






You're shipping fast, but every release feels like Russian roulette. Will this deploy expose secrets? Break compliance? Open a security hole that your CISO finds before attackers do?
I've spent years embedded with platform engineering teams at companies running Cloudaware's DevSecOps solution. What I've learned from DevOps leaders at firms processing millions of transactions daily: speed without guardrails is just expensive chaos. One VP of Engineering told me they caught 847 policy violations in Q3 alone—violations that would've cost them their SOC 2 certification.
This DevSecOps best practices guide answers the questions keeping you up at night:
- How do you catch misconfigurations before they hit production?
- What belongs in a pre-deployment checklist that actually works?
- Which pipeline gates prevent breaches without killing velocity?
Let's build something that ships fearlessly.
Key insights on DevSecOps best practices
You don’t need another “security is everyone’s job” pep talk. You need a release path that stays fast when the cloud gets messy, auditors ask questions, and someone tries to hot-fix prod from the console. Here are the DevSecOps practices I’d tape above the CI/CD dashboard if I could.
- Decide what’s a hard stop vs. a warning. Block secrets leaks, critical dependency risk, and high-impact IaC misconfigs. Warn (then ticket) the rest with SLAs, or you’ll train teams to ignore everything.
- Make policy-as-code your source of truth. If the rule can’t be versioned, reviewed, and rolled back like code, it won’t survive the next reorg.
- Treat IaC like production code. Scan Terraform/CloudFormation/K8s manifests in PR, and fail builds on the “never again” stuff: open admin ports, public buckets, wildcard IAM, missing ownership tags.
- Sign what you ship, verify what you run. Scanning is nice. Provenance is better. CI signs artifacts, deploy checks signatures/attestations, and anything unverifiable doesn’t get promoted.
- Make every merge traceable to cloud reality. Tag resources with
release_id/git_shaduring deploy, then you can look at a risky SG or role and answer in a minute: what commit created it, who approved it, and whether prod drifted. - Assume drift will happen and design for it. Detect console changes, flag them as misconfigurations/policy breaches, and route them to the owner with context. Don’t ask security to “triage the universe.”
- Keep evidence automatic. If proving compliance means screenshots before every audit, you’ve already lost. Good DevSecOps implementation best practices make evidence fall out of automation as a byproduct of shipping.
Why DevSecOps practices are important?
If you own the release path, you’re already moving fast. The problem is the shape of risk changed: more cloud surface area, more third-party code, more toolchain sprawl, and more ways for a tiny config mistake to become a production problem. Implementing DevSecOps practices is how you keep speed while making your pipeline predictable, provable, and harder to abuse.
Benefits that show up in real org metrics:
- You ship faster without drowning in tooling. A GitLab survey found 69% of CxOs said they’re shipping at least twice as fast as a year ago, while 54% of individual contributors reported using 6–14 tools, and only 17% had started toolchain consolidation. The checklist mindset gives you fewer, stronger gates instead of five dashboards arguing with each other. s204.q4cdn.com
- Credential theft and ransomware get less room to breathe. In Verizon’s 2024 DBIR, “use of stolen credentials” was the top initial action in breaches at 24%, with ransomware close behind at 23%. Pipeline controls that block leaked secrets, enforce least privilege, and verify artifacts directly reduce the easy wins attackers keep using. Verizon
- The cost of getting it wrong is brutally high. IBM reports the average global breach cost hit USD 4.88M in 2024, with average detection and containment times of 194 days and 64 days globally. That’s why automation-heavy workflows matter. IBM also notes organizations using AI and automation save about USD 1.9M compared to those that don’t. IBM
- Supply-chain risk becomes visible instead of theoretical. GitLab’s survey says 67% of contributors reported a quarter or more of their code comes from open source libraries, yet only 21% of organizations were using an SBOM. DevSecOps practices like SBOM + signed provenance turn “we think it’s safe” into “we can prove what shipped.” s204.q4cdn.com
- Fixing vulnerabilities stops being blocked by the process. The same GitLab data points out 52% of security professionals said organizational red tape slows vulnerability fixes, and 55% said they most commonly discover vulnerabilities after code is merged into a test environment. Good practices shift discovery earlier and make ownership obvious, so fixes move like engineering work, not escalation work. s204.q4cdn.com
Read also: What Is DevSecOps - Definition, Security, and Methodology
Now, let’s dive into exact insights 👇
Gate every deploy with CMDB-aware policy checks instead of a spreadsheet of ‘rules’
"The fastest way to lose control is letting CI/CD ship whatever Terraform or Helm produced, then hoping someone notices the misconfiguration later."
After cleaning up enough post-deploy disasters, Valentin Kel, Cloudaware's DevOps, knows reactive security is just expensive cleanup work.
One boring rule keeps his team sane: nothing deploys unless the change passes policy checks that know what the asset is and where it lives. You're not asking, "Does this YAML look okay?" The question is, "Will this new S3 bucket expose customer PII in prod?"
- Start with continuous discovery. Pull every asset from AWS, Azure, and Google Cloud into your CMDB. Don't let them stay anonymous.
- Tie each one to an owner, an environment tag, and a data classification.
- Turn "vpc-a1b2c3" into "prod payment VPC owned by FinTech team." That context matters when a deploy is waiting for approval.
Cloudaware's CSPM policies like below become your actual guardrails.
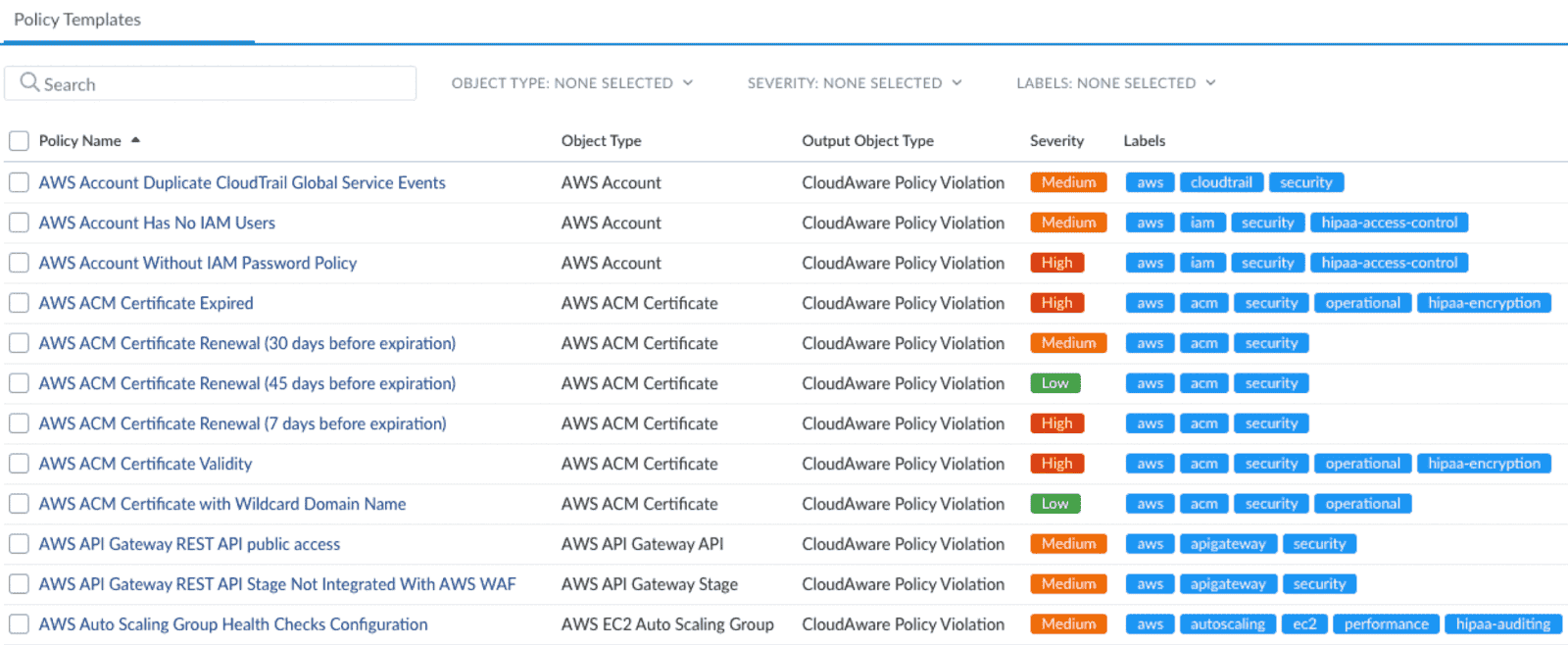
Valentin Kel's team gates on things that have caused real pain before.
Publicly reachable storage? Blocked.
Security groups wide open to the internet on admin ports? Nope.
IAM roles so permissive they're basically handing out root access? Hard pass.
Resources missing mandatory tags like owner or data_class? Not happening.
Last quarter, they caught 63 attempts to deploy storage buckets with public read access. Each one would've shipped to production on a Friday afternoon without that gate.
Ensure that the result triggers an immediate stop in your pipeline. A change that causes policy breaches in production should result in a build failure before anyone writes a postmortem about it. Valentin Kel's favorite number:
The mean time to detect dropped from 11 days to roughly four minutes.
You catch problems before the deploy button even works, which is how best practices for securing DevSecOps pipeline should feel.
But here's the thing. Blocking bad deploys only helps if your engineers aren't tab-switching through twelve different tools to figure out what broke. AI is making that problem worse, not better, and we need to talk about why consolidation just became urgent.
Consolidate the toolchain to cut context-switching (and AI makes this urgent)
Dave Steer, who's spent years studying what actually works in DevSecOps at scale, sees a pattern emerging. *“Leaders are pushing for fewer tools, tighter workflows, and way less "security duct tape" holding everything together. Teams drowning in toolchain sprawl can't move fast, even when they're talented.*” - this is his take from GitLab's 2024 Global DevSecOps Survey.
AI code assistants are generating more code faster than ever. Sounds great until you realize your security tooling wasn't built for that volume. Developers are already juggling five different dashboards to check SAST results, SCA findings, secrets scanning, and IaC policy violations.
Add AI into the mix, and you're asking humans to review 3x the output with the same fragmented workflow.
What to do instead
Pick one CI/CD control plane. Then pick one findings workflow where all security signal lands. Wire your SAST, SCA, secrets detection, and IaC scanning into that single pane of glass so developers aren't chasing alerts across multiple tools.
Cloudaware customers integrate CSPM and compliance results directly into their CI/CD pipelines.
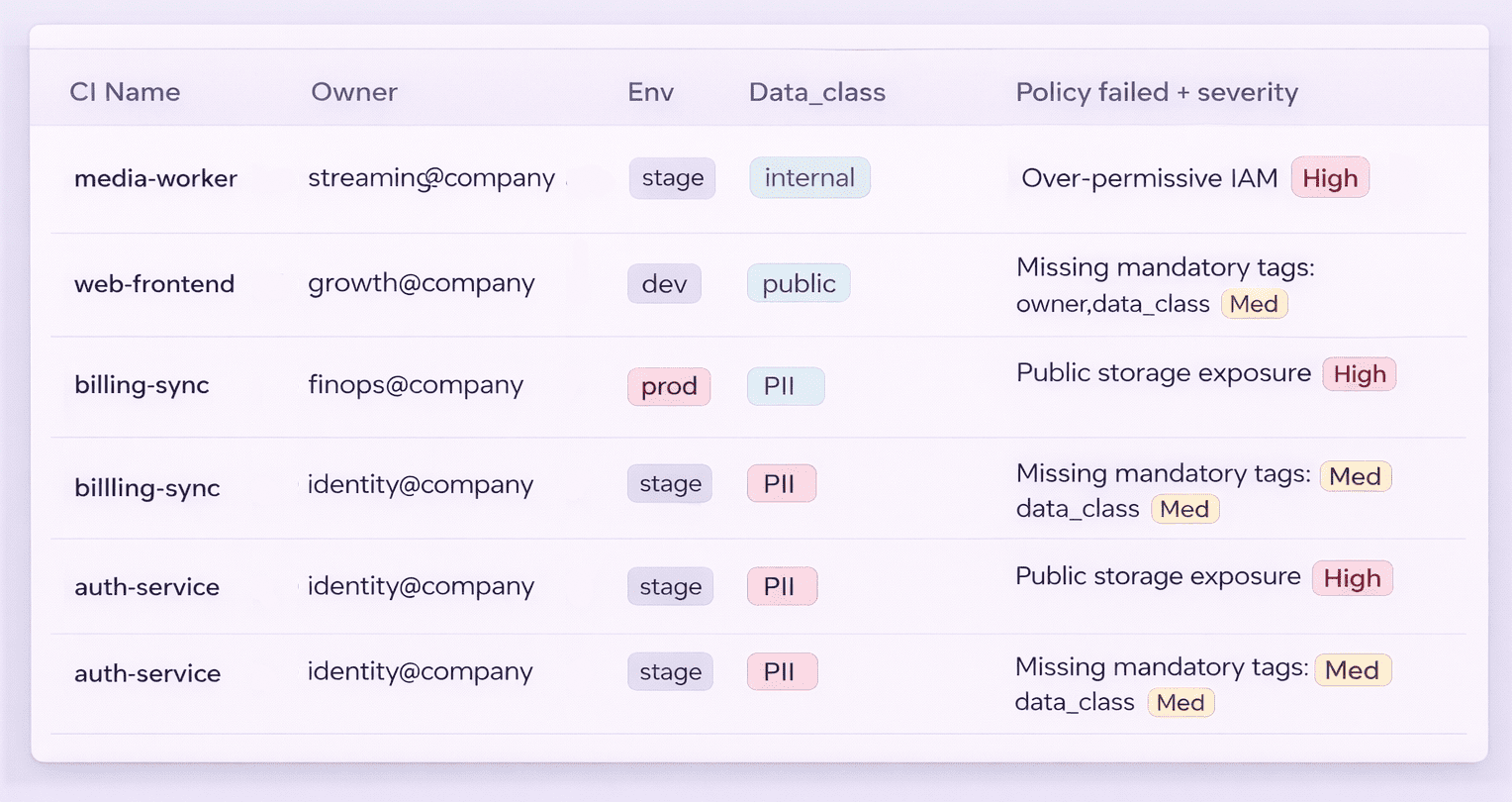
A developer sees "deploy blocked: IAM role overprivileged" right where they're already working, not buried in a separate security portal they check twice a month. The remediation guidance lives in the same place as the error message.
During one of the demo calls, Cloudaware client told me they cut their mean time to remediation by 40% just by eliminating the tool-switching tax. Developers stopped ignoring findings because they stopped having to context-switch to find them. Simple DevSecOps practices that actually stick are the ones that don't require your team to rewire their entire day.
The AI angle
When code generation speeds up, your security checks need to keep pace without adding friction. A consolidated toolchain means your gates scale with AI-assisted development instead of becoming the bottleneck. Best practices for implementing DevSecOps in 2025 have to account for the fact that your developers might be shipping 5 PRs before lunch, and every single one needs the same rigor.
Of course, consolidating tools only works if the secure path is also the easiest path. That's where golden paths come in, and they're simpler to build than you think.
Build “paved roads” so secure behavior is the easy default
Michael Bargury has watched security teams burn out trying to police every commit. In his piece on security for high-velocity engineering, he makes the case that central teams need to stop only filing findings and start shipping well-supported, optional secure building blocks instead. Auth libraries. Secrets patterns. Hardened templates. Things developers actually want to use because they make life easier, not harder.
The logic is straightforward. If your secure path requires more work than the insecure shortcut, developers will take the shortcut every single time. Not because they don't care about security, but because they're measured on shipping features, and you just made security the slow option.
How to build a golden path that people actually take
Start small. Publish one or two blessed service templates that bundle everything:
- CI configuration,
- deployment manifest,
- logging setup,
- policy checks baked in.
A developer clones the template, changes a few lines for their specific service, and they're done. Security is already there. They didn't have to think about it.
Why this works when enforcement doesn't
Enforcement pisses people off. Golden paths get adopted because they solve real problems. A developer doesn't want to figure out how to rotate secrets safely or which security group rules won't trigger an audit. Hand them a template that already handles it, and they'll use it. Implementing DevSecOps practices this way means you're building leverage, not resentment.
Michael Bargury's right that high-velocity teams need security to keep up without slowing down. Golden paths do that. But they're not enough on their own. You still need guardrails to catch the edge cases, especially in Kubernetes, where drift and misconfigurations can sneak in fast.
Enforce guardrails with Kubernetes policy-as-code
Golden paths handle the happy path. But what about the engineer who skips the template, or the manual patch that bypasses your CI/CD entirely? Joaquin Manuel Rinaudo from AWS tackled this in his piece on integrating Kubernetes policy-as-code solutions into Security Hub. His answer:
"Validate and modify configs before they land in your cluster, then continuously evaluate what's already running."
Why you need both admission control and drift scanning
Admission control stops bad configs at the gate. Someone tries to deploy a privileged pod or a container without resource limits? The request gets blocked before it touches production. You're preventing mistakes, not cleaning them up three weeks later during an audit.
Drift scanning catches what's already live. Configs change over time. A pod that was compliant last Tuesday isn't anymore because someone manually patched a deployment or updated a base image without checking policies. Continuous evaluation finds that drift before it becomes your next incident.
Build your "never again" policy library
- Build your “never again” policy library with the tools that enforce where it matters. Use Gatekeeper/Kyverno for Kubernetes admission rules (privileged pods, missing network policies, no resource limits).
- Use Cloudaware custom policies for cloud exposure and identity risks that keep showing up in postmortems (public storage, internet-facing services without TLS, over-permissive IAM, missing owner/data_class tags).
- Then wire Cloudaware policies into CI/CD so the deploy fails before misconfigurations land in prod, and your dashboards show which teams are trending down from “40+ violations per sprint” to a few edge cases.
One SRE lead wrote 12 Gatekeeper policies pulled directly from their previous year's postmortem history. Privileged containers, missing security contexts, services exposed without TLS. Violations dropped from 40+ per sprint to two or three edge cases within three months. Best practices for DevSecOps in cloud security aren't about catching everything after the fact—they're about making common failures impossible.
Integrate findings where people actually work
Pipe policy violations into your existing security view or ticketing system. Don't create another dashboard. Cloudaware customers route Kubernetes policy findings into one source of truth, showing CSPM alerts and compliance drift. Platform engineers see "namespace missing network policy" right next to "S3 bucket publicly accessible." One queue, faster fixes.
Joaquin's integration pattern uses Security Hub as the aggregation point. You're not asking teams to check five tools for five violation types. Store your Gatekeeper constraints in Git, version them, review them, and test them in CI before they go live. DevSecOps version control best practices mean treating policies like application code. Bad policy causes false positives? Roll it back the same way you'd roll back bad app code.
Start DevSecOps implementation with ownership + environment boundaries in the CMDB, then automate the rest
Most implementations fail because teams implement scanners first and governance last. You end up with 20,000 findings and nobody who can answer 'is this ours?'"
The fix: define ownership and environments as first-class data, then attach security and compliance automation to that structure.
Enforce a simple model for every asset. Build this into your CMDB from the start:
- Owner (team or service owner)
- App/service name
- Environment (dev/stage/prod)
- Data sensitivity level
- Required controls
Not optional tags. Core inventory fields that can't be skipped.
Scope policies using CMDB context
Prod environments get stricter policies and tighter thresholds. A publicly accessible S3 bucket in prod? Hard block. Same bucket in a dev sandbox? Warning with a 48-hour fix window.
Non-prod still enforces the "never again" rules. No open admin ports. No missing owner tags. No IAM wildcards in prod-adjacent accounts. One platform team cut their triage backlog by 60% once they stopped treating all findings equally and started routing based on actual risk and ownership.
Route violations to the right people
Cloudaware already knows who owns what. Violations go straight to the owning team, not into a generic security queue. "FinTech team, your prod payment service has an overprivileged IAM role" beats "Security team, please triage 400 alerts" every time.
If you're using Cloudaware's Conflux for log management, enrich logs with CMDB metadata. Investigations start with "which service/owner/env" instead of decoding resource IDs at 2am. Best practices for implementing DevSecOps mean building context into your tooling from day one, not retrofitting it when you're already underwater.
Why this order matters
Scanners without ownership create noise. Ownership without automation creates toil. DevSecOps implementation best practices start with the CMDB because everything else depends on knowing who owns what and where it lives.
Perfect inventory still doesn't tell you where attackers will actually focus their energy. That requires threat modeling, and it doesn't need to be a once-a-year ceremony buried in a wiki.
Threat model with a lightweight, repeatable frame (not a once-a-year ceremony)
Adam Shostack stripped threat modeling down to four questions that actually fit into a sprint cycle. His Four Question Framework works because it's fast and repeatable: "What are we building? What can go wrong? What will we do about it? Did we do a decent job?"
That's it. No 60-page documents. No day-long workshops that produce a PDF nobody opens.
When to run a lightweight threat model
Require 15 to 30 minutes of structured thinking for:
- Any new data flow
- Auth changes
- External integrations
- New API endpoints that touch sensitive data
One DevOps lead made this mandatory for anything that crosses environment boundaries. Their team caught an integration that would've sent customer PII to a third-party analytics tool without encryption. The threat model session took 20 minutes and saved them from a breach notification letter.
Turn outputs into backlog items using Cloudaware context
Shostack's framework generates actionable work, not artifacts. "What can go wrong?" surfaces specific threats like credential leakage or unauthorized data access. "What will we do about it?" becomes actual tickets with Cloudaware data backing them up.
Use your CMDB to ground the threat model in reality. When you ask “What are we building?”, pull the actual asset inventory from Cloudaware instead of relying on assumptions. You are not guessing which S3 buckets store customer data. You are looking at tagged resources with known classifications and owners.
When you ask “What can go wrong?”, start with Cloudaware’s existing policy violations and compliance findings for similar assets. That way, threat modeling begins from real drift and recurring failure modes, not a blank slate.
Convert threats into backlog items with acceptance criteria, then wire Cloudaware policies to verify that the controls were actually implemented.
- If the threat is “Credentials could leak through logs,” create a ticket to implement secret rotation and add a CSPM policy that detects hardcoded secrets in environment variables.
- If the threat is “Data could be accessed without authorization,” create a ticket to enforce least-privilege IAM and add a policy that flags wildcard permissions on production roles.
Best practices for DevSecOps in cloud security mean your threat model lives in Jira or Linear with Cloudaware validation built in, not in a Confluence page that gets archived after the first sprint. Controls get implemented, policies verify they're working, and you can trace each mitigation back to the threat it addresses.
Run DevSecOps like risk reduction, not “find all bugs”
Your security program generates 400 findings per sprint, but developers keep shipping the same vulnerabilities. The problem isn't that they don't care. The problem is you're optimizing for the wrong metric.
Tanya Janca has watched this pattern destroy security programs. "If security doesn't have developer buy-in, your 'shift left' becomes theater." She's right. Filing more bugs doesn't reduce risk if nobody fixes them.
Track outcomes that actually matter
Stop counting vulnerabilities found. Start measuring the risk reduced. Fewer exposed secrets in production. Shorter critical-fix windows. Reduced blast radius when incidents happen. One platform team ditched its “127 medium-severity findings” reports and started tracking “mean time to patch critical vulnerabilities,” which dropped from 14 days to 3 days. Engineering leadership actually paid attention to that number.
Cloudaware makes this trackable with real data. Pull compliance trends over quarters. Measure how long policy violations stay open by severity and owner. Show a reduction in recurring misconfigurations after you shipped that golden path template. DevSecOps security best practices mean proving your work reduces actual risk, not just generates Jira noise.
Give developers fixes, not just findings
A CVE description doesn't help anyone ship code. Developers need PR-ready fixes and working examples. When Cloudaware flags an overprivileged IAM role, include the least-privilege policy they should copy. When secrets scanning catches a hardcoded API key, link to your Vault setup with exact commands they can run.
Janca's point about velocity is critical. Tooling that punishes speed gets bypassed. Best practices for DevSecOps in cloud security mean gates that fail fast with clear remediation, not vague warnings developers learn to ignore. Security that helps teams ship faster earns trust. Security that only blocks without helping gets routed around.
Catching misconfigurations before deploy only works if you trust what you're deploying. Most teams still aren't signing their container images, which means they can't verify artifact integrity when it actually matters.
Make artifact integrity verifiable: sign + verify images, and treat provenance as first-class
If your pipeline “scans images” but can’t prove the exact image digest you built is the one you deployed, you’re basically doing security theater with nice charts. My rule is simple: artifact integrity has to be verifiable. Not “we think it came from our registry.” Verifiable.
Now, how to make it stick in best DevSecOps practices for cloud environments using Cloudaware: use Cloudaware’s CMDB context (owner, app, env) to standardize allowed registries and image sources per environment, then run policies that flag violations when runtime reality drifts from your rules (wrong repo, missing tags/ownership, unexpected workloads).
That gives you continuous evidence, not a once-per-release screenshot.
Once you trust your artifacts, the next trap shows up fast. AI/ML supply chains multiply dependencies and make typosquatting painfully easy.
Treat AI/ML supply chain as part of DevSecOps
You’ve just finished making artifact integrity verifiable. Perfect. Now the uncomfortable follow-up: AI/ML workloads quietly turn your supply chain into a jungle. Dependency trees get huge, build images get chunky, and an AI agent can “helpfully” pull a near-name package that looks right at a glance and is wrong in the one way that matters. Typosquatting loves speed.
So here’s the advice I give teams who own release workflows.
- Start by locking where dependencies can come from. Use allowlisted registries and private mirrors.
- Pin versions and, for the stuff you can’t afford to guess on, pin hashes. When you can, prefer build-from-source so you’re not trusting mystery binaries that were compiled who-knows-where. Chainguard’s angle is exactly this: source-built deps plus signed provenance and SBOMs so you can verify what you’re consuming.
- Then make it pipeline-real: SBOM + signed provenance becomes a gate for critical images and model artifacts. No SBOM, no promotion.
- Finally, shrink the blast radius. Minimal base images reduce what can be exploited and what you have to patch.
- Pair that with an aggressive patch SLA because AI stacks move fast, and old CVEs pile up fast.
And once your AI supply chain stops being a guessing game, you’ll want the next control to snap into place 👇
Every merge must be traceable to the exact resources it changed.”
You’ve locked down the AI/ML supply chain. Nice. Now you need the other half of the trust equation: when something looks risky in prod, you should be able to walk it back to a human decision in under a minute.
Version control isn’t “GitHub has commit history.” It’s being able to point at a sketchy security group or an overly-permissive IAM role and say, fast: this commit created it, this PR approved it, and this is whether prod drifted after the merge.
“If I can’t tie a cloud resource to a PR, I don’t call it controlled. I call it hope with a dashboard.”
➡️ Make every infra change carry an ID you can trace. Start in GitHub or GitLab. Require a deploy identifier on anything that can touch infrastructure: git_sha, pr_number, or release_id. Then propagate it during Terraform / CloudFormation deploys as resource tags. This is the boring move that makes the next steps possible.
➡️ Let Cloudaware connect the dots automatically. Once resources are deployed, Cloudaware discovers them and pulls those tags into the CMDB. Suddenly it’s not “sg-0d91…” anymore. It’s “payment-api, prod, owned by Team X, shipped in commit abc123.” That’s where accountability stops being a Slack debate.
“CMDB context turns ‘who did this?’ into a lookup, not an investigation.”

➡️ Validate the merge result with provider-specific guardrails. Now you’re in DevSecOps security best practices territory: enforce CSPM rules that check what the merge actually produced in the cloud. The classics still catch most outages and exposures:
- no
0.0.0.0/0to admin ports in prod - no wildcard IAM permissions for prod roles
- mandatory tags present:
owner,app,env,data_class,release_id
➡️ Make it real by detecting drift, not just scanning PRs. Here’s where teams get surprised. Someone “hot-fixes” in console on a Friday. Git never sees it. Cloudaware still will. If prod drifts, you flag misconfigurations/policy breaches against the same ownership + release context, so the right team gets pinged with evidence.
And once traceability is in place, you can finally turn this into something teams love instead of fear: a practical DevSecOps best practices checklist you can drop into any pipeline without slowing releases.
DevSecOps best practices checklist
You’ve already done the hard thinking. Now you need something your team can actually run, every day, without turning releases into a ceremony. This DevSecOps best practices checklist is the “don’t let it slip” version. Keep it close to the pipeline. Treat it like your pre-flight. If one box fails, you either fix it or you’re choosing risk on purpose.
And that’s the whole point of implementing DevSecOps practices: fewer surprises, tighter proof, faster shipping.

Experience the benefits of DevSecOps implementation with Cloudaware
Once you start running that checklist for real, you hit the same bottleneck every team hits. The controls aren’t the hard part. It’s the sprawl. Ten accounts turn into fifty. Tags drift. Someone “just fixes it in console.” Evidence goes missing right when leadership asks for it.
That’s where Cloudaware earns its keep in a DevSecOps best practices guide like this. It gives you one place to see what’s deployed, how it’s related, who owns it, and whether it still matches the guardrails you agreed on.

Cloudaware helps you ship faster by reducing the time you waste on “what is this resource and why does it exist?” and “is this actually compliant right now?” Instead of chasing resource IDs across clouds, you get operational context and enforcement signals in the same view.
What you actually use in day-to-day DevSecOps practices
- CMDB with real cloud context: auto-discovered assets across AWS/Azure/GCP and on-prem, tied to app/service, environment, and ownership, so findings aren’t orphaned.
- CSPM guardrails that understand the provider: enforce policies where they matter, per cloud, without pretending one rule fits everything.
- Tag- and CMDB-aware governance: require
owner,app,env,data_class,release_idso every resource is traceable to a team and a change. - Drift visibility: catch when prod no longer matches what went through Git, then surface the delta as a misconfiguration/policy breach with evidence.
- Evidence that falls out of automation: policy status, asset history, and ownership context that’s ready when audit questions show up.
- Optional: Conflux logging layer: auto-discovers log sources, enriches events with CMDB/tags, and makes investigations start with “which service/env/owner” instead of raw IDs.