






Most teams searching for AWS DevSecOps need four things that are hard to assemble from scattered docs.
First, an AWS-native reference architecture from commit to runtime with a clear mapping of DevSecOps controls to AWS services.
Second, a CI/CD pipeline example they can copy.
Third, patterns that work at scale across multiple accounts with consistent guardrails, ownership routing, and audit evidence.
Fourth, a hands-on workshop runbook to enable teams.
If that sounds familiar, keep reading, and you’ll find:
- Commit to production AWS DevSecOps blueprint with a control to service map
- Copy-paste pipeline flow with SCA, SAST, and DAST stages
- AWS Security Hub findings pipeline with ownership routing and triage mechanics
- Multi-account operating patterns for guardrails, drift control, and audit trails
- Workshop-style runbook with prerequisites, modules, and expected outputs
AWS DevSecOps commit-to-production blueprint
AWS defines DevSecOps as integrating security testing at every stage of the software development process, supported by tools and processes that drive collaboration between developers, security, and operations, with security treated as a shared responsibility.
On AWS, security controls are enforced through the delivery path and the operating plane. You map controls to services, decide where gates live, and ensure evidence is generated automatically.
To see how DevSecOps changes once the architecture and scale shift, start with what can actually go wrong across the path to production and which controls must hold under load. That is what the next section covers.
Threat model and security controls across the stack
Architecture doesn't stay still. The form changes, the goal stays the same, and your security controls must evolve with it. What worked when there was one deployable and one team breaks when the system becomes a mesh of services.
Scale is the real driver. In enterprise setups, microservices can grow into hundreds or thousands of components. That increases the attack surface, multiplies change events, and raises the cost of unknown changes in production. So the AWS threat model has to cover the full path, not just code scanning. Controls we anchor early determine whether findings can be routed, gated, and proven later:
Controls we anchor early determine whether findings can be routed, gated, and proven later:
- IAM and identity boundaries aligned to ownership
- Access constraints tied to environments and promotions
- Vulnerability handling rules that define when to block and when to route
Services map: identity, CI/CD, secrets, posture, findings
Once a system reaches thousands of components, point-to-point thinking collapses. The “diagram” becomes noise. You need a consistent method for mapping controls to services across the stack, so teams stop improvising, and outcomes become repeatable.
This subsection introduces the control-to-service map you can use as a baseline. It keeps the blueprint implementable and makes it easier to standardize guardrails across accounts and teams.
Controls and AWS services to map:
- Identity and access controls: IAM, Organizations, and Control Tower
- CI/CD controls: CodeCommit, CodeBuild, CodePipeline
- Secrets controls: Secrets Manager and parameter management
- Posture and audit controls: Config and CloudTrail
- Findings and detection controls: Security Hub, GuardDuty, Inspector
Use this map to standardize a single pipeline AWS flow across teams, with the same control boundaries and evidence outputs.
Сommon DevSecOps AWS stall patterns
Most DevSecOps programs stall for boring reasons: delivery is full of handoffs, slow feedback, and unclear ownership. The classic chain looks familiar: BA to architect to dev to QA to middleware to DB to storage to backup to network to data center to appsec and infosec. Every hop adds delay, context loss, and a new place where responsibility can disappear.
Common AWS stall patterns:
- Full scanning on every change. The pipeline becomes a bottleneck because expensive checks run on low-risk diffs. Teams wait for results, then rerun jobs after small fixes.
- Noisy findings with no thresholds. If every tool reports everything, teams stop trusting the signal. Without severity mapping, confidence levels, and explicit “block vs route” rules, findings become backlog noise.
- Gates that require meetings. A gate that requires discussion is a scheduling dependency. Releases slow down because approval becomes a coordination task.
- Alerts with no owner. Unowned findings are operational debt. They get triaged repeatedly, never closed, and create “unknown change” risk over time.
Then teams try to “add security” and end up making it worse. They pile on tools that don't connect, treat every finding as a stop-the-line event, and ship noise instead of signal. The result is predictable: longer pipelines, alert fatigue, and developers learning to bypass gates rather than fix issues.
How to accelerate DevSecOps on AWS
Agile is a cycle, not one big release. Accelerating DevSecOps on AWS means tightening that cycle with the minimum set of controls that produce signals across your cloud delivery path. What to optimize first:
- Reduce handoffs with deterministic gates: Move decisions into the same workflow where changes happen. Replace “discussion gates” with written criteria: what blocks, what routes, and what requires approval. Default model: block only on new Critical/High introduced by the change or on policy violations that expand exposure or privileges.
- Parallelize and cache where the pipeline actually burns time: Run independent checks concurrently (dependency checks, static analysis, IaC policy checks). Cache dependencies and build layers. The goal is to avoid rerunning full work on unchanged components and to keep PR feedback within a predictable window.
- Scan diffs by default, run full checks by exception: Diff-based checks should run on every PR and merge. Full scans should be triggered by exception: scheduled cadence, pre-prod promotion, or high-risk change categories (auth, network exposure, IAM, crypto, secrets handling).
- Gate selectively and keep remediation gated when blast radius is high: Automate detection and enrichment everywhere. Keep remediation gated for identity and production exposure changes. This matches the practitioner reality: detect automatically, remediate with approval when the impact is high.
The next three sections are pipeline checkpoints: pre-merge controls, CI security testing, and pre-prod promotion gates. This is exactly where delivery either stays predictable or turns into manual triage. Each checkpoint is a small set of gates with explicit thresholds, ownership routing, and audit-ready outputs.
Checkpoint #1: AWS CodeCommit pre-merge controls
Pre-merge is where you prevent avoidable risk from becoming the new baseline. If anything can land in main, CI becomes cleanup work instead of validation. Checkpoint #1 sets the rules for what is allowed to enter the branch that feeds every deployment.
Treat AWS CodeCommit as a control point. Standardize three things across all repos:
- First, branch policy. Protect main, require reviews, and define explicit owners for critical paths. Apply the same rules to application code, IaC, and pipeline definitions.
- Second, change authorization. Restrict who can push and who can approve. Align access to team ownership and environment boundaries so privileges match responsibility.
- Third, entry checks. Run fast, high-confidence checks before merge and block only on issues that are cheap to detect and expensive to fix later.
At the microservices scale, the problem isn't writing code. It is controlling change volume and keeping behavior consistent across services. That is why pre-merge gates become mandatory. Without them, chaos scales with the number of deployables.
Pre-merge security gates: block vs not block
Pre-merge gates should be strict only on issues that are cheap to detect and expensive to fix later. Everything else should be routed, not blocked.
Design the gate around two outcomes: fast feedback and deterministic decisions. This is AWS security testing that happens before the branch becomes the new baseline, and it is where signal-to-noise ratio matters most.
| Block the merge | Don't block the merge |
|---|---|
| Secrets are detected in code, configs, or IaC | Findings are low confidence or high noise |
| Policy checks fail for high-risk patterns (for example, public exposure or privileged roles) | The issue needs environment context to confirm exploitability |
| SAST-lite flags a clear exploitable pattern with high confidence | The fix requires coordination across teams or scheduled remediation |
Read also: DevSecOps Vulnerability Management. CI/CD to Runtime Loop
Checkpoint #2: security testing in CI that developers won’t hate
CI is where security either becomes a reliable signal or permanent noise. The goal is a minimal, repeatable set of checks that catch real vulnerabilities early, produce stable results, and only block releases when the risk is clear.
When your AWS architecture is hundreds or thousands of services, you need standardized automated checks. Think of it like a 50-story building. You don't inspect it floor by floor by hand for every change.
Checkpoint #2 is designed around three rules:
- Fast feedback by default, deeper checks by exception
- Deterministic stop-the-line criteria, not subjective debate
- Output that is actionable for owners, not a raw dump of findings
SCA and code analysis for CI gates
Run SCA to cover third-party dependencies and static analysis for first-party code paths. Keep them separate in reporting and thresholds so you can tune false positives without hiding real risk.
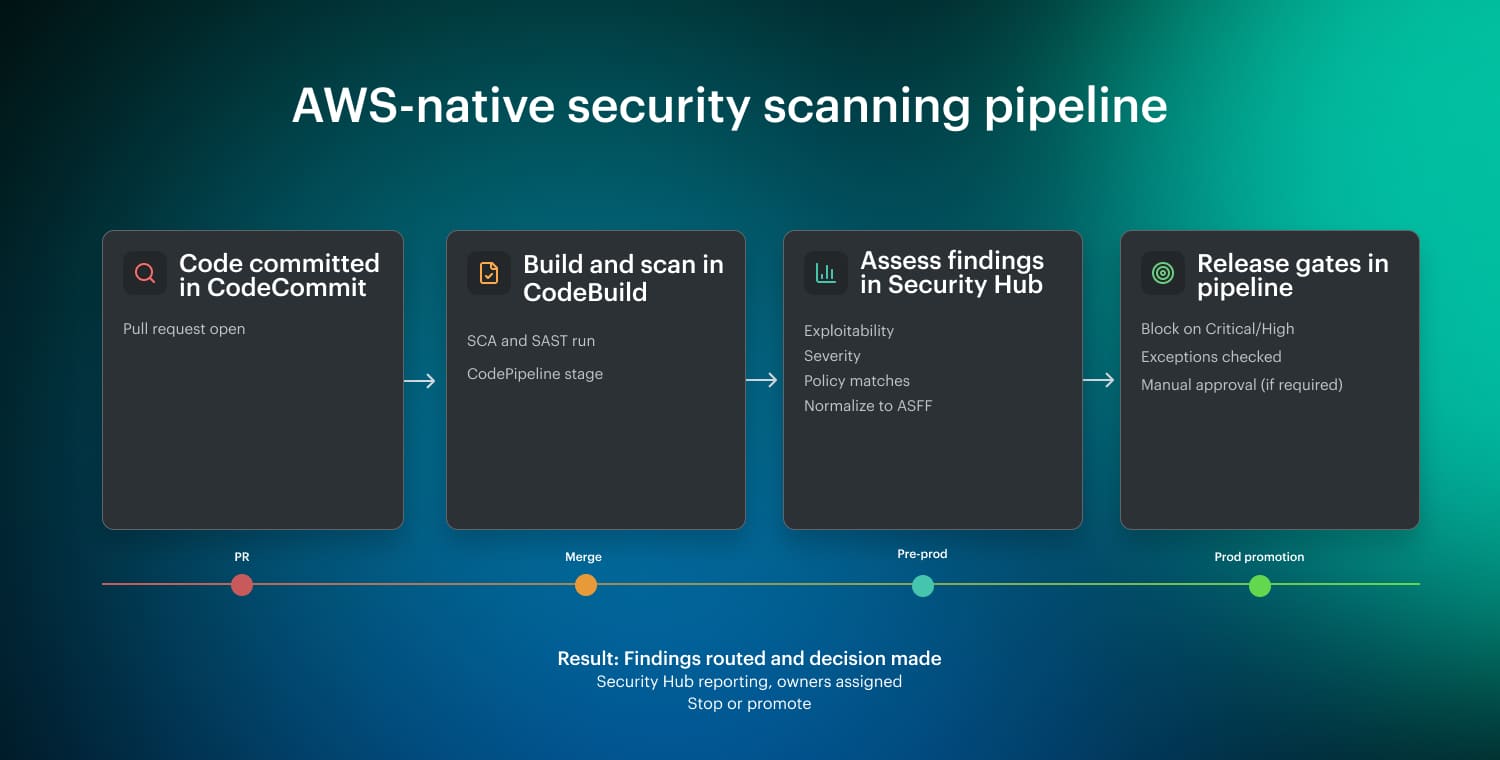 In an AWS-native CI/CD flow, scanners run in CodeBuild as part of a CodePipeline stage. Outputs are normalized (often to ASFF) and published to Security Hub for aggregation and triage. Security Hub is the reporting layer. Release gates remain in the pipeline and evaluate severity thresholds plus exception rules before promotion.
In an AWS-native CI/CD flow, scanners run in CodeBuild as part of a CodePipeline stage. Outputs are normalized (often to ASFF) and published to Security Hub for aggregation and triage. Security Hub is the reporting layer. Release gates remain in the pipeline and evaluate severity thresholds plus exception rules before promotion.
What this enables:
- Fast PR feedback with diff-based scans
- Consistent full scans before pre-prod or production promotion
- Deterministic stop-the-line criteria with owner-approved, time-bound exceptions
Read also: DevSecOps Culture - Operating System Keeping Security Fast
Checkpoint #3: AWS CodePipeline promotion gates and release controls
Checkpoint #3 is where teams usually lose consistency. One environment gets “special handling,” pre-prod drifts from prod, and approvals happen outside the pipeline. The fix is a promotion model that is deterministic and auditable.
Build the AWS pipeline around one rule: build once, promote many. Produce a single application artifact in CI, then promote that exact artifact through pre-prod and into production. Security checks and release gates are explicit stages. No rebuilds in pre-prod. No “production-only” path.
Minimal stage layout build once, promote many
Use AWS CodePipeline to orchestrate a deterministic sequence:
- Source: trigger on commits to main (run PR checks separately for pre-merge scanning)
- Build (artifact): package once, publish the artifact, and scan outputs
- Security checks: run dynamic testing and static analysis as first-class CodeBuild stages, ideally in parallel
- Deploy to pre-prod: deploy the same artifact you built
- DAST and environment checks: run post-deploy in pre-prod, scoped and time-boxed
- Release gates in pipeline: enforce severity thresholds, check exceptions, require manual approval if needed
- Deployment to production: promote only after gates pass
Treat pre-prod deployment as the validation environment and production deployment as a promotion event, not a rebuild.
Artifacts and sources of truth
At scale, you cannot manage security by “team intuition.” As the speaker notes, when systems reach thousands of components, “the diagram becomes much more complex.” Your pipeline needs a single source of truth that makes change traceable.
Make the pipeline the system of record by standardizing three evidence objects:
Artifact identity and immutability
Build once and promote the same artifact across environments. Assign an immutable version and make it the primary key for deployment, scanning, and incident response. If pre-prod differs from prod, you have no reliable baseline.
Scan outputs as artifacts, not screenshots
Store SBOM and scan reports as build artifacts tied to the pipeline execution ID. Treat them as evidence. This lets you diff findings between releases and prove what changed, not just what was detected.
Approvals and change context
Capture approvals in pipeline history and link them to the exact artifact version and promotion. The minimum record should answer: who approved, when, what was promoted, and what checks were evaluated.
This is how you make “unknown change” rare: the artifact version, scan outputs, and approval history form a single traceable chain.
Deterministic gates with thresholds and exceptions
Standardization exists because reinventing gates per team fails at scale. In the video’s words, “every company have their own pattern, which means you’re reinventing everything”. Gate policy should be deterministic and portable across repos and accounts.
Define gate rules upfront using three policy layers:
Release thresholds
Block on new Critical or High introduced by the change, and on policy violations that expand exposure or privileges. Route lower-severity issues to owners with SLAs instead of blocking delivery.
Exception governance
Exceptions aren't “ignored.” Make them time-bound, owned, and auditable. Every exception should include an owner, expiry date, justification, and approval path. Expired exceptions should fail the next promotion until renewed or remediated.
High-risk change triggers
Not all diffs are equal. Escalate gates for changes that expand blast radius: identity and trust changes, network exposure, secrets handling, and production promotion steps. These are the places where human-in-the-loop approval is justified.
Read also: My Kubernetes DevSecOps Implementation Playbook
Application security coverage across build, deploy, and runtime
Web applications have dominated for decades, so AWS application security has to be systematic. Build, deploy, and runtime are different control planes. If you mix them, you either miss real vulnerabilities or slow delivery with checks that cannot produce actionable outcomes at that stage.
| Stage | Primary goal | What it covers | What “good” looks like |
|---|---|---|---|
| Build-time | Fast, deterministic signal and prevention | SCA for third-party dependencies, SAST for first-party code paths, secret scanning | New vulnerabilities don't enter mainline, low noise, predictable CI gates |
| Deploy-time | Block unsafe exposure before it becomes production reality | IaC and policy checks, image scanning for shipped artifacts, permission reviews to prevent blast-radius expansion | No privilege expansion or public reachability slips through, stricter gates for high-risk changes |
| Runtime | Verification and evidence in production conditions | Confirm what is running, detect configuration drift, validate exploitability with real routing, auth, and permissions | Clear evidence trail for what changed, when, by whom, and what was verified after remediation |
Where SAST/DAST stops and runtime starts
SAST and DAST are necessary but incomplete. Static analysis flags code patterns, not reachability in production. Dynamic testing tests a running environment, but coverage is constrained by time-boxing, environment fidelity, and authenticated flow complexity. The remaining gap is prod context.
Use OWASP as the vulnerability taxonomy, but enforce controls by stage: prevent what you can at build-time, block exposure and permission expansion at deploy-time, and detect plus verify at runtime.
The handoff is simple: once risk depends on real routing, real identities, and real access paths, it becomes a production problem and must be handled with telemetry, ownership, and evidence.
Runtime security guardrails and incident response
CI reduces risk, but runtime is where you confirm what actually happened. This section covers the minimum operational guardrails and telemetry you need to detect Critical issues fast, preserve evidence, and respond without guessing. Treat runtime security as an operating loop, not a one-time scan.
In the classic model, separate teams own OS, middleware, DB, network, data center, and security. In reality, incidents cross those boundaries. That is why you need a single runbook and a single telemetry plane.
Start with two non-negotiables: complete audit trails and continuous drift visibility. CloudTrail provides an immutable record of actions. Config tracks configuration state over time, so you can answer what changed without reconstructing events from memory. This is the baseline for AWS security in a multi-team cloud environment.
Detection and triage work best when findings are centralized. Use Security Hub as the aggregation layer for high-signal findings so teams don't chase alerts across disconnected consoles. The main Amazon DevSecOps goal is to route work with owners and SLAs, not “someone should look at this.”
Minimal incident runbook
This runbook is built for real AWS incidents: scope first, contain the blast radius, remove the root cause, then prove the system is back in a known-good state. It is also audit-ready by design, so you can link actions back to owners, approvals, and verification outputs.
- Triage: confirm scope and impact, identify the owning service and account, classify severity, and decide whether access must be restricted immediately.
- Containment: reduce blast radius first, isolate affected resources, revoke or rotate exposed credentials, and apply temporary access constraints while preserving evidence.
- Fix: patch the root cause (code, configuration, IAM policy, dependency) using approved tools and standard change paths. Avoid manual hotfixes that create new drift.
- Validation: re-run the relevant checks, confirm the signal is gone, and verify no new exposure was introduced.
- Evidence: capture timestamps, affected resources, actions taken, and verification results, then link findings, tickets, and approvals so the audit trail is complete.
Read also: 8 DevSecOps Container Security Vulnerabilities and How to Fix Them
How to run AWS DevSecOps in multi-account environments
Enterprise scale isn't two environments and two clusters. It can be hundreds or thousands of components, sometimes spread across hundreds of clusters. At that scale, team-by-team security fails. Drift becomes normal, controls diverge, and “unknown change” turns into an operating condition.
AWS multi-account model is the baseline for separation of duties and blast radius control. It lets you enforce identity and access boundaries consistently, centralize audit trails, and prove control coverage without relying on manual evidence collection.
The objective is repeatability: same policies, same logging, same detection standards across every production account.
Standardize four things first:
- Account and environment structure (dev, staging, prod, shared services)
- Access boundaries tied to ownership and promotion workflows
- Centralized logging and evidence retention
- Consistent detection and findings aggregation across accounts
To make multi-account repeatable, you need guardrails that scale without per-team tuning. Organizations and Control Tower are the AWS-native way to enforce baseline governance and centralized logging, so drift doesn't become your default operating mode.
Organizations and Control Tower patterns
Use AWS Organizations and Control Tower to enforce guardrails once and apply them everywhere. Treat guardrails as productized cloud security controls, not per-team configuration.
Minimum standard set:
- Baseline accounts and landing zone rules
- Centralized audit and logging services
- Consistent policy enforcement for identity, network exposure, and configuration drift
- Shared detection and reporting services so findings are comparable across accounts
AWS Control Tower and Organizations provide a strong landing zone baseline, but they don't solve day-2 operations at scale: cross-account ownership routing, exception handling, and audit-ready evidence, especially in multi-cloud environments.
Security integration workflows for remediation and exceptions
At scale, security fails in the gaps between teams. More roles and handoffs mean more unknown change, and the same question on every incident: who owns the fix? Security integration solves this by turning findings into routed work with deterministic outcomes.
The goal is simple: every finding has an owner, an SLA, and an auditable disposition.
Operationalize four workflow objects:
- Ticketing and routing: create a ticket from each finding, assign it to the owning team, and track SLA and status changes
- Exceptions: allow time-bound exceptions with explicit owner and approval path
- Evidence: capture what changed, who approved, what was verified, and link it back to the finding
- Automation: auto-detect and auto-enrich everywhere; auto-remediate only where safe, and gate the rest
One engineer's rule is to automate everything that doesn't require a human in the loop for regulatory reasons. Another calls IAM drift the worst at scale and recommends automated detection with gated remediation, noting they still end up scripting Jira integrations and custom policy enforcement.
This is one of the DevSecOps practices that prevents findings from turning into unowned backlog.
Auto-remediation loop
This is the highest-ROI automation because it reduces MTTR without removing accountability. The default model is automated detection and enrichment, with gated remediation when the blast radius is high.
How it works in practice:
- Rule: define what “bad” means (policy, configuration, vulnerability threshold)
- Event: use a Lambda function to normalize raw scanner output and attach ownership metadata before routing
- Fix: auto-remediate only low-risk, reversible issues
- Verification: re-check that the issue is gone and no new exposure was introduced
- Evidence: store before/after state, timestamps, approvals, and verification output
Operationally, centralize findings in Security Hub so triage and reporting stay consistent across accounts, and connect your tools to routing and exceptions. Otherwise, “automation” turns into scripts, manual glue, and unowned backlog.
Read also: DevSecOps Velocity. Ship Faster Without Growing Security Debt
AWS DevSecOps tooling: what to standardize across accounts
Multi-account on AWS isn't the hard part. The hard part is making AWS security controls behave the same way across accounts, teams, and pipelines.
The failure mode is predictable: teams can scan, but they can't operationalize. Over time, they lose determinism, releases slow down, and “unknown change” becomes normal.
This is the gap most teams describe when they search for Amazon DevSecOps at scale. They are about standardizing the interface: where results land, how severity is mapped, how gates make decisions, how ownership is assigned, how exceptions expire, and how evidence is preserved across accounts.
Native vs open-source vs Marketplace
Pick one default stack per control type, define where results land, and define the threshold policy. Otherwise, teams accumulate tools that don't connect, and ownership routing becomes manual.
Your decision model should answer:
- Which services are mandatory in every account and pipeline
- Which tools are allowed as team-level exceptions
- Which scanners you run centrally vs per-repo, for example, SonarQube for SAST governance
The table below focuses on the operational capabilities that decide whether DevSecOps scales.
For the open-source column, Trivy represents CI-first scanning (dependency and container image scanning). For the Marketplace column, we use Cloudaware as the reference because it targets the operational gaps that typically remain after landing zone setup.
🟢 available 🟡 limited / requires custom build-out 🔴 not available
| Capability | AWS-native | Open-source (Trivy) | Marketplace (Cloudaware) |
|---|---|---|---|
| Multi-account governance baseline | 🟢 | 🔴 | 🟢 |
| Multi-cloud coverage | 🔴 | 🔴 | 🟢 |
| Centralized asset inventory (CMDB-style) | 🟡 | 🔴 | 🟢 |
| Continuous configuration drift detection | 🟢 | 🔴 | 🟢 |
| Compliance posture (benchmarks, controls) | 🟡 | 🔴 | 🟢 |
| Exceptions workflow (time-bound, owner-based) | 🟡 | 🔴 | 🟢 |
| Ownership routing (team/account/service-based) | 🟡 | 🔴 | 🟢 |
| Ticketing and notifications out of the box | 🟡 | 🔴 | 🟢 |
| Audit-ready evidence trail (what, who, when) | 🟡 | 🔴 | 🟢 |
| Central findings aggregation for security signals | 🟢 | 🔴 | 🟢 |
| Dependency scanning (SCA) | 🟡 | 🟢 | 🟡 |
| Container image scanning | 🟡 | 🟢 | 🟢 |
AWS-native scanning is strongest when integrated with AWS-native artifact stores and services. Trivy represents CI-first scanning. Cloudaware represents day-2 governance workflows and operationalization, not a drop-in replacement for CI scanners.