slack threads, or memory, the issue is rarely missing security and almost always missing structure.
DevSecOps audit checklist
Use this checklist to verify whether the delivery system can explain its own decisions:
- Release decisions are traceable to promotion gates and policy rules, so auditors can follow a change from commit to production without manual correlation.
- Blocking behavior is consistent, meaning similar changes produce similar outcomes across environments, instead of one-off exceptions.
- Exceptions are rare and time-bound, typically representing a small percentage of releases rather than becoming a parallel approval path.
- Policy changes are versioned, so teams can show when a rule changed and which releases were affected.
- Incidents map back to approved decisions, allowing teams to explain why a change was allowed and what rule will change next time.
- Evidence is available immediately, not assembled during the audit window.
Continuous audit requirements
Continuous audits depend on evidence produced as part of delivery:
- Evidence latency is near zero, meaning decisions are logged when they occur, not hours or days later.
- Policy evaluations are retained, so teams can answer audit questions without re-running scans.
- Configuration and asset changes are tracked continuously, not sampled periodically.
- Runtime signals update delivery rules, reducing repeat findings over time.
When these conditions hold, audits validate system behavior instead of interrupting delivery.
How to implement AI in DevSecOps safely
Among teams that are using AI in DevSecOps today, the pattern that holds up best is using it to reduce cognitive load without letting it become a decision authority, because the fastest way to lose trust in a delivery system is when a model quietly starts influencing what ships. That’s why guidance like the NIST AI Risk Management Framework keeps coming back to explainability, governance, and drift, especially when AI output affects operational flow.
What’s working in practice is applying AI to assessment rather than approval. Teams use it to cluster findings, correlate signals across tools, or summarize evidence that already exists, while keeping release decisions deterministic. This is broadly consistent with how regulated environments approach automation under U.S. DOD authorization guidance, where assessment can scale, but approval remains rule-based and auditable.
The most troubles come when AI is placed directly in the enforcement path without clear boundaries. Models hallucinate, inherit bias, and drift as inputs change, which lines up closely with failure modes described in the OWASP Top 10 for LLM Applications and echoed repeatedly in practitioner discussions. Once a pipeline blocks “because the model said so,” trust drops and bypasses usually follow.
Read also: DevSecOps Framework in 2026 - How to Choose the Right One
Measuring DevSecOps implementation success
DevSecOps implementation starts to work when teams can tell whether delivery decisions are actually improving outcomes, because without shared signals, success quickly turns into opinion. Most teams already track activity, but what matters here is whether security decisions reduce recovery time, prevent repeat failures, and keep production behavior aligned with intent.
The metrics below reflect what experienced DevSecOps teams watch once the basics are in place, focusing on system behavior rather than tool output.
- MTTR vs MTTP. Mean Time To Remediate shows how fast teams fix issues, while Mean Time To Prevent indicates whether delivery rules are learning from those fixes. When MTTR improves but MTTP does not, the pipeline is reacting, not adapting.
- Policy violations over time. This measures whether the number of violations triggered by the same rules is trending down. A flat or rising line usually means enforcement exists, but thresholds or ownership are misaligned.
- Repeat incident rate. Repeated incidents tied to similar causes signal that runtime feedback is not changing delivery decisions. When this drops, the system is actually learning.
- Drift frequency. This tracks how often the runtime configuration diverges from the approved intent. High drift frequency indicates enforcement gaps between delivery and runtime.
Across practitioner talks and Reddit threads, the same outcomes show up when DevSecOps implementation is working:
- MTTR improves first, but repeat incidents drop later, once runtime feedback updates delivery rules.
- Policy violations initially spike, then decline as thresholds and ownership stabilize.
- Drift frequency drops sharply once enforcement moves closer to promotion and runtime.
- Audits shift from document reviews to spot checks of live systems.
One consistent takeaway from experienced teams is that metrics only become meaningful after baseline enforcement is in place. Before that, numbers mostly reflect noise, tooling differences, or reporting gaps rather than real improvement.
How Cloudaware supports DevSecOps implementation (without replacing your tools)
Cloudaware supports DevSecOps at the point where many teams stall, after a baseline exists, but enforcement, ownership, and evidence start to drift. It acts as:
- System of record. Cloudaware maintains a continuously updated inventory of real cloud and hybrid assets, so DevSecOps decisions are made based on what actually exists in prod.
- Context layer for enforcement. Through automated asset discovery and relationship mapping, Cloudaware connects services, environments, accounts, and ownership to keep policy enforcement accurate.
- Policy enforcement support. Policies are evaluated against a live asset context, so enforcement applies consistently across pipelines and runtime.
- Audit backbone. With historical change tracking, Cloudaware records who changed what, when, and where, allowing teams to trace runtime behavior back to approved intent.