






If you’re here, you’re probably sick of pitching security as “important” while leadership hears “slower releases.” You need DevSecOps benefits that show up on a slide: fewer failed changes, faster recovery, cleaner audit evidence. Our Cloudaware DevSecOps team lives in real pipelines, and we’ve seen what breaks at scale in customer environments, including NASA and Coca-Cola.
- So, [what is DevSecOps](What Is DevSecOps: Definition, Security, and Methodology) today?
- How do you cut cloud drift before it turns into a compliance scramble?
- Which checks belong near code, and which belong later in the process?
- What convinces development teams to fix issues without the endless back-and-forth?
- How do you prove progress with metrics like vulnerability MTTR and change failure rate?
Answers to these questions you’ll find below 👇
TL;DR on DevSecOps benefits
- Fewer “known bad” releases because vulnerabilities get caught closer to the commit. Verizon’s DBIR reported a 180% increase in vulnerability exploitation as the critical path to initiate breaches. Verizon
- Faster vulnerability cleanup when fixes stay small. One 2024 benchmark put mean MTTR for critical web app vulnerabilities at 35 days. Shift-left work aims to cut that trend hard. Edgescan
- Misconfigurations stop being your #1 cloud tax. Unit 42 found nearly 65% of known cloud security incidents were due to misconfigurations. Palo Alto Networks
- Change failure rate drops while delivery speeds up. In a 2024 performance-cluster analysis, elite teams deployed 182× more with 8× lower change failure rates. Octopus Deploy
- MTTR stops wrecking your weekends. DORA benchmarking commonly frames elite recovery as under 1 hour, not days. incident.io
- Audit prep shrinks from a quarter panic to a daily byproduct. RegScale research reports 58% of orgs spend 2,000+ person-hours/year on evidence collection, and 83% say manual compliance work causes moderate/major delays. Channel Insider
- Clear ownership routing means fewer zombie tickets. DORA-style metrics define what to track (deployment frequency, lead time, change failure rate, time to restore) so teams can connect controls to outcomes. DORA
If you need a simple way to show the benefits of DevSecOps, treat those metrics as your scoreboard. Cloudaware dashboards can centralize the signals across your tools so leadership sees one trend line per outcome, not five disconnected reports.
Read also: DevSecOps Statistics (2026) - Market, Adoption, and AI Trends
Catch vulnerabilities earlier (so fixes don’t become fire drills)
Most “security incidents” start as a calendar problem. The bug isn’t new. The surprise is. And right now attackers are betting you’ll stay late. Verizon’s 2024 DBIR found vulnerability exploitation surged nearly 3X (180%) as a key path to breaches.
You find a vulnerable package on Tuesday. The release shipped last Friday. Now you’ve got production traffic, an exec asking “are we exposed,” and a dev lead trying to recreate the build from memory. That’s how a 20-minute fix turns into a two-day fire drill.
This is one of the cleanest DevSecOps advantages because it’s measurable. When you push shift-left security into the pull request, your time-to-detect can drop from days to minutes. That shift matters because “normal” remediation is still slow.
One 2024 benchmark put average MTTR for critical web app vulnerabilities at 35 days. (Edgescan) When findings land while the change is still fresh, teams patch faster, reopen less, and your vuln MTTR trend finally starts bending down.
Cloud changes need the same treatment. Add IaC scanning and you catch “public S3 bucket” or “0.0.0.0/0 inbound” while it’s still just code, not a headline or a compliance scramble.
Cloudaware turns scan findings into a consistent “promote/stop” decision and attaches the evidence to the change record. That’s the leadership-friendly part. You get a control you can point to, plus proof.
Here is an example of the vulnerability scan coverage dashboard Cloudaware provides:
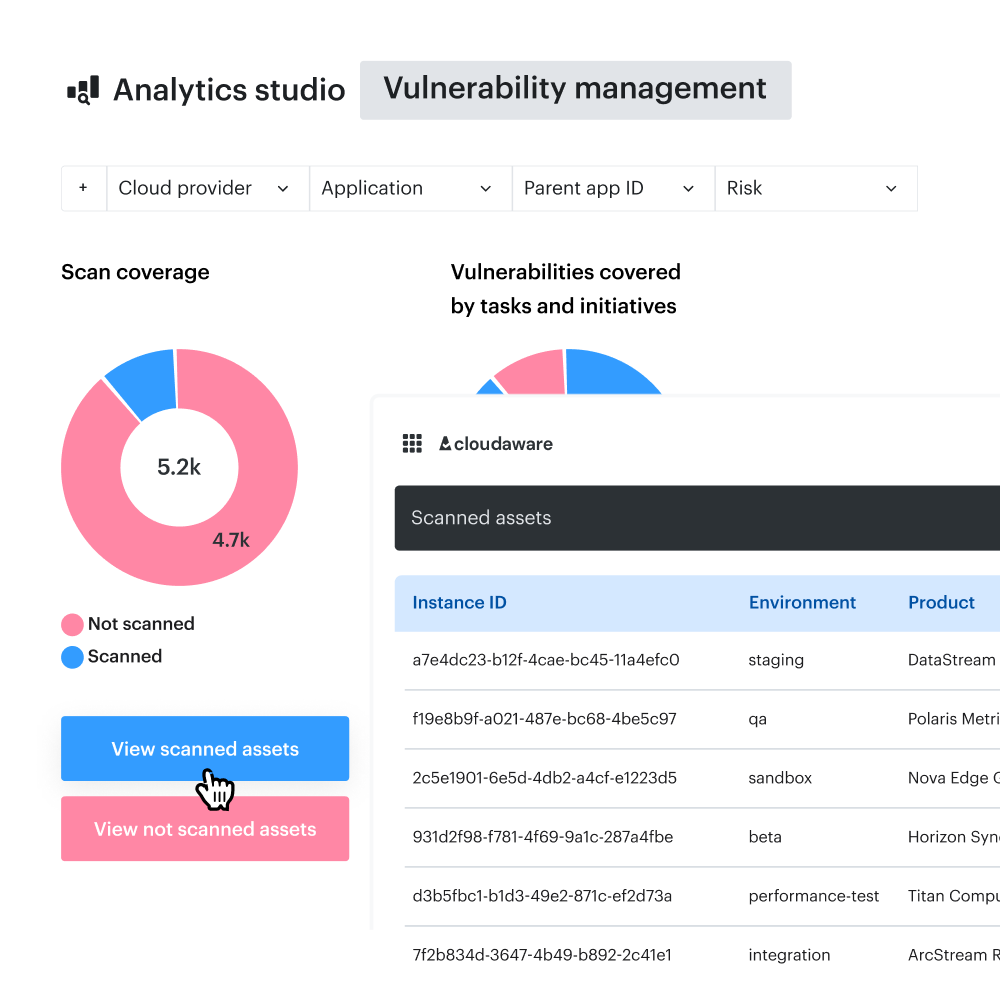
Want more details? Check how it works live.
Now the fun question. If you stop shipping known risk, how much does your change failure rate drop, and how many rollbacks disappear with it?
Reduce change failure rate (fewer rollbacks, fewer ‘hotfix Fridays’)
Execs don’t ask you for your backlog of findings. They ask one thing after a bad deploy: “How did this make it to production?”
That’s why change failure rate belongs in your DevSecOps pitch. It’s the percentage of deployments that cause degraded service or require remediation like a hotfix or rollback. (Google Cloud) Lower it and you reduce customer impact, cut escalation time, and stop paying for reversals with engineering hours.
The “best teams” proof is already out there. DORA-style benchmarking consistently shows elite performers ship dramatically more often with lower change failure rates, not higher.
One 2024 performance-cluster analysis reports elite teams deploy 182× more with 8× lower change failure rate. (Octopus Deploy) That’s the business argument: speed and stability can move together when the release path is controlled.
What breaks controlled delivery in real life is drift. Your pipeline can be clean and you still deploy into a cloud environment that quietly changed. One security group tweak, one role widened, one “temporary” console edit. Drift checks catch “the environment isn’t what you think it is” before production teaches you the lesson.
And if you want the stat that makes MTTR land on a slide: DORA’s research shows elite performers restore service in under an hour while low performers report months, a gap measured in the thousands. (Google Cloud)
That’s the next win to sell.
Read also: 10 DevSecOps Best Practices That Actually Survive Production
Faster recovery when incidents happen (shorter MTTR)
MTTR is the metric leadership understands without a translator. It answers the only question that matters mid-outage: how long until customers stop feeling it?
Run the math for a normal week. You have two production-impacting issues. Each one drags for 3 hours because the first hour is spent figuring out what changed. That’s 6 hours of degraded service, a pile of escalations, and a security leader pulled into status calls instead of managing risk. Now picture that same org with an average time-to-restore closer to 60–90 minutes. Same number of problems, radically different business cost.
DevSecOps gets you there by making response faster at the boring parts. The parts everyone forgets to fix because they’re not glamorous. Change traceability. Ownership clarity. Evidence you can trust.
When responders don’t know whether it was a container image, a Terraform module, or a cloud config tweak, they either roll back blindly or freeze. Both options burn time. Add ownership routing, and you cut the “who’s on point” delay. Add an auditable change trail, and triage stops being a Slack scavenger hunt. Suddenly your incident response becomes a repeatable process instead of a heroic effort.
Cloudaware ties incidents back to the exact infra/config change so responders aren’t guessing which deployment broke prod.
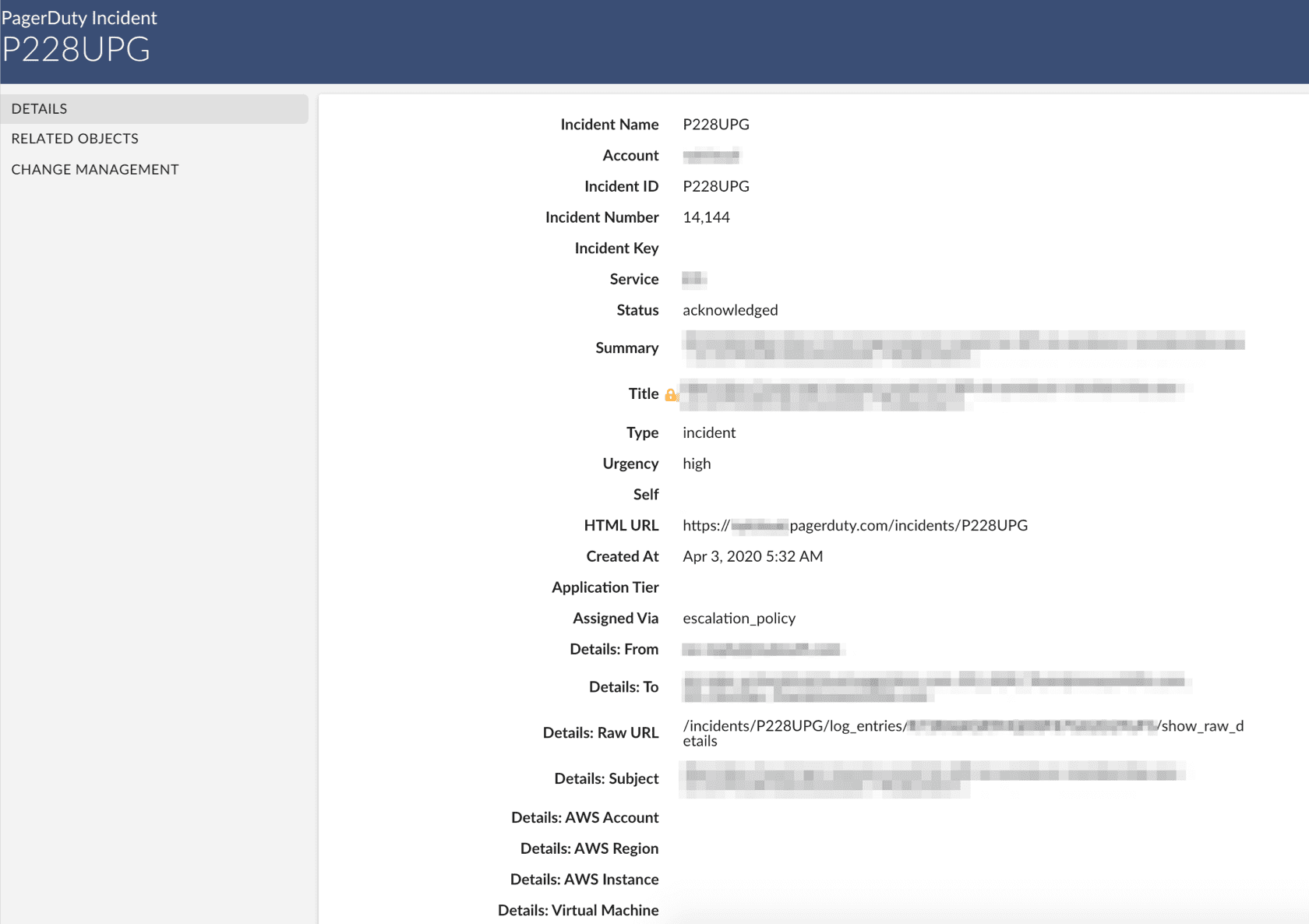
Want more details? Ask our expert.
That speeds triage, makes rollback decisions calmer, and turns postmortems into improvements instead of blame.
And once you can restore quickly, the next question becomes preventative: how do you stop the most common cause of cloud pain from shipping in the first place? That’s misconfigurations, especially when everything is driven by IaC.
Read also: What Breaks in Delivery When DevSecOps vs SDLC is Misunderstood
Fewer misconfigurations reach production (especially in cloud/IaC)
One of the sneakiest benefits of DevSecOps is that it reduces “oops surface area” before customers ever feel it. In the cloud, most ugly outcomes start small. A bucket goes public “just for a minute.” A security group opens up “temporarily.” An IAM role gets wildcarded because someone needed to unblock a deploy.
That’s not a rare edge case, either. Unit 42 found nearly 65% of known cloud security incidents were due to misconfigurations, with IAM configuration as the main culprit. (Palo Alto Networks) And Microsoft is blunt about the point of DevSecOps here: reduce the risk of deploying software with misconfigurations and other vulnerabilities attackers can exploit. (Microsoft)
Here’s how you make misconfiguration prevention real, not aspirational. Put two trend lines next to each other and watch what happens:
- Policy violation rate in CI: what your pipeline catches while it’s still just code.
- Prod drift rate: how often the live cloud environment deviates from what was approved.
If CI is “catching” 40 violations a week but drift stays flat at 10–12 changes, your controls are advisory. When drift drops to 1–2 while CI keeps blocking the same risky patterns, you’ve got baseline enforcement that leadership can trust.
An IaC policy approach makes this fair for development teams. Clear rules, enforced before merge, no Friday debates about what’s “acceptable.”
Cloudaware enforces cloud-specific policies pre-deploy, then continuously detects drift post-deploy.
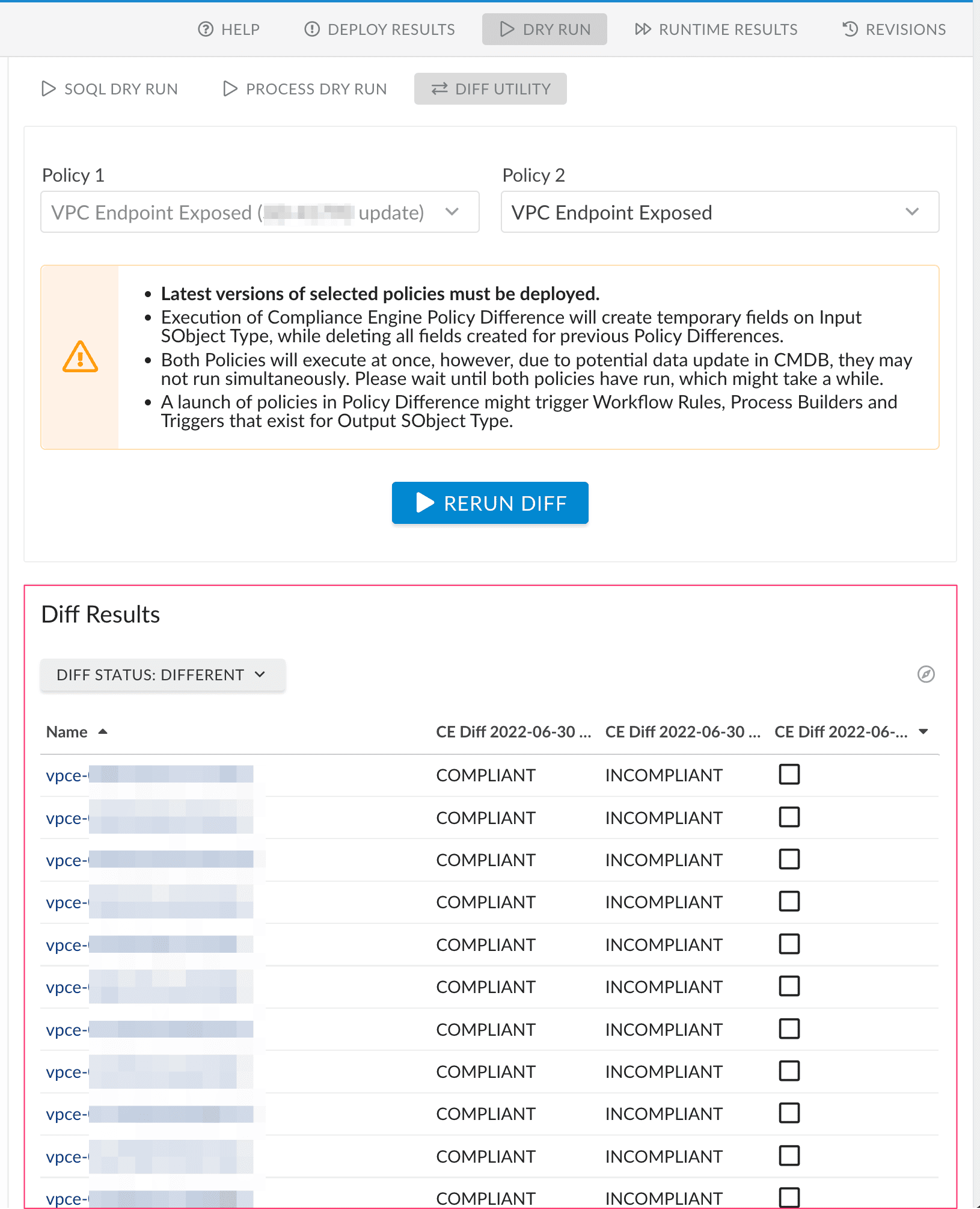
Want to know how it works? Ask our expert.
That’s baseline enforcement you can explain in one sentence and defend in an audit.
And once misconfigs stop slipping through, the next win basically writes itself. Compliance stops being a quarterly scavenger hunt because evidence is produced as part of the process.
Read also: Six pillars of DevSecOps - Practical Guide to Their Implementation in a Pipeline
Compliance becomes continuous (audit prep stops being a quarterly panic)
Ask any security leader what “audit readiness” really costs and they won’t say the audit fee. They’ll talk about the hidden labor bill. Evidence requests, screen grabs, spreadsheet archaeology, and the sprint that quietly disappears.
That pain is showing up in industry numbers now. In RegScale’s State of Continuous Controls Monitoring survey (250+ infosec leaders), 58% said they spend 2,000+ person-hours a year on evidence collection, and 83% said manual compliance work causes moderate or major delays in meeting requirements.
When compliance becomes a scramble, it also becomes a risk multiplier because teams are distracted, controls drift, and leadership starts getting “we think we have it” answers.
Here’s the predictable failure mode. An auditor asks for proof a control was enforced on that release. The control exists, sure. The evidence is scattered. Pipeline logs rotated out. Tickets say “approved” without saying what was checked. Screenshots are stale. Confidence dies right there.
Continuous compliance fixes the gap by making evidence automatic. Not “we’ll document it later.” Evidence created at the moment the change happened.
Two metrics make this board-ready:
- Audit evidence lead time (request → proof). If you’re at 3–5 days, you’re one vacation away from chaos. Mature teams drive it down to same day, sometimes under an hour, because the record is already assembled.
- % controls with automated evidence. Moving from 25% to 70% is not vanity. It’s fewer missed artifacts and fewer late “please send me proof by EOD” pings.
In a Cloudaware dashboard, you can pull up a change record and see the evidence right there: what was checked, which policy evaluated it, the result, and who approved promotion.
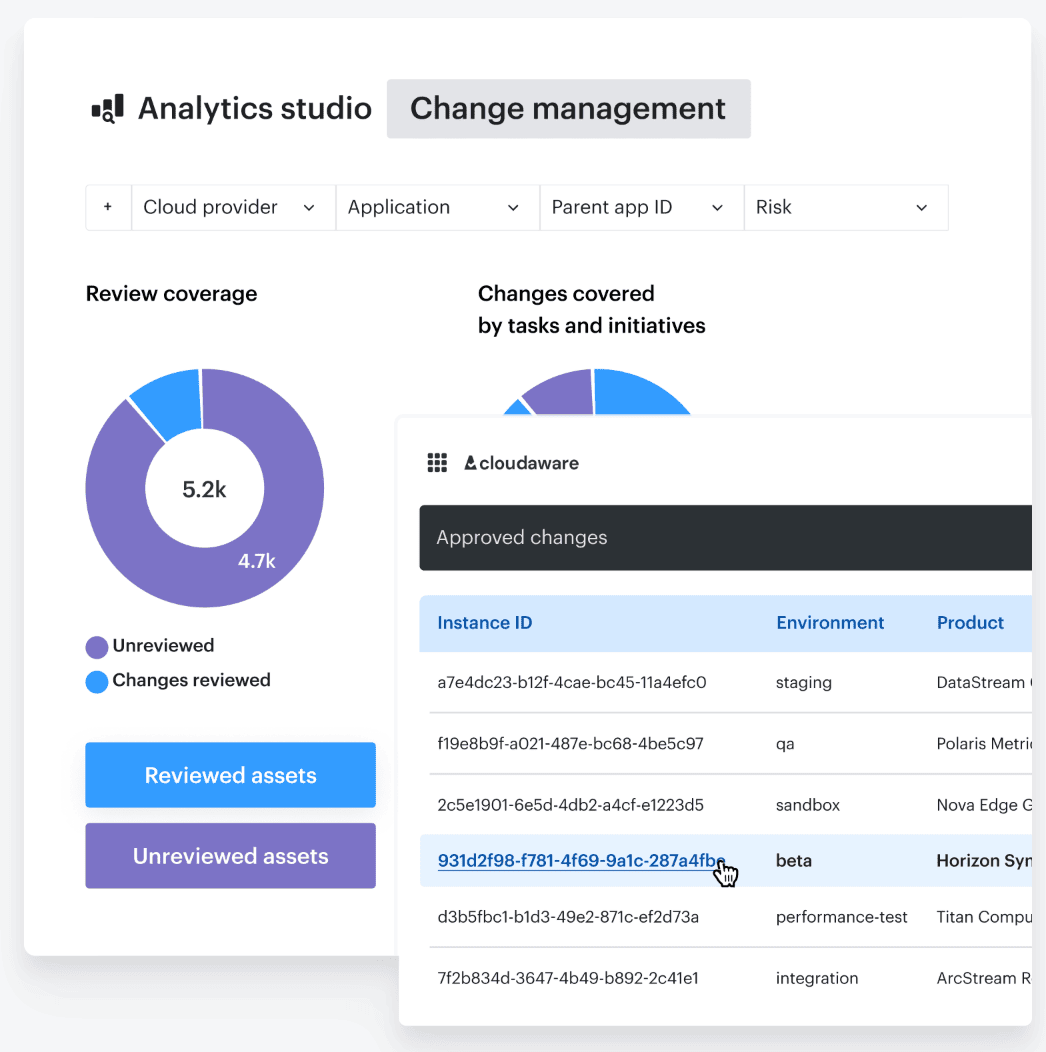
Want to know how it works? Ask our expert.
Click into a failed check and you get the inputs that mattered, not a pile of logs. That’s what “audit trail becomes queryable” looks like in real life, and it’s why the next question gets sharper fast.
Because once evidence is easy, you can’t hide behind “we didn’t know.” Ownership becomes visible. The right team gets the fix. That’s where accountability stops being abstract.
Read also: DevSecOps vs DevOps: What’s the Difference [Explained by a Pro]
Clearer accountability when security stops being ‘someone else’s job’
A finding shows up. It has a severity. It has a due date. What it doesn’t have is an owner. So it pings SecOps. Then it pings the platform team. Then it sits because nobody wants to touch the service they don’t control. Weeks later, you’re still “tracking” it, which is audit-speak for “we lost.”
This is where Agile DevSecOps gets practical. Shared responsibility doesn’t mean everybody does everything. It means the process knows who does what, automatically, every time. The people closest to the change fix it. Security defines the rule and watches outcomes. Ops handles the runtime realities. That’s Dev/Sec/Ops collaboration without the endless handoffs.
Make the win visible with two metrics:
- Start with % findings auto-routed to an owner. In a typical org, it’s painful to see 40% routed right on the first try and the rest bouncing through triage meetings. Mature programs get that number north of 80% because ownership is attached to services, repos, and cloud accounts.
- Then measure SLA adherence. If only 50% of “critical” issues close inside the agreed window, you don’t have a risk program, you have a reporting program. Push it to 85% and leadership can finally trust the burn-down.
You can learn more in our guide on “DevSecOps Roles and Responsibilities: Who Does What and Teams Structure”. And once you remove the ownership fog, the cost of fixing drops hard because you stop paying the coordination tax. That’s the next benefit.
Lower cost of fixing security issues
Want a fast way to waste security budget? Let issues age.
A vulnerability found in a pull request is a quick patch and a re-run. That same vulnerability found after release drags in more people, more meetings, more risk conversations, and usually a rollback plan “just in case.” The fix didn’t get harder. The coordination did. That’s the hidden line item nobody puts on the spreadsheet.
This is why the benefits of DevSecOps are so easy to defend to leadership. You’re not asking for perfection. You’re buying rework reduction by catching problems while the context is still warm. In a normal pipeline, you can see it in the numbers. Reopened tickets drop when “done” actually means done.
If your reopened ticket rate is sitting around 20% because teams interpret findings differently, pushing it down to 8–10% is a straight cost win. Less retesting. Fewer handoffs. Fewer late-stage “wait, this is still failing” surprises.
Then there’s the metric that should make every CISO lean in: escaped defect rate. Track how many vulnerabilities make it past testing and land in production anyway. If you’re currently seeing, say, 12 critical issues a month discovered post-release and you bring it to 3, you didn’t just improve cybersecurity posture. You reduced interruption risk and kept software development moving.
Cloudaware helps by standardizing what “pass” looks like across pipelines so teams don’t debate every finding.
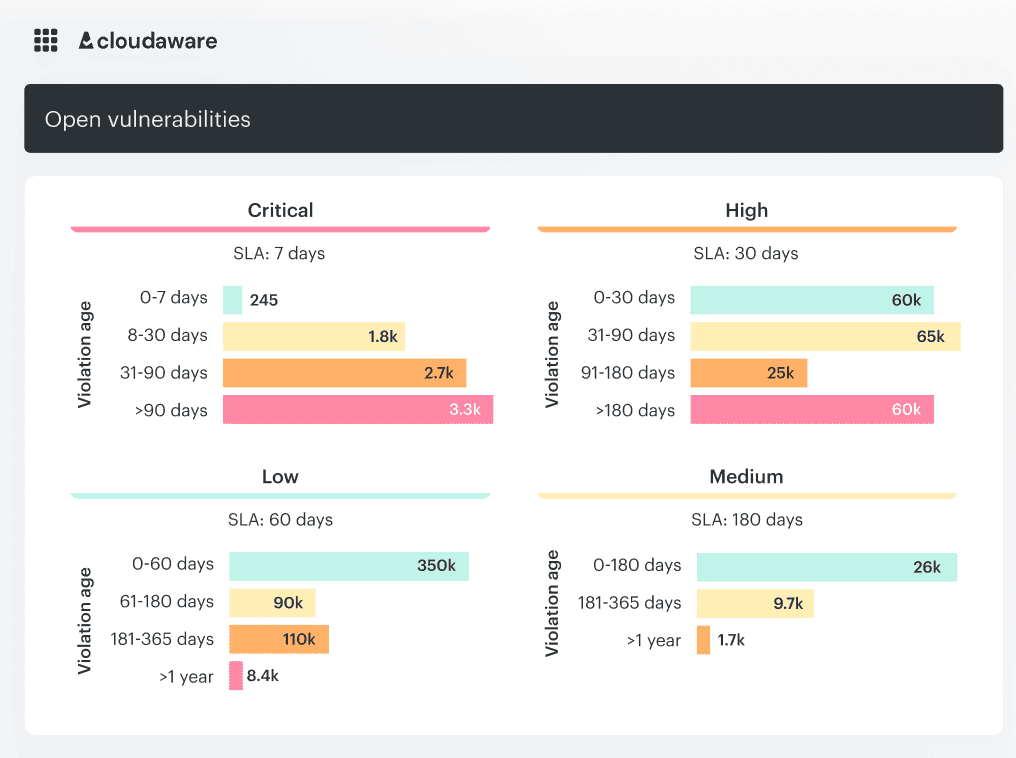
An element of the vulnerabilities dashboard in Cloudaware.
The rule is the rule, applied consistently across software development workflows, not re-litigated per team, per repo, per Friday afternoon.
And here’s the payoff leadership will love. When remediation gets cheaper and clearer, you can ship faster without gambling. That’s the next benefit: safer releases that don’t turn security into the bottleneck.
Read also: Inside the DevSecOps Lifecycle. Decisions, Gates, and Evidence
Faster, safer releases with security without becoming the bottleneck
Security becomes a bottleneck when it behaves like a separate department you visit at the end. “We’re ready to ship, can you review?” That’s how you get slow releases, rushed approvals, and quiet risk.
Now the uncomfortable stat. GitLab’s research on delivery delays has repeatedly pointed to late, manual testing as a major drag on release speed.
In their survey write-ups, teams report automation gaps and poor “in-the-workflow” visibility for results, including fewer than 25% enabling lightweight SAST in a web IDE and only 20% surfacing results in a pipeline report, plus 16% making DAST/dependency scan data available and 14% doing the same for container scan data.
Translation: a lot of organizations still run security like a separate phase and then wonder why delivery slows down.
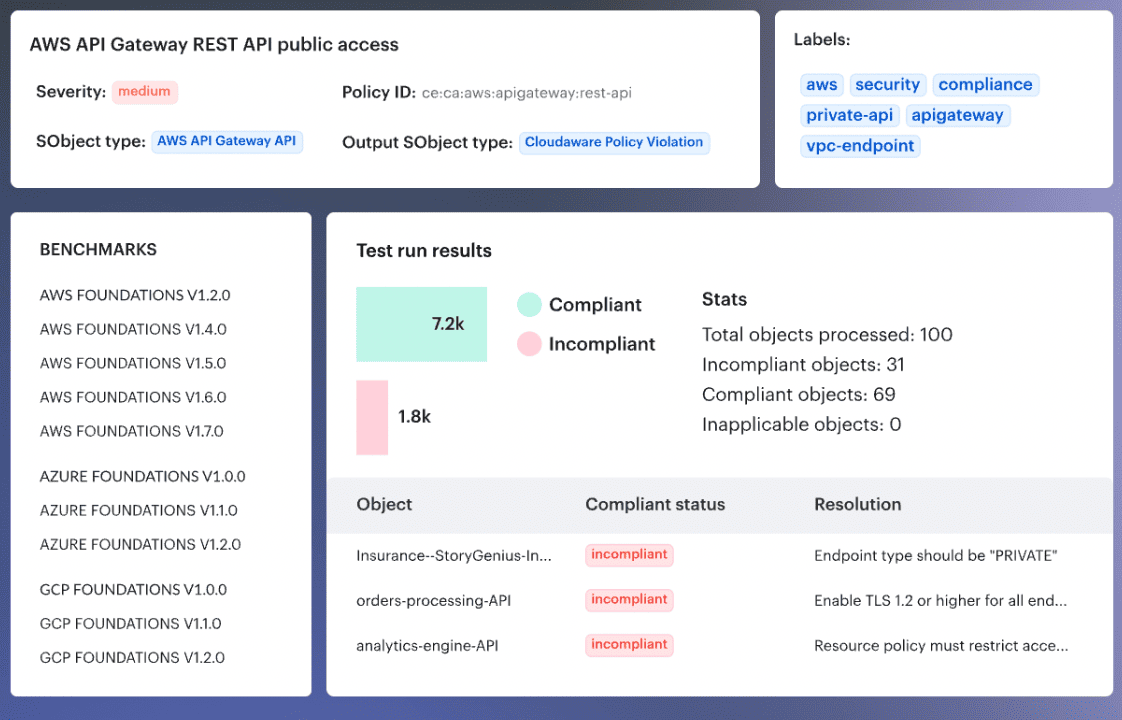
An example of a DevSecOps scan results in Cloudaware. Want to know how it works? Ask our expert.
The DevSecOps advantages show up when security becomes a predictable part of CI/CD. Checks run automatically. Policies are explicit. Approvals are based on data, not gut feel.
The release either qualifies for promotion or it doesn’t, and everyone can see the reason. That’s what secure delivery looks like in practice: fewer debates, fewer exceptions, fewer last-minute escalations.
If you need proof for leadership, use DORA’s throughput metrics. DORA defines deployment frequency and lead time for changes as core measures of software delivery performance.
When manual reviews stop being the critical path, deployment frequency rises. When teams aren’t re-litigating every finding, lead time drops. And yes, mature teams often move from weekly “big bang” releases to daily smaller changes because DevSecOps automation makes risk manageable.
Once releases are fast and controlled, the next question becomes obvious. When something does break or an auditor asks “why did this ship,” can you see the full story across the SDLC? What changed, where it ran, and who approved it. That’s visibility 👇
Read also: DevSecOps vs CI/CD. How to Build a Secure CI/CD Pipeline
Better visibility across the SDLC (what changed, where, and why)
Picture the executive moment. A production issue hits. Legal asks if customer data was exposed. An auditor pings for evidence on a specific release. Everyone turns to you and waits for one answer: what exactly happened.
If you can’t reconstruct the story fast, you don’t just lose time. You lose trust.
This is where the best DevSecOps benefits stop being “security stuff” and start looking like governance. You get a single thread of traceability from commit to build to deploy to cloud config. No Slack archaeology. No competing spreadsheets. You can point to the artifact, the dependency set, the checks that ran, and the approval that let it through. That’s end-to-end visibility over your software supply chain, which is the real thing leadership is buying when they fund DevSecOps.
Make it measurable with the DevSecOps metrics leadership already recognizes. DORA numbers only matter if you can explain them. Say your teams improve deployment frequency from weekly to daily and cut lead time from 4 days to 1. That’s a win. It becomes a risk if you can’t answer “which change caused the spike” without a two-hour investigation. Visibility turns that investigation into a query.
Cloudaware keeps Jenkins, GitHub Actions, or GitLab in place, then layers policy and approvals over the release path.
Here is an example of what it looks:
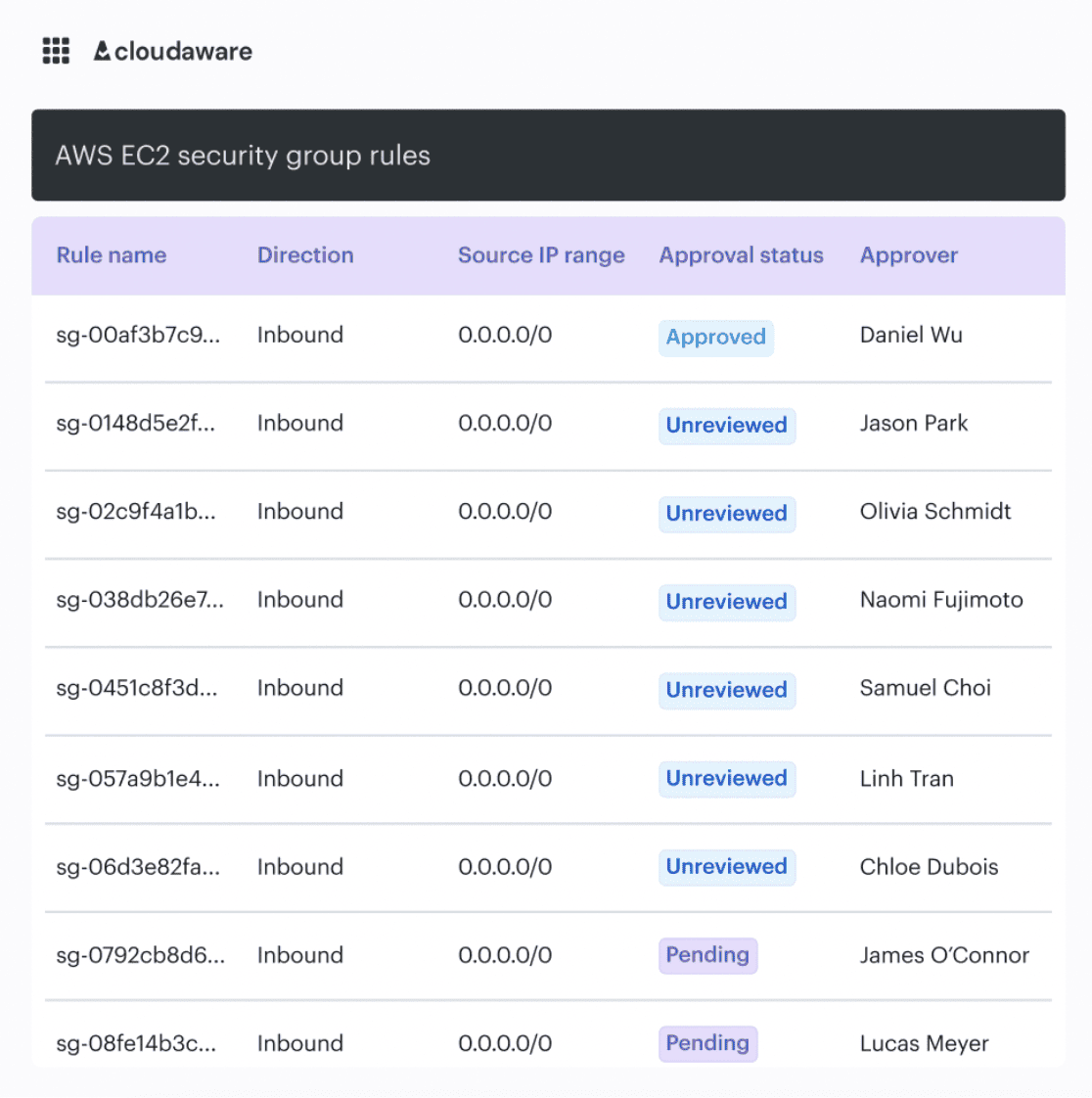
The result is one consistent decision trail across teams and tools, even when your pipelines aren’t identical.
Next section is where you cash this in. Once you can see the story end to end, proving value isn’t a slide deck exercise. It’s a scoreboard. Let’s talk about how to prove DevSecOps is delivering benefits.
Read also: 15 DevSecOps Tools. Software Features & Pricing Review
How to prove DevSecOps is delivering benefits
Proof is the difference between “DevSecOps sounds nice” and “DevSecOps is funded.”
Leadership doesn’t need another maturity model. They need a scoreboard that shows risk going down while delivery stays fast. So you pick a small set of metrics that connect the pipeline to business impact, then you track the trend monthly. Not vanity numbers. The ones that move when your tools, testing, and ownership model actually work.
A simple rule helps. If a metric can’t be influenced by your security and platform program, it’s noise. If it can, it becomes leverage.
Cloudaware dashboards can centralize these signals into one platform-level view, so you’re not stitching together screenshots from five systems every time someone asks “is this working?”
| Metric | What “good” looks like | What improves it | What breaks it |
|---|---|---|---|
| Deployment frequency (DORA) | Smaller, more frequent releases (daily or multiple times/week for key services) with stable outcomes | Automate checks in CI, keep gates predictable, release in small batches | Big-bang releases, manual approvals by exception, security review as a phase |
| Lead time for changes (DORA) | Lead time trending down (ex: 4 days → 1 day) without rising failure rates | Shift security earlier, fast feedback in PR, standard “pass” criteria | Waiting for end-of-sprint security testing, inconsistent rules per team |
| Change failure rate (DORA) | Low and falling (ex: 15% → under 5% for high-change services) | Release conditions tied to real controls, drift checks, consistent gating | “Ship now, fix later,” bypass paths, environment drift ignored |
| Time to restore service (DORA) | Time-to-restore shrinking (ex: 3 hours → 60–90 minutes) | Traceability from change to impact, clear ownership routing, practiced rollback | Guessing which deploy broke prod, unclear ownership, rollback as chaos |
| Vulnerability MTTD (security ops) | Discover risky changes fast (minutes/hours, not days) | Always-on scanning, alerts tied to changes, coverage across repos and IaC | Batch scanning, scanning only on releases, alerts with no context |
| Vulnerability MTTR (security ops) | MTTR trending down month over month (ex: 14 days → 5 days for critical classes) | Fix-in-PR flow, routing to the right team, fewer reopen loops | Tickets bouncing between teams, unclear severity rules, “accept risk” as default |
If these six trends move in the right direction together, you’ve got a real DevSecOps program. If deployment speed improves but the failure rate spikes, you’ve built acceleration without brakes. If you reduce vulnerabilities but delivery slows to a crawl, you’ve built a security tax. The win is balance; measured with clean data, you can defend.
Common misconceptions about DevSecOps isn’t ‘more tools’— it’s fewer arguments
⚠️ “We installed a scanner, we’re DevSecOps now.”
A scanner is a sensor, not a control. It can tell you there are vulnerabilities, but it can’t make anyone fix them, and it definitely can’t prove a decision was enforced. If findings land in a shared inbox with no owner, you’ll see the same pattern every quarter: lots of data, low closure, high reopen rate.
The importance of DevSecOps is enforcement plus accountability. Who owns the service. What “pass” means. What happens when it fails. Without those answers, you bought noise, not risk reduction.
⚠️“Security gates = slow delivery”
Bad gates are slow delivery. Good gates are fast decisions. The difference is design. If you gate on “everything must be perfect,” teams will bypass. If you gate on a short list of high-confidence signals, the pipeline stays predictable and teams trust it.
The best security gates feel like guardrails in software development. They’re consistent, they’re automated, and they don’t surprise anyone on release day.
That’s one of the real advantages of DevSecOps: fewer last-minute reviews and less rework because you fail early, in minutes, not after deploy.
⚠️ “One policy across all clouds”
That sounds efficient until you try it. AWS, Azure, and GCP don’t model identity, networking, and managed services the same way. A “simple” rule like public exposure or encryption can map to different resources, controls, and exceptions per provider. Treating them as identical creates gaps you won’t see until an auditor or an incident forces the comparison. DevSecOps works when policies are cloud-aware and the tools apply the right rule in the right place, with clear evidence and a decision trail.
These misconceptions are why some programs look busy but don’t move outcomes. Fix the thinking, then the metrics start behaving.
Reduce security debt with Cloudaware DevSecOps
You’ve just built the case for DevSecOps. Now you need the part that makes it real in a hybrid cloud org: consistent change control, evidence you can hand to an auditor, and approvals that don’t turn into a human bottleneck.
Here’s why DevSecOps often stalls in practice. Security sees findings, development sees noise, and nobody trusts the release decision because it’s scattered across CI logs, tickets, and tribal knowledge. Cloudaware tightens that loop by turning change data into an enforceable release path, with an audit-ready trail attached.
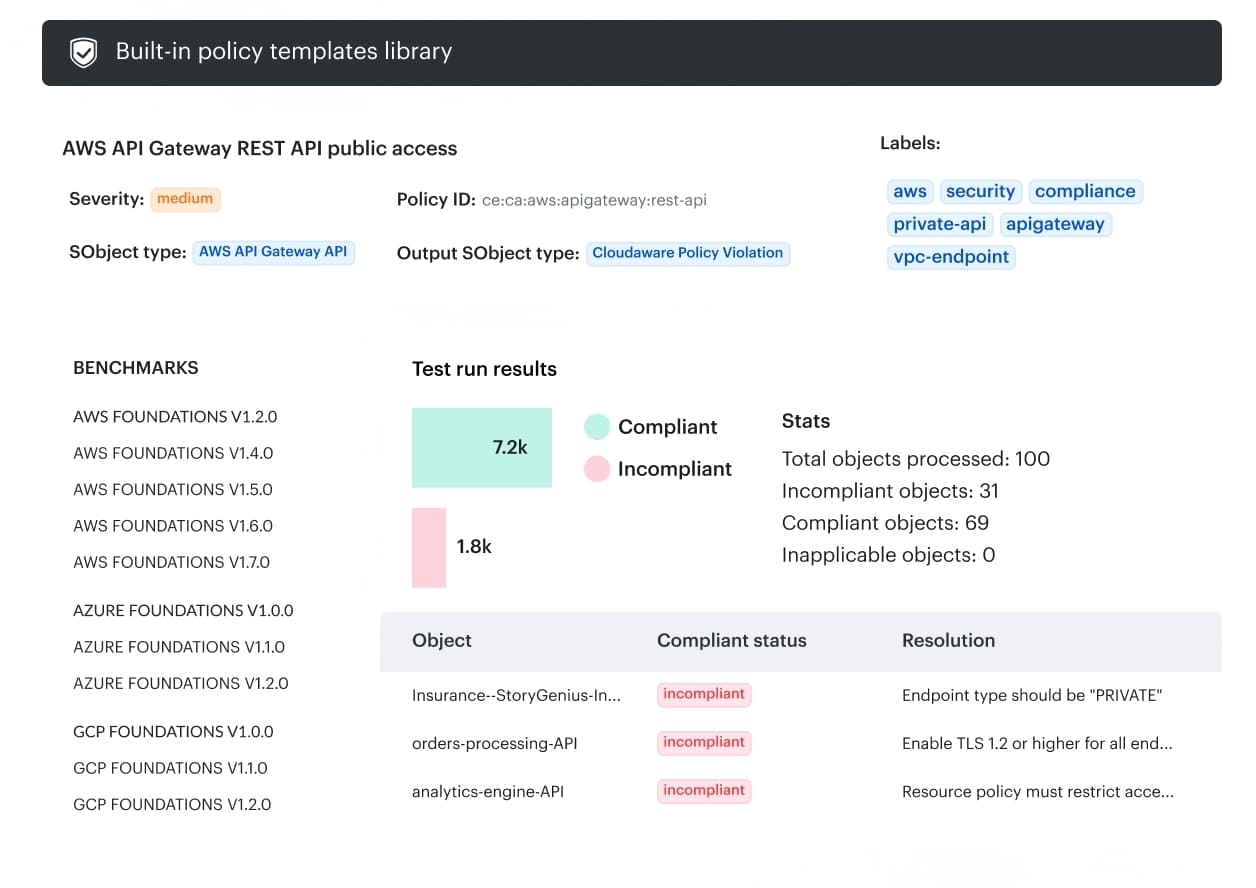
What Cloudaware does in the flow you’ve been describing:
- 100% change visibility across hybrid environments: track every change, who did it, and when, without relying on manual tagging.
- Real-time change review: stay in control of changes while keeping delivery moving.
- Policy-based go/no-go for infra and code releases: integrate signals from compliance/CSPM sources and block promotion when violations matter.
- Smart approvals that don’t waste humans: auto-approve low-risk changes, route high-risk ones to the right approver.
- Baseline + drift control: establish expected configs, detect drift, and keep a clean “what changed, where, and why” history.
- Audit-ready reporting: every approval/rejection/change is logged so evidence isn’t a quarterly scavenger hunt.
- High-risk change alerting + workflows: push the right events to Slack, Jira, ServiceNow, PagerDuty so response starts fast.
- Fast setup, low friction: read-only permissions, guided setup, 30-day trial with no credit card.
Cloudaware dashboards give you a platform-level scoreboard, so the same place you monitor release risk can also show the metrics your leadership cares about.