






“Why does a pipeline still have more access than the workload it delivers?” That question sits behind many delivery failures today, because incidents often begin before production, when automation retains broad permissions, credentials outlive their purpose, and the delivery path itself becomes part of the attack surface.
In zero trust DevSecOps, that problem extends beyond human access into machine identity sprawl, where pipeline identities, service connections, job tokens, deploy tokens, and workload identities accumulate privileges that teams no longer track tightly enough.
GitLab’s 2026 Global DevSecOps Report, based on a survey of 3,266 professionals, shows that these issues already sit inside day-to-day platform and security operations, while IBM’s Cost of a Data Breach 2025 puts the global average breach cost at $4.44 million, keeping identity misuse and overtrusted automation firmly on the security agenda.
This article is built around two Cloudaware experts: Alla L., Technical Account Manager, and Igor K., DevOps Engineer. Alongside their quotes, we use industry data from IBM and GitLab to show how zero trust works in real DevSecOps workflows.
TL;DR
- Zero trust is based on one rule: every handoff in the workflow has to prove identity, scope permissions, and carry evidence forward.
- Implementing zero-trust in DevSecOps starts with identity and artifact flow, not with another perimeter layer. Teams need to know which identity acted, what it could reach, what it produced, and whether the next stage should rely on it.
- The core trust principles are stable across stacks: least privilege, short-lived credentials, provenance, attestation, policy-based promotion, and runtime feedback.
- In zero-trust in DevSecOps workflows, build and artifact stages do most of the work. This is where builder identity, dependency scanning, signing, provenance, and approved digests have to hold.
- Application security now sits inside workflow design, because release decisions depend on build evidence, artifact integrity, deployment policy, and runtime state rather than on isolated tool output.
- Runtime still changes the release outcome after approval. Rollout coverage, digest continuity, policy coverage, and workload behavior all need to feed back into future promotion decisions.
- Tooling matters less than control coverage. The useful question is whether the stack already in place provides the policy, identity, evidence, and reporting features needed for securing your DevOps environments?
What zero trust in DevSecOps really means
Zero trust in DevSecOps is an operating model that requires every handoff in the delivery workflow to prove identity, scope access, and carry evidence forward before the next stage can rely on it. In practice, that means teams stop treating the path from commit to runtime as implicitly trusted and start evaluating each step based on what is acting, what it can reach, what it produced, and what proof travels with it.
At the workflow level, that applies to four identity surfaces that usually get mixed until something breaks:
- Human identity for developers and approvers
- Automation identity for pipelines, jobs, and service connections
- Artifact identity for the build output that moves between environments
- Workload identity for what actually runs after deploy
NIST defines zero trust around protecting resources rather than network segments, which fits modern software delivery more closely than older perimeter models.
GitLab reflects the same shift by treating automation as a first-class requestor, while Microsoft frames DevOps platforms, developer environments, and extensions as part of the attack surface.
In 2026, that is also why artifact provenance and machine identities matter so much: teams need to know not only who initiated a change, but also which identity built it, which artifact was produced, and which workload is now running it.
Why traditional CI/CD trust breaks under modern security pressure
Traditional pipelines break down when permissions are granted early and then left in place across build, deploy, and runtime. In 2026, the bigger issue is identity sprawl across the workflow, where pipeline identities, service connections, variable groups, deploy integrations, and workload credentials keep accumulating scope long after the original use case is gone.
In enterprise cloud environments, those gaps turn into compliance issues quickly because teams cannot show who accessed what, when, under which identity, and under which policy. That is where an operational weakness turns into a security compliance problem.
As Alla L. puts it, teams need “short-lived credentials rather than going ahead with the long-term passwords which we basically tend to hardcode into the systems,” and security “must start at the build pipeline itself.”
The common failure points are:
- Static secrets left in pipelines, scripts, images, or pipeline definitions
- Credentials embedded in variable groups and reused across environments
- Shared credentials that make ownership and revocation harder
- Excessive access that survives far beyond the original need
- Poor secret management across repos, runners, and services
- Shared runners or reused execution context that carry state across jobs
- Over-scoped service connections and deployment integrations
- Audit trails that leave software delivery events hard to reconstruct
IBM reports that 97% of organizations that experienced an AI-related security incident lacked proper AI access controls, which makes weak access control and overtrusted automation difficult to dismiss as isolated edge cases.
Read also: DevSecOps Pipeline Explained. Stages, Diagrams, and CI/CD Patterns
The DevSecOps model behind practical zero trust
A workable DevSecOps model starts with a boring but important fact: every stage in delivery can do damage if it gets more access than it needs.
A build job can pull secrets, a service connection can push into the wrong environment, an artifact can move forward without proof, and a deployment can inherit trust that no one meant to grant.
That is why the model is built around a small set of control points:
- Identity-first access, which answers who can act.
- Least privilege, which limits what that identity can reach.
- Short-lived credentials, which limit how long that access can exist.
- Artifact integrity, which determines what can be promoted.
- Promotion integrity and runtime feedback, which determine what can keep moving forward and what can still run after deploy.
Here is how those control points map to a real delivery flow: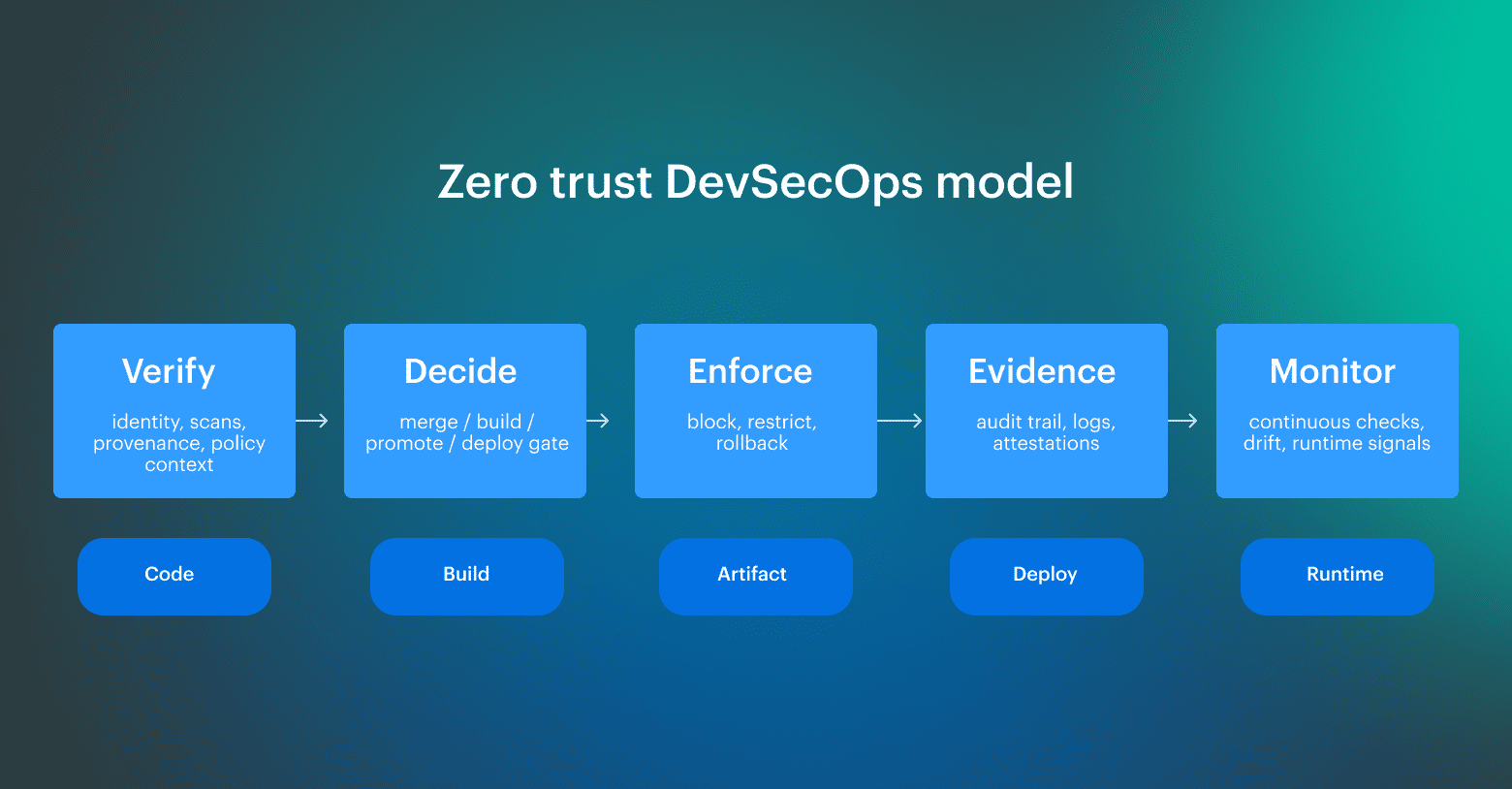 At that point, the workflow becomes easier to reason about operationally. Teams can explain who acted, what changed, what evidence was produced, and whether the next stage should rely on it.
At that point, the workflow becomes easier to reason about operationally. Teams can explain who acted, what changed, what evidence was produced, and whether the next stage should rely on it.
Read also: DevSecOps Maturity Model - Scorecard You Can Measure and Improve
3 principles teams need to trust DevSecOps without over-trusting pipelines
Teams need tighter access, but the real issue is how access is issued, scoped, and expired across the workflow. Pipeline and service identities should receive only the permissions they need for the lifetime of the job or workload, with revocation and TTL handled as part of the control plane rather than left behind as cleanup.
As Alla L. explains, zero trust depends on “least privilege access” and on “making security a part of every action, whether it is human or it is machine,” while dynamic secrets and short-lived credentials reduce the need to hardcode long-term secrets into systems or pipelines.
Scope access to the job and its lifetime
The first principle is scope. Pipeline and service identities should get only the permissions they need, only for the duration they need them, and only in the context where those permissions are expected to be used. Broad standing access is what keeps old trust alive in the workflow long after the original use case is gone.
Move trust with evidence instead of pipeline status
The second principle is evidence. A successful job is not enough to justify promotion on its own, because the next stage still needs proof of what was built, under which identity, and under which policy. That is why signing, attestation, provenance, and policy-based promotion belong in the same control path as pipeline identity and deployment approval.
Treat revocation as part of the operating model
The third principle is revocation. Service identity lifecycle breaks down fast when tokens, secrets, and role bindings outlive the job or workload they were created for. Revocation and TTL need to be part of the operating model itself, because cleanup after the fact does not remove exposure while the access is still active.
In practice, teams implement these principles through three control layers:
| Control type | What it changes | Typical examples |
|---|---|---|
| Visibility controls | What teams can see and review | Secret scanning, audit logs, alerting, approval notifications |
| Access controls | How permissions are granted, scoped, validated, and revoked | Least privilege, short-lived credentials, JIT access, dynamic secrets, service identity TTL |
| Promotion controls | What can move forward in the workflow | Signing, attestation, provenance, policy-based promotion |
At the workflow level, the logic stays straightforward:
- Policy decides who or what can act
- Context decides when that action is allowed
- Evidence decides what can move forward
- Revocation decides when that access should end
Operational management gets simpler when teams separate detection from enforcement, keep service identities short-lived, and stop treating visibility alone as proof that the access model is under control.
Read also: DevSecOps Velocity. How Ship Faster Without Growing Security Debt?
Build-stage controls for zero trust DevSecOps
Build is where pipeline risk becomes execution risk. A single job can read secrets, resolve dependencies, package software, publish artifacts, and hand trusted output to the next stage.
If that job runs with broad access, reuses static credentials, or executes inside a runner that already carries state from previous jobs, the workflow inherits that exposure.
As Alla L. notes, zero trust has to start at the build stage, where every image, dependency, and secret should be verified before release, and short-lived credentials should be injected into CI/CD so tokens and keys never end up hardcoded in source or images.
The build-stage controls that matter most are:
- Ephemeral runners. Each run starts clean, and the runner does not become part of the attack path
- Builder identity. The job can prove which identity performed the build
- Federated or secretless auth. The pipeline receives temporary identity-based credentials instead of stored secrets
- Isolated dependency resolution. Packages are pulled from approved sources under controlled policy
- Scoped access. Build identities can reach only the repos, registries, and services required for that run
- Build assurance checks. Dependency, secret, and artifact validation happens before promotion
- Build provenance. Provenance is produced at build time rather than reconstructed later
- Signing-ready pipelines. Outputs leave build with provenance and can move forward under policy
Build is also where teams set the runner trust boundary. The useful test is simple: can you explain which identity performed the build, which dependency sources were allowed, what the job could reach, what artifact it produced, and why the next stage should trust that result?
Read also: DevSecOps Culture. Operating System Keeping Security Fast
Artifact integrity in zero trust DevSecOps workflows
Artifact integrity decides whether the next stage receives trusted output or just another package with a successful build behind it. Teams need to know what was built, from which source, on which builder, with which inputs, and under which policy.
In 2026, that decision also depends on whether the approved artifact digest stays intact across environments, because trust attaches to the digest, not to a tag, a pipeline name, or a release label.
The core controls are:
- SBOM. Teams can see the dependency inventory shipped with the artifact
- Signing. The artifact carries a verifiable producer identity
- Provenance. The build records where, when, and how the artifact was produced
- Attestation. Security claims travel with the artifact instead of living in a separate dashboard
- Digest immutability. Promotion follows the approved artifact digest across environments without rebuild or environment-specific mutation
- Policy-based promotion. Environments accept only artifacts that meet the required checks
SLSA treats provenance as verifiable information about software artifacts and recommends explicit attestations rather than inferred trust. While NIST’s SSDF positions secure development practices as controls that need to be integrated into each SDLC implementation, rather than handled as a downstream review.
Together, these controls define whether promotion preserves trust or quietly strips it away through rebuilds, retagging, or environment-specific packaging. A signed artifact still loses value when one environment promotes by digest, another pulls by tag, or the release path rebuilds the package instead of moving the approved output forward unchanged.
Deployment gates that scale DevSecOps without slowing delivery
A deployment gate evaluates whether an artifact can move forward under policy and under the conditions of the target environment. In practice, teams are dealing with three separate decisions at once, and keeping those decisions separate makes release flow easier to operate and easier to audit.
That separation looks like this:
| Gate layer | What it checks | Typical outcome |
|---|---|---|
| Artifact readiness | Approved artifact version or digest, signature, provenance, attestations, required validation results | allow, warn, or block |
| Environment readiness | Environment-specific policy, deployment window, target restrictions, required approval scope | allow, warn, or block |
| Exception override | Owner, reason, expiry, bypassed control, review path | temporary allow or block |
Inside that model, the gate still has to answer a few questions:
- Which approved artifact digest is allowed to move forward?
- Is the same digest preserved across the promotion chain?
- Which attestations are required before promotion?
- Which environment-specific checks should warn and which should block?
- Does an exception have an owner, an expiry, and a recorded reason?
A workable gate keeps promotion continuity intact from one environment to the next instead of re-deciding trust from scratch at every stage. Teams need to know why this artifact can deploy now, what evidence was evaluated, which environment rules applied, and whether any override is still active.
That is the part of release management that keeps security, trust, access, and compliance aligned without turning deployment into a manual bottleneck.
Why runtime security must be part of the workflow
Deployment gives you a release event, but runtime shows you what the workload is actually doing after that release lands.
In production, runtime state drifts from release state fast. Old replicas can remain active, policy can apply unevenly, and approved digests don't always match what is running across the workload. Runtime security belongs inside the workflow because deployment approval does not validate rollout completeness, artifact continuity, or post-deploy policy coverage.
As Igor K. explains, a team can harden a workload at one point in time, but keeping that posture aligned with application updates is difficult when the application changes every few weeks. Runtime policy has to move with the workload, and that requires both enforcement and observability, plus enough automation to derive updated policy from what actually changed between versions.
At runtime, watch signals that change risk after deployment:
- Behavior drift across releases. Process, file, and network activity start to diverge from the expected workload profile
- Rollout coverage. The expected digest is running, the rollout has completed, and the old version is no longer serving
- Policy coverage. New policy is applied across the workload set rather than only to part of the environment
- Post-deploy feedback. Runtime findings feed back into future promotion decisions instead of staying in the alert queue
Runtime evidence becomes useful when it is tied to behavior that should not exist after deployment. In Kubernetes, that often starts with service account tokens mounted into pods that don't need API access.
The same applies to sensitive file paths and unexpected process execution in production, including access to database directories or attempts to run package managers such as apt and apt-get.
For management and compliance, runtime closes the evidence gap between what passed in CI/CD and what actually executed after release. Audit and review questions extend into rollout state, resource access, and whether the policy is still held once the workload is live.
Read also: Azure DevSecOps in Real Production Environments
Examples of security controls across the workflow
In DevSecOps, the workflow needs a defined security role at each stage, with clear access rules, visible trust boundaries, and enough evidence for day-to-day management and compliance.
Teams are securing a chain of identities, artifacts, approvals, and runtime behaviors across cloud delivery, so the useful question is: What should be checked at each handoff before the next stage can proceed?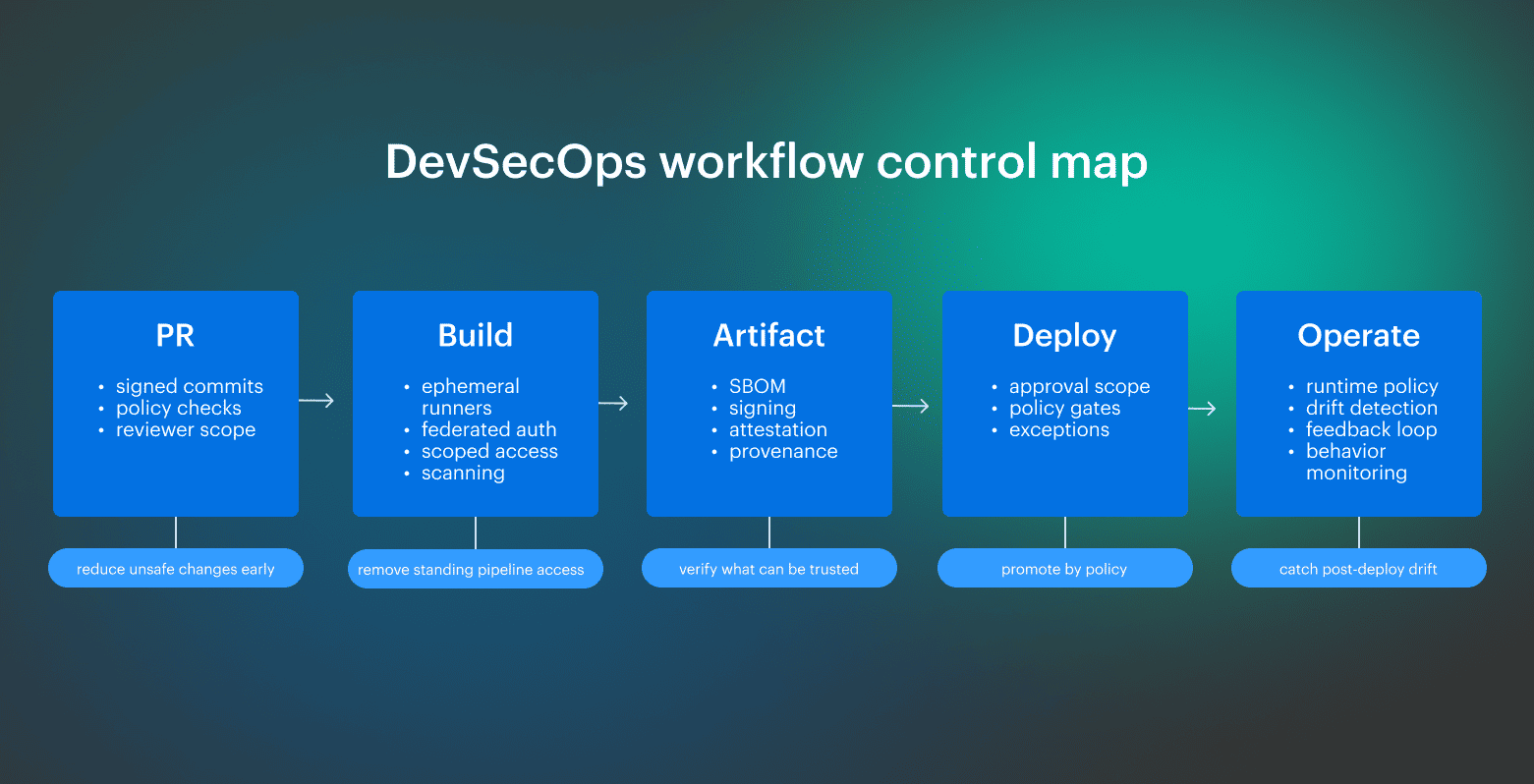 Some vendors package this model as platform-led enforcement, and phrases like “Accuknox enables zero trust” sit in that layer of the market. For engineering teams, the practical question is narrower: how do the same checks map to the stack they already run?
Some vendors package this model as platform-led enforcement, and phrases like “Accuknox enables zero trust” sit in that layer of the market. For engineering teams, the practical question is narrower: how do the same checks map to the stack they already run?
How this model maps to common stacks
Teams usually work inside an existing stack, so the useful question is where that stack already supports identity, policy, evidence, and runtime feedback, and where it still leaves standing access in place.
In a GitHub Actions + cloud stack, the practical pattern is OIDC-based workload identity instead of stored deployment secrets. GitHub documentation is explicit on the goal here: workflows can access cloud resources without storing long-lived cloud credentials as GitHub secrets, which makes this stack a strong fit for short-lived pipeline credentials and scoped deploy access.
In a GitLab CI/CD stack, the same pattern shows up through ID tokens and job-scoped credentials. GitLab documents OIDC-capable ID tokens for CI/CD jobs and positions them as a least-privilege alternative to storing secrets in projects or relying on runner-level permissions.
In an EKS-based stack, the same model maps to IAM roles for service accounts or EKS Pod Identity, so pods assume scoped AWS permissions through Kubernetes service accounts instead of sharing node-level or static credentials. AWS documents both IRSA and EKS Pod Identity for this pattern.
In a Microsoft-heavy stack, the identity layer usually centers on Azure DevOps, Microsoft Entra workload identity, AKS, and Key Vault-backed secret access. Microsoft’s AKS guidance supports enabling OIDC issuer and Microsoft Entra Workload ID for clusters, and its Key Vault integration patterns keep secret access tied to workload identity rather than static pipeline credentials.
The operating model stays the same: define who can act, what can move forward, and which runtime signals should return to the workflow.
How to measure trust in a modern DevSecOps workflow
DevSecOps metrics answer a practical question: Does the system still behave the way the team thinks it does?
In 2026, that usually comes down to a short set of operational signals: identity coverage, artifact integrity, exception pressure, runtime drift, and evidence readiness.
A useful reporting set should stay short:
- % of pipelines without static secrets
- % of service connections using scoped or federated identity
- % of pipeline, machine, and workload identities using short-lived or federated credentials
- % of signed artifacts with complete attestations
- % of deployments gated by complete policy evidence
- % of deployments using the approved artifact digest without mutation
- % of runtime workloads matching the approved artifact digest
- % of stages where policy is enforced rather than only documented
- Exception aging, including owner and expiry
- Active exceptions by environment and control type
- Runtime drift events per release and per environment
- Audit evidence readiness, including whether who/what/when/policy-state information is available without manual reconstruction
As Igor K. points out, policy has to move with the application, because once the workload changes, a static enforcement view stops reflecting the real runtime state. That is where observability becomes operational: it has to show version-to-version change in a way the team can use for policy updates and enforcement decisions.
These are operational best practices because they show whether the workflow is producing usable evidence or leaving the team to rebuild state during incident review, audit prep, or security compliance checks.
How Cloudaware makes these metrics easier to track
Cloudaware helps teams evaluate these metrics without stitching the workflow together by hand.
That matters as soon as the workflow spans multiple environments and tools, where teams may already know that a change happened, an exception is still open, or a workload drifted after release, but still lose time proving which asset, environment, or release that signal belongs to.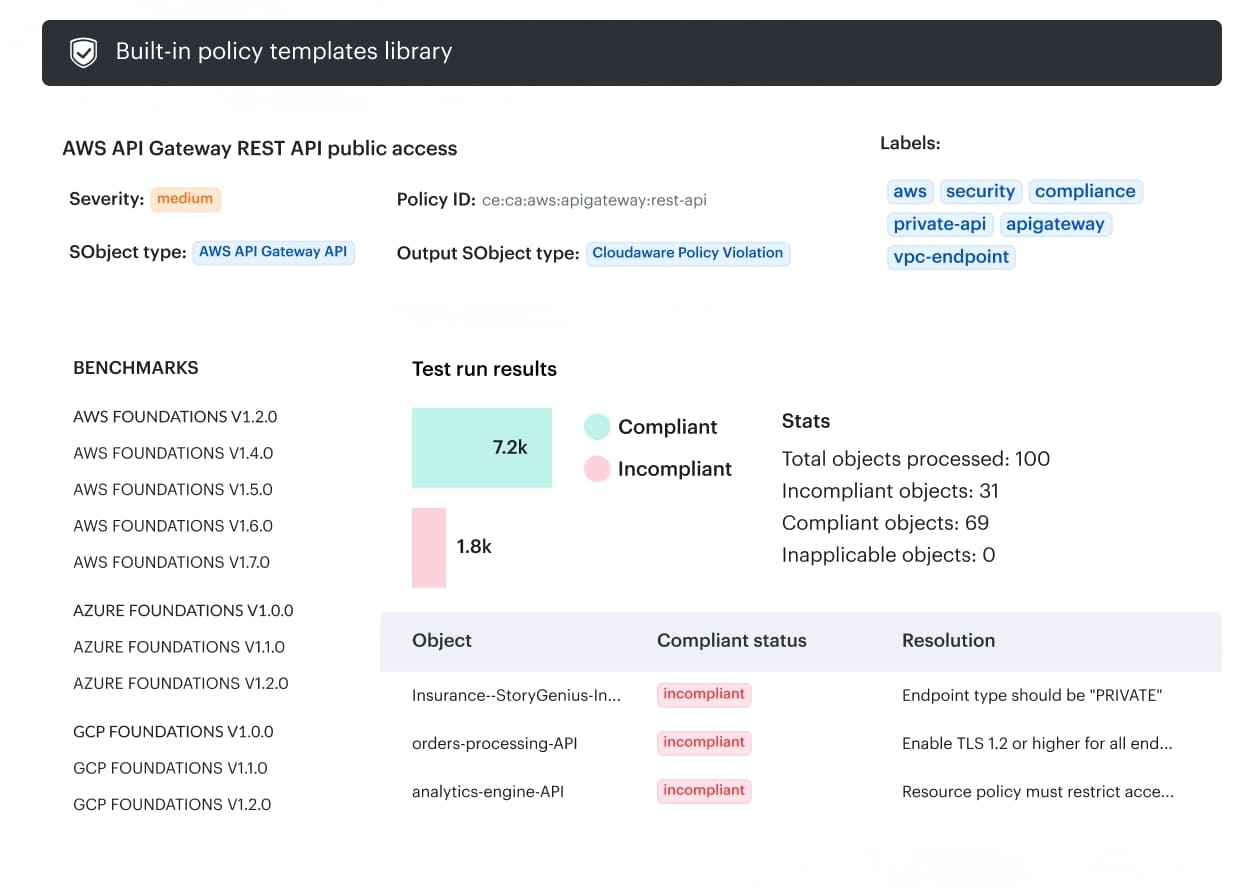 Cloudaware capabilities that matter most are:
Cloudaware capabilities that matter most are:
- Change visibility tied to affected assets and environments, so teams can see what changed, where it changed, and what service or resource context it belongs to.
- Approval and policy history in the same flow, so release decisions, rejections, and policy outcomes stay traceable instead of being reconstructed from separate tools.
- Drift tracking against approved intent, so runtime or configuration drift can be measured against the expected state and tied back to change history.
- CMDB-backed ownership and dependency context, so exceptions, findings, and changes can be linked to the asset, owner, application, and environment that actually matter in review.
- Audit-ready logs and reporting across environments, so teams can pull who/what/when evidence without turning audit prep into manual log digging.