






Gartner predicts that through 2027, 99% of cloud security failures will be the customer’s fault, nearly always rooted in misconfiguration.
That number stings because cloud sprawl rarely arrives as one giant mess. It creeps in quietly: a forgotten AWS account, an Azure subscription with stale roles, a GCP test workload nobody owns, and an on-prem dependency still wired into production.
The risk usually looks boring before it gets expensive:
- one public bucket
- one overbroad admin role
- one untagged workload
- one drifted security group
- one compliance control with no evidence trail
Cloud security posture management (CSPM) continuously discovers and fixes cloud misconfigurations across AWS, Azure, GCP, and beyond. For the full primer, see our explainer on what cloud security posture management is.
The importance of cloud security posture management shows up when CSPM turns messy findings into something teams can actually fix: asset, owner, environment, policy impact, and next action.
Below are nine reasons CSPM is now non-negotiable, and what each one looks like operationalized in a real cloud estate.
Key Insights
- CSPM matters because the cloud failure pattern is painfully preventable. Through 2025, 99% of cloud security failures will be the customer’s fault, which usually means ownership, configuration, access, or governance broke before the provider did.
- The biggest benefit is continuous visibility across messy hybrid estates. 73% of organizations use hybrid cloud, so security teams are no longer protecting “AWS” or “Azure.” They are protecting AWS, Azure, GCP, Kubernetes, SaaS, and on-prem dependencies moving at the same time.
- Cloud security posture management turns misconfigurations into owned work. A public bucket, wildcard IAM role, exposed port, or disabled logging control only reduces risk when the finding lands with the right asset owner, app context, environment, blast radius, and fix path.
- CSPM shortens the gap between detection and remediation. Instead of sending 9,000 alerts into the void, mature teams use risk scoring, attack path context, and Jira or ServiceNow routing to find the 90 issues that can actually hurt production first.
- Compliance gets cheaper when evidence follows the asset. SOC 2, PCI DSS, HIPAA, DORA, NIS2, CIS Benchmarks, and internal controls all get harder when proof lives in screenshots. CSPM keeps policy status, exceptions, owners, changes, and audit evidence tied to the live resource.
- Posture improvement compounds. One fixed IAM pattern can remove dozens of future findings. One ownership rule can stop tickets from bouncing between Security, Platform, and AppDev. One drift-control loop can keep an emergency change from becoming next quarter’s audit problem.
- The business case is not theoretical. The global average breach cost at USD 4.4 million, while extensive security AI and automation saved organizations USD 1.9 million compared with teams that did not use those capabilities. CSPM sits in that same automation story: find risk earlier, route it faster, prove it cleaner.
Reason 1. Misconfiguration is now the single biggest cause of cloud breaches
Start with the money trail. IBM’s 2025 Cost of a Data Breach Report puts the global average breach cost at USD 4.44 million. The same analysis ties 26% of breaches to human error and 23% to IT failures, which is exactly where cloud misconfigurations usually live: not in some movie-level exploit, but in a setting someone changed, copied, forgot, or never reviewed.
Verizon’s team analyzed 22,052 incidents and 12,195 confirmed breaches, with the human element still hovering around 60% in its SMB snapshot.
So yes, zero-days matter. Nobody serious waves them away.
But in the cloud, the thing that gets teams first is usually more ordinary:
- a public S3 bucket with sensitive files inside
- an IAM role that allows wildcard permissions
- an exposed admin port left open after testing
- a secret sitting where a scanner or attacker can read it
- a workload with no clear owner, no tag discipline, and no remediation path
That is why Cloud security posture management belongs in this conversation early. Its job is not to admire the architecture diagram. It checks the live estate while AWS accounts, Azure subscriptions, GCP projects, Kubernetes clusters, and on-prem dependencies keep changing underneath the team.
Why public buckets, over-permissive IAM, and exposed secrets keep happening
Cloud review loses when the estate changes faster than people can reason through it.
A platform engineer can deploy a new environment in minutes. A developer can request broader access to unblock a release. A data team can create storage for exports, tests, model training, or reporting. Each change may look harmless alone.
The attack surface grows in the gaps between those small decisions.
What makes the problem ugly is ownership. Security sees the finding, but the fix belongs somewhere else. Platform owns the module. DevOps owns the pipeline. The app team owns the workload. Compliance needs the evidence. Nobody wants another ticket with “high severity” and no useful context.
A useful posture program ties the finding back to the working system: asset, owner, environment, application, recent change, policy impact, and remediation group. That is the difference between “we detected risk” and “we know who can close it.”
A real-world example: one exposed bucket, 273,000 financial documents
In September 2025, UpGuard disclosed a publicly accessible Amazon S3 bucket containing more than 273,000 PDF documents tied to Indian bank transfers. The files exposed unredacted bank account numbers, transaction amounts, and, in many cases, names, phone numbers, and email addresses.
UpGuard also reported that the bucket was adding roughly 3,000 new files per day before it was secured.
That is the whole argument in one uncomfortable example.
The breach did not need a sophisticated exploit chain. It needed sensitive data, public exposure, weak visibility, and enough time for the mistake to matter. In 2026, the winning cloud security teams are the ones catching that pattern while it is still a configuration issue, not after it becomes a breach story.
Reason 2. Multi-cloud and cloud sprawl have outgrown human-scale security
73% of organizations use hybrid cloud, while multi-cloud adoption continues to rise. Public cloud usage concentrated across major providers, with AWS used for active enterprise workloads by 83% of respondents, Azure at 79%, and Google Cloud behind them. That is the shape of the modern estate: not one cloud, not one control plane, not one clean owner map.
Add Oracle Cloud for one business unit. Add Kubernetes because the platform team standardized around it. Add SaaS, inherited accounts, test environments, CI/CD identities, and a few “temporary” exceptions that somehow survived three quarters.
That is cloud sprawl. Quiet at first. Ugly at scale.
The math of cloud sprawl
A mid-market cloud estate can look manageable in a slide.
Then you open the real inventory.
50 accounts or subscriptions
12 regions
180 cloud services
4 Kubernetes clusters
Thousands of IAM roles, service accounts, keys, buckets, disks, databases, secrets, and network rules. Dozens of deployments every day
Now multiply that by AWS, Azure, GCP, Oracle Cloud, and on-prem dependencies that still affect production.
The problem is not just volume. It is motion.
82% of container users run Kubernetes in production, which means security teams are not only checking VMs and storage anymore. They are dealing with namespaces, pods, images, manifests, ingress rules, service accounts, secrets, runtime drift, and the weird little permission chain nobody sees until something breaks.
Why ticket-based security can’t keep up
A ticket is useful after someone knows what must happen. It is a terrible way to discover risk.
By the time security reviews the request, the workload may already be running. By the time the owner replies, the Terraform module may have changed. By the time compliance asks for evidence, the original change might be buried under five newer commits.
That is why mature teams push controls into the workflow:
- IaC scanning checks risky Terraform, CloudFormation, ARM, and Kubernetes manifests before deployment.
- Policy as code turns “we should not allow this” into a repeatable control.
- Runtime posture checks catch what still gets through: console edits, drift, unmanaged assets, expired exceptions, and overbroad access.
Cloud security posture management closes the gap between cloud velocity and security review. Not by asking humans to inspect every account, region, service, and commit manually. By turning live cloud state into something security, DevOps, platform, and compliance teams can actually act on.
Reason 3. Compliance is continuous now, and annual audits no longer cut it
Audit prep used to have a season. You knew the process. Clean up the evidence folder. Chase screenshots. Ask the platform for access to exports. Ping DevOps about encryption. Hope the auditor does not ask why one production account looks different from the other 49.
That model fails as soon as your cloud estate begins to change on a daily basis.
A workload can pass a SOC 2 control on Monday, fail a CIS Benchmarks check on Tuesday, and create a PCI DSS headache by Friday because someone opened access for testing and forgot to close it. No villain. No dramatic breach. Just cloud doing what cloud does: moving faster than the review cycle.
The shift: from audit prep to evidence-on-demand
Continuous compliance means the control is not “true” because a spreadsheet says so.
It is true because the live asset proves it.
For a cloud security leader, that proof needs to answer practical questions fast:
- Which asset failed the control?
- Is it production, staging, or dev?
- Who owns it?
- What changed recently?
- Which framework is affected?
- Is there an approved exception?
- Can we show audit evidence without rebuilding the story by hand?
That last one is the killer.
Because if evidence lives across screenshots, Slack threads, Jira tickets, cloud consoles, spreadsheets, and someone’s memory, audit prep becomes archaeology. Expensive archaeology.
What the frameworks are really asking for now
The framework names differ. The operational demand is converging.
| Framework | What it pressures cloud teams to prove |
|---|---|
| SOC 2 | Access, change management, logging, availability, confidentiality, and security controls are working, not just documented. |
| PCI DSS | Cardholder-data environments stay protected through secure configuration, encryption, access control, monitoring, and vulnerability management. |
| HIPAA | Electronic protected health information has safeguards around access, storage, transmission, backups, and audit trails. |
| FedRAMP | Authorization requires ongoing monitoring, not a one-time approval story. |
| NIS2 | Cybersecurity governance and risk ownership must be visible across critical sectors and supply chains. |
| DORA | Financial entities need proof of ICT risk management, resilience, and third-party control. |
| CIS Benchmarks | Cloud resources follow hard configuration baselines across AWS, Azure, GCP, Kubernetes, operating systems, and more. |
| NIST CSF 2.0 | Governance, roles, policy, risk decisions, and accountability need evidence behind them. |
This is where cloud security posture management becomes more than a security tool.
It becomes the evidence layer between cloud operations and GRC.
Because “compliant on every commit, in every account, every minute” sounds intense until you compare it with the alternative: six weeks of audit panic, half-trusted exports, stale screenshots, and a team trying to explain a cloud estate that changed while they were documenting it.
Reason 4. Every fix today reduces tomorrow’s attack surface
The benefits of cloud security posture management aren’t a list of features. They’re a compound series. Every misconfiguration fixed today is a finding you don’t triage tomorrow, an alert that doesn’t fire next week, and an auditor question you don’t answer next quarter.
That is where posture work gets interesting.
Close one public bucket, and you reduce exposed data risk. By tightening one wildcard IAM policy, you can reduce the blast radius. By removing one internet-facing admin port, you eliminate one attack path. Fix a missing owner tag, and the next violation lands with the right team instead of bouncing between security, platform, and app owners.
Small fix. Bigger downstream effect.
The compounding chain
A mature CSPM program usually starts with continuous monitoring across AWS accounts, Azure subscriptions, GCP projects, Kubernetes clusters, and on-prem dependencies. Then the loop gets faster:
- IaC scanning catches bad infrastructure patterns before deployment.
- Policy as code keeps the same rule enforced across teams and clouds.
- Drift detection catches console edits, expired exceptions, and emergency access after release.
- Risk prioritization shows which findings increase real exposure, not just which ones look ugly in a dashboard.
- Clean asset context shortens MTTD and MTTR because teams know what broke, who owns it, and what needs to change.
This is where cloud security posture management benefits become practical. Fewer repeat violations mean less alert noise. Less noise means faster triage. Faster triage lowers MTTR. Lower MTTR reduces the time risky assets stay exposed.
The audit side compounds too.
When evidence is already tied to the asset, compliance teams do not spend weeks rebuilding the story from screenshots, tickets, and cloud console exports. Cyber-insurance reviews also get easier because the team can show control coverage, remediation history, and exposure trends instead of promising “we’re working on it.”
Engineering gets time back last, but feels it first.
No more vague tickets like “fix critical cloud risk.”
No more hunting for ownership.
No more reopening the same policy breach across 15 accounts.
Every closed misconfiguration makes tomorrow’s cloud estate a little smaller for attackers, auditors, and tired engineers to fight through.
Reason 5. CSPM closes the gap between detection and action
CSPM helps with cloud security by giving security teams one continuously updated view of every cloud asset, surfacing misconfigurations as they appear, prioritizing by exploitability and business impact, then routing remediation to the team that owns the resource before attackers.
A finding is not risk reduction.
It is a smoke alarm. Risk drops when the alert becomes owned work: the right team, the right asset, the right fix, with enough context to close it without three meetings and a Slack archaeology project.
This is where cloud security gets messy in real estates. Security sees an overbroad IAM role. Platform sees a Terraform module. The app team sees a release dependency. Compliance sees a failed control. Each team is looking at the same risk from a different window.
Nobody is wrong. The workflow is broken.
What CSPM has to connect
A useful CSPM program should answer the questions that decide whether a finding gets fixed or ignored:
- What asset is affected? Inventory across AWS, Azure, GCP, Kubernetes, and on-prem has to be live.
- Who owns it? No owner means no accountable remediation.
- What does it support? A dev sandbox and a production payments workload should not compete for the same urgency.
- How exposed is it? Risk scoring needs exploitability, blast radius, data sensitivity, and internet exposure.
- Which policy failed? Security guardrails and policy as code make the rule clear.
- Where does the fix go? ServiceNow, Jira, or another ITSM flow should receive the full context, not a vague “critical cloud risk” ticket.
Take a public storage bucket.
If it belongs to a production payments app, contains sensitive exports, has internet exposure, and no approved exception, it should jump the queue. If it is an empty dev bucket in a sandbox account, it still needs cleanup, but it does not deserve the same response.
That is the detection-to-action gap CSPM closes.
Not “we found 9,000 issues.” “We know which 90 widen the attack surface, who owns them, and what has to happen next.”
Reason 6. Posture doesn’t improve from quarterly snapshots
CSPM improves your cloud security posture by replacing point-in-time audits with continuous evaluation. Every new resource, IAM change, and IaC commit gets checked against the baseline as the estate changes, so drift is caught while it is still small.
Quarterly posture reviews have one ugly flaw.
They age the second someone ships.
An S3 encryption check passes on Monday. On Wednesday, a new bucket lands outside the baseline. Azure access gets expanded during an outage. A GCP project appears for analytics. Kubernetes ingress changes because one service needed a quick release.
The report still looks clean.
The cloud does not.
What actually improves posture
Not another dashboard. A tighter operating loop.
- Before deployment: IaC scanning checks Terraform, CloudFormation, ARM, and Kubernetes manifests for public storage, missing encryption, wildcard permissions, weak logging, and untagged production resources.
- During deployment: policy gates block the dangerous stuff, request approval for edge cases, or allow an exception with an expiry date.
- After deployment: drift detection catches console edits, emergency firewall rules, expanded IAM roles, and controls disabled “just for testing.”
- Over time: posture score, repeat violations, SLA misses, exception age, MTTD, and MTTR show whether risk is actually going down.
That last part matters. A posture score only helps if a CISO can see why it moved.
- Did production criticals drop?
- Which team keeps reopening the same security group exception?
- Are high-risk findings sitting past SLA?
Did preventive security reduce repeat policy failures month over month?
That is the DevSecOps shift underneath CSPM.
Security moves closer to the commit. Drift gets handled before it becomes audit debt. Preventive security stops being a slogan and starts showing up in fewer repeat findings, cleaner ownership, and faster fixes.
Reason 7. CSPM and DSPM together read both the cloud infrastructure and the data inside it
A public bucket is a cloud security problem.
A public bucket with payroll exports, PHI, API keys, and customer IDs inside is a breach path with a business owner, a regulatory scope, and a very different SLA.
That is why CSPM alone can miss the real priority.
CSPM reads the infrastructure layer: bucket exposure, IAM access, encryption, security groups, logging, and drift. DSPM reads the data layer: PII, PHI, secrets, source code, regulated records, intellectual property, and data sovereignty risk.
One tells you the door is open. The other one tells you what is sitting behind it.
Where cloud data security posture management gets serious
Cloud data security posture management works when it connects exposure to consequence.
A storage asset marked “public” is useful information. But cloud data security posture management should also answer:
- What sensitive data discovery found inside
- Whether data classification is accurate
- Which identities can access the data
- Whether it violates residency or retention rules
- Which app, owner, and environment are attached
- How big the blast radius gets if access is abused
The best cloud posture management for data security does not rank risk by severity labels alone.
It ranks by what attackers could actually reach.
That means infrastructure context, data classification, sensitive data discovery, ownership, region, access path, and remediation priority need to live in the same risk story. Otherwise, teams clean up what looks loud and miss what could hurt.
Reason 8. Agentless CSPM onboards a new cloud account in under 30 minutes without an install
The benefits of agentless CSPM for cloud security come down to one thing: coverage that arrives before the cloud estate has already changed again.
A single cloud account can often be connected in under 30 minutes when onboarding uses an API-based read-only role. That is the clean version: create the role, authorize discovery, run the first inventory, surface the first posture findings.
Compare that with agent-based coverage.
For AWS Systems Manager, a node must have the SSM Agent installed and running, the right IAM instance profile, and service endpoint connectivity before it appears as a managed node. Three moving parts before security can reliably act on that machine.
Microsoft’s own agentless scanning docs make the contrast plain: agentless scanning requires no installed agents, no network connectivity, and does not affect machine performance. It can scan Azure VMs, AWS EC2 instances, and GCP compute instances connected to Defender for Cloud, with scans running on a 24-hour schedule.
So the speed difference is not “agentless is prettier.”
It is operational.
Agentless CSPM can start with the cloud control plane. Agent-based tools have to reach the workload.
A useful onboarding dashboard should make that visible fast:
| Coverage signal | Agentless CSPM target |
|---|---|
| Time to first account visibility | Under 30 minutes for a typical single account |
| Install requirement | 0 workload agents |
| First scan scope | Accounts, regions, services, IAM, storage, networking, metadata |
| Early blind spots | Missing owner tags, public resources, overbroad access, disabled logging |
| Escalation path | Assign owner, open Jira or ServiceNow ticket, approve exception, or fix now |
That is where agentless changes the operating model.
No agent fleet to maintain before discovery.
No waiting for golden images.
No missed ephemeral workloads just because they vanished before deployment coordination caught up.
The cloud can create risk in minutes. Posture coverage has to show up in the same time zone.
Reason 9. CSPM becomes the cloud security control plane
In January 2019, Gartner published Innovation Insight for Cloud Security Posture Management and framed CSPM around a very specific cloud problem: successful cloud attacks were overwhelmingly tied to customer-side misconfiguration, mismanagement, and mistakes. That was seven years ago. The problem did not shrink. It got promoted.
Look at where the market moved next.
Gartner later described CSPM as a key component of CNAPP, not a side utility. Its CSPM solution criteria page says CSPM is commonly bought as part of broader cloud security platforms that include CWPP, CIEM, KSPM, cloud detection and response, and attack path analysis. Gartner’s 2024 competitive overview also projected the CSPM market to grow from $2.1B in 2024 to $6.1B in 2028, with roughly 30% average annual growth.
That is the market saying something pretty loudly.
CSPM is turning into the cloud security control plane.
Not because every team wants another console. Please, no. Most already have enough tabs open to qualify as a risk category.
Because cloud security now needs one place where the estate becomes explainable:
| Control-plane question | What the posture layer should answer |
|---|---|
| What exists? | Accounts, subscriptions, projects, clusters, workloads, identities, storage, networks |
| What changed? | IaC commits, console edits, new services, drift from approved baselines |
| What matters first? | Attack path, blast radius, data sensitivity, exposure, business criticality |
| Who owns the fix? | App owner, platform team, business unit, remediation group |
| Can we prove it? | Policy status, audit evidence, exception history, MTTR, trend line |
This is also why CNAPP convergence does not make CSPM less important. Gartner’s public cloud security commentary describes CNAPP as an integrated set of capabilities spanning runtime threat detection, visibility and control, posture management, software composition analysis, and workload security. It also notes that CNAPP products keep evolving toward data security, GenAI posture assessment, and multi-cloud configuration monitoring.
So the buying question changes.
Not: “Do we need CSPM or CNAPP?”
More like: “Which system becomes trusted enough to govern cloud risk across security, DevOps, platform, compliance, and architecture?”
Here’s the practical future-proofing test.
- If a new cloud security platform enters your stack tomorrow, can your posture layer feed it clean context?
- f the CISO asks why production risk rose 18% this month, can you answer by account, owner, and policy?
- If compliance asks for evidence, can you show the live asset and its history, not a stale screenshot?
- If platform teams push back on a finding, can you show the exact attack path and blast radius?
That is where CSPM earns its place in 2026.
The stack will keep converging. CNAPP will keep absorbing adjacent controls. Hype Cycle language will keep changing because markets love renaming things right when teams finally understand them.
But the operating need stays boringly durable: know what exists, know what changed, know what breaks policy, know who owns it, and prove the risk is going down.
See your cloud posture the way your team actually has to fix it
Cloudaware turns cloud security posture management into an operating view for teams running AWS, Azure, GCP, Kubernetes, VMware, SaaS, and on-prem infrastructure together.
Security leaders use it to see risk across the full estate. Cloud architects use it to catch drift before it becomes architectural debt. DevSecOps and platform teams use it to route fixes with owner, app, environment, and remediation context already attached. Compliance teams use it because audit evidence is a lot easier to trust when it is tied to the live asset, not rebuilt from screenshots two weeks before review.
The useful view is not “critical findings: 438.”
It looks more like this:
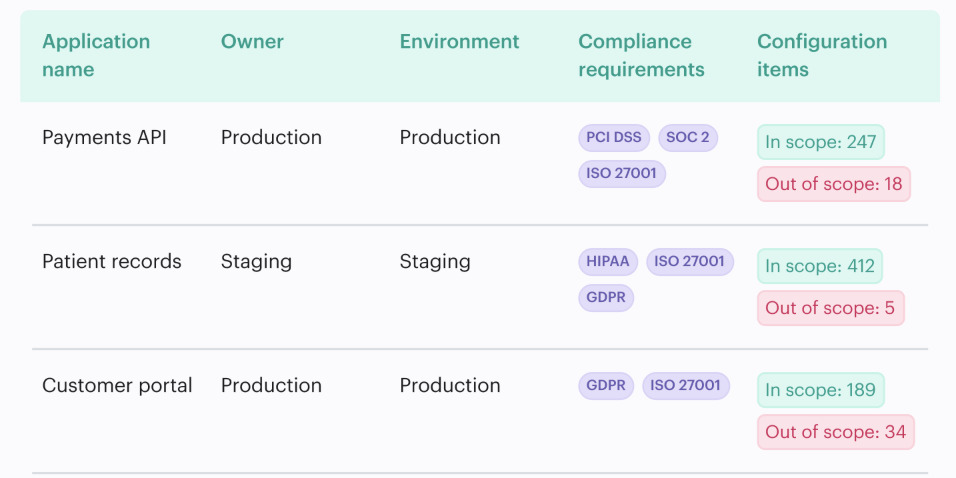
That is where cloud security posture management gets practical. The finding arrives with the CMDB context needed to close it: asset, owner, application, environment, related items, policy impact, attack path, and remediation workflow.
Cloudaware capabilities:
- CSPM for multi-cloud policy checks, misconfiguration detection, risk scoring, exceptions, and remediation routing.
- CMDB for the configuration management database layer behind the finding: owners, applications, environments, dependencies, and related cloud assets.
- ServiceNow and email integration for routing policy violations and ownership gaps into ITSM workflows.
- Jira integration for sending actionable fixes to DevSecOps and platform teams without losing the cloud context.
Cloudaware works best when the walkthrough starts with something messy and real: one noisy policy, one production account, one ownership gap, one exception nobody trusts anymore.