






You know what they say — FinOps lifecycle is just three tidy stages: Inform, Optimize, Operate. But let me tell you, in real life? It’s more like trying to untangle 400 GCP tags, a surprise Azure invoice, and a cost anomaly alert… all before your second coffee.
In theory, it's clean. In practice, it’s overlapping chaos — cloud architects buried in untagged S3 buckets, finance chasing phantom Kubernetes costs, and DevOps folks dodging commitment planning like it’s radioactive.
You don’t move through these phases. You loop, you backtrack, you firefight. And that’s exactly why I wrote this article — to lay out what really works at scale.
Inside 👇
- Pro tips for each of FinOps phases
- Operate stage done right (finally)
- Who owns what, and when
- Metrics that actually matter
- Cloud-aware cost reporting (not just dashboards)
- Common mistakes, and how to dodge them
But first, let’s check if we are on the same page about the definition.
What is the FinOps lifecycle
If you’re still at the stage of clarifying FinOps meaning for stakeholders, start with the basics before mapping your work to the FinOps lifecycle.
At its core, the FinOps lifecycle is a framework for managing cloud cost in a way that’s collaborative, transparent, and actually scalable. It breaks down into three official phases: Inform, Optimize, and Operate.
Sounds clean, right?
Now here’s what really happens when you try to apply it in the wild.
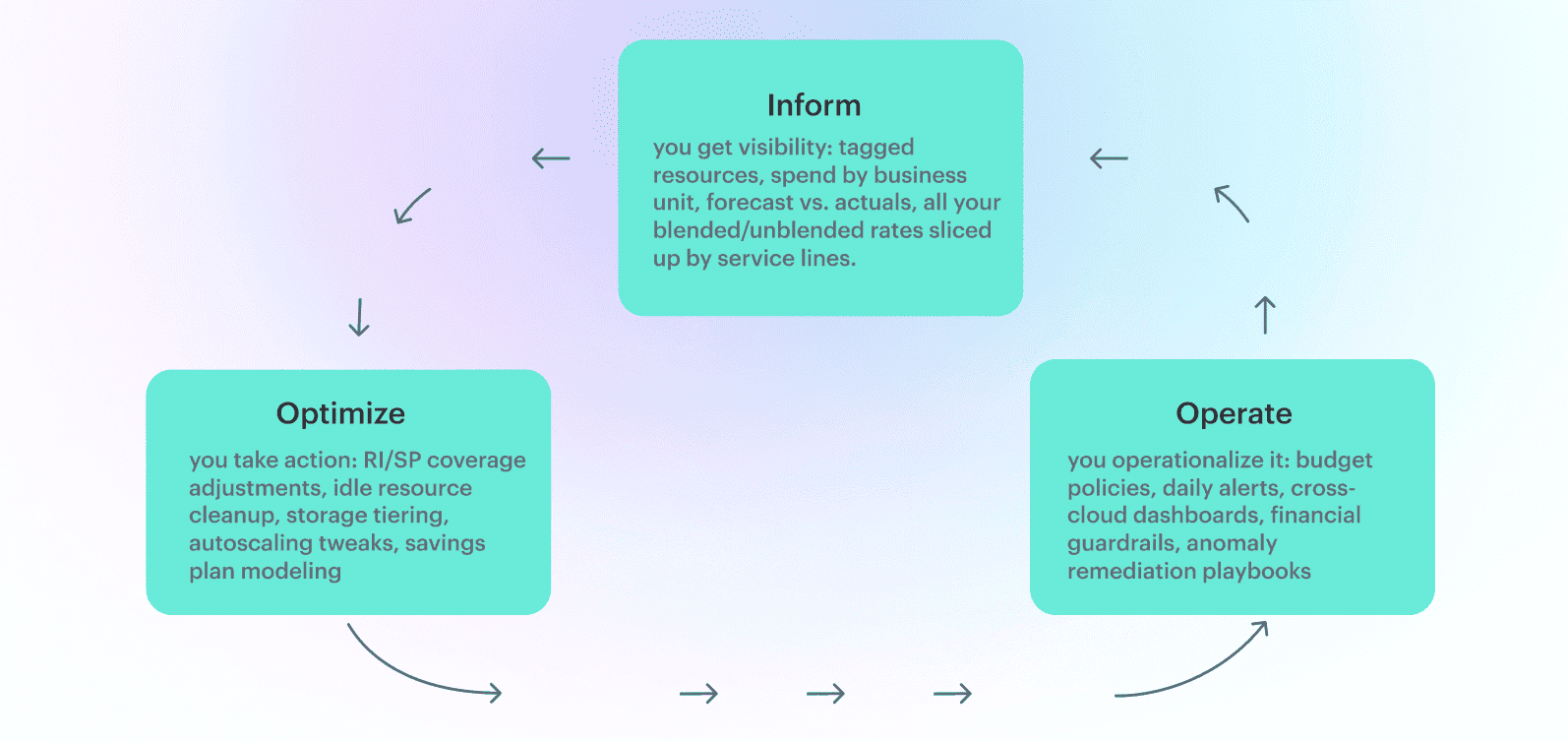
- In Inform, you get visibility: tagged resources, spend by business unit, forecast vs. actuals, all your blended/unblended rates sliced up by service lines.
- In Optimize, you take action: RI/SP coverage adjustments, detect unexpected spikes, underutilized commitments, upcoming expirations, idle resource cleanup, storage tiering, autoscaling tweaks, savings plan modeling.
- In Operate, you operationalize it: budget policies, daily alerts, cross-cloud dashboards, financial guardrails, anomaly remediation playbooks.
But here's the kicker — these stages aren’t sequential. They're layered, tangled, and triggered out of sync depending on which team’s looking at the numbers. That’s the messy reality of most FinOps activities.
Here is a real case on how it works from our client Caterpillar:
They run apps across AWS, Azure, and some legacy services in an on-prem OpenStack cluster. Over 1,300 cloud accounts. Their Inform phase was handled by a part-time financial analyst pulling CUR and Azure EA data into Excel every Friday. Devs didn’t tag anything. Kubernetes costs? Black hole.
So we rolled out Cloudaware. In two weeks, we had tagging reports across environments, RI/SP coverage metrics by region, and daily emails showing idle EBS volumes, over-provisioned RDS, and unused VMs.
Then we hit Optimize — but guess what? The Ops team had a Terraform pipeline that recreated inefficient configurations every night. So we synced FinOps alerts with their GitHub Actions to block PRs violating cost policies.
In Operate, we built a weekly cadence: Slack alerts for overspend thresholds, exec dashboards for product leads, and a financial guardrail workflow where anything over 20% budget deviation triggered a Jira ticket and a FinOps review.
No one “completed” the FinOps lifecycle. It evolved. And that’s the point. You don’t finish FinOps — you build muscle around it.
Let’s dive into the details of the first phase.
Inform phase: from “where’s our money going?” to “show me the ROI”
It is the part of the FinOps cycle where everyone’s asking the same question: “Where’s our money going?” But what they really mean is: “Why does this invoice look like a slot machine exploded in my inbox?”
This is the foundation of all your FinOps activities — it’s where visibility turns into power. You’re not optimizing anything yet. You’re mapping the chaos. It’s digging through CUR files, Microsoft Azure billing exports, GCP billing exports, and stitching it all together into something a CFO and a DevOps lead can both understand without starting a teams war.
At this stage, the organization the goal isn’t cost savings. It’s clarity. That sweet “a-ha” moment when you can finally say, “Here’s what we’re spending, here’s who’s spending it, and here’s what it’s tied to.”
The main tasks of the Inform phase (and why they matter):
1️⃣ Establish granular visibility. We’re talking full resource-level spend breakdowns — not just by service, but by business unit, app name, environment, even cost center. You need proper tagging, and not just random keys.
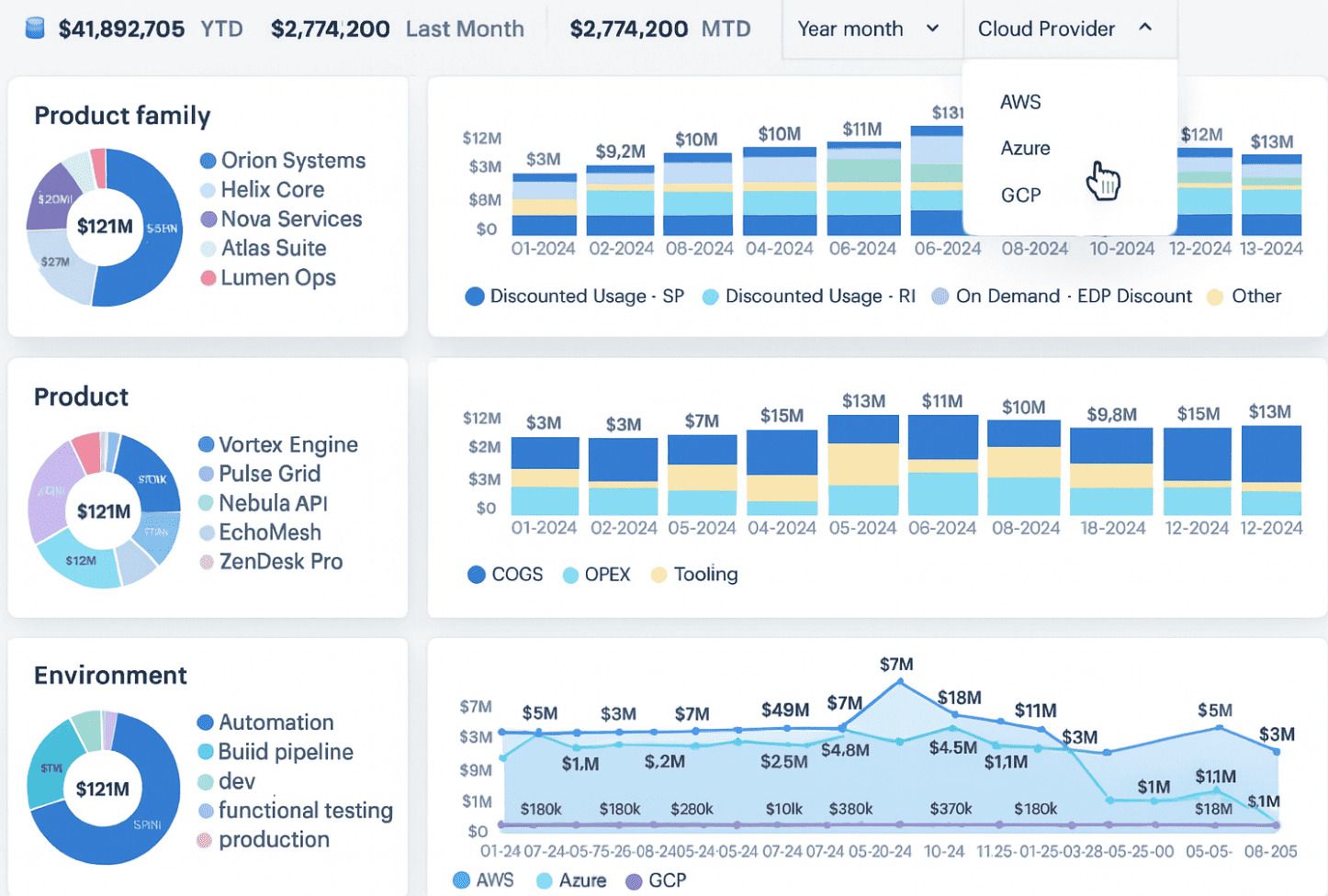
FinOps dashboard in Cloudaware. Schedule demo to see it live.
Think: Project, Owner, Environment, ApplicationTier. On GCP, enforce instance-name tagging. On AWS, use SCPs to block untagged deployments. On Azure? Don’t rely on Resource Groups alone — they’re not always cost-isolated.
2️⃣ Accurate cost allocation. Blended vs unblended cost matters a lot when you’re dealing with shared resources, cross-charged infra, and dev/test workloads spun up and forgotten. The Inform phase sets up showback and chargeback models that make sense.
FinOps dashboard in Cloudaware. Schedule demo to see it live.
3️⃣ Forecasting & budgeting baseline. You can’t forecast future spend until you know what normal looks like. Here, you’re building historical models — 30/60/90-day run rates per product, infra type, team, and provider. You're also aligning those with committed spend plans like AWS EDPs, Azure RIs, and Google CUDs. And don’t forget seasonality.
FinOps dashboard in Cloudaware. Schedule demo to see it live.
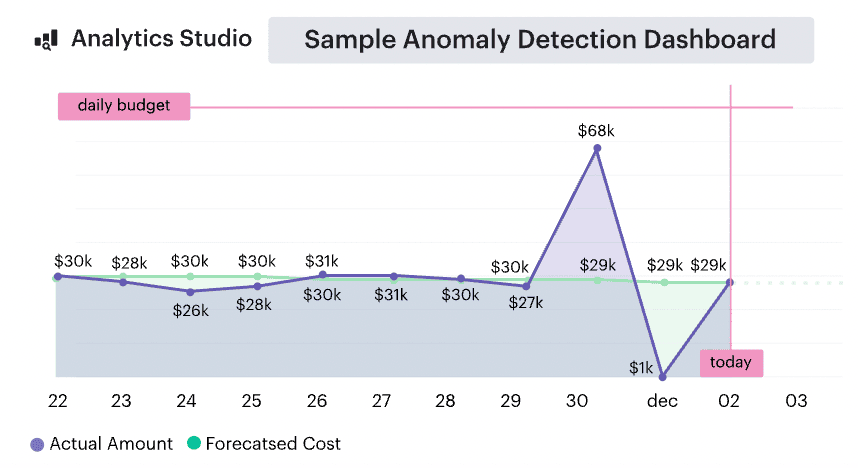
One client had huge GPU burst spend in Q4 for ML model training. If that’s not factored in? Your forecast’s toast.
4️⃣ Benchmarking. This isn’t just external (“what’s a normal EC2 cost per vCPU?”). It’s internal. How does Team Alpha’s Kubernetes cluster efficiency compare to Team Beta’s? What’s your average RI utilization rate by region? Inform is when you surface this and hand teams the mirror.
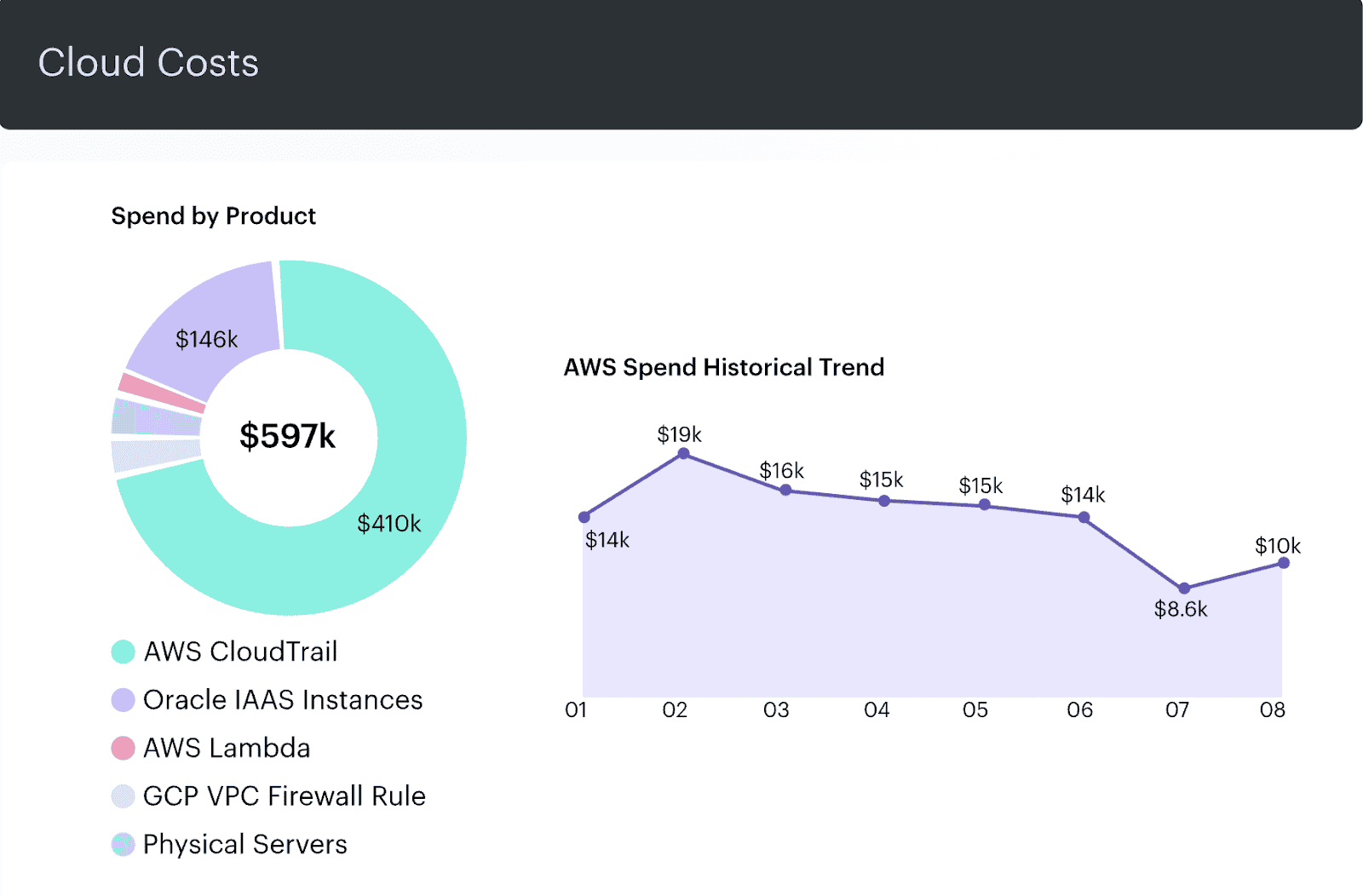
FinOps historical spend dashboard in Cloudaware. Schedule demo to see it live.
5️⃣ Alerting on anomalies. You’re not reacting yet — that’s Optimize’s job. But you’re setting the stage with anomaly detection: unexpected cost spikes, tagging drift, RI/SP underutilization, new unallocated SKUs. These alerts aren’t just noise — they’re your early warning system.
So yeah, Inform isn’t sexy. But it’s everything. It turns billing noise into a narrative.
And when done right, it’s the moment when your CTO stops asking “What are we paying for?” and starts saying “Show me the ROI.”
Metrics that matter
If you can’t measure it, you can’t manage it… and if you can’t explain it, good luck getting budget approval.
When you’re deep in the trenches of FinOps activities, especially in a multi-cloud monster of a setup, these five metrics aren’t just numbers — they’re the pulse check of your cloud cost sanity. I've seen them transform shouting matches into strategy sessions.
- % of Tag Coverage (Critical Tags Only). We’re not aiming for “every resource tagged” — that’s unrealistic. But if 92% of your spend isn’t covered by
Environment,BusinessUnit, andApplicationtags, you’ve got fog where there should be floodlights.
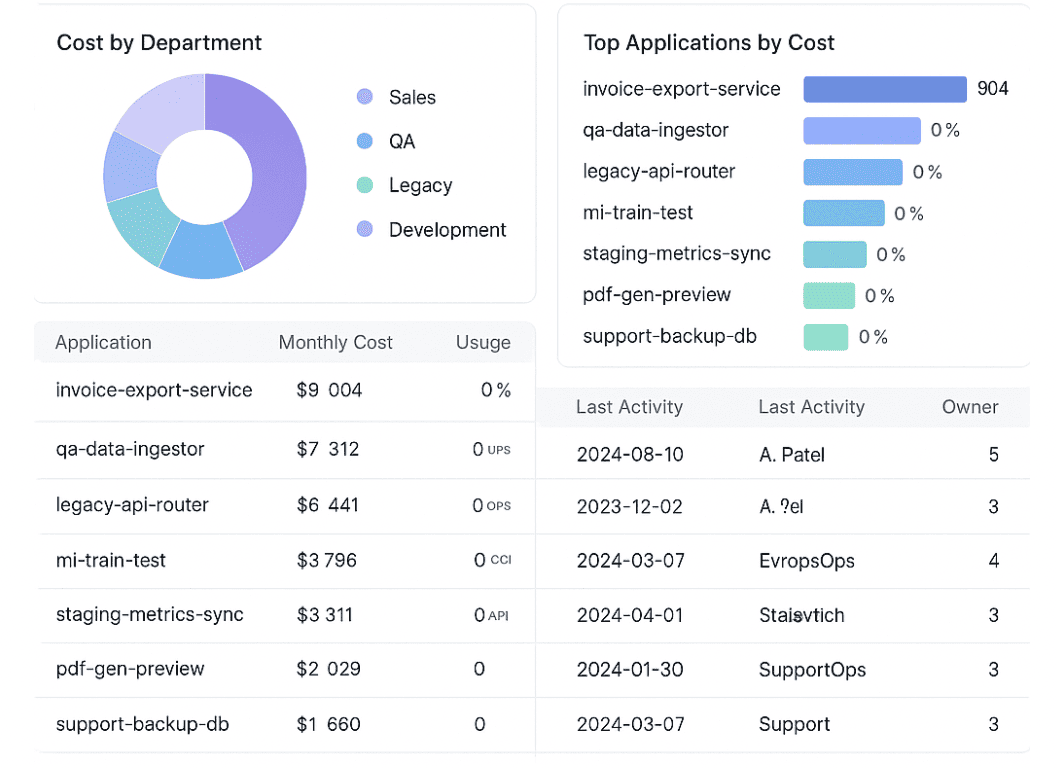
You can’t allocate, optimize, or alert on what you can’t attribute. This number tells you if your entire FinOps foundation is leaking before you even start. - % of Allocated Spend. Tagging alone isn’t enough. Are you actually pushing shared costs to the right owners? Think shared S3 buckets, Kubernetes node pools, NAT gateways, RDS clusters — they live in no-man’s land until you set up allocation logic. Cloudaware’s CMDB relationship mapping helps here, auto-assigning those shared services by service tier or pod annotations.
- Forecast Accuracy (Actual vs Planned). You’re comparing your predicted spend (based on prior usage, commitments, scaling patterns) to actuals. This requires RI/SP commitment amortization logic baked in — otherwise, your forecast will be permanently off.
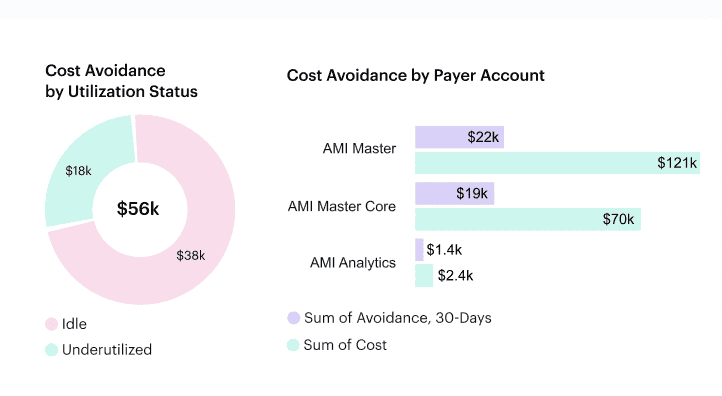
Bonus points if you calculate accuracy per team. One client had a 4% variance company-wide, but DevOps was off by 28%. Why? They were scaling new GKE workloads weekly without telling FinOps. We only saw it in hindsight. - % of Unused or Orphaned Resources. You’re not optimizing yet, but this is your early red flag metric. Cloudaware’s waste detection caught 84 unattached EBS volumes across 3 accounts — idle for 15+ days, tagged to “sandbox” but billing under prod’s budget. Not actionable yet, but it went straight to the cleanup backlog.
- Tag Drift Rate. Tags decay. People mistype. IaC templates evolve. Teams clone old configs. Tag drift tracks how fast and where your tagging compliance slips. It’s especially granularly when you scale horizontally — new accounts spun up without guardrails, new projects launched from old Terraform modules. I set up a weekly tag drift report that showed three new projects launched in Azure without
CostCenterorEnvironment. Why? Their ARM templates skipped the tagging block entirely.
3 Mistakes that break the inform phase (and what to do instead)
These are the three biggest mistakes I’ve seen during the Inform phase of the FinOps lifecycle — the kind that quietly snowball into budget blowouts, executive escalations, and 2AM dashboard freakouts. I asked my favorite FinOps friends to spill the tea — and here’s what they had to say:
The tagging illusion
Technical Account Manager Iurii Khokhriakov:
“We thought we had tagging figured out — until I tried pulling a cost report for just ‘prod’ workloads and got 17 different tag variations. The finance team just gave up.
The mistake? Assuming tags exist = tagging is usable. In reality, every team had their own version of env, product, and owner, and none of it was enforced. Our dashboards were unreadable, our chargebacks meaningless.
Here’s how we fixed it: We defined a strict tag policy across AWS, Azure, and GCP — same keys, same casing. Then we built guardrails: AWS SCPs, Azure Policies, GCP org constraints. We hooked Terraform into pre-commit checks to block any deploys missing critical tags like CostCenter or ServiceOwner.
Cloudaware provided a full tag coverage dashboard across all accounts — showing where we were missing data and where naming drift had crept in. Now, tagging is owned, tracked, and baked into CI. It’s part of the culture — not an afterthought.”
Infra takes the fall
“We kept seeing 80% of our cloud cost tied to ‘Infra’. At first, we thought we were massively overprovisioning. Then we realized: all untagged resources — shared NATs, RDS clusters, security tools — were defaulting to our team by design.
The mistake? No allocation logic. Just dumping everything unassigned into one account. Which meant no one wanted to clean it up, because no one saw the cost tied to their app.
Here’s what we did: We mapped out shared services in our CMDB and used Cloudaware’s related items to trace actual usage. Then we applied weighted allocation — based on request volume, attached pods, or number of dependent apps — and split costs across consuming teams.
For Finance, we started publishing a “Shared Infra Breakdown” dashboard. That one chart turned Infra from the scapegoat into the enabler. Everyone sees their slice now — and surprise, people started optimizing.”
Read also: One IT Asset Management Guide to Rule Your Hybrid Cloud Setup
Forecasting by vibe
Anna, ITAM expert at Cloudaware:
“Our Q1 forecast missed by $140K. Why? GCP launched a GPU-heavy ML training workload. Azure RIs lapsed mid-month. And no one flagged either until the invoices landed.
The mistake? Forecasting based on hope, not historical data. We were using flat projections instead of actual usage curves. No seasonality. No commit timelines.
The fix? First, we pulled 90-day trends from CUR, Azure EA, and GCP billing exports. Then, we added commitment layers — amortized RIs, EDP obligations, and upcoming SP renewals. We synced that with our CMDB so we could tie forecast segments to specific app workloads.
We tagged burst workloads (Type=ML_Training) and reviewed historical volatility by service. Our forecast model finally started reflecting reality — not just finance theory. Now we revisit forecast vs actual monthly and tweak based on what's spinning up, what’s ramping down, and what got forgotten. No more surprises.”
Seen one of these in your own cost reports? You’re not alone. These mistakes happen quietly — until they don’t. But once you see them, you can fix them fast, and take control of your FinOps activities from the ground up.
Optimize phase: now that you know, fix it
This is the part of the FinOps lifecycle where teams stop admiring the problem and actually fix it. You’ve got your spend visibility, your tags are mostly behaving, your dashboards finally make sense… now what?
Now you act.
This phase is about turning insight into savings — operational, automated, and repeatable. We’re not budgeting here. We’re engineering.
Here’s what goes down in Optimize phase:
- Rightsize or retire what’s bloated. Dig into your EC2, GCE, and Azure VM usage. Are those instances running at 12% CPU for weeks? Kill 'em or downsize.
Use Cloudaware's rightsizing dashboards, or plug into native tools like AWS Compute Optimizer and Azure Advisor. And don’t forget: overprovisioned storage (hello unattached EBS and premium disks) is just as bad. - Commit strategically. Reserved Instances, Savings Plans, CUDs — great discounts, but they’ll bite if you miscalculate. Track coverage and utilization by region, family, and lifecycle stage. I’ve seen teams lose six figures by renewing RIs with no workload left behind.
- Automate the boring stuff. Why wait for someone to act on an alert when you can auto-shrink non-prod clusters at night? Schedule cleanup jobs. Trigger policies from Cloudaware or your orchestration layer. Reduce manual effort — increase financial efficiency.
- Tune your tagging and policies. Tag everything new correctly. Lock down drift with CI/CD checks. And update your cost guardrails — what was “acceptable” spend last quarter might be waste now.
Read also: Multi-Cloud Cost Optimization Assessment Playbook
Metrics to track at this phase
It’s not enough to just do the work. You’ve got to prove it. And that means tracking the right signals, not just whatever your cloud provider throws in a report.
This is where your dashboards start speaking the language of impact — not just cost.
Here’s what I always keep an eye on:
- Rightsizing ratio. How much of your compute/storage footprint is actually being used vs what’s provisioned? Start by pulling utilization data from Cloudaware’s dashboards or native tools like Compute Optimizer and Azure Advisor. Then calculate how many resources are running at <40% usage over 7+ days. That’s your baseline bloat.
- RI/SP/CUD coverage and utilization. Coverage = how much of your steady-state workload is protected by commitments. Utilization = how efficiently you're using what you bought. Track it by account, region, instance family, and term length.
- Automation coverage. Which optimization actions are automated (like stopping idle VMs at night) vs still manual? I always tag automated policies and track % of monthly savings. If it’s under 50%, you’ve got ops debt.
- Waste detection delta. You’ve got financial waste policies in place — great. But are they catching less over time? Use Cloudaware’s waste detection history: measure monthly potential savings trends. If it’s flat, your org isn’t adapting fast enough.
- Optimization ROI. The golden metric. Take all FinOps-driven savings and divide it by total engineering hours or effort cost to get there. If your FinOps playbook isn’t profitable on its own, it’s just another cost center.
Read also: Choose an ideal ITAM software: Top 15 asset management tools
Typical mistakes companies do at Optimize phase
Mistake #1: Buying Commitments Without Guardrails
Anna, ITAM expert at Cloudaware:
“One client renewed $300K worth of 3-year EC2 RIs based on last quarter’s usage… then migrated half their workloads to containers. Their coverage looked great on paper — until the infrastructure shifted under their feet.
The mistake? No alignment between purchase decisions and infra roadmap. Finance approved the commit, but engineering never saw the plan.
Here’s the fix: We built a joint RI/SP planning board inside Cloudaware, tied to environment tags and CI/CD data. Now they track coverage by instance family, region, and lifecycle stage — and only commit when workloads are pinned long-term. We also send pre-expiry alerts to cost owners 30 days in advance.
And we made a rule: no commit purchases without a sign-off from both Infra and FinOps. Governance meets savings.”
Mistake #2: Manual Optimization at Scale
Mikhail Malamud Cloudaware GM:
“They had over 800 AWS accounts and were still rightsizing by spreadsheet. They’d get reports on idle EBS or oversized instances — then email the owners, hoping someone would take action. Two months later? Nothing changed.
The issue? Manual processes don’t scale. Optimization wasn’t operationalized — it was wishful thinking.
We helped them trigger automated actions from Cloudaware’s compliance policies. Idle disks get flagged and deleted after a 10-day window. Underutilized EC2s are auto-downgraded unless exempt.
And we linked their cost alerts to Slack and Jira — so engineers stopped ignoring emails and started treating FinOps like part of their release flow.”
Mistake #3: Optimizing Without Context
Kristina, Seniour ITAM expert at Clodaware:
“They downsized everything aggressively — even production workloads that needed buffer for traffic spikes. One team got blamed for a revenue dip when their autoscaling group couldn’t catch up.
The root issue? No cost-performance balance. They optimized based on CPU stats, not business impact.
Here’s how we fixed it: We enriched Cloudaware’s rightsizing data with metadata from the CMDB — app tier, environment, SLA tags. Now non-prod gets aggressive savings policies, but prod workloads get headroom baked in.
And we added rollback triggers. If response time or error rate crosses a threshold post-change, optimization actions are reversed.
It’s not about cutting cost. It’s about cutting the right cost.”
These mistakes are everywhere — but with the right visibility, logic, and tooling, the Optimize phase becomes less firefighting, more foresight. Want to tackle the Operate phase next? That’s where the real FinOps discipline kicks in.
Operate phase: where most FinOps initiatives stall
This is the part of the FinOps lifecycle phases that nobody warns you about until you’re already in the middle of it, wondering why your clean dashboards didn’t magically stop the chaos.
Because this is it. This is the part where all that visibility and optimization work? It either becomes a system… or it fades into PowerPoint oblivion.
Operate is where FinOps framework gets real. It’s not about cool dashboards or a perfect tagging policy — it’s about what actually happens on a Tuesday when costs spike and no one knows why.
It’s the everyday flow — the weekly reviews, the Slack alerts that actually get read, the Jira tickets that trigger without someone chasing them. It’s the moment your org stops being reactive and starts running FinOps like it runs infrastructure — built-in, not bolted on.
And honestly? When it works, it feels like peace. No last-minute budget freakouts. No mystery charges. Just rhythm.
What companies actually doing in FinOps operate phase
- Weekly rituals. Set up your FinOps cadence — weekly or biweekly. Go over RI/SP usage, untagged resources, forecast vs actual, and anomalies. The right people in the room. Everyone leaves with actions. Keep it short, keep it sharp.
- Guardrails that bite. Use tools like Cloudaware to define your thresholds — “anything over 15% variance triggers a flag,” “idle VMs get deleted after 7 days,” that kind of thing. And make those policies do stuff, not just raise eyebrows.
- Real-time alerts that land. Slack, Jira, email — whatever your teams use, plug cost alerts straight into it. So if 42 EBS volumes get spun up overnight with no tags, the right team sees it before the invoice drops.
- Living playbooks. Write down what happens when stuff breaks — “cost anomaly in staging,” “forecast busted,” “commit expiring in 10 days.” Make the response part of muscle memory, not a meeting.
- Continuous feedback. Check what worked, what didn’t. If your autoscaling policy just saved $9K — log it. If your forecast missed by 30%, fix the logic. Operate is where we learn and tighten the loop.
So yeah, Operate isn’t shiny. It’s not what people brag about. But it’s the phase that makes FinOps stick.
It’s the difference between “Hey, we fixed that cost issue” and “Wait… didn’t we fix this last quarter?”
Operate Phase Metrics That Actually Mean Something
- Forecast Accuracy (%). This is your credibility metric. How close was your projected spend to reality — by team, service, or environment? If you said AWS would be $110K and it came in at $148K, that’s not a rounding error — that’s a broken loop. Track forecast vs actual monthly, flag variances >15%, and tie it to commit coverage and spend anomalies. Cloudaware lets you visualize this by product line, not just by cloud account.
- Alert-to-Action SLA. You raised a cost anomaly alert. Cool. Now how long did it take someone to respond and resolve it? This metric shows how FinOps operational you really are. Set internal SLAs — say, 24 hours for prod, 72 for staging — and track median response time by team. Cloudaware’s compliance policies + Slack/Jira hooks make this visible and actionable.
- RI/SP/CUD Utilization Trends. It’s not enough to have coverage. You want to know how efficiently you’re using it over time. Track this weekly by region, instance family, and service. Look for flat or dipping utilization curves — that’s your early warning to reassign capacity or pause future commitments.
- Policy Violation Rate. How many workloads are breaching your cost guardrails? Track how often things get flagged for:
- Unattached volumes beyond policy window
- Missing
CostCenterorOwnertags - Spend over threshold without approval
Low violation count = maturity. High violation count = visibility gap. Use Cloudaware’s policy engine to generate this as a report you can review in every FinOps sync. - % Tagged Spend. Tags are great, but only if they’re tied to actual spend. Track what % of your monthly bill is fully tagged and allocated to a team, app, or environment. If 25% of your Azure or GCP spend is still “unallocated” — you’ve got decisions being made without context.
- Anomaly Resolution Rate. How many alerts are noise vs how many were legit and resolved? Tune your detection logic over time to minimize alert fatigue. If 80% of anomalies lead to action, you’re golden. If most get ignored, your logic or thresholds need love.
- Optimization Rollback Rate. Yup — even in Operate, we’re still optimizing. But if every second rightsizing action leads to app breakage, something’s off. Track rollback incidents tied to CPU/memory tuning, disk downgrades, or scheduling policies. It helps you balance cost savings with system stability.
That’s the heartbeat of Operate: fast signal, smart action, tight loop. You’re not just tracking cloud costs. You’re watching how your org handles pressure, decisions, and change.
And honestly? Once these metrics are in place, you stop chasing problems — and start steering the whole damn ship.
3 common operate phase mistakes (and how to catch them early)
By the time you hit Operate, things should be humming. But here’s the truth: this phase is where most teams quietly stall. Not because they lack tooling, but because habits don’t stick and accountability drifts. These quotes from my Cloudaware crew are here to show you what really breaks down — and how to build it back stronger.
Mistake #1: Dashboards with no follow-through
Iurii Khokhriakov, Technical Account Manager at Cloudaware:
“They had five dashboards tracking every cost metric imaginable… but no one owned the actions. Spend anomalies stayed open for weeks — costing them $15K in avoidable overages in a single quarter.
The issue? Operate wasn’t operational — it was observational.
We set up ownership inside Cloudaware:
- Cost center owners got weekly reports via Slack
- Tag compliance issues turned into Jira tickets
- Policy violations triggered alerts with auto-assignees
Dashboards became workflows. Not just charts.”
🚩 Trigger: If your FinOps dashboard has >10 unresolved cost anomalies older than 7 days — you’re stalled.
Fix-it Checklist:
- Route Cloudaware alerts to Slack/Jira by
CostCenter - Assign policy owners by tag (
Owner,Product) - Review open issues weekly in FinOps sync
- Track closure rate over time
Mistake #2: No escalation path for anomalies within lifecycle phases
Daria, ITAM expert at Cloudaware:
“One team saw a 300% GCP spend spike over the weekend. The alert fired — but landed in a shared inbox. Nobody saw it until Monday. By then, $40K had evaporated.
The mistake? Alerts without urgency logic.
We configured Cloudaware’s compliance engine to:
- Route alerts by
Environmenttag - Auto-prioritize: prod → PagerDuty, staging → Jira, non-critical → email
- Track alert-to-resolution SLA by team
Now spikes don’t get missed — they get managed.”
🚩 Trigger: If alerts land in one inbox and rely on manual triage — your risk exposure is high.
Fix-it Checklist:
- Tag workloads by environment:
prod,stage,sandbox - Build Cloudaware alert rules by tag + dollar impact
- Integrate with Slack and incident systems
- Set SLA thresholds for response time
Mistake #3: Static policies in a dynamic org
Anna, ITAM expert at Cloudaware:
“A financial team within an organization I had a demo recently had a $500/day spend policy… which made sense when they were smaller. But they launched 3 AI training workloads, entered new regions, and guess what? The same policy flagged every new project as a fire. People stopped paying attention.
The issue? Policy drift — FinOps rules weren’t keeping pace with infra evolution.
We used Cloudaware to build dynamic guardrails:
- Thresholds scaled by service type and cost history
- Tags like
ProjectPhase=experimentalauto-adjusted alert levels - Policies reviewed monthly in a cost governance sync
Result? Teams trusted alerts again. And acted faster.”
🚩 Trigger: If alerts feel noisy or false-positive-prone — your thresholds are out of sync.
Fix-it checklist:
- Create dynamic Cloudaware policies using fields data like
Tag,DailySpend,ServiceName - Optimize thresholds quarterly based on past resources usage
- Add a policy review block to your monthly FinOps rhythm
- Provide your teams with an opportunity to monitor alert resolution rate to detect alert fatigue
Who owns what in FinOps lifecycle?
Here’s the real persona map I use when helping teams untangle the spaghetti — with Cloudaware as the backbone, tags as the glue, and clear accountability as the non-negotiable.
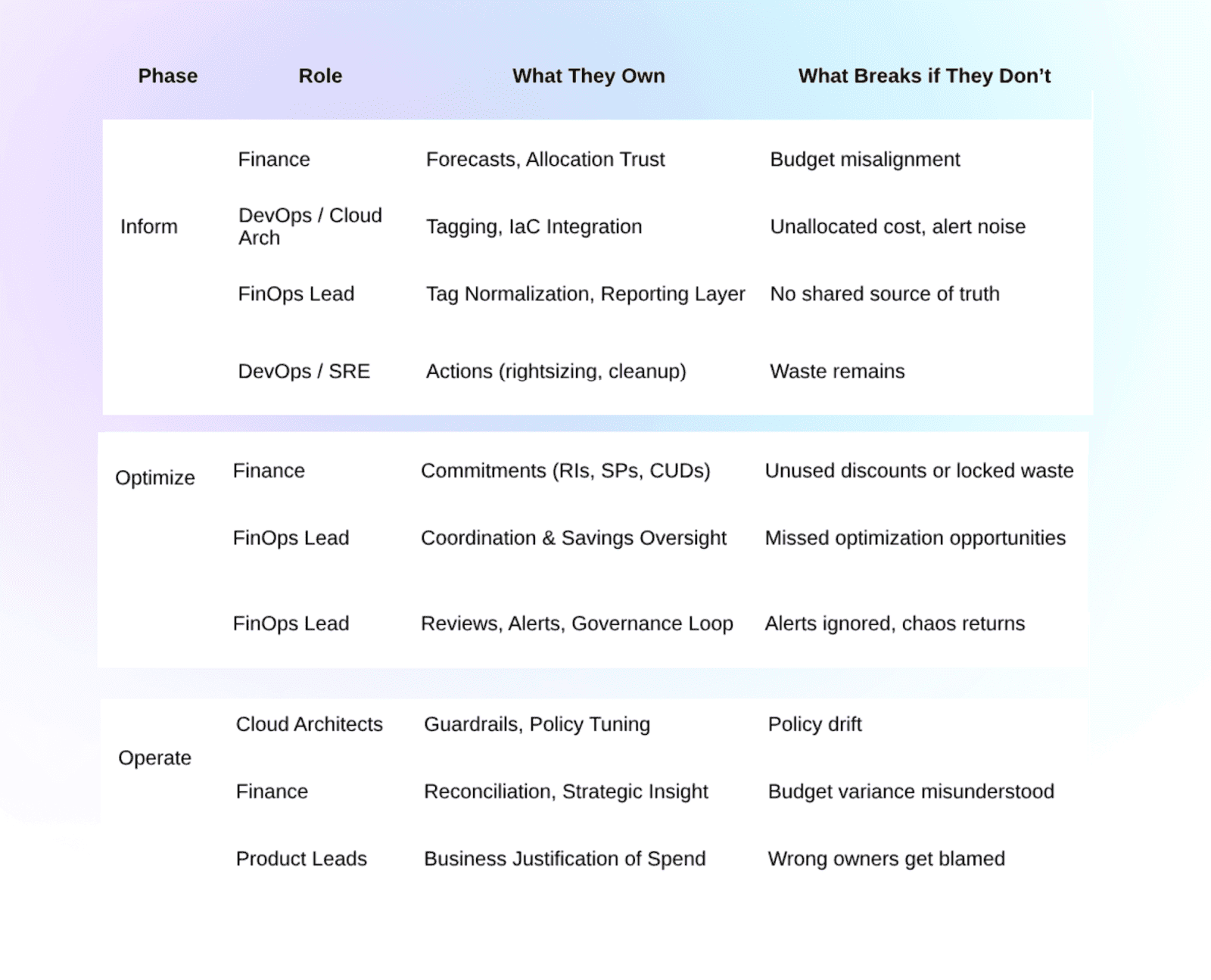
Inform Phase — Visibility & Trust
Okay, so this is where things should be simple — just get the data, tag your stuff, and show Finance where the money’s going. But oh no, here’s where the drama starts.
Finance
They own the forecasts and margin models. But if they don’t trust the numbers coming from DevOps? It all falls apart.
“Why is half our AWS bill unallocated?”
Cue panic and spreadsheets.
Fix it: Sync your tags with Finance’s budget codes (CostCenter, Project, etc.). And for the love of all things SaaS, let them look at the actual Cloudaware dashboards — not filtered Excel exports someone manually updates every Friday night.
DevOps / Cloud Architects
These folks spin up infra at lightning speed. But if they’re not embedding tags at deploy time, that’s how you get $30K in “unknown” GCP spend.
“We’ll tag it later” = famous last words.
Fix it: Build tagging into your Terraform modules. Use Cloudaware policies to block untagged stuff from hitting prod. Make tagging automatic, so no one ends up playing tag cop.
FinOps Lead
This poor soul’s stuck translating tech data for Finance and simplifying finance language for Dev.
DevOps says, “This is too basic.” Finance says, “This is too technical.” Classic.
Fix it: Create dashboard layers in Cloudaware — one for Finance (forecast, blended/unblended), one for Engineering (utilization, idle), and one shared space to track untagged chaos.
Optimize Phase — Action & Alignment
Here’s where things get spicy. You’ve got visibility, now it’s time to take action — but everyone’s scared to touch prod or commit to savings.
DevOps / SRE
They're told “optimize costs,” but don’t want to break production. Can you blame them?
Fix it: Classify by environment tag (prod, stage, dev). In Cloudaware, apply policies based on risk level. Give them rollback-safe automations so they can breathe.
Finance
They’re managing SPs, RIs, and CUDs — locking in discounts like heroes.
Problem is, they’re doing it based on last quarter’s usage... and guess what? Infra moved everything to containers last week.
Fix it: Bring Finance and Infra into the same commitment planning call. Use Cloudaware to compare actual vs committed usage before clicking "purchase."
FinOps Lead
They’re expected to deliver savings, but have zero authority to make changes.
No power, just responsibility — love that for us.
Fix it: Tie Cloudaware compliance policies to actual tags and owners. Let FinOps fire the alert, but make Product or Dev approve the fix via Jira. Shared ownership, baby.
Operate Phase — Governance & Accountability
This is where FinOps either becomes a habit… or a graveyard of dashboards no one looks at anymore.
FinOps Lead
They keep the rhythm: alerts, weekly reviews, escalations. But if no one closes the loop? You’re back in firefighting mode.
“Wait, wasn’t this flagged last month too?”
Fix it: Cloudaware can auto-create Jira tickets for every policy violation, route them by ServiceOwner, and track who actually closes the loop. Weekly review or it didn’t happen.
Cloud Architects / Platform Owners
They own the guardrails, but if they don’t tune them as infra evolves, things get noisy fast.
“Why are we getting 47 false alerts a day?” Because your policy still thinks it’s 2022.
Fix it: Review policies quarterly. Let Cloudaware flag outdated rules and help you rebuild based on current SKUs, tags, and service types.
Finance
They tell the story — actuals vs budget, strategic spend. But if they don’t know what triggered that GCP GPU spike, they’re left guessing.
“Was this a mistake or a launch?”
Fix it: Add tags like App, ProjectPhase, BusinessUnit to infra. Let FinOps or Product annotate anomalies in Cloudaware, so Finance gets narrative, not noise.
Product / Engineering Leads
They’re supposed to own the “why” behind workloads. But when cost spikes hit and everything points at Infra?
Surprise: it was an ML experiment pushed to prod with zero tagging.
Fix it: Enforce Owner and Product tags. Cloudaware groups spend by business unit and sends weekly spend digests — so no one can pretend they “didn’t know.”
Read also: Top 13 Cloud Monitoring Tools Review - Pros/Cons, Features & Price
Bonus: Weekly FinOps Ops Call Template
It’s not just a status update — it’s your cost-control cockpit. It’s where billing chaos gets context, idle resources get called out, and commitments get sanity-checked before they blow up next month’s margin.
If you do it right, this call becomes your ritual. The heartbeat of your FinOps rhythm.
Here’s exactly how I run it with my crew — engineers, cloud architects, finance leads, and product owners — across multi-cloud chaos, tag gaps, and RI regret.
How to prepare
Before the call, make sure:
- Your Cloudaware dashboards are updated (daily billing + policy sync is working)
- The Forecast vs Actual report is filtered by
BusinessUnitandEnvironment - Your top policy violations are grouped by
Ownertag — we don’t name and shame, we clarify and assign - You’ve pulled the top 5 anomalies from Cloudaware, ideally flagged in the last 7 days, tagged, and unresolved
- All new commits (RIs, SPs, CUDs) from the past week are logged, along with upcoming renewals
What to talk about
1. What changed this week?
Start with major infra shifts:
- New regions spun up?
- New AI workloads running on GCP with GPUs?
- Any workload migration (EC2 → Fargate, VM → AKS)?
Why this matters: these shifts break commit models, spike costs, and usually bypass tag governance.
2. Forecast vs actual: variance watch
- Where did we go over or under?
- Is this seasonal, structural, or a one-time spike?
- Did any untagged resources skew the numbers?
Focus on business units or environments showing >15% variance. Flag for re-forecast or re-tag if needed.
3. Top policy violations
Review Cloudaware compliance alerts:
- Unused volumes older than 7 days
- Instances >80% idle
- Resources missing
CostCenterorOwner - Budget thresholds breached by service or team
Discuss who owns what. Reassign tags. Decide: automate, remediate, or escalate?
4. Anomaly review
- What cost spikes got flagged?
- Which ones are real, and which are just noisy alerts?
- Was anyone surprised by the bill?
Confirm alert rules are still calibrated. If not, tune detection logic based on patterns (ServiceName, Environment, time-of-day behavior).
5. Commitment coverage health
- What’s our RI/SP/CUD utilization looking like?
- Are we overcommitted in any region, family, or service type?
- Any renewals coming up in 14–30 days?
Flag anything <60% utilization — discuss reallocating or pausing future purchases. If workloads are shrinking, call it out.
6. Upcoming workloads or projects
- Any launches, POCs, or scale tests happening this month?
- Do they have tags? Budgets? Owners?
This is your chance to get ahead of unplanned spend. Tie upcoming activity to projected cost, tag requirements, and accountability.
7. Open actions + approvals
- What cost-saving actions are pending?
- Any rightsizing recommendations not yet reviewed?
- Who needs to approve auto-remediation?
Clear blockers. Log action items in Jira or your FinOps backlog. Don’t let things drift.
This call isn’t about catching people — it’s about catching patterns. The more consistent you are, the faster your team shifts from reactive to proactive. And honestly? Once everyone sees how clean this rhythm runs, they stop treating FinOps like overhead and start treating it like ops.
And here’s the tool that makes it all actually work
If you're still stitching together AWS CUR files, Azure EA exports, and GCP billing reports by hand — we need to talk. Because the deeper your cloud footprint gets, the faster the costs spiral. And the harder it becomes to answer the one question every exec eventually asks: “What are we spending, and why?”
That’s exactly why companies like Coca Cola and NASA use Cloudaware — it’s the FinOps engine I trust to keep every phase of the lifecycle tight.
It pulls in your daily cloud billing from AWS, Azure, Oracle, Alibaba, and GCP, aligns it with your tag structure, CMDB metadata, and org policies — and turns it into actual FinOps leverage.
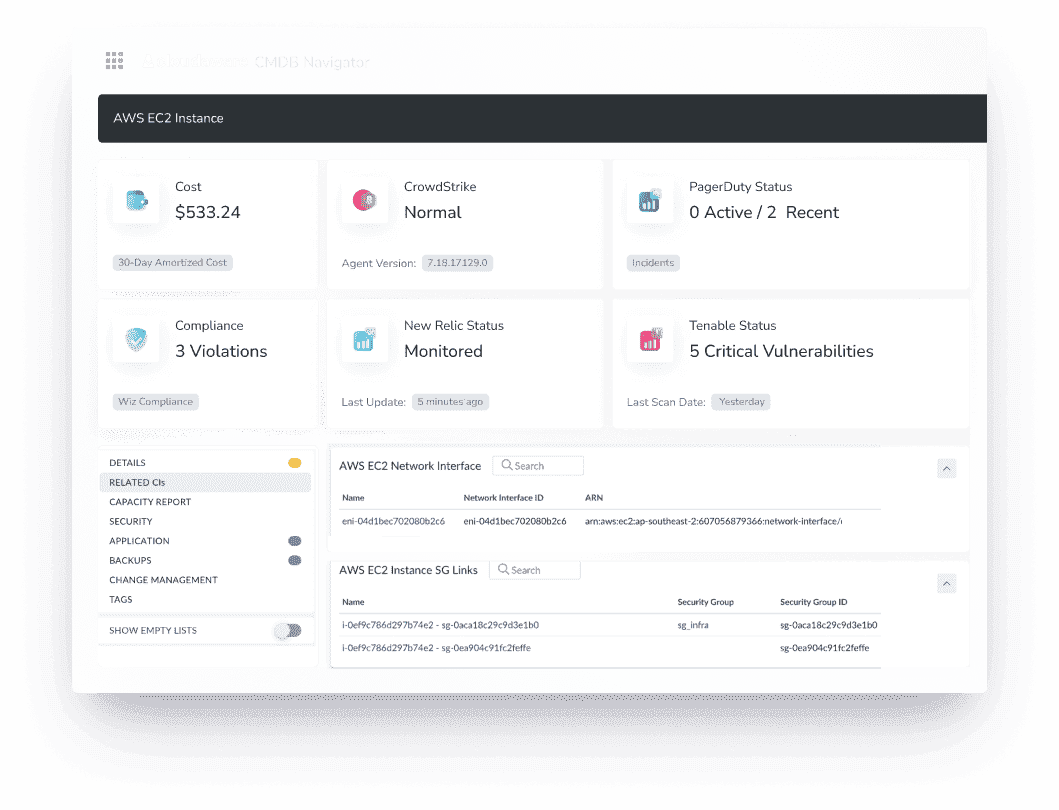
I’m talking:
- Daily cost tracking with amortized, unblended & blended views
- Waste detection policies across storage, compute, RIs, SPs, and CUDs
- Tag coverage scoring (finally, a way to show who’s skipping tagging and where)
- Forecast vs actual reports, filtered by any object within your environment
- Compliance policies with automation options — not just alerts
- Built-in workflows for Slack, Jira, and email notifications
It’s not just cost tracking — it’s cost optimization done with full financial context. And yes — it handles multi-cloud like it was born for chaos. Thousands of accounts? No problem.
If you’re serious about turning FinOps from dashboard theater into real operational impact, this is your platform.