






Security controls lose value when they no longer lead to predictable delivery decisions, because findings surface without a clear agreement on whether they should block, warn, or simply be observed. In this state, security may be present at every stage of the pipeline, but the DevSecOps toolchain itself fails to operate as a coherent system.
This guide treats the DevSecOps toolchain as a structured set of decision points that connect detection, enforcement, and remediation across the delivery lifecycle.
The goal is to show how to build a secure toolchain that remains predictable under constant change, enforces risk boundaries teams understand, and produces outcomes that can be trusted operationally and during audits.
What is a DevSecOps toolchain
A DevSecOps toolchain is how security decisions are wired into the delivery pipeline so teams know what can move forward and what must stop. It defines where security checks run, which results actually matter, and how those results affect pull requests, builds, deployments, and runtime changes, instead of leaving security to dashboards and after-the-fact reviews.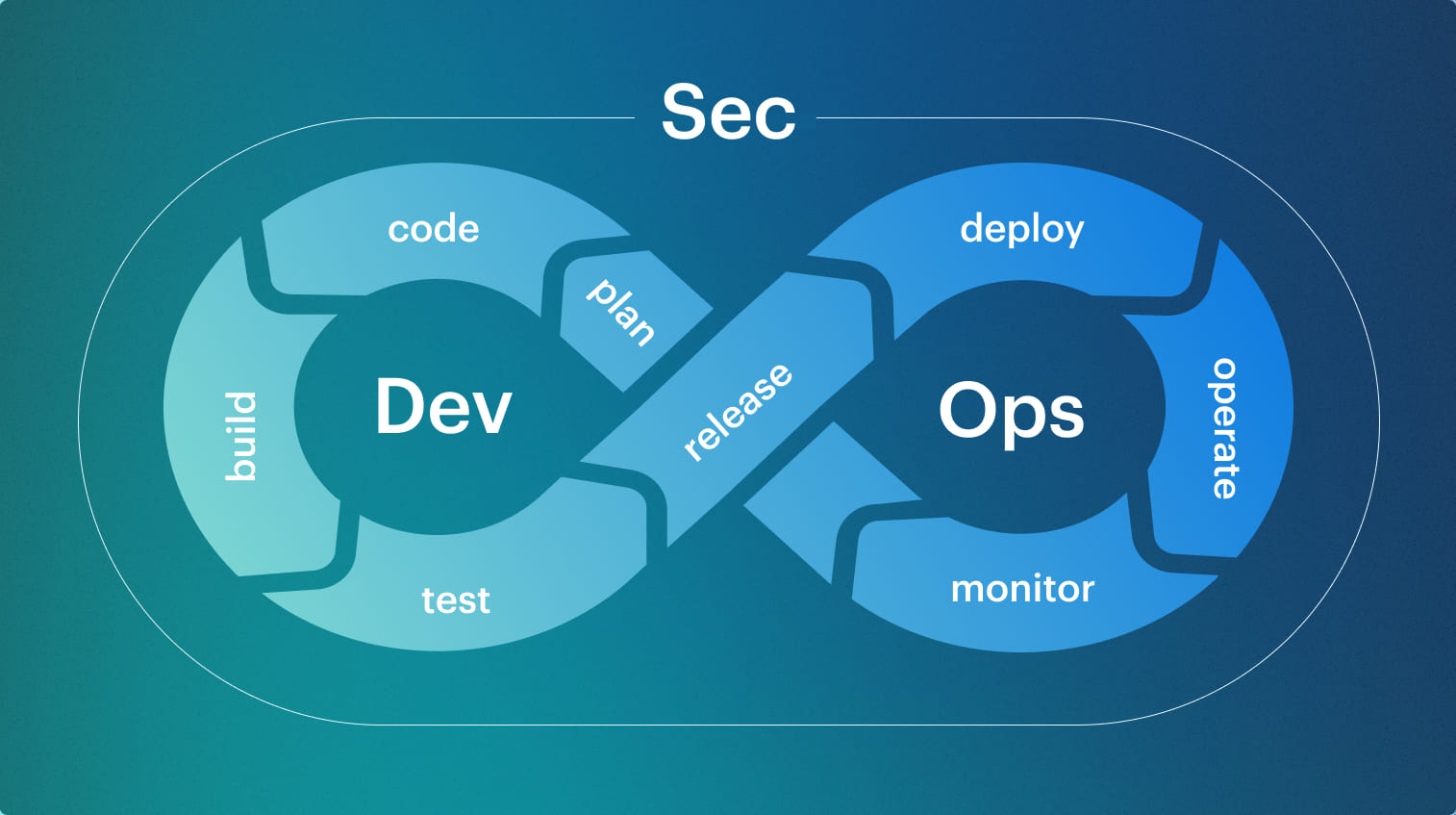 A DevOps toolchain focuses on building and shipping changes reliably, while a DevSecOps toolchain introduces security decision points that are enforced the same way every time. The difference is not the number of scanners, but the existence of clear rules for when security blocks a change, when it warns, and when it simply records signal.
A DevOps toolchain focuses on building and shipping changes reliably, while a DevSecOps toolchain introduces security decision points that are enforced the same way every time. The difference is not the number of scanners, but the existence of clear rules for when security blocks a change, when it warns, and when it simply records signal.
A collection of security tools that report into separate dashboards is not a DevSecOps toolchain, even if every SDLC stage is technically covered. When findings are produced without shared decision points and ownership, security outcomes drift toward manual review, and the pipeline stops being the place where risk is actually decided.
The practical boundary is simple: a DevSecOps toolchain exists only when security signals influence promotion in a consistent way
In practice, this means combining CI/CD orchestration with application and dependency checks, infrastructure validation, artifact integrity controls, deploy-time policy enforcement, runtime visibility, and governance layers that connect findings to owners and verified fixes, so security decisions remain part of delivery instead of becoming post-release analysis.
What a DevSecOps toolchain really is (and why tool sprawl happens)
A DevSecOps toolchain grows uncontrollably when security is added one control at a time without a shared decision model. Each new requirement introduces another tool, each team integrates it locally, and the result is an environment where dozens of tools produce signals that are difficult to compare, prioritize, or act on in a consistent way.
Tool sprawl usually comes from three systemic causes: What makes these problems hard to undo is that they tend to become embedded in delivery workflows. Once tool-specific severity models are wired into promotion logic, ownership is implied by pipeline structure, and exceptions are handled informally, reversing those decisions later requires coordinated changes across multiple teams and systems rather than a simple tooling swap.
What makes these problems hard to undo is that they tend to become embedded in delivery workflows. Once tool-specific severity models are wired into promotion logic, ownership is implied by pipeline structure, and exceptions are handled informally, reversing those decisions later requires coordinated changes across multiple teams and systems rather than a simple tooling swap.
A DevSecOps toolchain only becomes effective when it is treated as a system rather than a collection of tools. Security controls need to be connected through shared policies, consistent enforcement points, and clear ownership, so that findings lead to decisions and decisions lead to fixes instead of adding more noise to an already crowded pipeline.
DevSecOps toolchain security: what “secure” actually means
DevSecOps toolchain security breaks when outcomes depend on where an issue is detected instead of what risk it introduces. When the same issue blocks a pull request, passes a build with a warning, and reaches production unchanged, teams end up renegotiating decisions repeatedly and the pipeline stops being trusted as an enforcement mechanism.
A secure DevSecOps toolchain fixes this through ownership, not by adding more controls. Application security owns policy and decides which risks block promotion, while the pipeline applies those decisions consistently. Controls are placed only where they can affect promotion, results are evaluated with context, and blocking behavior follows application security policy rather than tool-specific severity labels or local overrides.
Identity, secrets, and access control
In a DevSecOps toolchain, identity determines blast radius, and most failures come from unclear boundaries. Reused service accounts, shared identities across stages, and long-lived credentials collapse the distinction between CI execution and runtime behavior, so a single leaked secret can affect systems it was never meant to touch.
A secure setup enforces clear separation. CI identities are distinct from runtime service identities, and human access is not reused for machine execution. Identities are scoped to a single stage, credentials are short-lived, and secrets are issued based on execution context rather than static configuration.
Access exists only while a job runs and only for the resources it requires, which limits impact by default instead of relying on cleanup after the fact.
Supply chain and dependency security
Dependency security stops working when vulnerability scanning produces lists instead of decisions. Teams see CVEs and advisories, but cannot tell whether a dependency is actually used in a deployed path, whether the vulnerable code is reachable, or which service owner is expected to act, so findings circulate without affecting delivery.
The decision point for dependency risk has to exist before artifact promotion. Supply chain security starts to work only when vulnerability data is evaluated in the context of real application usage and ownership, and when the outcome of that evaluation determines whether the build can proceed, is allowed with conditions, or is blocked.
At that point, the backlog collapses into a small set of issues teams can close as part of normal delivery rather than an external security queue.
Infrastructure guardrails
Infrastructure risk becomes expensive once it reaches runtime. A misconfiguration discovered after deployment forces teams into rollback, emergency changes, or explicit risk acceptance in production, none of which scales with frequent releases or predictable delivery.
IaC management and IaC scanning exist to prevent that outcome by enforcing guardrails, not by reacting after the fact. Guardrails fail non-compliant changes before promotion and stop known risks from entering runtime, while runtime alerts and investigations act as compensating controls when prevention was incomplete.
Treating compensating controls as a substitute for guardrails shifts decision-making downstream and turns infrastructure security into continuous cleanup instead of controlled change.
Read also: 4 DevSecOps Implementation Steps That Hold Under Release Pressure
DevSecOps toolchain reference architecture
A DevSecOps toolchain reference architecture shows how a change moves through the delivery pipeline and at which points security can stop or allow that change. Security controls are placed where they can influence outcomes, but not every control is meant to block change. Some exist to enforce promotion decisions, while others exist to detect drift or exposure after deployment and route remediation back to the owning team rather than retroactively questioning earlier approvals.
Security controls are placed where they can influence outcomes, but not every control is meant to block change. Some exist to enforce promotion decisions, while others exist to detect drift or exposure after deployment and route remediation back to the owning team rather than retroactively questioning earlier approvals.
The pipeline relies on a system-of-record layer to keep these decisions coherent over time. Asset data defines what exists and who owns it, change records capture what was modified and when, and evidence explains why a change was allowed or blocked, which keeps security signals tied to real cloud resources and changes without reconstructing context later.
Read also: DevSecOps Framework in 2026 - How to Choose the Right One
DevSecOps technology stack by SDLC stage
A DevSecOps technology stack is easier to reason about when it is mapped to work that needs to get done at each stage of the SDLC and to the concrete artifacts those stages produce. This avoids tool-first discussions and keeps the focus on decisions, ownership, and outputs rather than on accumulating more tools.
Below is a stage-based view that reflects how DevSecOps technologies are typically used in practice, without naming vendors or ranking products.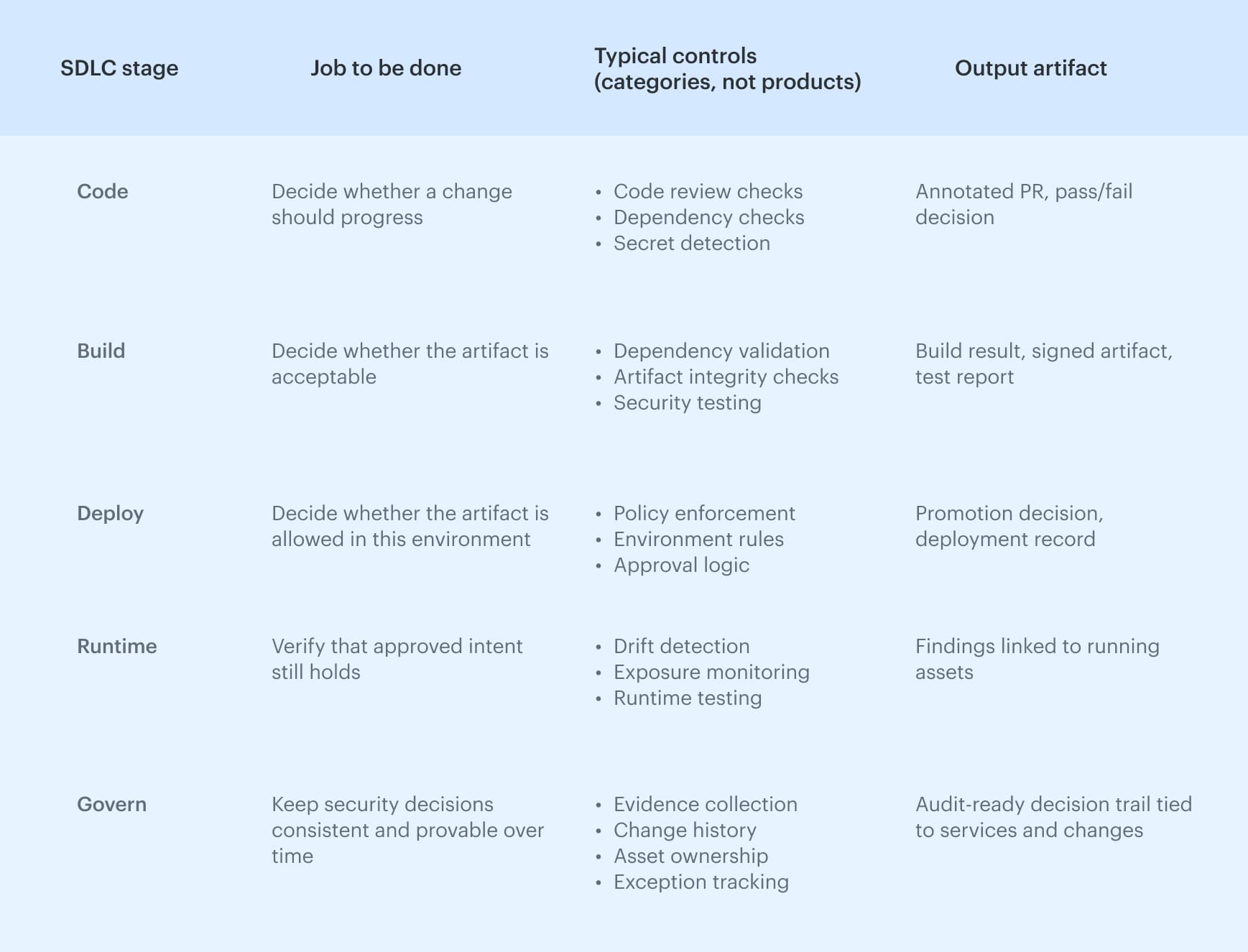 This view highlights how tools fit into the system without turning the stack into a catalog. Each stage answers a specific question and produces an artifact that feeds the next decision, which is what keeps a DevSecOps pipeline predictable as it scales.
This view highlights how tools fit into the system without turning the stack into a catalog. Each stage answers a specific question and produces an artifact that feeds the next decision, which is what keeps a DevSecOps pipeline predictable as it scales.
Read also: What Breaks in Delivery When DevSecOps vs SDLC is Misunderstood
How to build a DevSecOps toolchain (step-by-step)
Building a DevSecOps toolchain is rarely about adding new tools. The harder part is aligning existing security signals with clear decision points, ownership, and enforcement so outcomes stay consistent as pipelines and teams scale.
In practice, a DevSecOps toolchain is assembled by defining where decisions are made, which signals influence them, and how results flow back into engineering and management processes.
The order matters, because enforcing controls before decisions are predictable usually increases noise, creates bypasses, and trains teams to work around the pipeline instead of with it.
A practical build sequence that works
- Pick a single place where promotion decisions are made. If merges, releases, and deployments are controlled by different systems, the toolchain will never behave consistently, no matter how many security tools are added
- Define severity bands that translate directly into action. Use a small, fixed set of outcomes such as block, allow with warning, and record only, and apply them everywhere so decisions do not depend on the repository or the team
- Start with a small number of signals that reliably change risk. Secret exposure, exploitable dependency risk, high-impact IaC misconfigurations, and asset exposure are enough to establish signal quality before expanding coverage
- Assign ownership before you scale coverage. Every signal needs a clear owner, a remediation path, and an explicit closure condition, otherwise findings accumulate without resolution
- Add deploy-time guardrails only after early gates are stable. Deployment policies should be deterministic and environment-scoped, while runtime controls are used to verify drift, not to correct upstream inconsistency
- Capture evidence as part of normal flow. Blocks, approvals, overrides, and closures should leave a trace tied to the change and the owning service, so audits and incident reviews do not depend on reconstruction after the fact
Integrating security into the DevSecOps toolchain
Integrating security into the DevSecOps toolchain works only when controls are anchored to delivery decisions rather than added as parallel review steps. The patterns below show where security testing and application security checks belong in practice, and how DevSecOps tools are used to influence outcomes without turning the pipeline into a negotiation.
A PR-first pattern places the earliest security signal where developers still have full context and fast feedback. Code, dependency, and configuration checks run as part of pull requests, and their results are used to decide whether a change is even eligible to move forward, not to populate a backlog that gets reviewed later.
Build gates focus on the artifact, not the code diff. Security testing at this stage validates what is actually being produced and promoted, which makes application security outcomes consistent across repositories that share build logic. If a build gate fails, the artifact does not exist, which avoids downstream exceptions.
Deploy gates answer a different question: whether this artifact is allowed in this environment. Policy enforcement at deployment is environment-scoped and deterministic, so the same artifact can be allowed in one context and blocked in another without rewriting earlier rules or re-running unrelated checks.
The runtime loop is not a substitute for earlier controls. Runtime signals are used to verify that approved intent still holds by detecting drift, exposure changes, or unexpected behavior, and to route remediation back to the owning team rather than retroactively questioning promotion decisions.
Exceptions are treated as controlled changes, not silent bypasses. When a control is overridden, the decision is explicit, time-bound, and tied to ownership, so exceptions do not accumulate invisibly and application security does not degrade over time under delivery pressure.
Anti-pattern: using runtime findings to reopen promotion decisions
Using runtime findings to revisit promotion decisions breaks the toolchain. When issues discovered after deployment are used to question earlier approvals, upstream gates lose authority and teams begin to route around them to keep releases moving.
In a stable DevSecOps toolchain, promotion decisions are not reopened. Runtime findings trigger remediation through normal change ownership and follow-up work, rather than retroactive enforcement, which keeps security behavior predictable and prevents the pipeline from turning into a permanent exception loop.
Read also: DevSecOps vs CI/CD: How to Build a Secure CI/CD Pipeline
From findings to fixes: how toolchain signals become action
Security only improves outcomes when signals turn into owned work with a clear end state. Most DevSecOps tools can detect issues, but without context and routing, vulnerabilities remain open, dashboards grow, and management ends up chasing status instead of reducing risk. The missing step is a consistent path from finding to fix that teams recognize as part of normal delivery.
The table below shows how common signals move through a DevSecOps toolchain when that path exists.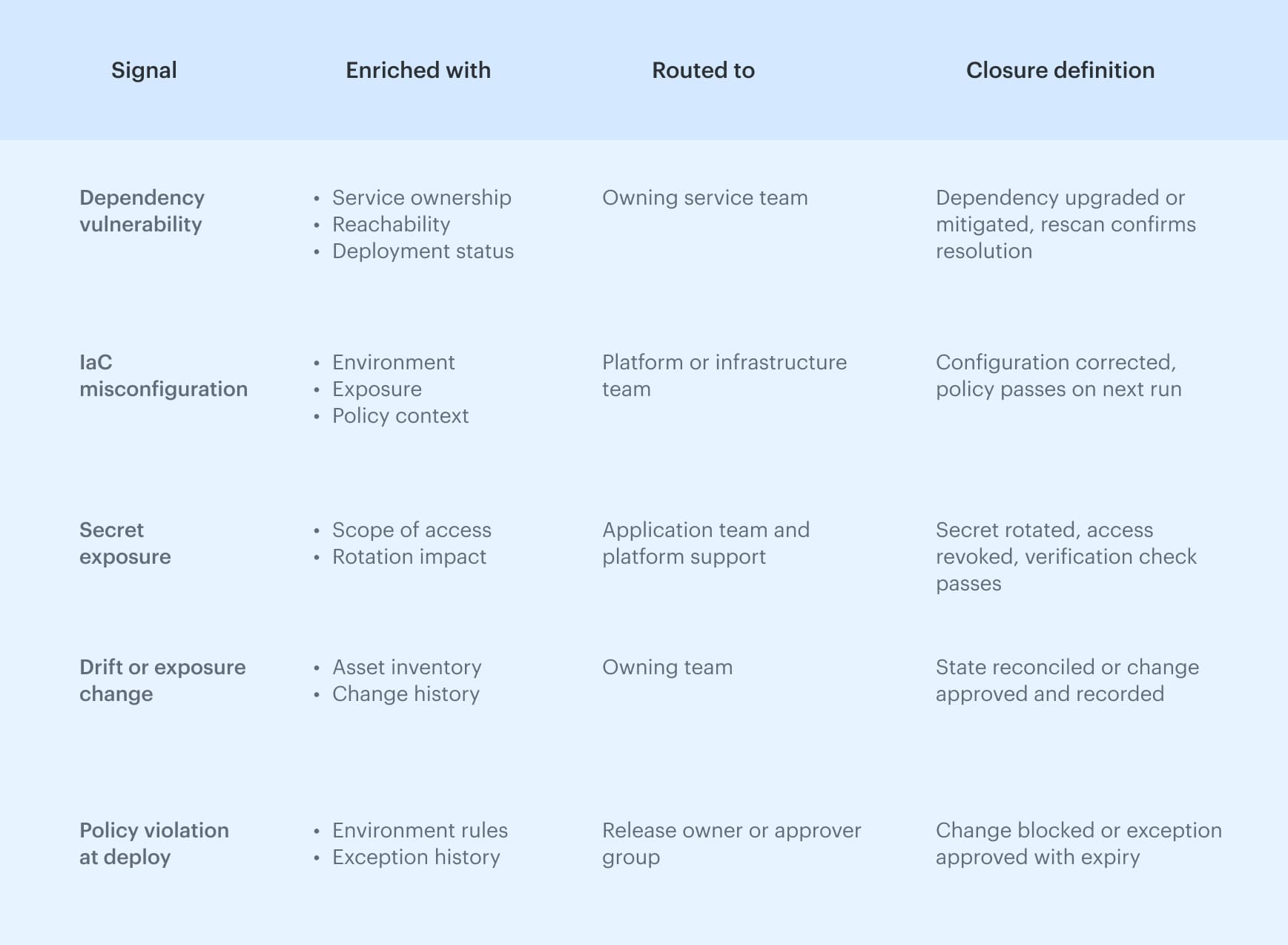 What determines whether this works is not the detection tool, but the closure definition attached to each signal. Ownership, exposure, and deployment context decide who acts, but closure criteria decide when the issue actually leaves the system instead of lingering as a permanent warning.
What determines whether this works is not the detection tool, but the closure definition attached to each signal. Ownership, exposure, and deployment context decide who acts, but closure criteria decide when the issue actually leaves the system instead of lingering as a permanent warning.
Routing must be explicit. Each signal maps to a single owning team and a defined remediation path, which keeps collaboration focused and prevents issues from bouncing between queues. Closure is verified by a concrete outcome, not by acknowledging an alert, so management can track progress without manual reconciliation.
How Cloudaware supports DevSecOps across the toolchain
Within a DevSecOps toolchain, Cloudaware is used as a shared layer for tying security signals to assets, changes, and ownership. These capabilities do not replace CI/CD systems, scanners, or runtime enforcement tools.
- Centralized asset inventory with relationships. A unified CMDB that maintains an up-to-date view of cloud and infrastructure assets, including relationships between resources, services, and environments. This establishes a reliable base for ownership, impact analysis, and routing.
- Continuous change tracking and history. Persistent tracking of infrastructure and configuration changes over time, showing what changed and when. This allows security and platform teams to link findings to concrete changes instead of working from point-in-time snapshots.
- Policy-driven change governance. Change decisions are evaluated against policy conditions using asset and environment context at the governance layer, keeping approval logic consistent without coupling it to CI/CD execution.
- Ownership context for assets and findings. Assets and changes are associated with owning teams or services, enabling findings to be routed automatically to the correct owners without manual triage or cross-team escalation.
- Audit-ready evidence and decision traceability. Asset state, change history, approvals, and exceptions are preserved as part of normal operations, allowing teams to explain and prove security decisions later without reconstructing context from tickets, logs, or spreadsheets.
Across all stages, Cloudaware acts as a system of record for assets, changes, and evidence. This keeps DevSecOps workflows traceable over time, allows teams to prove why decisions were made, and lets management track remediation without reconstructing context from multiple tools, tickets, or dashboards.