






You open the billing dashboard and the numbers don’t add up. Finance sees one thing, engineering swears they’re under budget, and procurement is chasing discounts no one’s tracking.
That gap? That’s where money leaks.
And it’s the exact moment teams go looking for FinOps use cases they can put into play fast — because theory won’t close a $200K variance.
The truth is, every process has a breaking point. Cost allocation gets messy when tags slip. Budget management stalls when spend outpaces approvals. Anomalies appear before anyone has time to react. Forecasts drift so far off they lose credibility. Shared costs spark finger-pointing.
- So how do you turn those friction points into repeatable wins?
- When budgets crack mid-month, what guardrails actually hold?
- When anomalies land overnight, who owns the first response?
- When forecasts wobble, how do you bring Finance and Engineering back on the same page?
This article digs into exactly that.
Cost allocation: When finance can’t see who spent what
“Last month our AWS bill jumped 18% in ten days and no one could say which team did it.” On the export, prod and dev look identical. EKS node groups share the same keys, NAT gateways and Transit Gateway fees pile into “misc,” and CloudWatch/Datadog land on a central account. Over in Azure, orphaned managed disks show up without owner_email; in GCP, BigQuery storage sits under a platform project with no clear split.
Finance is staring at 26–32% unallocated and can’t finish the pack; the operations channel explodes with “who owns this?” threads; Engineering leads triage spreadsheets instead of shipping. Tag coverage hovers around 70–75% — application, environment, cost_center missing on the noisiest resources. Variance Review slips by two days, chargeback stalls, and Product can’t defend unit costs in roadmap meetings.
If you’ve ever scrambled to explain a cost spike to finance, you’re not alone.
Here is how to fix this:
- Ingest & enrich, then aim the spotlight.
Agentless connectors pull AWS CUR, Azure Cost Management, and GCP billing daily, normalize time/currency, and enrich every line with CMDB context —application__c,environment__c,owner_email__c,cost_center__c. The moment data lands, role-tuned views snap into place: Finance sees allocation accuracy and “spend at risk,” Engineering sees untagged resources by service, and FinOps gets a heatmap of where ownership breaks. - Apply one Allocation Policy, compute fair splits.
You define drivers once — requests, vCPU-hours, GB-months, egress bytes — for NAT, observability, data transfer, and other shared services. CloudAware’s engine calculates splits and reclassifies lines, so chargeback/showback mirror how the platform actually runs. - Close the loop with Salesforce-native automation.
When tags or drivers are missing, Force.com rules auto-open Jira/ServiceNow, route to the right CI/service owner from the CMDB, set SLAs, and track remediation to done. Dashboards update after each recompute, keeping Variance Review and the month-end pack current.
We keep it simple on purpose: one pipeline from raw billing → enriched context → policy math → tickets → reports. In the catalog of finops use cases, this is the foundation, and it sticks because it’s baked into your day-to-day operations as documented practices — not another side spreadsheet.
Results:
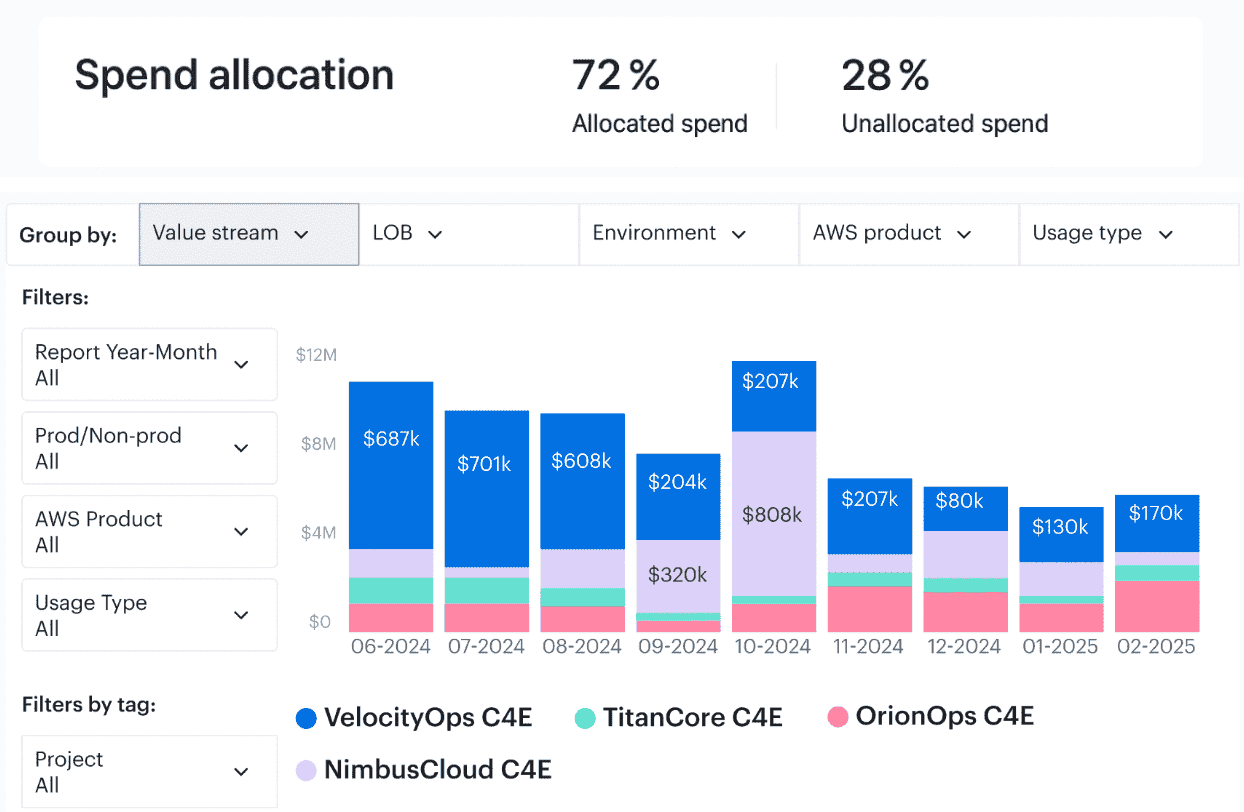
Cost allocation example in Cloudaware. See it live.
“For the first time, finance stopped challenging our numbers.” That was week six.
Allocation accuracy climbed from 68% → 93% in six weeks, and forecast variance tightened to ±10%. We reclassified ~$320K/month from “unowned” into accountable teams and uncovered ~$120K/year in duplicate/idle resources — without touching production.
Finance closed 1–2 days faster with chargeback that stuck; Engineering cut budget-dispute time by ~50% and focused on fixes instead of finger-pointing. Product got feature-level unit costs to back roadmap calls. At the business level: steadier spend, cleaner margins, fewer surprises.
The new normal is predictable: nightly recomputes, tickets that route themselves, and one clean allocation pack for month-end — automation practices embedded into everyday operations.
Read also: 7 Best Cost Allocation Software 2025 - Tools, Features & Pricing
Cloud cost optimization: When cloud spend grows faster than budgets
By day 12 of the sprint, on-demand compute is up 22% and nothing in the roadmap explains it. AWS Auto Scaling Groups never scaled back; m6i.xlarge nodes sit at 8–12% CPU; a db.r6g.2xlarge hums overnight with five connections. In Azure, managed disks linger unattached after a migration. Over in GCP, the nightly BigQuery job jumps from 2 TB → 14 TB scanned because a wildcard crept into the query.
“Our AWS bill spiked 30% in two weeks and no one could say why.”
“We blew 50% of the budget by the 10th.”
“Who owns these fleets?”
Finance needs a number for the variance deck this afternoon; Engineering leads are triaging incidents, not capacity; Product freezes a non-critical release. Your cloud cost curve bends up while the story behind it is a blur.
Sounds familiar?
Here’s how we fix it:
- Ingest & enrich, automatically. Agentless connectors pull AWS CUR, Azure Cost Management, and GCP billing nightly, normalize currency/time, and enrich every line with CMDB fields —
application__c,environment__c,owner_email__c,cost_center__c. Now your finops cloud view isn’t just dollars; it’s spend tied to real services and teams. - Put the right eyes on the right facts. As data lands, role-tuned views light up: FinOps sees drift by service/account and rising cloud cost run-rate; Finance gets allocation % and budget versus actuals; Engineering gets a ranked backlog of over-sized resources (CPU <10% for 7 days, idle disks, cold DB tiers) with owners resolved from the CMDB.
- Close the loop with Salesforce-native automation. Force.com rules turn findings into work: breach policies open Jira/ServiceNow against the correct CI/service, set SLAs, post to Slack/Teams, and attach the evidence (top drivers, recent changes). Daily recomputes refresh dashboards, and anomaly thresholds route straight to the accountable team — no spreadsheets, just automation.
- Make it a cadence, not a fire drill. A 30-minute weekly FinOps–Engineering review moves the backlog; month-end packs build themselves; and the runbook captures the practices (Tagging Governance, Rightsizing, Anomaly Triage, Commitment Coverage) so the motions live inside your operations, not in someone’s head.
Read also: 10 Cloud Cost Optimization Strategies From FinOps Experts
Result:
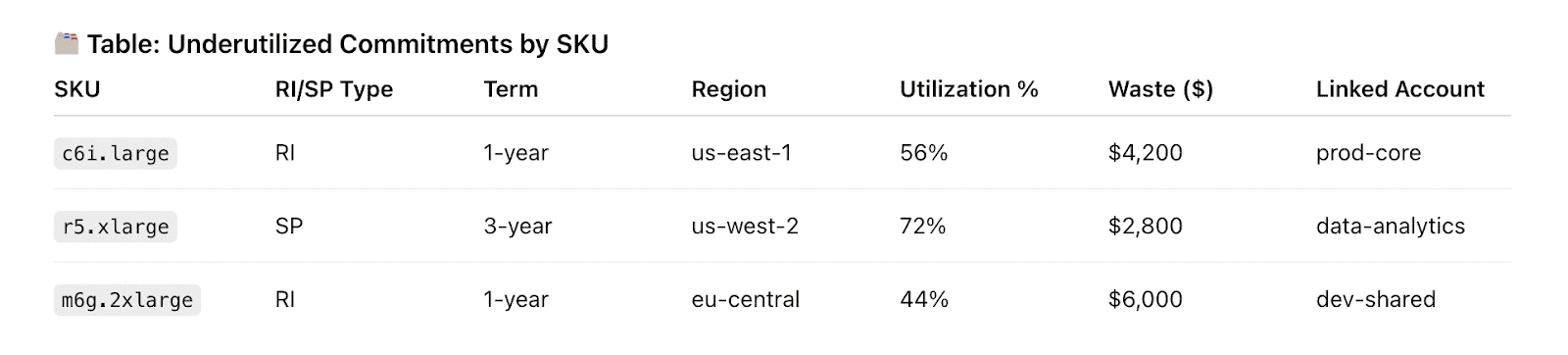
Element of the Cloudaware FinOps report about RI utilization. See it live
“For the first time, Finance stopped challenging our number — variance is ±10% and month-end is calm.” That was the FinOps lead at week eight.
On-demand compute fell 14%, total cloud cost dropped 8%, and RI/Savings Plans coverage rose 12 points with utilization above 90%. Rightsizing and idle cleanup unlocked about $120K/year without touching production resources. Finance closed 1–2 days faster, and Engineering won back roughly two sprint-days/month once ad-hoc cost chases disappeared.
Read also: Cloud Cost Optimization Framework: 11 Steps to reducing spend in 2026
Managing shared costs: When no one wants to own the bill
Close week, 3:10 p.m.: Finance is staring at 19% of last month’s costs in “misc.” NAT/Transit Gateway processing, EKS/AKS control-plane hours, Log/metrics ingestion, Azure Firewall, Front Door, and GCP Interconnect all camped in a platform account. Egress alone jumped 41% and no product P&L claims it.
“Who owns Transit Gateway on the core VPC?”
“If it’s in the platform subscription, do we split by traffic or headcount?”
“Our chargeback is dead in the water.”
Engineering leads get pinged to defend line items they never spun up. Product can’t finalize unit economics for next quarter’s bets. Finance needs a number for the variance deck in two hours. Meanwhile, Slack fills with screenshots of CSVs and half-built pivot tables trying to reverse-engineer usage drivers.
If you’ve ever watched shared costs drown out the real story, you’re not alone.
Read also: 6 Ways to (not) Fail AWS Cloud Cost Optimization in 2026
Here’s how we fix it in Cloudaware:
- Ingest & enrich, then map to reality. Agentless connectors pull AWS CUR, Azure Cost Management, and GCP billing nightly, normalize time/currency, and enrich each line with CMDB fields (
application__c,environment__c,owner_email__c,cost_center__c). Platform accounts and services are bound to actual owners so shared costs stop floating. - Apply one policy; compute fair splits. You define the Allocation Policy once, with drivers that mirror how the platform works — requests for gateways, vCPU-hours for control planes, GB-months for storage, egress bytes for transfer. Where billing lacks a metric, we use documented proxies. Splits are calculated from real usage and posted back to your allocation views and chargeback.
- Put the right eyes on the right view. Role-tuned dashboards light up as soon as recomputes finish: finops sees split health and drift by service/account, Finance sees allocated totals with variance impact, Engineering gets per-service chargeback linked to the owning CI so the next action is obvious.
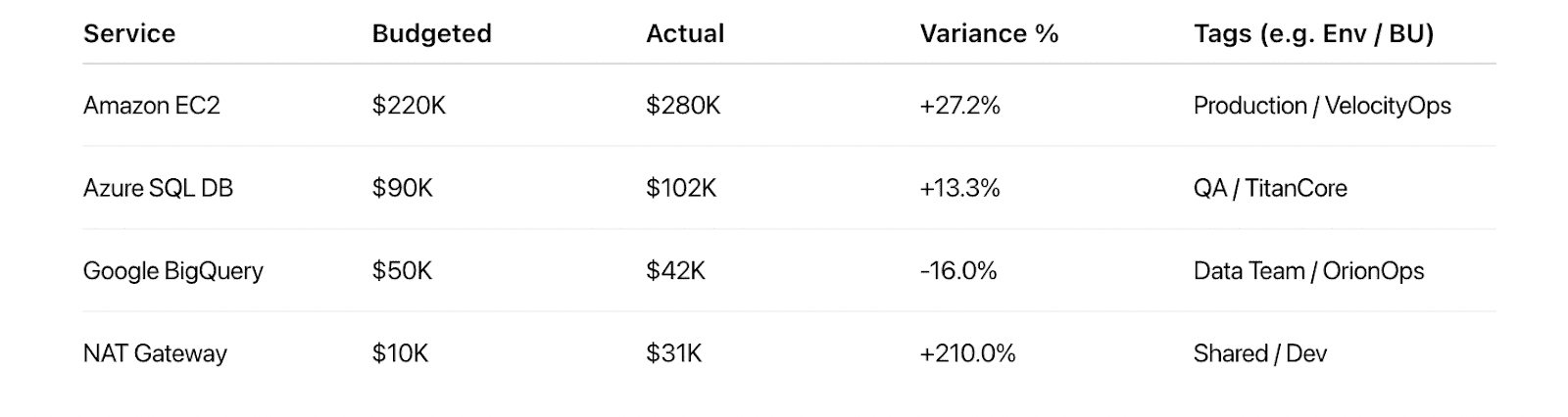
Variance of Budgeted vs. Actual Spend report in Cloudaware. See it live
- Close the loop with Salesforce-native automation. Force.com rules open Jira/ServiceNow when drivers or tags are missing, route to the correct owner from the CMDB, set SLAs, post to Slack/Teams, and track to done. Nightly recomputes refresh reports so your numbers move in lockstep with the underlying costs.
- Make it a cadence, not a scramble. A 15-minute weekly Allocation Review and a month-end close playbook keep the policy live inside normal spend management — no side spreadsheets, no last-minute heroics, just a documented flow the team follows.
Read also: FinOps Maturity Model. 7 Expert Moves You Can Steal
Budget management: When teams burn through budgets halfway into the month
“By the 12th, half the budget’s gone.” The exports back it up: AWS autoscale never dialed down after launch, a pile of Azure managed disks stuck around post-sprint, and one GCP BigQuery job quietly doubled scans. Finance sees a mid-month blowout and can’t wrap Variance Review; Engineering leads keep fielding “who owns this?”; Product parks non-critical work until a credible number lands.
Same pattern in prod and dev — compute, storage, and egress doing most of the damage. This is one of those FinOps use cases teams tackle in the first 30 days.
Here is how to fix this:
-
Bind spend to owners. Ingest AWS CUR, Azure Cost Management, and GCP billing. Normalize in Cloudaware and map accounts/subscriptions/projects to apps, teams, and environments via the CMDB.
-
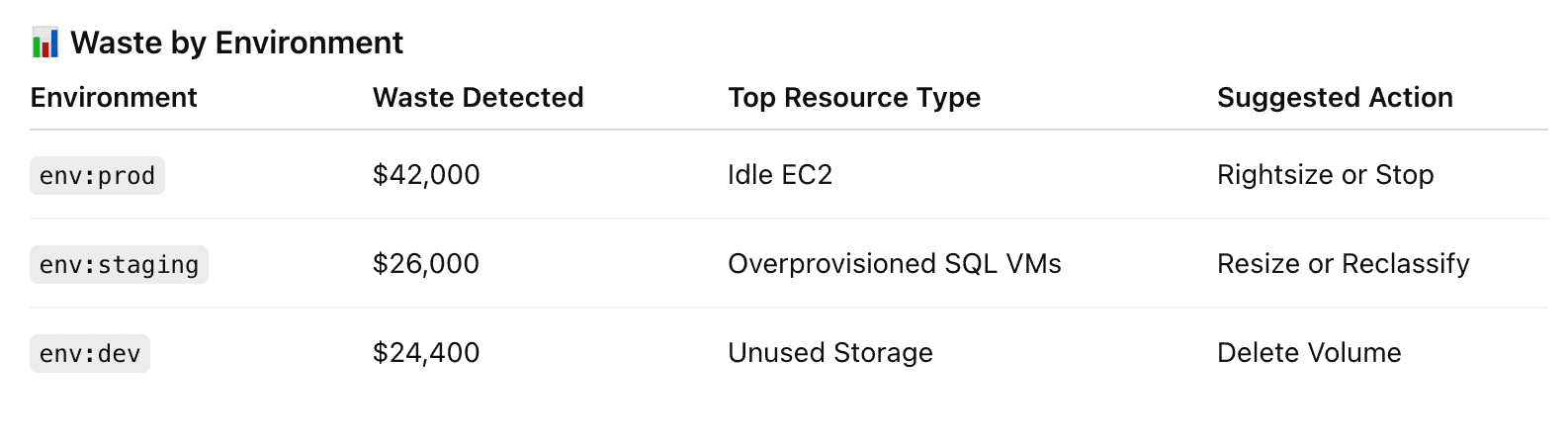
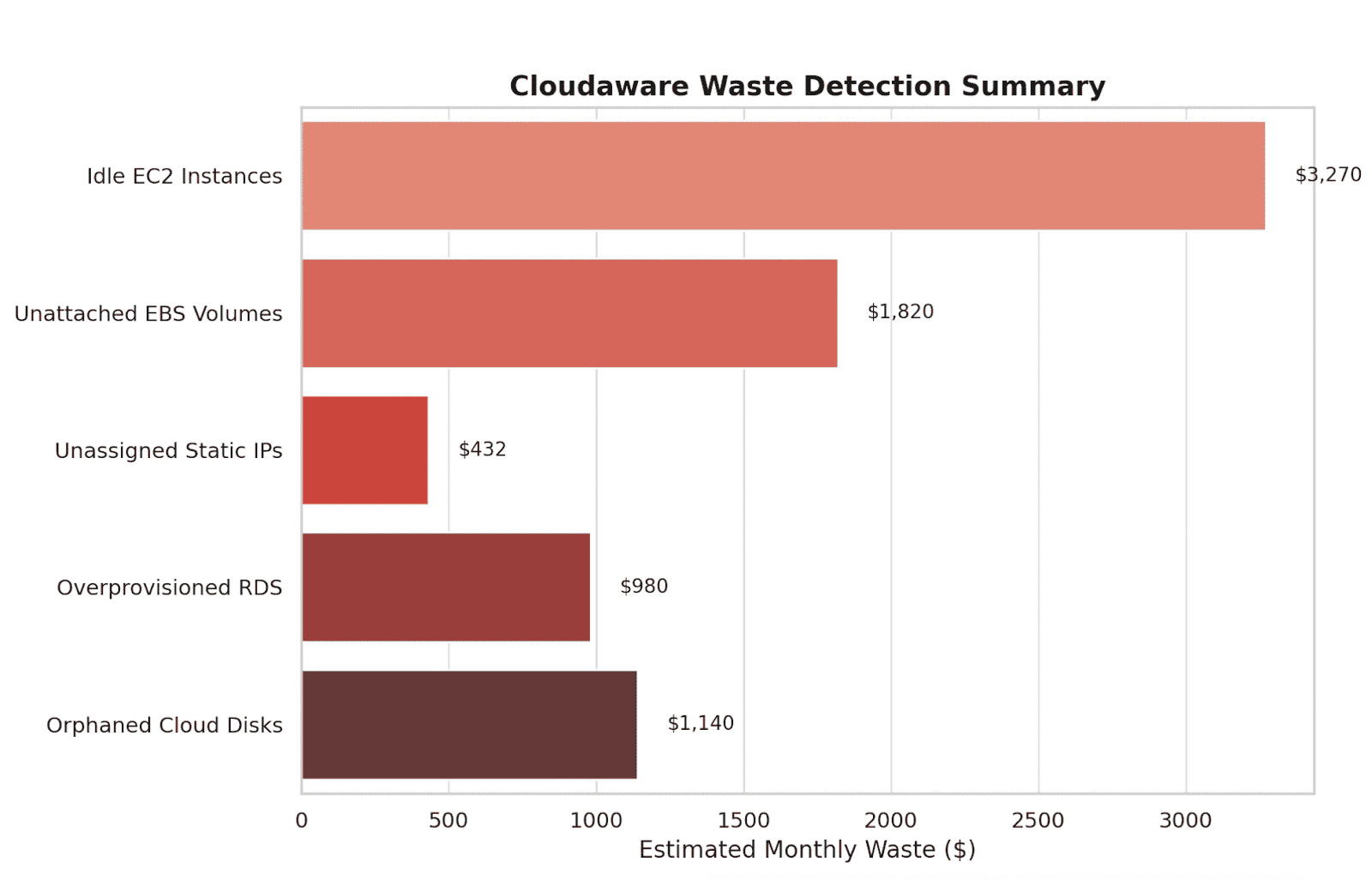
Element of the Cloudaware FinOps report. See it live
-
Set Budget Guardrails. Define rules like “burn >50% by day 10” or “projected EOM overspend >10%.” When thresholds trip, Force.com flows open Jira/ServiceNow with the owner prefilled from the CMDB, SLA set, and context attached.
-
Watch run-rate daily. Use advanced spend reports to project month-end; day-over-day deltas flag sudden drifts for quick triage.
-
Publish a Rightsizing Backlog weekly. Prioritize heavy-hitter resources first — EC2/VMs <10% CPU for 7 days, cold RDS/SQL tiers, unattached disks, and over-provisioned K8s nodes.
-
Enforce Tagging Governance. Required keys at deploy; daily conformance scans catch drift and route fixes to owners so new spend stays allocatable.
-
Mind commitments. Track RI/Savings Plans coverage and utilization; alert on dips and queue rebalance tasks so on-demand exposure doesn’t creep up.
-
Lock the cadence. Embed the rhythm into operations with a 30-minute weekly FinOps–Eng Budget Review and a month-end Forecast Reconciliation playbook.
-
Keep it visible. Alerts, ticketing, and dashboard refreshes run via automation using Force.com flows.
-
Make it stick. Codify repeatable practices in a living runbook: Tagging Governance, Rightsizing, Anomaly Triage, Commitment Coverage, and Close Procedures.
Read also: 12 Multi Cloud Management Platforms: Software Features & Pricing Review
Result:
- On-demand compute down ~12%;
- total monthly budget management impact ~7% lower spend;
- overspend incidents cut ~70%.
Forecast variance tightens from ±19% → ±10%, and Finance closes one day faster. Engineering regains ~2 sprint-days per month by avoiding ad-hoc cost chases, and Product plans with burn rates they can trust.
Workload management: When engineers scale fast but forget to scale down
This is the story my teammates hear quite often on the demo calls:
Launch week hits and the graphs look heroic — AWS Auto Scaling Groups stretch to meet traffic, Azure VM Scale Sets follow suit, and GCP Managed Instance Groups keep pace.
Then traffic cools, but the fleets don’t. Finance sees the run-rate drifting north; Engineering leads juggle incidents and never quite get to capacity hygiene; Product stalls roadmap bets while waiting for a credible number.
This use case shows up after every big push.
Idle compute resources kept humming long after the applause.
Here’s how to fix workload management:
- We normalize AWS CUR, Azure Cost Management, and GCP billing into one view, then sort by service + tag to expose over-provisioned fleets. Then, framed this as workload management and built a “Scale-Down Playbook”: rules flag ASGs/VMSS/MIGs with <10% CPU for 7 consecutive days or low p95 requests, plus clusters oversized by vCPU-hours per pod.
- The CMDB resolves owners; Cloudaware publishes a weekly “Scale-Down Backlog” with Jira tasks prefilled by team, environment, and SLA.
- Day-over-day deltas catch sudden drops that should trigger desired-count resets.
- Automation handles nightly recompute, ticket updates, and dashboard refreshes using Force.com flows. We documented practices in a living runbook — Tagging Governance, Rightsizing Policy, Anomaly Triage, Commitment Coverage — and tuned RI/SP alerts when on-demand drift rises.
- We embedded the cadence into operations with a 30-minute FinOps–Eng capacity review and a month-end “Forecast Reconciliation” checklist.
The result was predictable spend without throttling delivery:
- On-demand compute dropped ~15%, total monthly spend fell ~8%, and RI/SP utilization climbed 12 points.
- Forecast variance tightened from ±17% to ±9%.
- Finance closed a day faster, Engineering reclaimed ~2 sprint-days a month by skipping ad-hoc cost chases, and Product planned launches on capacity that actually matched reality.
Read also: AWS Cloud Cost Management: A Practical Guide
Managing anomalies: When cloud spend spikes overnight without warning
We hear the same opener all the time: “We came in this morning and the line jumped.” Overnight. In AWS prod, an S3 lifecycle tweak kicked off extra replication. In Azure, a new policy doubled Log Analytics ingestion. In GCP, a BigQuery job looped through terabytes.
Finance pings about a looming variance; Engineering is already firefighting; Product hits pause until someone can trust the number.
Here’s how we fix it in Cloudaware:
- Billing from AWS CUR, Azure Cost Management, and GCP invoices lands 4 AM, gets normalized, then is checked against baselines by account, service, and tag. Thresholds do the first pass — service spend +40% vs trailing 7-day median, unit-cost deviation +25%.
- When they trip, Force.com flows create a Jira/ServiceNow ticket, route it to the right owner from the CMDB, set an SLA, and attach an anomaly packet (top drivers, recent changes, affected services).
- Alerts speak in usage units — requests, vCPU-hours, GB scanned — so owners see the lever to pull, not just a dollar spike. Triage follows the runbook: validate tags and drivers, diff recent deployments, roll back the offender, or cap the runaway job.
- We wire it into incident management with on-call ownership, a simple severity matrix, and short RCAs that classify the driver (rate vs utilization) and queue a guardrail (budget alerts, quotas, scale policies). During cleanup, Tagging Governance protects cost allocation so showback/chargeback stays intact when lines are reclassified.
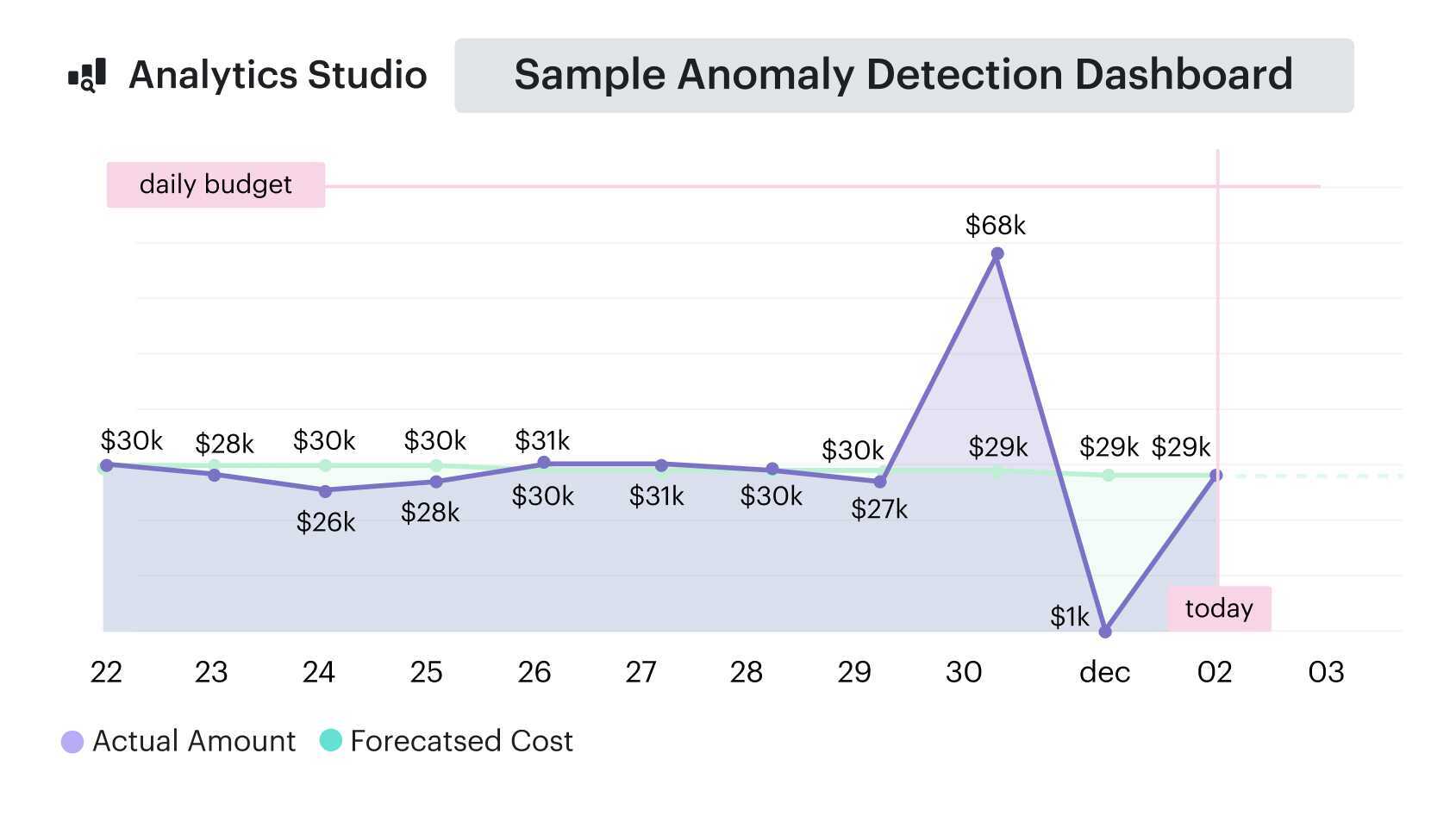
Anomaly detection report element. See it live
First month results of Cloudaware client:
- mean time to detect drops from ~12 hours to ~45 minutes;
- mean time to mitigate to ~2 hours.
One overnight incident avoided ~$28K, and monthly anomaly loss shrinks ~60%. Forecast variance tightens from ±16% to ±9%; Finance closes a day faster.
Engineering sees fewer ad-hoc pings because the alert reaches the owner with context on the first pass. Costs stop snowballing — and the process sticks — because it lives in Cloudaware dashboards, tickets, and a runbook teams actually use.
Read also: How Cloud Experts Use 6 FinOps Principles to Optimize Costs
Cloud cost rightsizing: When workloads run big but usage stays small
“We scaled for the launch…and never scaled back.” - common issue Cloudware experts hear from companies. AWS EC2 fleets cruise at Friday’s peak, a handful of Azure VMs keep their largest shapes, and one GCP job hums along like the party never ended.
Finance watches the run-rate bend north; Engineering is neck-deep in incidents instead of capacity hygiene; Product stalls a feature push waiting for a number they can trust. Oversized prod and dev, low CPU, sleepy connections — no one has ten spare minutes to dial it down.
Here’s how we fix it:
First, AWS CUR, Azure Cost Management, and GCP billing land in one normalized view and get enriched with owners via the Cloudaware CMDB (apps, teams, environments). Next comes a Rightsizing Policy:
- EC2/VMs under 10% CPU for 7 days,
- database tiers with persistently low connections,
- unattached disks and cold volumes,
- instance families out of step with observed demand.
Candidates are ranked by savings and risk. Ownership resolves from the CMDB. Then Salesforce-native Force.com flows open Jira/ServiceNow automatically — pre-filled with service, environment, and SLA — so work lands with the right team. Recommendations stay grounded in usage signals (CPU, memory, connections, IOPS), not hunches.
Cloudaware dashboards keep spend management visible by owner, environment, and service, while commitment coverage (RI/Savings Plans) is monitored so utilization dips trigger tasks before month-end.
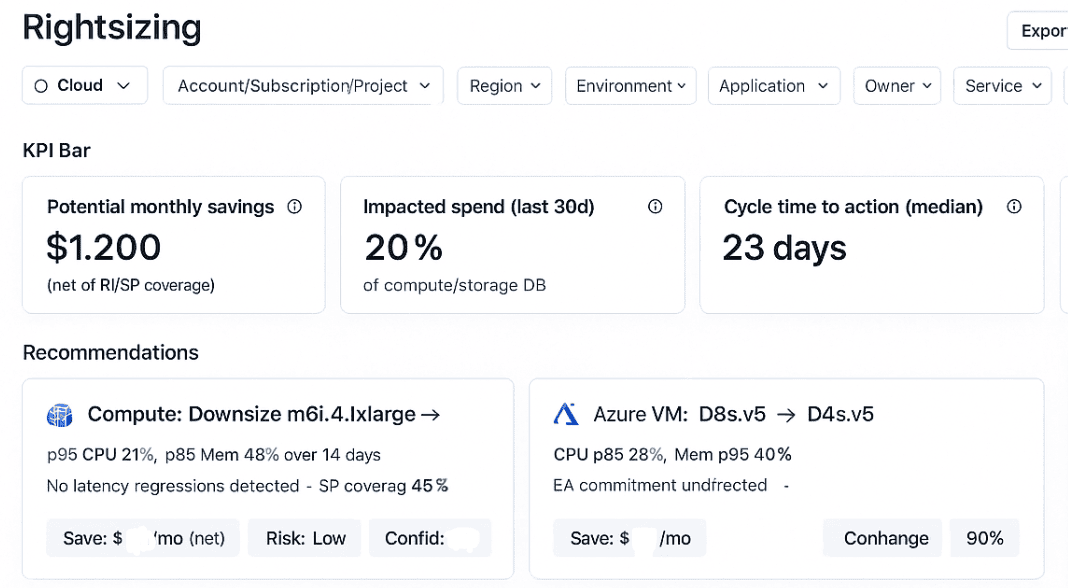
Example of the Cloudaware rightsizing dashboard. See it live
Behind the scenes, daily recalcs, ticket updates, and report refreshes run as background automation. A living runbook anchors the practices — Tagging Governance, Rightsizing, Anomaly Triage, Commitment Coverage, Forecast Reconciliation — and we wrap it in a light management cadence: a 30-minute weekly rightsizing review, sprint SLAs on fixes, and a month-end forecast check.
Two sprints later, the curve behaves. On-demand compute is down ~14%; total cloud costs drop ~8%; storage trims come from deleting idle volumes and right-tiering databases. Forecast variance tightens from ±18% to ±10%, and Finance closes a day faster. Engineering wins back ~2 sprint-days a month by skipping ad-hoc cost chases, and Product plans launches on capacity that finally matches reality.
Read also: Augmented FinOps. How the Best Teams Scale with Automation
FinOps forecasting: When next quarter’s cloud bill is a shot in the dark
The planning call starts tense. AWS just came off a peak, Azure disks linger from a migration, and a GCP pipeline quietly doubled scans. Finance needs a number for the board. Engineering isn’t confident the run-rate will hold. Product wants to lock roadmap bets without torpedoing the envelope.
Last quarter missed by double digits, so no one trusts the baseline.
If you sit in FinOps, you’ve lived this.
Here’s how we fix it:
- AWS CUR, Azure billing, and GCP invoices land in one normalized model and bind to apps, teams, and environments through the CMDB. Now you can actually separate compute, storage, data platforms, and network into service-level forecasts that map to owners.
- From there, we build a bottoms-up forecast that reflects how you operate: seasonality from release calendars and traffic events, planned changes like headcount or feature flags, and commitment levers — what RIs/SPs exist today, when they expire, and where additional coverage makes sense.
- Forecast views sit side-by-side (status quo, optimize, growth), and commitment coverage/utilization data is pulled straight into the model so the “buy/hold” calls are grounded in facts.
- Guardrails keep the plan honest. Budget alerts watch burn and drift; thresholds trigger tasks with owners and SLAs via Force.com workflows, so follow-through doesn’t rely on heroics. Weekly forecasting huddles maintain the signal, and a month-end reconciliation playbook closes the loop with Variance Review and Commitment Planning.
Example of the FinOps forecasting dashboard:
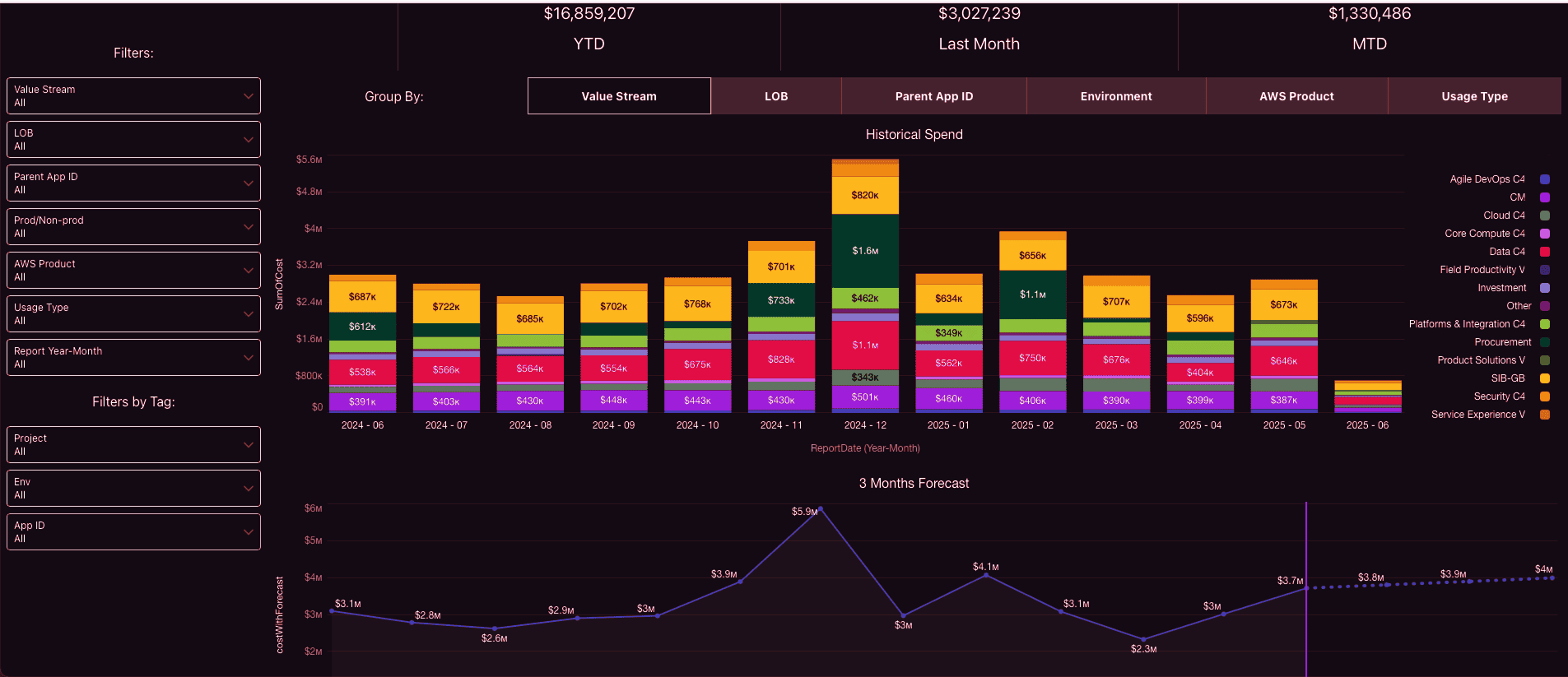
Results land quickly: variance tightens from ±18% to around ±9% within two cycles; RI/SP coverage climbs; Finance closes faster with fewer rework loops. Engineering stops firefighting numbers because the model mirrors real usage and commitments. Most importantly, costs stop blindsiding executives — the forecast is credible, and the levers to change it are visible.
Read also: Cloud Migration Costs for Enterprises: Forecasting, Risks, and Savings Controls
Policy enforcement: When tagging rules break and compliance slips
Month-end hits and the AWS/Azure/GCP exports don’t match reality. Prod and dev read the same, shared services pile into “misc,” and one in four lines arrives without application, environment, or owner_email. Finance stalls Variance Review; Engineering burns standups debating ownership; Product can’t defend unit economics for roadmap calls.
Those untagged services quietly snowball into surprise costs at close.
Here’s how we fix it:
- Start by wiring billing into context: ingest AWS CUR, Azure Cost Management, and GCP billing, then bind accounts/subscriptions to apps, teams, and environments in the Cloudaware CMDB (fields like
application__c,environment__c,owner_email__c,cost_center). - Next, make the rules explicit with a versioned Tagging Governance policy (required keys + exceptions) enforced two ways: CI/CD tag gates and daily conformance scans. Cloudaware Tagging Analysis surfaces non-compliant assets by team, environment, and dollar impact, while Allocation Policy documentation defines how shared services (NAT, observability, data transfer) are split using fair drivers.
- Routing happens automatically: Force.com flows open Jira/ServiceNow with the right owner from the CMDB, apply SLAs, post to Slack/Teams, and escalate on breach via an Escalation Matrix.
- Every rule is anchored to measurable usage signals — requests, vCPU-hours, GB-month — so fixes are obvious. Gaps show up on Showback/Chargeback and Variance Review dashboards by team and service, and the month-end Close Playbook locks in the cadence.
If you work in FinOps, you know the real win is discipline, not heroic spreadsheets. We made that discipline stick by treating it as a program: a living runbook of practices (Tagging Governance, Shared-Cost Normalization, Chargeback, Data Quality SLAs) embedded into day-to-day management with named owners and time-boxed SLAs.
Results:
Allocation accuracy moved from 66% → 95% in two sprints. Mean time to remediate non-compliant tags dropped from five days to 36 hours. Forecast variance tightened from ±20% to ±10%, and Finance closed a day sooner. Engineering cut budget-dispute interrupts by ~45%, and Product finally got feature-level baselines for roadmap trade-offs.
Among FinOps use cases, policy enforcement is the quiet unlock that keeps every downstream process honest.
Read also: How to use FinOps framework: Top 10 mistakes & their fix
Reducing idle resources: When ‘just in case’ turns into wasted spend
Launch traffic fades; leftovers linger. In AWS, EC2 test clusters don’t scale back and EBS volumes stay unattached after sprints. Azure carries managed disks long past a migration while a couple of load balancers see single-digit requests all week. GCP sandboxes keep BigQuery reservations warm for nobody. Finance flags the run-rate bend, Engineering triages incidents instead of cleanup, and Product pauses a small release until the number makes sense. If you live in FinOps, you’ve watched “temporary” quietly become “permanent.”
Here’s how to fix it:
Inside Cloudaware, AWS CUR, Azure Cost Management, and GCP billing snap to apps, teams, and environments via the CMDB. An Idle Waste Policy codifies the thresholds:
- unattached EBS/managed disks > 7 days,
- EC2/VMs < 10% CPU for 7 days,
- database tiers with near-zero connections,
- idle load balancers,
- orphaned public IPs.
Example of the dashboard on idle resources:
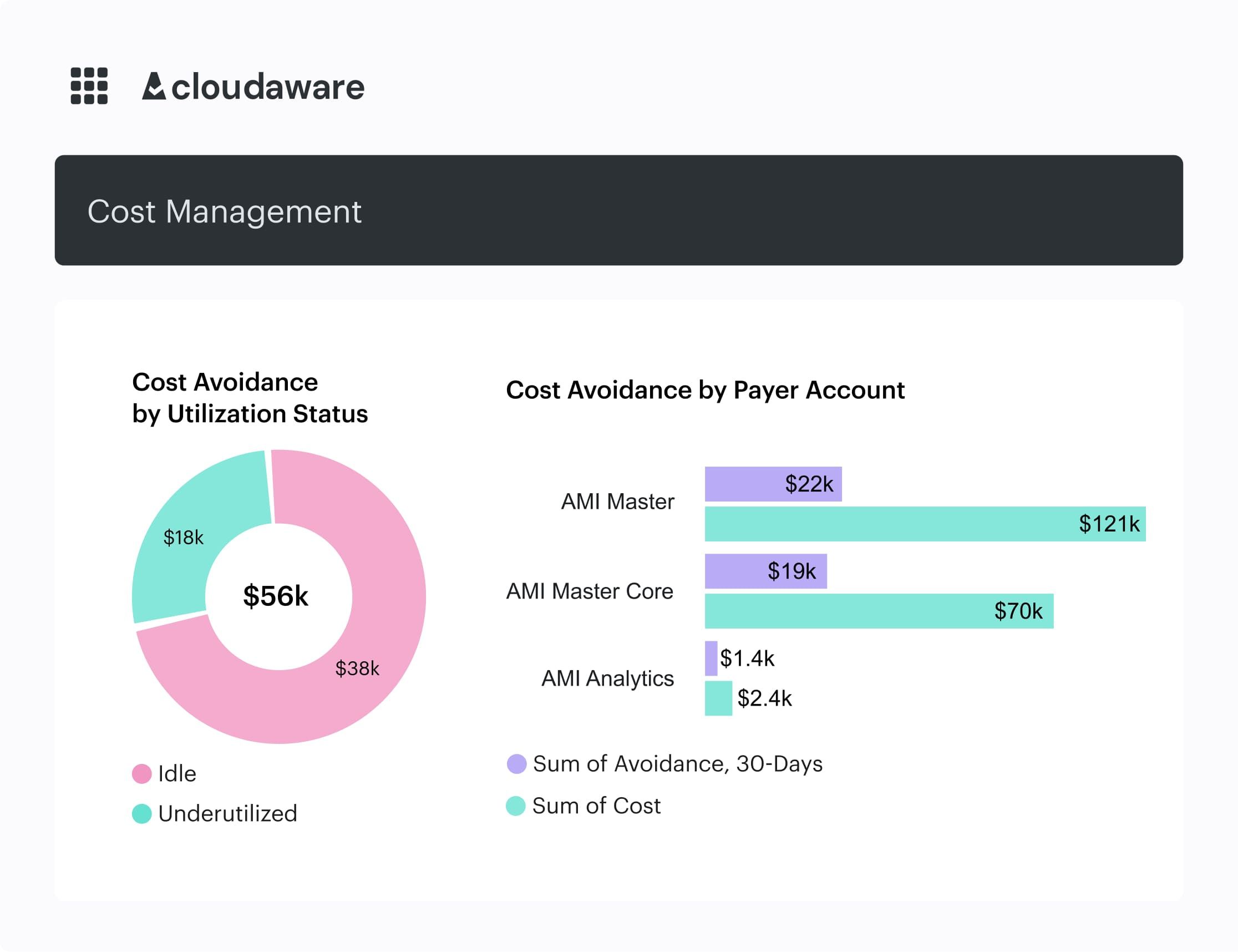
Candidates get ranked by savings (and risk), owners resolve automatically, and Force.com flows open Jira with SLAs — no hunting for who fixes what. Detection leans on usage signals (CPU, memory, connections, IOPS, request counts), so the remediation is obvious: shut down, resize, or right-tier.
Daily conformance feeds an “Idle Waste” dashboard; a weekly Waste Review lifts the top items into a sprint-sized backlog.
Governance holds the line — Tagging Governance, month-end Variance Review, and Showback/Chargeback keep ownership sticky.
The runbook captures the muscle memory: Idle Waste Policy, Rightsizing, Close Procedures.
Nightly automation handles recomputes, ticket updates, and report refreshes, not spreadsheets.
Two sprints later, cloud costs fall ~6–9%: on-demand compute down ~14%, storage trims from deleting unattached volumes and right-tiering databases. Forecast variance tightens from ±17% to ±10%. Finance closes a day faster. Engineering wins back ~2 sprint-days a month without ad-hoc hunts, and Product plans the next release with clean headroom.
Tag coverage: When missing tags turn reports into guesswork
Month-end lands and the exports don’t tell a straight story. In AWS prod, EKS nodes mirror dev; in Azure, a stack of managed disks arrives with no owner; in GCP, a data pipeline slips into “misc.” Finance can’t close Variance Review or run chargeback cleanly. Engineering leads field “who owns this?” threads. Product pauses roadmap calls without unit baselines. Untagged and mis-tagged spend is everywhere — application, environment, owner_email, cost_center — so no one trusts the roll-ups. If you work in FinOps, you’ve lived this week.
Here’s how to fix it:
- First, we ingest AWS CUR, Azure billing exports, and GCP ingest billing files into one model and bind accounts/subscriptions/projects to apps, teams, and environments via the CMDB.
- Next, a versioned Tagging Governance policy (required keys, documented exceptions) goes live, and Tagging Analysis highlights non-compliant assets by team, environment, and dollar impact.
- From there, Force.com flows do the lifting: open Jira/ServiceNow with the right owner from the CMDB, attach offending records, set SLAs, and escalate if tickets age out. Leaders get targeted visibility through dashboards that surface tag coverage and “spend at risk” by service and account.
- Detection is anchored to usage signals — requests, vCPU-hours, GB-months — so teams know exactly what to tag, resize, or shut down. Overnight automation refreshes reports, recomputes compliance, and updates ticket states.
- Weekly Variance Review confirms reclassified lines land in showback/chargeback. A living runbook locks in the practices: Tagging Governance, Data Quality SLAs, Shared-Cost Allocation Rules, Close Procedures.
- Finally, we embed it in day-to-day management with a 10-minute “Tag Health” stand-up each sprint and a month-end close checklist.
Example of the dashboard with tagging coverage within Cloudaware:
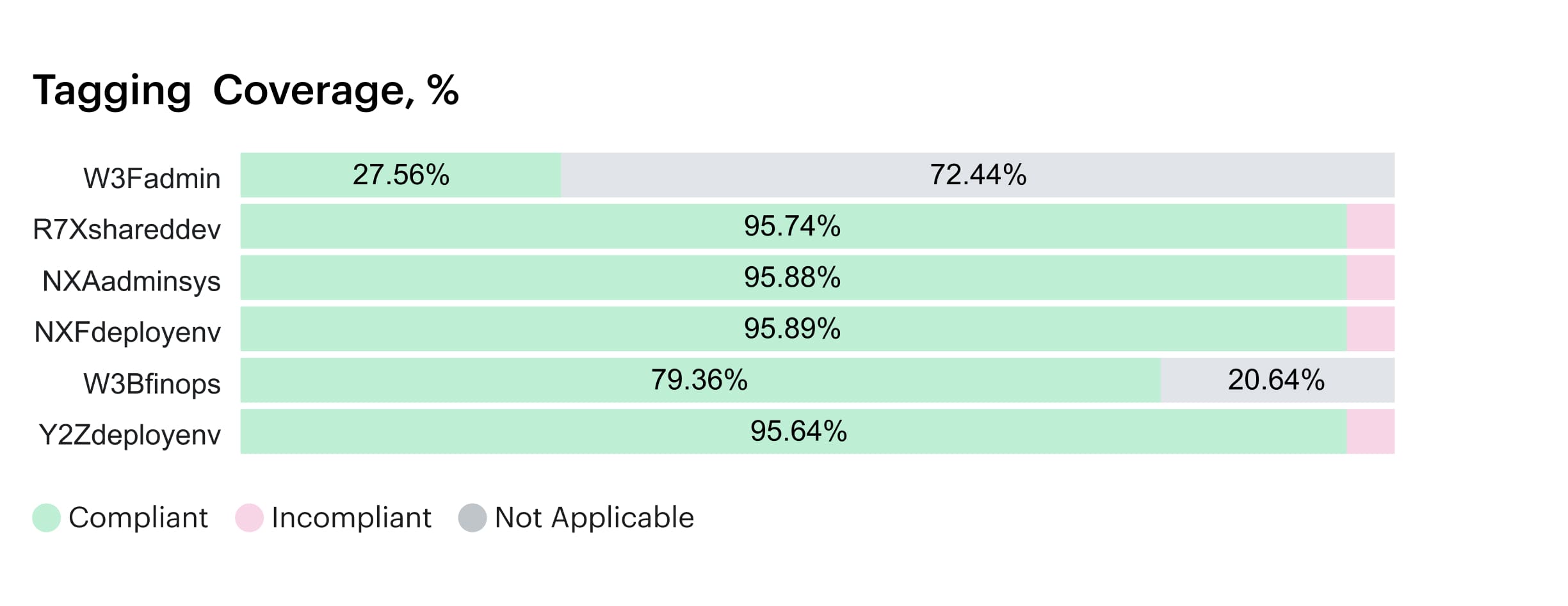
Two sprints later, tag coverage jumps from 69% → 96% and allocation accuracy from 71% → 95%. Mean time to remediate drops from five days to 36 hours; forecast variance tightens from ±19% to ±10%; Finance closes a day faster. Engineering cuts budget-dispute interrupts nearly in half. Product gets feature-level visibility for roadmap trade-offs. Cloudaware turns hidden costs into accountable line items — and the report finally matches how the work gets done.
How Cloudaware tackles all these FinOps use cases
Cloudaware pulls in AWS CUR, Azure Cost Management exports, Alibaba, Oracle, and GCP Billing, layers them with CMDB fields (application__c, environment__c, owner_email__c), and delivers tailored views to each accountable owner.
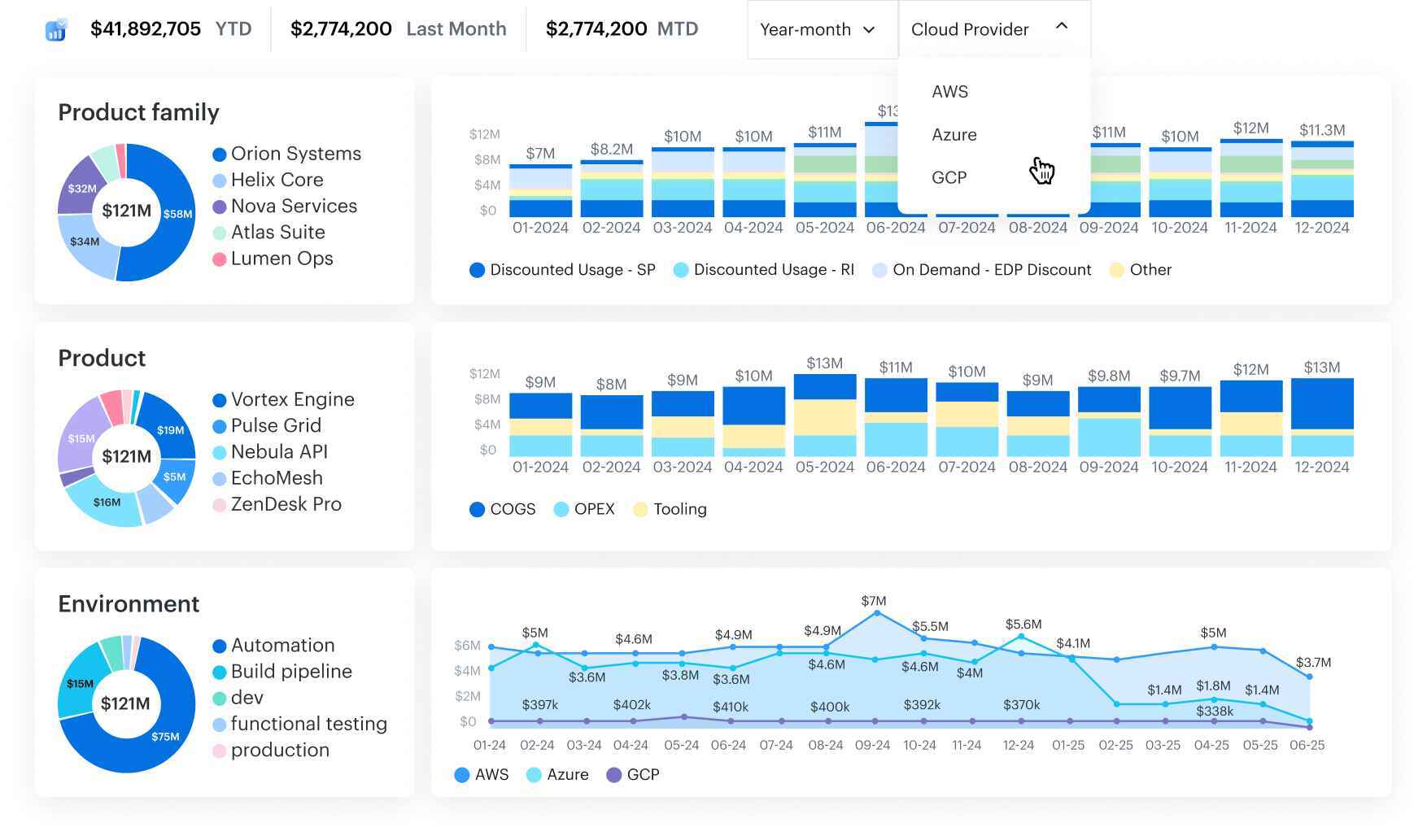
FinOps managers handle commitment planning, forecasting, showback/chargeback, anomaly handling, and policy governance. Engineering leads dive into rightsizing, autoscaling reviews, and tag hygiene. Finance compares amortized vs. blended/unblended costs and runs variance checks. Product leaders track service-level unit economics over time.
Cloudaware platform unifies spend + inventory + ownership in one pane. It turns raw billing records into clear actions — who should move, what to change, and where the savings land. Dashboards are role-aware, reports are ready to schedule, alerts open tickets, and every update ties back to the right CI or service within your cloud infrastructure.
FinOps features that map to your process:
- Commitment Planning & Tracking. Coverage and utilization by family/region; renewal nudges; scenario tables you can publish with buy/hold guidance.
- Forecasting & Variance Review. Amortized trends, quick toggles for blended vs. unblended, variance drivers; monthly and mid-month health checks.
- Anomaly Detection & Routing. Day-over-day spikes, owner fields, and Slack/Jira delivery with timestamps; track triage and decision SLAs.
- Waste & Rightsizing. Idle/underused views, storage TTL adoption, scheduling candidates; a rightsizing backlog you can burn down in sprints.
- Showback/Chargeback. Allocate via tags + CMDB fields; log and age policy exceptions; exports ready for finance close.
- Agentless Inventory + Normalization. Cloud assets roll into a unified CMDB with dependable app/team/env classifications.
- Tagging Quality. Coverage scoring for application__c, environment__c, owner_email__c; surface non-compliant resources and aging exceptions.