






Teams can ship to production several times a day, yet the moment someone asks, “Who approved this, and what exactly changed?” the answer is either a shrug or a ticket written after the fact. That is why DevSecOps change management still swings between cowboy releases and a manual CAB.
This guide gives you a practical model where decisions happen at pipeline gates, evidence is captured automatically, and the audit trail outlives the CI/CD run, so you can link every change to code, an artifact, an environment, and the real CIs/CMDB state.
It also reflects Cloudaware practitioners’ day-to-day work: engineers who handle approvals and rollbacks, plus technical account managers who see what breaks first under audits and incident pressure, and how to fix it without slowing delivery.
Why DevSecOps teams still struggle with change management
CI/CD made shipping faster, but it did not make delivery controlled. In many organizations, change management still happens in meetings and message threads, so the decision trail disappears as soon as the release is done. The pain shows up when DevSecOps teams have to explain who approved a release, what risk was accepted, and whether production still matches the original intent.
The common pattern is thin approvals, after-the-fact records, and missing ownership. Someone clicks “approve” without the evidence that would make the decision defensible, the record gets written to satisfy the process, and nobody can confidently name the owner of the service or CI that moved.
Signs your change management is slowing delivery and failing audits:
- Approvals are granted, but nobody can point to the evidence
- A release is live, but the change record is created later “for compliance”
- Ownership is unclear; exceptions bounce between platform, security, and app teams
- The audit trail depends on screenshots, chat logs, or manual spreadsheets
Takeaway: If approvals, ownership, and evidence are not linked to the release, change decisions will not survive audits or incidents.
What “change” means in a DevSecOps system
A change is any modification that alters the production baseline, whether it comes from application code, configuration, infrastructure, dependencies, or identity policy.
The rule is operational: if the baseline shifts, there must be a traceable record that explains what moved, why it moved, and who owned the decision, and that record becomes your single source of truth across the software delivery system.
The point is to keep change management predictable during the development cycle, so rules improve after incidents instead of improvisation becoming the norm. What counts as a change:
- Application code merges and releases
- IaC updates
- Configuration flags and environment variable updates
- Dependency bumps and lockfile changes
- Policy/IAM changes
- Secret rotation and key material updates
- Registry base image updates
Takeaway: If production can drift from intent without a traceable record, “change control” is just a story told after the deploy.
DevSecOps change: baseline, promotion, and exceptions
Baseline is the expected production state you can validate. In practice, it is the combination of the artifact version, the configuration and policy intent, and the environment boundaries that define “what should be running,” plus the checks that make that claim defensible when someone asks later.
Promotion is the controlled movement of a specific artifact or plan between environments, with the decision recorded as an outcome. If a team can’t point to the exact artifact and the exact environment it was promoted into, then it is not a promotion.
An exception is a time-bound deviation from policy with a named owner, a reason, and an expiry date, so it can be reviewed and removed rather than becoming a permanent bypass.
This is the core shift: change management becomes the discipline of controlling promotion and exceptions, not documenting what already happened.
Read also: 9 DevSecOps Benefits for Security Leaders [With Proof]
Where change decisions should actually happen
A CAB can still exist as governance, but it should not approve every release. In fast delivery, change management belongs at the decision points that already control flow: PR merge rules, policy-as-code thresholds, and environment approvals triggered by real signals.
Control should follow the change. Put enforcement where decisions become irreversible, such as merge, artifact publish, or production deployment, and rely on tools and the delivery platform to keep outcomes repeatable.
Change decision flow:
- PR opened with scope and owner metadata
- Automated checks run
- Policy evaluation returns an explicit outcome
- Artifact build produces a versioned output tied to the PR
- Signing and provenance attach integrity metadata to the artifact
- Deployment approval enforces env boundaries and promotion rules
- Post-deploy verification validates status signals and writes a release record
Takeaway: Put approvals where the system becomes irreversible, and keep CAB focused on exceptions, not routine releases.
Policy-as-code gates vs manual approvals
| Dimension | Policy-as-code gate | Manual approval |
|---|---|---|
| Purpose | Deterministic decision on a defined rule | Time-bound risk acceptance for a specific case |
| Output | Allow / Stop / Exception required | Approved / Rejected / Approved with conditions |
| Best use | Routine, frequent changes with stable rules | Rare, high-impact, ambiguous, or emergency cases |
| Evidence | Structured signals tied to the run/artifact | Evidence summary must be linked to the same record |
| Failure mode | Over-blocking due to noisy thresholds | Rubber-stamping or inconsistent decisions |
| How it improves | Tune thresholds from outcomes and drift | Convert recurring approvals into gates over time |
Start with a minimal baseline policy you can enforce consistently, then expand it as you learn where the real risk concentrates. This keeps thresholds stable while you tune them, and it ties improvements to risk management outcomes, which is what makes change management scale.
Read also: Six pillars of DevSecOps. Practical Guide to Their Implementation in a Pipeline
Automated change management and pipeline evidence
Automated change management starts when the pipeline produces evidence tied to a specific artifact and promotion path, because that is what makes change management defensible under review and repeatable under pressure. When the delivery system emits structured facts as it runs, you get usable data for risk decisions and audit answers, and you stop reconstructing intent later from scattered tools.
This framing also matches NIST’s SSDF (SP 800-218), which treats development artifacts as evidence and emphasizes retaining that evidence so it can be shared when requested.
What auditors actually need
Auditors rarely need the full pipeline log; they need a reproducible answer for compliance questions: what changed, who approved it, which controls ran, where it was deployed, and what proves those statements.
A workable locker keeps evidence queryable by service, release, environment, and time, and protects it from silent edits after the fact. Once evidence is represented as structured data and linked across the relevant tools, CAB review becomes a review of facts and exceptions instead of a debate about whether the process was followed.
CMDB scope and “unauthorized change”
A pipeline can look perfect on paper, yet audits still fail when runtime reality does not match what the process claims happened. In ITSM terms, a service is only explainable when the change management trail points to the CIs and ownership boundaries actually affected by a change.
“Unauthorized change” is how the gap shows up in production: CI state shifts with no linked release or record, which usually means drift or an out-of-band edit worth investigating.
What unauthorized change looks like in practice (common signals):
- Drift status flips after a release window, with no corresponding promotion event
- Console edits or break-glass access appear without a linked approval/waiver
- CI relationships change without a matching release record
- A permission boundary changes while code and IaC histories stay unchanged
- Runtime configuration differs from the last known declared baseline
Takeaway: If CI reality can change without a linked record, “audit-ready” delivery is an illusion.
CMDB scoping rules for fast-moving services
Start with production services, their runtime environments, identity bindings, and the few resource classes that consistently define impact, such as registries, clusters, and cloud accounts or subscriptions. The main goal is to build an accountability map that the delivery platform can reference when a release is promoted and when drift is detected.
Change management improves when the change record points to the service, the target environment, the owner, and the CI types impacted, because approvals and risk decisions become contextual rather than generic.
Identity changes: approvals, policies, and secrets
Identity updates often have more blast radius than a code release because they redefine who can do what in production across many services at once. Treat that change surface like any other production path. When access policies are still updated through ad hoc console edits or “quick fixes,” production behavior changes without a defensible decision trail.
Secret lifecycle belongs in the same control loop: rotation, scanning, and revocation need a predictable path, not heroics. A secret leak often starts as a convenience shortcut, then becomes an incident under pressure, and teams discover they cannot prove which access was granted, when, and why.
Identity controls that should be automated (and enforced through tools):
- Policy-as-code for roles, permissions, and trust relationships
- Required review for any privilege expansion or trust boundary change
- Automated policy evaluation against environment-specific rules
- Break-glass workflow with owner, expiration, and automatic revocation
- Secret scanning in CI and pre-deploy checks for leaked credentials
- Scheduled secret rotation with verification and rollback-ready steps
- Detection and alerting for out-of-band IAM or access changes
Takeaway: If identity changes can bypass review and traceability, every other control becomes negotiable in production.
Supply chain changes: SBOM, provenance, and compliance SBOM
A dependency bump or base image update is a change that reshapes risk even when feature behavior does not move. Chain security usually fails in one predictable way: teams treat third-party components as background noise, then a transitive update or rebuild alters production without a clear answer for what changed.
SBOM closes the gap only when it is generated for the exact artifact you deploy and pinned to its immutable digest, which turns the compliance SBOM question into a lookup instead of a debate. With real SBOM management, you can answer what is inside, what changed since the last release, and whether policy thresholds were met, without trusting registry tags or rebuilding history. Treat SBOM software output as a first-class release artifact, then add provenance and signing so you can prove what the artifact is and where it came from.
What to store per release for supply chain audits:
- Artifact version and immutable digest
- SBOM generated from the built artifact, stored with a stable reference
- Dependency versions and transitive dependency snapshot
- Signing proof and provenance metadata
- Scan summaries with policy outcomes and timestamps
- Exceptions or waivers tied to the release, with the owner and expiration
- A minimal data view for “what changed since last release”
Takeaway: If your SBOM and provenance are not bound to the deployed digest, supply chain assurance turns into guesswork.
The matured change management process: signals and feedback loops
A matured change management process shows up when change management no longer depends on heroics and tribal knowledge. You see it in standardized workflows, automated decisions, and how consistently teams can defend why a release was allowed, blocked, or granted an exception. Use the ladder as a diagnostic. The signal is variability: where two engineers looking at the same change reach different outcomes, where exceptions never expire, or where evidence is complete in one service and missing in another, even when the delivery platform looks “green.”
Use the ladder as a diagnostic. The signal is variability: where two engineers looking at the same change reach different outcomes, where exceptions never expire, or where evidence is complete in one service and missing in another, even when the delivery platform looks “green.”
Feedback loops are what make maturity compound. Turn post-deploy outcomes into rule updates so the system improves through metrics:
- Promote recurring incident patterns into explicit policy thresholds and required checks
- Convert common manual approvals into automated rules
- Tighten rollback criteria when the change failure rate rises, then validate with post-deploy verification
- Track exception reasons and expirations, and retire rules that generate noise
- Use deployment status signals to confirm intent matches production
Read also: DevSecOps Maturity Model. A Practical Scorecard You Can Measure, Store, and Improve
Okta’s view on maturity: KPIs and accountability
Okta frames maturity as the point where delivery decisions stay explainable under review because governance is embedded in how work moves through the system. Mature practices connect risk signals and compliance expectations to measurable outcomes, and they make ownership visible at the service level so exceptions have an accountable home.
| KPI | What to do when it moves the wrong way |
|---|---|
| Lead time for change | Identify where gates stall, then automate evidence capture earlier |
| Change failure rate | Tighten the relevant gate and improve quality signals before promotion |
| MTTR | Standardize rollback paths and post-deploy validation |
| % automated approvals | Convert repeatable approvals into policy thresholds and documented exceptions |
| Approval latency | Narrow manual approvals to true exceptions and high-risk changes |
| % releases with complete evidence | Fix missing linkage so release data ties artifact, target, and approval together |
Read also: 13 DevSecOps Metrics for 2026. What to Measure and Why?
Release management, rollback discipline, and post-deploy verification
Release management needs a durable record you can pull up months after the run: the artifact digest, the configuration version that was applied, the target environment, the checks summary, and any approvals or waivers that allowed promotion. When that record is complete, the release stays explainable across the software lifecycle, and production status can be traced to a concrete version instead of a guess.
Post-deploy verification is part of managing change, not an optional add-on. Drift detection, smoke checks, and runtime policy verification tell you whether production still matches intent, and they give the delivery platform a reason to stop promotion when post-deploy status disagrees with the release record
Takeaway: A release is only defensible when post-deploy checks can prove the deployed record still matches production.
Post-deploy drift
Runtime drift usually points to one of two failures: a change happened out of band, or the system does not track the class of changes that actually moved production. The teams that handle this well do not debate whether drift is “expected”; they ask which gate, ownership link, or CI scope rule would have surfaced before it became production behavior.
When a drift alert fires, the follow-up updates something specific: a policy threshold, a required check, an exception workflow, or the CMDB scope for that service, so the next release blocks the same pattern or captures it as an explicit exception. If runtime events do not update delivery rules, the system does not learn, and incidents repeat with slightly different symptoms.
Implementation blueprint: tools, data model, and operating cadence
The fastest implementations start with a release record schema and an ownership map. A vendor-neutral blueprint links tools through one traceability thread across software development: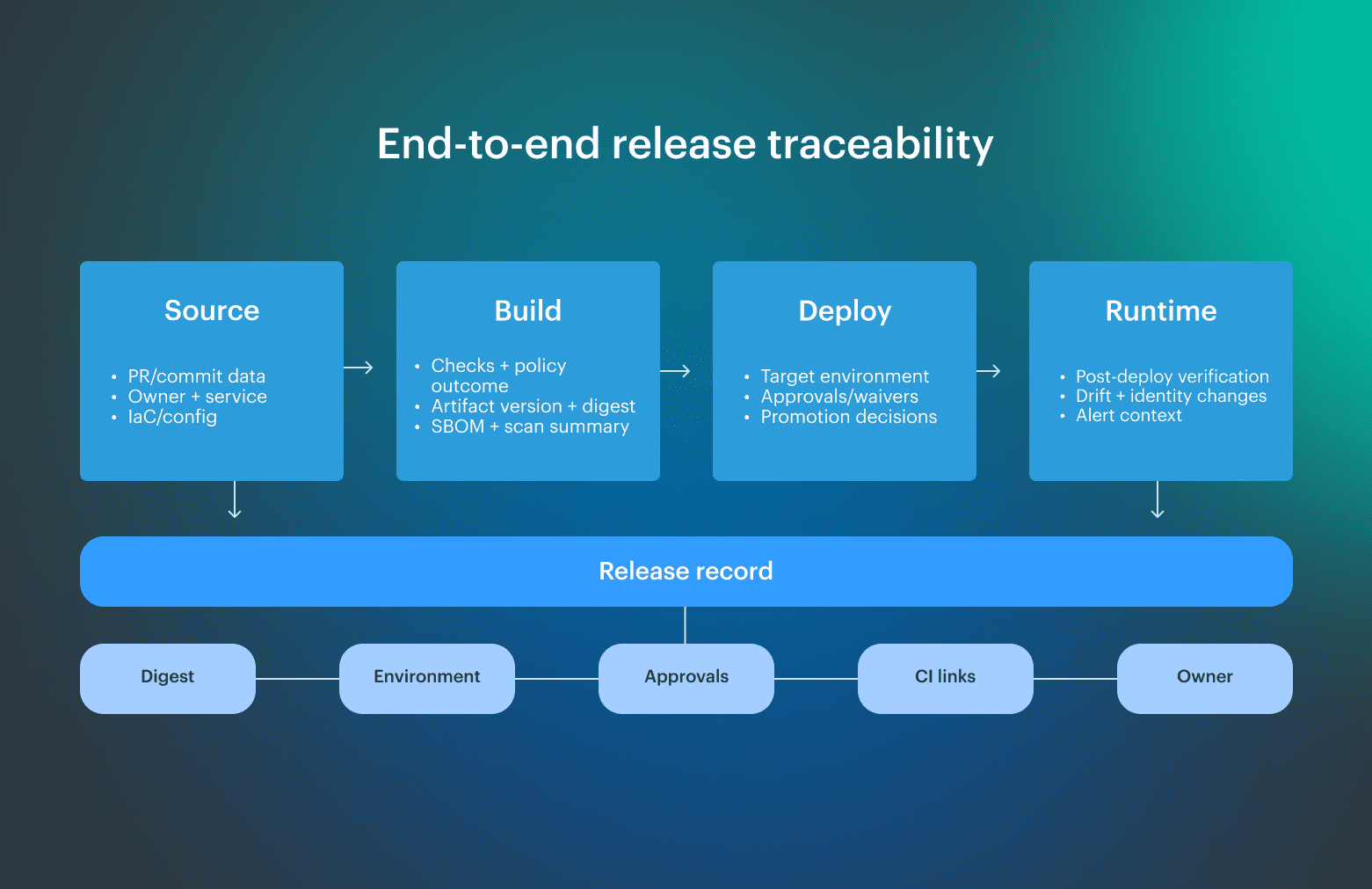 Operating cadence is what keeps the model from rotting. Run a weekly exceptions-and-incidents review that produces concrete rule updates, a monthly policy and CMDB-scope tune-up, and a quarterly maturity check that uses one overview dashboard to confirm the system is learning. This turns a DevSecOps transformation into a structured approach to handling alterations in software development.
Operating cadence is what keeps the model from rotting. Run a weekly exceptions-and-incidents review that produces concrete rule updates, a monthly policy and CMDB-scope tune-up, and a quarterly maturity check that uses one overview dashboard to confirm the system is learning. This turns a DevSecOps transformation into a structured approach to handling alterations in software development.
First 2 weeks plan:
- Define the minimum release record fields your team will enforce
- Agree on service ownership and environment boundaries
- Pick 1-2 gates that already cause hesitation and formalize them
- Stand up evidence storage and retention rules
- Implement a CMDB scope MVP for production services only
- Create an exception workflow with owner, reason, and expiration
Takeaway: Start with the release record and ownership contract, then connect tools and cadence around that spine.