






You’re here because DevSecOps has turned into a vibe, and you need something you can defend in a roadmap review. Good news: you’re in the right place. Together with Valentin (DevOps), we created this six pillars of DevSecOps guide:
- So what are the DevSecOps pillars really doing behind the buzzwords?
- Which one breaks first when teams scale?
- And what does “done” look like when prod still ships fast?
Let’s start with a cheat sheet you can skim in 60 seconds and use as your shared scoreboard.
TL;DR
Here’s the TL;DR you can use as a shared scoreboard. Each pillar exists to prevent a very specific failure mode, and each one only “counts” once it shows up as a pipeline behavior you can measure. CSA’s starter metrics are the backbone here too: deployment frequency, vulnerability patch time, % of code automatically tested, and automated tests per application.
| Pillar | What it prevents | What you implement | What you measure |
|---|---|---|---|
| Collective Responsibility | Alerts with no owner, fixes stuck in limbo | Service/asset ownership mapped, clear RACI, time-bound exceptions | % services with an owner, mean time to assign, exception expiry compliance |
| Collaboration & Integration | Security as a parallel process that adds queues | PR checks + release approvals + tickets + chat notifications in one flow; block/warn/log rules | approval lead time, % changes auto-approved vs routed, rework rate after reviews |
| Pragmatic Implementation | Tool sprawl, red pipelines, “rerun until green” culture | Start with prod + sensitive data paths; gate on high-confidence signals; everything else is feedback | false positive rate after tuning, % controls scoped by env, time-to-remediate blockers |
| Bridging Compliance & Dev | Audit scrambles and screenshot evidence | Control → automated check → policy result → evidence log → report | audit readiness time, % controls with automated evidence, policy breach closure time |
| Automation | Slow builds and noisy gates that get bypassed | Block/warn/log tuning by environment; drift baselines + drift detection | pipeline delay added by checks, drift MTTR, % checks automated |
| Measure, Monitor, Report, Act | “We think we’re better” with no proof | Weekly metrics cadence + action triggers (tune gates, expire exceptions, fix ownership) | deployment frequency, vulnerability patch time, % code automatically tested / automated tests per app |
Next, before we go deeper, let’s lock in one thing: why this six-pillar list is the canonical framework you can cite with a straight face.
Why this “six pillars” list is the canonical one
If you’ve Googled “six pillars” before, you’ve seen the problem: everyone repeats a list, then quietly tweaks it until it fits their angle. That’s not useful when you need a framework you can defend in front of AppSec, Platform, and leadership.
CSA’s version is the canonical one because it has provenance and structure. It starts as an official CSA publication (released in 2019), not a blog post, and it’s maintained as a series hub with an overview plus six pillar papers, each tracked with release dates and ongoing updates.
SafeCode is part of the lineage too, through the SAFECode-CSA DevSecOps Working Group, which is a strong signal that it was built to survive real-world delivery constraints, not just read well.
You’ll even see the framework referenced in security community materials like NIST NCCoE workshop content, which is another “this gets taken seriously” tell.
And here’s the on-the-ground reason we use it at Cloudaware: these pillars map cleanly to where pipelines actually break at scale. Ownership gets fuzzy, approvals turn into archaeology, evidence shows up late, drift undoes yesterday’s controls, automation adds friction, and metrics don’t trigger action.
Now let’s walk through the six pillars and translate each one into pipeline moves you can run.
Six pillars of DevSecOps
In real pipelines, “DevSecOps” usually breaks in boring places. Nobody knows who owns a service in prod. A check fails and sits in limbo. Compliance asks for evidence and you’re stitching screenshots at 11 PM.
That’s why the Six pillars of DevSecOps matter - they’re a checklist for where delivery systems leak risk.
Here’s the set:

Next we start with the pillar that decides whether everything else works or becomes theater. 👇
Pillar 1: Collective Responsibility
Collective Responsibility is an ownership model that survives the moment a policy check fails at 3:07 PM and everyone suddenly discovers “shared” means “floating.” If your asset inventory can’t tell you who owns the service in prod, you don’t have anything collective. You have a delay.
When this pillar is working, AppSec and the platform team build the paved road. They define the default controls, the golden pipeline path, and the “block vs flag” rules teams can ship with. Product squads stay in execution because they’re the only people who can safely change the code, IaC, and runtime config.
A boring, explicit RACI keeps it sane: who owns the fix, who can approve an exception, who verifies it, and who gets pulled in when that exception expires.
Security champions help when they act like a routing shortcut and translator, not a human SIEM.
The fastest way to kill this pillar is a pattern I’ve watched repeat for years: “When collective responsibility becomes ‘everyone gets alerts,’ it quietly turns into ‘nobody closes anything.’” Ownership has to be addressable.
Here’s how Cloudaware teams typically make that addressable without heroics. They map services to owners and environments first, so when a misconfiguration shows up it routes to the team that can actually change it.
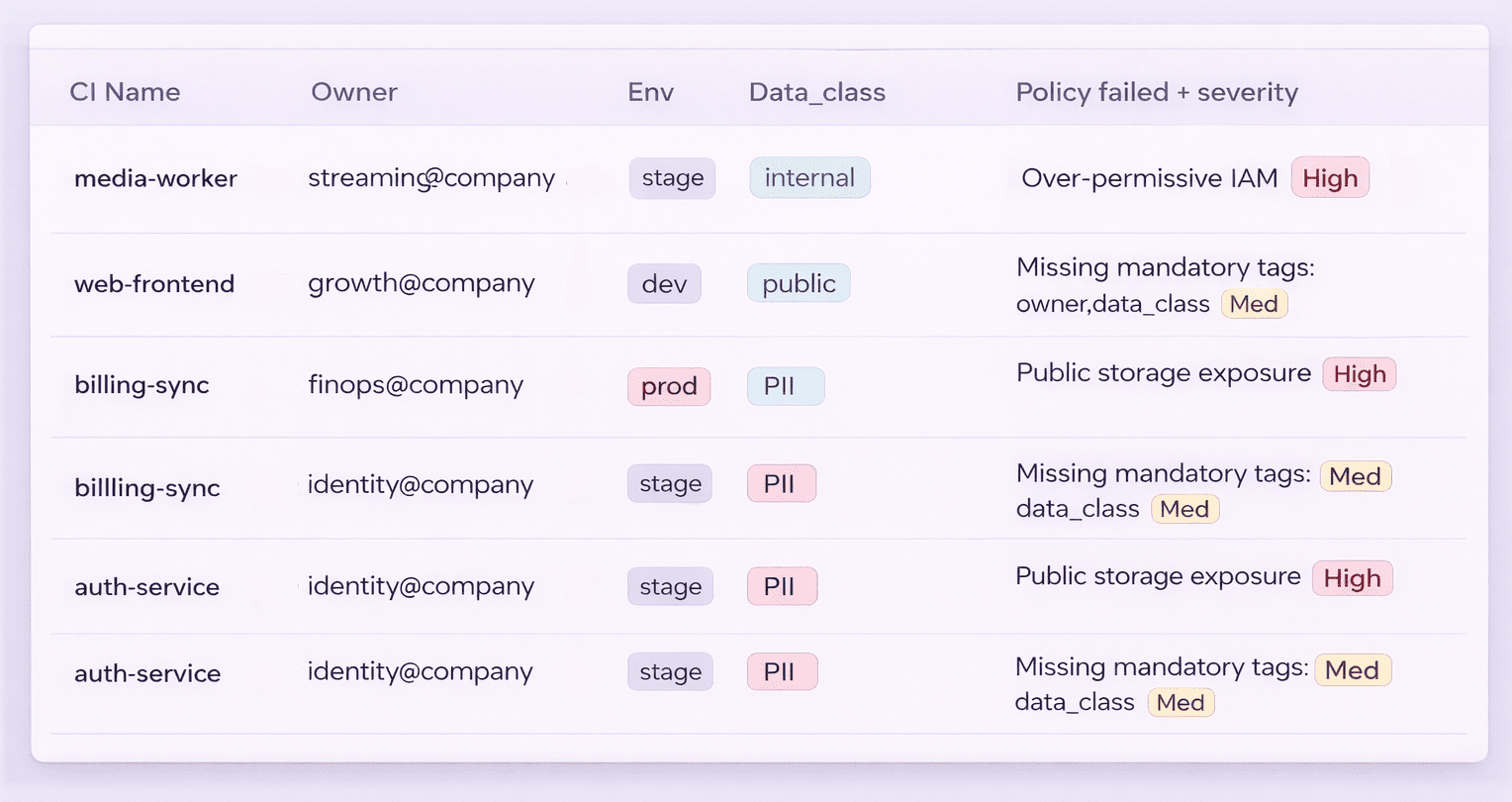
Then they use change history to quickly settle the hard questions: what changed, who changed it, and when.
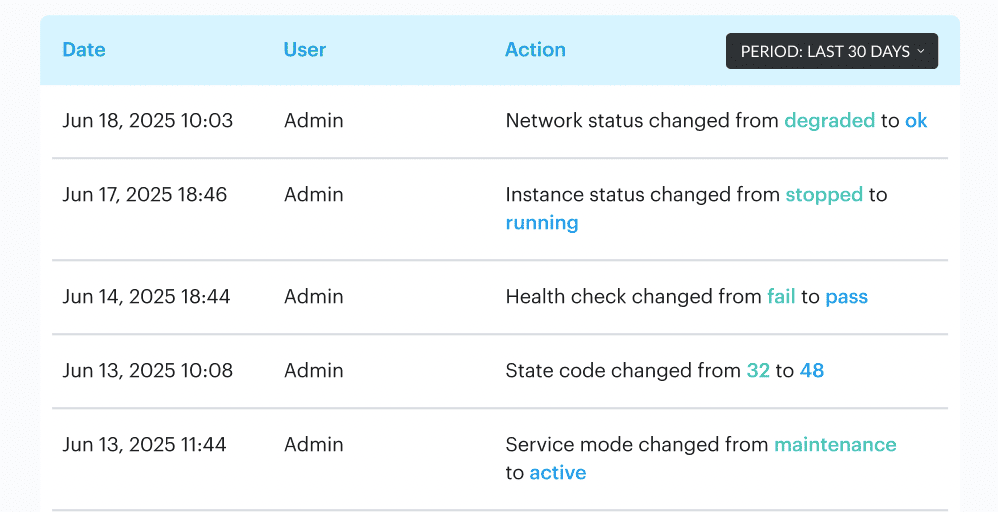
Change management history in Cloudaware. See it live.
That one habit turns accountability from debate into a traceable workflow.
You’ll know it’s improving when the % of services with a named owner climbs, the mean time to assign work drops from days to hours, and the exception count with expiration dates behaves like a managed backlog instead of a graveyard.
Read also: 10 DevSecOps Best Practices That Actually Survive Production
Pillar 2: Collaboration and Integration
CSA is pretty blunt on this pillar: security gets real speed when people build it together, with shared context, instead of lobbing requirements across team boundaries. You’ll recognize it when it happens. Reviews stop feeling like a separate ritual and start behaving like part of delivery.
The pipeline pattern is almost boring, which is why it works.
- Put the cross-functional workflow where engineers already spend their attention.
- Start in the pull request with PR checks that run fast and explain themselves, so fixes happen while the change is still fresh in someone’s head.
- Then keep the “rules of engagement” tiny and explicit. Define what gets blocked, what gets warned, what gets logged for later, and who owns each decision. Change approvals sit inside the release flow with clear thresholds.
When a decision needs humans, it happens in the same operational lane teams already trust, including chatops for time-sensitive calls and ITSM integration when you need traceability and audit-friendly records.
A common mistake shows up as “collaboration” that looks busy while outcomes stall 👇
On a demo call last month, one client hit me with a line that was so painfully accurate I wrote it down.
They said:
“We added more touchpoints and called it integration. Checks run in one place, exceptions live in another, approvals happen somewhere else, and every handoff drops context. The team thinks the process is ‘safe’ because more people looked at it, yet nobody can explain which conditions actually block a release.”
And you could feel the fatigue behind it.
Because what they really had wasn’t a DevSecOps workflow. It was a relay race.
Security scan fires → results land in Tool A.
Exception gets discussed in a ticket → Tool B.
Approval gets granted in a chat thread → Tool C.
And the pipeline? The pipeline is just sitting there like, “Cool story… so are we shipping or not?”
They told me the worst part wasn’t even the delays. It was the ambiguity.
Everyone assumed it was “safe” because more humans were involved. More eyes. More meetings. More “+1 looks good.” But when something went wrong, nobody could answer the only question that matters:
“What exactly would have blocked this release?”
So they changed the whole approach.
Instead of stitching tools together with handoffs, they made one clear contract — written in pipeline terms:
- Block: hard stop, you don’t ship.
- Warn: ship allowed, but it’s visible and owned.
- Log: collect signal, no drama.
Then they did the part most teams skip: they routed the decision to the owner who can actually act.
Not “Security approves everything.” Not “Platform team is the bottleneck.”
The owner of the service. The person who can fix, accept, or redesign.
And exceptions stopped being eternal “special cases.” They became time-bound by default—with expiry and review baked in.
Their punchline was the best summary of the whole thing:
“When the workflow holds the context, people spend their time shipping and improving controls, not reconstructing history.”
To keep this pillar honest, measure the friction. Approval lead time tells you whether collaboration is flowing or pooling. The percentage of changes auto-approved versus routed shows how well you’ve tuned the contract. Rework rate after reviews exposes hidden churn that teams rarely admit out loud.
Next comes the pillar that decides whether your program scales with sanity 👇
Read also: DevSecOps vs CI/CD. How to Build a Secure CI/CD Pipeline
Pillar 3: Pragmatic implementation
Tool sprawl feels productive right up until nobody can answer a simple question: *“What do we do with this finding?*” CSA calls that out for a reason. There’s no universal tool stack, and piling scanners onto a pipeline rarely produces actionable insight. It usually produces noise and debates.
So Pillar 3 starts with a decision, not a purchase. Pick the riskiest path first. Production. Anything that touches sensitive data. The goal is risk-based scoping that teams can explain in one breath. From there, gates earn their place. High-confidence signals get the power to stop a release. Everything else becomes feedback that teams can triage, tune, and learn from without derailing delivery.
That’s how maturity shows up in a real org: fewer red builds that mean nothing and more “this failed for a reason we understand.”
Michael, one of our Cloudaware managers, told me about a moment that comes up a lot on demos.
The pattern behind that story is the part most teams recognize: when every team has its own definition of “urgent” and nobody owns the rules, exceptions explode, trust collapses, and the pipeline becomes easy to game. The fix is to scope controls by environment so dev does not get treated like prod, define a small blocker class that everyone agrees can stop a release, and tune false positives down until gates regain credibility one decision at a time.
Main lessons:
- Keep the scoreboard simple and ruthless.
- Track the percentage of controls scoped by environment across dev, stage, and prod, because one set of rules won’t survive all three.
- Watch the false positive rate after tuning to protect the signal-to-noise.
- Please measure the time-to-remediate for "blocker" class issues, as these are the controls on which the releases depend.
Next comes the part leadership cares about even more than clean gates: evidence you can hand to auditors without a fire drill. 👇
Pillar 4: Bridging compliance and development
Compliance usually shows up with the same three requests: show me the control, show me where it runs, and show me proof it ran. Pillar 4 exists so you can answer those questions without reopening old tickets and DM’ing people who already left the company. Bridging Compliance and Development is basically control mapping that survives reality.
The workflow stays almost annoyingly straightforward:
Control → automated check → policy result → evidence log → report.
You want it boring. Boring means repeatable. Repeatable means you can ensure continuous compliance without inventing a new process every quarter.
A common mistake sounds like a DevOps lead narrating an outage, except the outage is your audit prep:
Cloudaware DevSecOps teams tend to measure this pillar with numbers that don’t lie. Audit-readiness time shrinks because reports pull from consistent evidence and audit logs instead of manual assembly. DevSecOps report element in Cloudaware. See it live.
DevSecOps report element in Cloudaware. See it live.
They watch how many policy breaches get caught before deployment, track closure time for misconfigurations, and review exceptions by environment with timestamps so “we’re compliant” isn’t a feeling; it’s a trail.
Next, we take that clean evidence chain and make it scale across teams and changes without adding friction 👇
Read also: DevSecOps Roles and Responsibilities. Who Does What and How Teams Are Structured
Pillar 5: Automation
Everyone turns to automation when the pipeline becomes busy. CSA makes the trade-off explicit: automation boosts efficiency, and those same automated checks can slow builds if the workflow doesn’t evolve around them.
The pattern that holds up under load starts with classification. Split outcomes into block, warn, or log-only, then tune by environment so prod doesn’t inherit dev’s experimental chaos. That’s how security gates stay credible. Teams can predict what happens next, and “fast feedback” stays fast.
Runtime needs its discipline. Drift detection plus baseline comparisons catch the quiet changes that happen after deployment, when someone tweaks IAM, security groups, or cluster settings and forgets. The anchor here is the baseline configuration that everyone agrees is “normal,” then you watch for meaningful deviation.
Cloudaware DevSecOps teams usually measure this pillar with operational numbers, not feelings. They watch how often automated approvals handle low-risk changes versus how many get routed for review, how long approvals sit pending, and whether drift is being detected and closed out with a clear history of what changed and who signed off.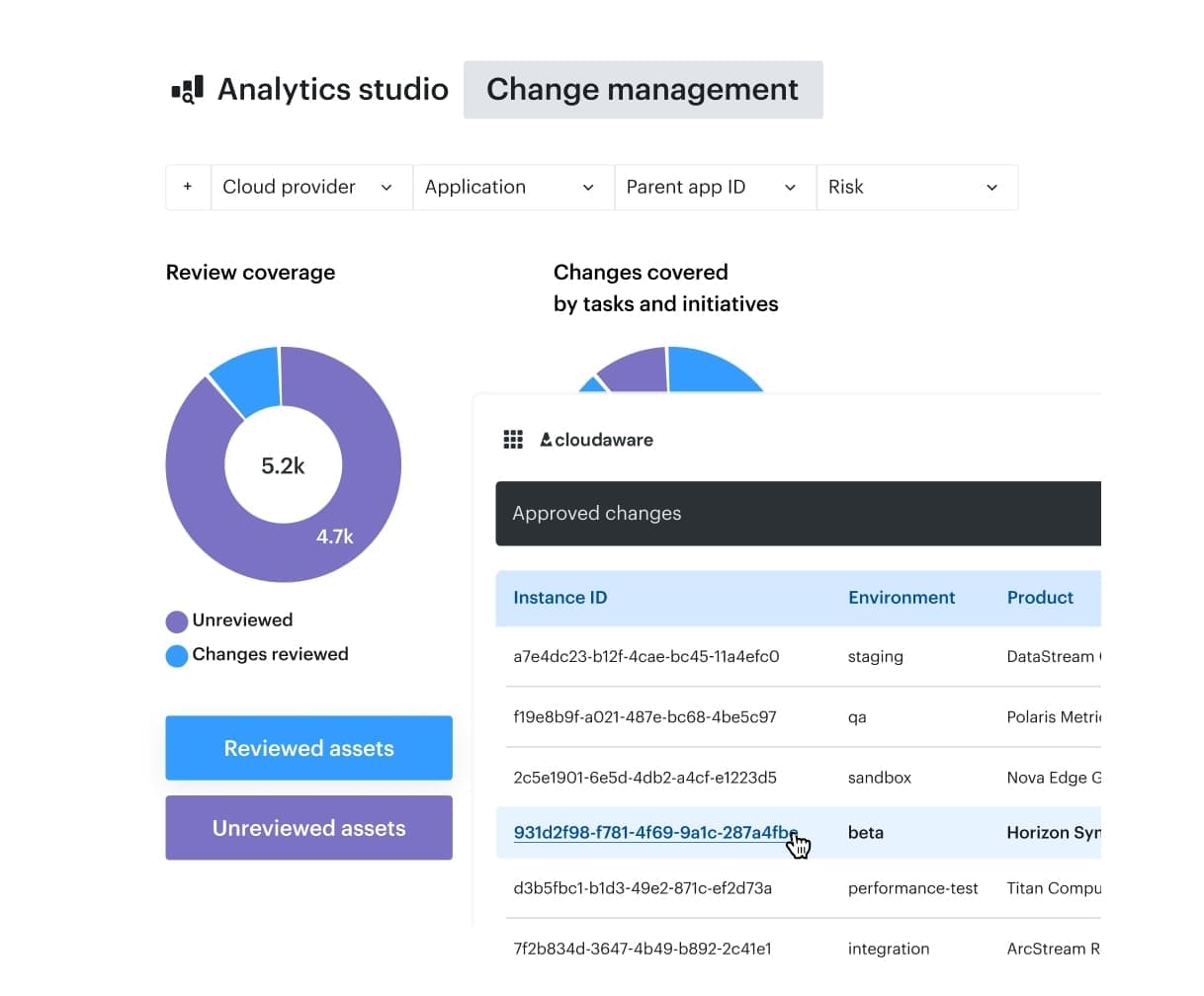 Change management dashboards in Cloudaware. See it live.
Change management dashboards in Cloudaware. See it live.
Cloudaware’s baselines, full attribute change recording, and audit logs make that measurable without manual archaeology.
Next up, we turn those signals into a shared scoreboard that leadership and engineering both trust 👇
Pillar 6: Measure, monitor, report, and action
Metrics are where DevSecOps either earns trust or slowly turns into folklore. Pillar 6 exists because “we’re doing better” doesn’t survive a budget review. A shared scoreboard does. You monitor what matters, report it on a predictable cadence, and let the numbers force continuous improvement instead of opinion-driven tweaks.
Begin with the signals that connect delivery and risk.
- Deployment frequency tells you whether teams can still ship.
- Vulnerability patch time shows how long exposure hangs around in production.
- Coverage needs its own reality check too, so track the % of code automatically tested and automated tests per app.
- Then zoom into the flow. Approval lead time exposes slow governance. Exception expiry compliance keeps “temporary” from becoming permanent.
- Drift MTTR gives you the recovery story when configuration changes slip in after deployment.
- Rework rate after reviews catches the churn that kills momentum and hides in polite conversations.
This is where Cloudaware outcomes become measurable work, not marketing lines. “100% change visibility” becomes a trackable promise that every production change has a trace, an owner, and a timestamp. “95% fewer false alarms” becomes a quantity you can see in reduced noise, fewer routed reviews for non-issues, and faster time-to-signal when something actually matters.
Pair those with monitoring, and you get a system leaders can trust because it behaves predictably week to week.
Next, we’ll translate this scoreboard into an execution plan you can run without chaos 👇
Read also: DevSecOps Framework in 2026. NIST, OWASP, SLSA, and How to Choose the Right One
A 30/60/90-day rollout plan of DevSecOps pillars
This rollout plan is based on a hard reality CSA calls out: DevSecOps implementation and maintenance can take a few months to several years. So the win condition isn’t “do everything.” It’s steady progress you can prove, without blowing up delivery.
- Week 1 starts with the six pillars of DevSecOps as your shared language, then you turn that language into operating rules. In the first 30 days, focus on ownership and environments. Get every critical service tied to an owner, decide what “prod” really means across accounts, and introduce policy outcomes that teams can predict: block, warn, or log-only.
- By day 60, you move from opinions to receipts. Evidence becomes automated, approvals and routing stop living in tribal memory, and drift baselines give you a stable “this is normal” reference point. That’s when audits get quieter and change reviews stop turning into archaeology.
- At 90 days, you expand coverage with intention. Exceptions shrink because they expire and get revisited. Metrics-to-action loops tighten, so a warning either gets tuned, promoted to a blocker, or retired. That’s how DevSecOps pillars turn into a system, not a poster.
Next, we’ll show how to level this approach up in the real world 👇
Implement six pillars of DevSecOps with Cloudaware
The rollout plan works when the framework stops living in a slide deck and starts living in the pipeline. Cloudaware supports that translation by turning the six pillars of DevSecOps into three things teams can execute: context, workflow, and proof.
- In practice, Cloudaware teams begin by making ownership and environments “queryable,” not tribal. DevSecOps services surface high-risk changes with service catalog context, so routing goes to the team that can actually act. That alone protects signal-to-noise because the pipeline stops yelling at everyone at once.
- Then the flow gets tight. Approvals become a first-class mechanism: routed by account, user group, and environment; time-boxed to change windows; and pushed into Slack/Jira/ServiceNow/PagerDuty so decisions happen where work already happens. Evidence follows the same path, because the change management system is built for audits and automated approvals.
- Finally, teams stabilize runtime reality. Cloudaware records who changed what, when, and where, and pairs that with drift baselines so deviations become traceable work, not guesswork. Go/no-go decisions can also consume signals from compliance/CSPM sources like Wiz, Palo Alto, and AWS Trusted Advisor using violations data.
Here's where the real magic occurs:

That’s how the DevSecOps pillars become measurable outcomes: “100% change visibility” as complete change traceability, and “95% fewer false alarms” as fewer noisy alerts and fewer pointless routed reviews.