






GCP DevSecOps gets messy when teams try to bolt security onto a delivery path that was never designed to carry trust. In Google Cloud, the friction usually shows up in broken feedback loops, too many handoffs, disconnected CI/CD and artifact workflows, context switching between tools, and identity models that still depend on long-lived keys instead of short-lived trust.
This guide shows what DevSecOps looks like when it is built as an operating model:
- How does Google Cloud DevSecOps handle artifact trust?
- How does DevSecOps in GCP fit enterprise delivery?
- Where do Google Cloud services actually reduce risk instead of adding more process?
TL;DR
- GCP DevSecOps is a control model, not a list of Google Cloud services.
- The strongest enforcement point is usually pre-deploy, when artifact trust, policy, identity, and environment scope can still stop a bad release.
- Mature teams keep the block path narrow and leave noisy signals in warn or monitor.
- Most failures come from weak mechanics: broad access, weak ownership, soft approvals, and detached runtime evidence.
GCP DevSecOps in enterprise cloud delivery
GCP DevSecOps uses the same base as DevOps, but keeps security inside the delivery path instead of treating it as a separate review step. On Google Cloud, that means build, artifact storage, deployment, runtime, and observability stay in one operating path.
For enterprise teams, the difference between “using GCP” and “running DevSecOps on GCP” is straightforward. One hosts workloads in a cloud. The other turns that cloud into a governed execution layer with trusted builds, controlled promotion, workload identity, and policy enforcement tied to the same path.
A workable GCP DevSecOps model usually combines four layers around the same delivery path:
- Delivery: repos, CI/CD, promotion, runtime rollout
- Control: testing, policy gates, artifact trust, runtime checks
- Identity: IAM, service accounts, federation, scoped access
- Evidence: attestations, logs, approvals, runtime verification
What is GCP in DevOps?
GCP in DevOps is the execution layer where code moves through build, artifact handling, deployment, runtime, and observability.
GCP gives teams managed services for CI/CD, artifact storage, runtime, and monitoring, so delivery can run through one repeatable platform path instead of a loose set of handoffs.
That foundation becomes GCP DevSecOps when the same path also carries policy checks, artifact trust, identity boundaries, and runtime verification.
How GCP fits a multi-cloud DevSecOps platform
In an enterprise, GCP usually sits next to other cloud platforms, internal systems, and external developer tooling. Mature teams don't treat Google Cloud as a self-contained stack. They use it as one execution layer inside a wider DevSecOps platform.
That only works when a few things stay consistent across clouds: identity boundaries, artifact trust, approval points, and the evidence path from commit to runtime. If those change per provider, the release model starts to fragment. GCP then becomes another special case instead of part of the same delivery system.
Read also: DevSecOps Compliance. CI/CD Controls, Evidence, and SOC 2
GCP DevSecOps for multi-cloud enterprise teams
In an enterprise, GCP rarely stands alone. It usually sits inside a wider delivery platform that already includes other cloud providers, shared identity systems, internal platforms, and multiple CI/CD paths.
That is the difference between a cloud deployment and a DevSecOps operating model. In a mature setup, a workload doesn't get a different trust model just because it lands on a different provider.
Why mature teams treat GCP as part of a wider DevSecOps platform
Mature teams don't let GCP become a provider-specific side path with its own release logic. The same ownership model, control points, artifact flow, identity boundaries, and evidence path need to hold across clouds, even when the underlying services differ.
The artifact becomes the unit of trust. It is built once, evaluated once, and promoted through environments without changing the rules around it.
Where DevSecOps ownership lives in enterprise platform teams
Application teams own code changes and release health. Platform engineering owns the paved road: pipeline patterns, artifact handling, deployment automation, and identity integration. Security engineering owns policy logic and the trust model around artifacts, approvals, and enforcement.
Routine releases should stay inside the system. Humans handle exceptions, not normal deployments. That is what turns DevSecOps from a loose collaboration model into something that holds under pressure.
Read also: DevSecOps Culture. Operating System Keeping Security Fast
Google DevSecOps starts with a trusted delivery system
Google DevSecOps only works when security stays inside the same delivery process that moves code toward production. It isn't a second track after development, and it isn't a review layer bolted onto release day.
In real systems, controls belong at the moments that change state:
- When code becomes a build
- When a build becomes an artifact
- When an artifact is approved for deployment
- When runtime signals confirm what actually shipped
DevSecOps Google teams put decisions where they can be enforced and where ownership is still clear. If a control depends on someone interpreting it under pressure, it isn't part of the system yet.
The DevSecOps pipeline from source to runtime
DevSecOps pipeline carries two things at the same time: the change itself and the evidence needed to move it forward.
Repo and PR gates reduce obvious risk early, but they don't make a release trustworthy on their own. Trust gets stronger when the build produces a specific artifact, that artifact becomes the unit of promotion, and later controls verify the exact thing being deployed rather than a loose version of it.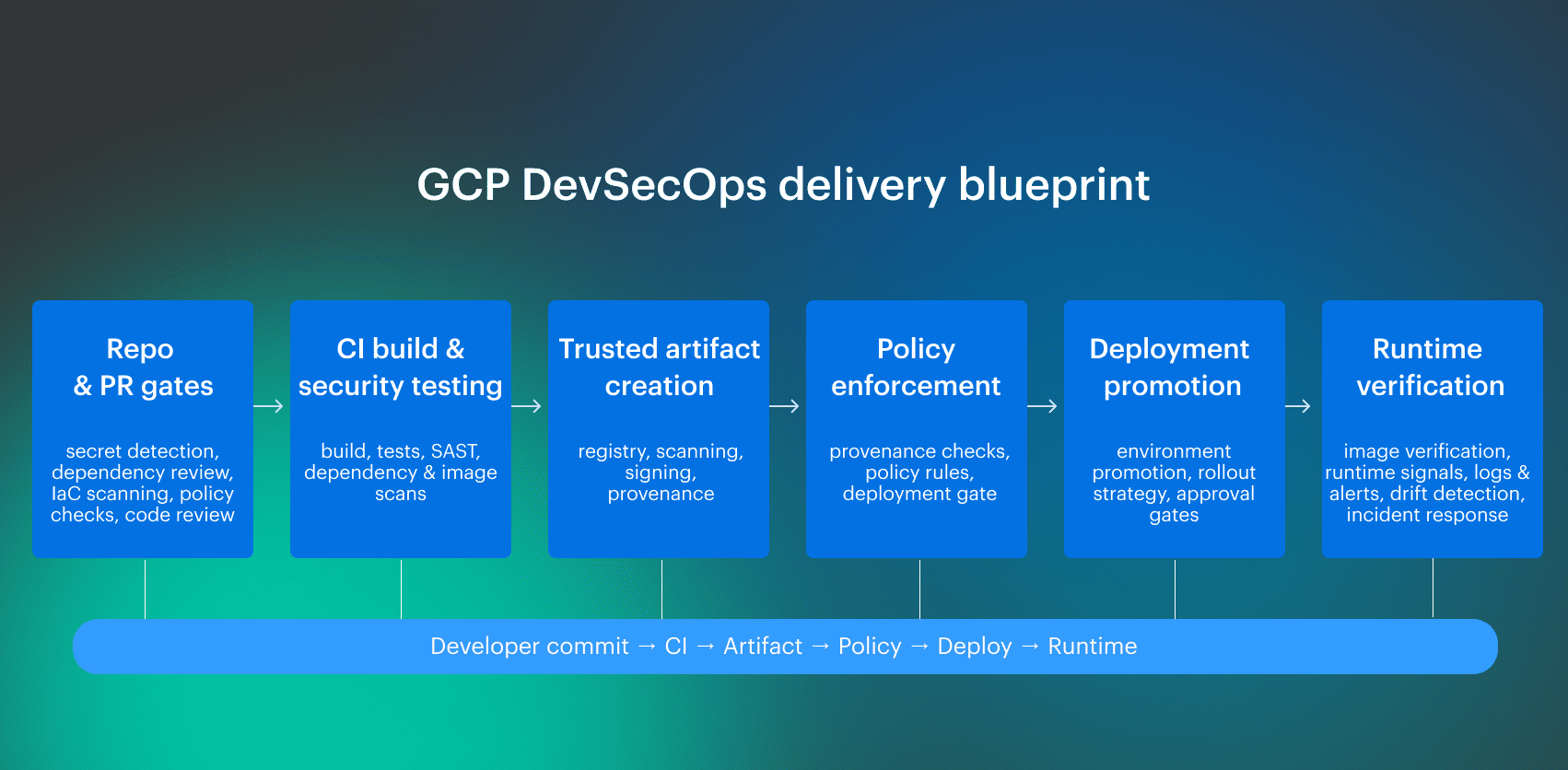 The real value of the pipeline is that it turns security from commentary into enforcement. A finding is no longer just information someone may review later. It becomes a condition that shapes whether the change can move at all. That is the difference between a CI/CD flow with security tooling and a DevSecOps operating model.
The real value of the pipeline is that it turns security from commentary into enforcement. A finding is no longer just information someone may review later. It becomes a condition that shapes whether the change can move at all. That is the difference between a CI/CD flow with security tooling and a DevSecOps operating model.
Read also: My Kubernetes DevSecOps Implementation Playbook
How a GCP DevSecOps pipeline works in practice
In a mature GCP DevSecOps setup, the pipeline is there to decide whether a change has earned the right to run. That sounds obvious, but this is where many rollouts go soft. Teams run scans, collect reports, and still promote artifacts based on habit, pressure, or incomplete context.
In GCP, DevSecOps implementation flow only works when trust moves with the artifact, not with a ticket, a screenshot, or somebody’s memory of what passed earlier. That creates a simple operating rule:
- Build once: Produce one release candidate
- Evaluate once: Attach the required checks and decisions to that exact build
- Promote the same artifact forward: Move the approved artifact across environments without rebuilding it
The pipeline stops acting like a transport layer and starts acting like an enforcement path.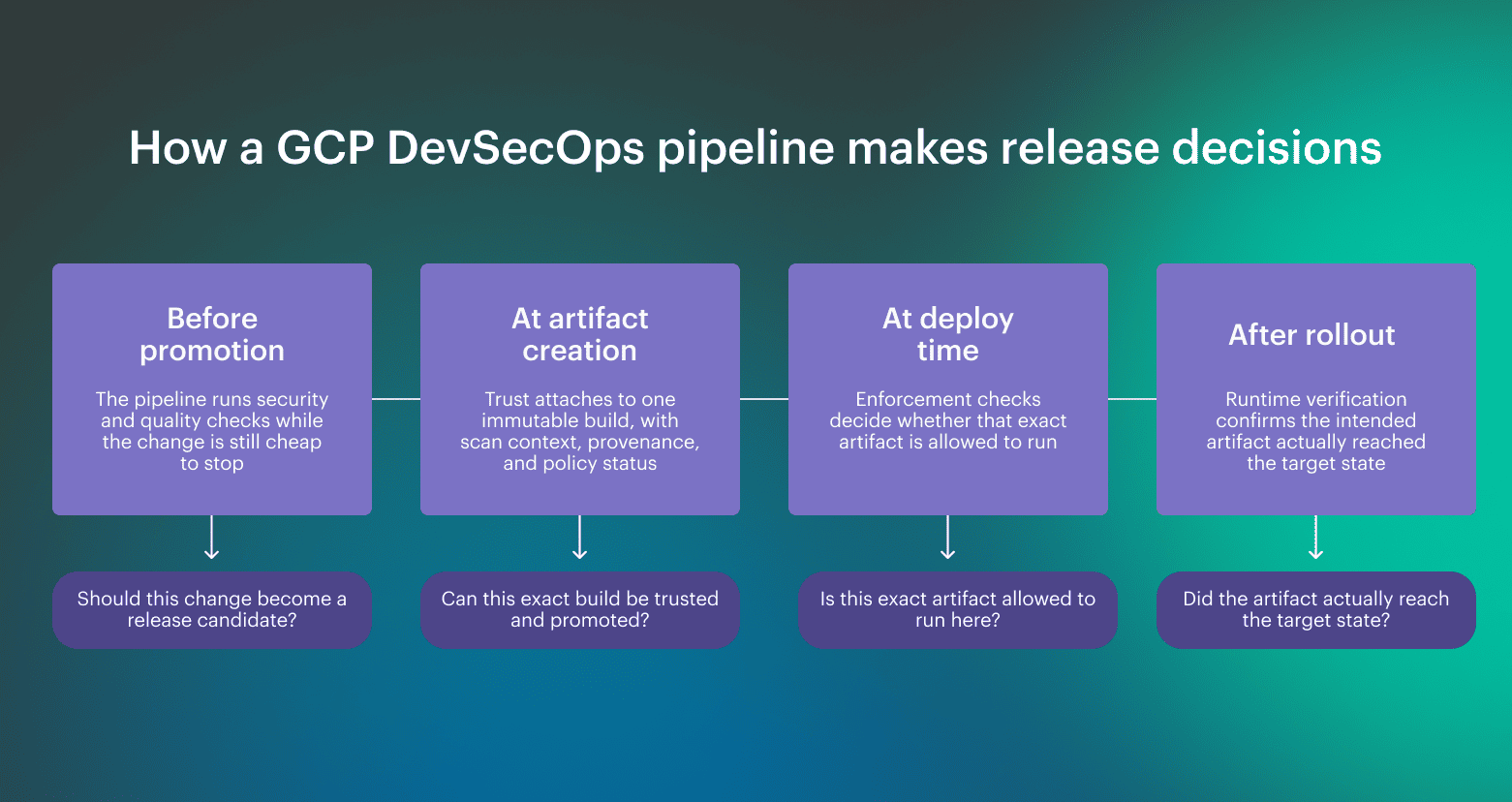 A release isn't complete when deployment succeeds. It is complete when runtime confirms that the intended artifact, policy state, and rollout outcome match what the pipeline approved.
A release isn't complete when deployment succeeds. It is complete when runtime confirms that the intended artifact, policy state, and rollout outcome match what the pipeline approved.
Security testing before the artifact moves forward
Before promotion, security testing should answer a narrow question: is this change fit to become a release candidate?
That usually includes source checks, dependency analysis, and image-related testing, but the important part isn't the number of scans. It is whether the pipeline can create one release artifact with usable results attached to it.
The output of this stage is a go/no-go signal attached to a specific build candidate. If findings live in separate dashboards and are not tied back to the artifact being promoted, the pipeline generates information but not a release decision.
Container image controls that protect deployment trust
The container image is the deployment unit, so trust has to become concrete there. Mature teams treat the image as the object that moves through environments, not as a disposable package rebuilt on demand. In GCP, that usually means one flow:
- Store centrally: Push it to Artifact Registry
- Attach trust data: Keep scan results, provenance, signing, or attestation tied to that image
- Enforce at runtime: Use Binary Authorization to make deployment decisions on the exact artifact being promoted
At runtime, verification should confirm the image digest that was approved, not just the tag or release name. Otherwise, the pipeline approved one thing and the cluster may be running another.
Read also: 8 DevSecOps Container Security Vulnerabilities and How to Fix Them
The core tools behind secure delivery on GCP
A mature delivery path on GCP isn't about how many tools you use. It depends on whether each Google Cloud service has a clear job in the trust chain. When those chain parts live in separate systems with separate logic, secure delivery starts to drift.
That doesn’t mean every enterprise stays fully Google-native. Many teams still use GitHub or GitLab for source and CI orchestration, then rely on GCP for artifact storage, policy enforcement, deployment targets, and runtime.
The important question is whether the chain still carries the same artifact, the same policy state, and the same release decision all the way to runtime?
How Cloud Build, Artifact Registry, and Binary Authorization work together
These services map to three separate decisions in the same trust path.
- Cloud Build: What exactly was built, and under which build identity?
- Artifact Registry: What immutable object is moving forward, and what context stays attached to it?
- Binary Authorization: Is that exact artifact allowed to run in this environment?
Google’s reference architecture uses this chain for secure CI/CD on GKE, and Google documents Binary Authorization as deploy-time policy enforcement rather than a general-purpose scanner.
| Service | What it should own | What goes wrong without it |
|---|---|---|
| Cloud Build | Build execution, test steps, provenance inputs, attestation generation | Build identity is vague, and results live only in logs |
| Artifact Registry | Immutable artifact storage plus attached scan and metadata context | Teams promote tags or versions instead of a specific artifact |
| Binary Authorization | Deploy-time policy gate on the exact image | Approval becomes manual interpretation instead of enforcement |
The important part is the chain: Cloud Build can feed attestations into Binary Authorization, while Artifact Analysis scans images pushed to Artifact Registry and keeps vulnerability data tied to image digests, not just tags. That gives the platform something concrete to enforce later.
Why Cloud Deploy matters for controlled promotion
Teams often get build and scanning right, then lose control during promotion. Artifacts move across environments through scripts, manual steps, or team-specific workflows.
Cloud Deploy addresses that by separating responsibilities:
- Build and artifact flow: decides what is eligible to move
- Cloud Deploy: controls how it moves across targets
- Policy enforcement: decides whether it is allowed to run
Cloud Deploy is the delivery control plane. It supports GKE, GKE attached clusters, Cloud Run, and custom targets, so promotion can stay consistent across runtimes.
Binary Authorization is also broader than GKE, with deploy-time controls across multiple environments. That allows promotion and enforcement to stay separate without breaking the model.
Teams can stay fully Google-native or keep GitHub or GitLab for CI. The model still holds if promotion, artifact identity, and policy state stay attached to the same release object.
Read also: DevSecOps Velocity. Ship Faster Without Growing Security Debt
Identity, Access, and Policy Controls in GCP
In a mature GCP setup, identity is part of the control plane. Most pipeline failures around trust start with weak boundaries: the same identity can build and deploy, long-lived credentials sit in CI systems, or policy depends on who happens to have broad enough access at release time.
The goal is:
- Keep access narrow: Identities should only do the job they were created for
- Separate trust domains: Build, deploy, and runtime should not share the same level of control
- Make policy repeatable: Teams should not have to renegotiate control decisions every time they ship
In “Google Cloud terms”, that means using IAM carefully enough that one weak identity doesn't become control over the whole release path. Least privilege isn't just a general security principle here. It is what keeps one compromised step from turning into a full-platform problem.
Three patterns usually weaken the delivery platform first:
- Broad build-to-deploy access: one identity can do too much
- Long-lived keys in CI: static credentials outlive the process around them
- Passive audit review: the evidence exists, but no one uses it to improve control quality
How GCP IAM supports secure service-to-service access
GCP IAM gives teams the structure for that separation. Roles and permissions define what each identity can do, while service accounts let build systems, deployment systems, and workloads act with distinct scopes.
A useful model is:
- Build identity: can fetch source, run pipeline steps, and create artifacts
- Deploy identity: can promote approved artifacts into target environments
- Runtime identity: can access only what the running workload needs
This is where Workload Identity Federation matters. Google documents it for deployment pipelines specifically to avoid long-lived service account keys and replace them with federated, short-lived credentials. That removes one of the weakest patterns in CI/CD design: static keys stored in pipeline systems.
Policy enforcement without slowing delivery
Policy works when it is predictable. The goal is to make routine decisions automatic and keep human judgment for real exceptions.
A healthy model looks like this:
- Automated gates: handle normal checks and every release must pass
- Exception logic: handles known risk with an owner, scope, and expiration
- Approvals at irreversible moments: usually promotion into a sensitive environment
Runtime visibility, logging, and cloud security signals
A green deployment doesn't prove a trustworthy release, it only proves the pipeline reached its own stopping point. Runtime still has to confirm that the approved artifact, expected identity, and rollout state actually made it into the cluster.
This is where teams fool themselves. The pipeline says the rollout succeeded, Kubernetes says the workload is healthy, and the release gets marked done. Meanwhile, an older replica set is still serving traffic, the wrong image digest is running on part of the workload, or a manual change has already drifted the runtime away from what the pipeline approved. In GKE, that gap between pipeline truth and cluster truth is where release confidence breaks.
That is why runtime visibility belongs inside the security model. In cloud systems, especially on GKE, trust isn't closed at deploy time. It is closed when runtime evidence confirms the system reached the intended state.
How logging and runtime signals complete the feedback loop
Mature teams usually verify four things before they consider a release complete:
- Approved digest: The image digest running in the cluster matches the artifact approved in the pipeline
- Rollout convergence: All intended replicas moved to the new version
- No old runtime state: No older pod, replica set, or image digest is still serving traffic
- Expected identity: The workload runs under the intended service account and permission boundary
A common failure mode looks like this: the pipeline approves digest A, deployment succeeds, but one part of the workload still runs digest B because the rollout stalled and old pods never fully drained. The release record says success. Runtime says mixed state. Mature teams trust the runtime.
Without that loop, DevSecOps turns optimistic. The pipeline tells you what should have happened. Logs and runtime signals tell you what actually happened. Mature teams close releases on the second one, not the first.
Read also: The Cloud Log Fragmentation Problem - Why Enterprises Can't Track Where Their Logs Go?
A mature operating model for enterprise DevSecOps on GCP
One of the most common fail model is when the same release is judged by different rules in different places. One set in CI, another in production, and a third during incident response. That is where enterprise models go soft. The controls exist, but they don't mean the same thing across the system.
A mature operating model fixes that. The release has to mean the same thing across repos, environments, and clouds. In DevSecOps GCP, that matters more than any individual scanner or platform feature. If production is where the rules change, the model isn't mature yet.
A useful test is whether teams can answer the same five questions everywhere:
- Who can build?
- Who can promote?
- What makes an artifact trusted?
- Where is approval required?
- What runtime evidence closes the release?
If those answers vary by repo, team, or cloud environment, maturity is still shallow. That is why Google Cloud DevSecOps only holds when provider-specific shortcuts stop changing what a release actually means.
Read also: DevSecOps Maturity Model. Scorecard You Can Measure and Improve
What mature teams standardize across repos, environments, and clouds
Mature teams standardize the parts that break first under pressure.
- Pipeline shape: So teams stop inventing provider-specific release paths
- Policy baselines: So risk isn't renegotiated in every repo
- Identity boundaries: So build, deploy, and runtime stay in separate trust domains
- Artifact trust: So promotion doesn't turn one approved build into multiple interpretations
- Runtime evidence: So release truth survives handoffs, audits, and incidents
The point is keeping the system predictable when teams move fast, especially across GKE and other runtimes.
The certification view: what a GCP DevOps professional still needs to learn
The GCP DevOps Professional track teaches you the services and how to wire them together. It doesn't teach judgment. It will not tell you where trust should attach to an artifact, where approvals should stop being manual, or how to prove that what is running matches what was approved.
Those are operating model problems. In practice, they show up at the boundaries between pipeline design, identity, observability, and service ownership, where the system stops being clear about who decided what and why.
In real environments, this is where things start to drift. Asset state, release evidence, ownership, and runtime context end up split across CI systems, tickets, and runtime tooling. Cloudaware helps keep that context tied to the same objects, so release decisions stay enforceable after deployment.