






High-frequency delivery exposes a mismatch between CI/CD velocity and audit preparation. When control evidence is assembled manually, engineering throughput degrades, and traceability gaps persist.
Compliance in DevSecOps focuses on treating audit readiness as an output of the delivery system. Controls are enforced in the pipeline, and evidence is generated continuously with a verifiable chain from change to build to deployment.
This article helps you learn how to implement pipeline controls in CI/CD so every change is provable via system-generated evidence. If you are currently preparing audits with screenshots and ad-hoc exports, these patterns will help to reduce audit lead time, increase control coverage, and preserve release velocity.
TL;DR
- IT compliance in DevSecOps stands for implementing compliance controls inside CI/CD so every change is provable via system-generated evidence.
- You don't need more “security tooling.” You need a delivery path that produces proof by default when release velocity is high and audit questions arrive late.
- Treat controls as pipeline behavior plus recorded outcomes. Every change should generate traceable evidence across PR approvals, pipeline runs, artifact identifiers, deploy records, and RBAC changes.
- Use gates for high-impact, high-confidence risk and warnings for the rest, or teams will ignore signals. Exceptions must be time-boxed with owner, scope, and closure criteria, or they become bypass debt.
- Keep a control-to-evidence matrix and an evidence library so audits become retrieval, not reconstruction. Evaluate platforms on end-to-end traceability, immutable history, exception lifecycle, and exports, not dashboards.
What compliance in DevSecOps means in practice
In DevSecOps, compliance isn't a document set or a last-minute audit scramble. Look at it as the behavior of your delivery system under real change velocity. What the workflow allows, what it blocks, and what it records by default matter more than what the policy says.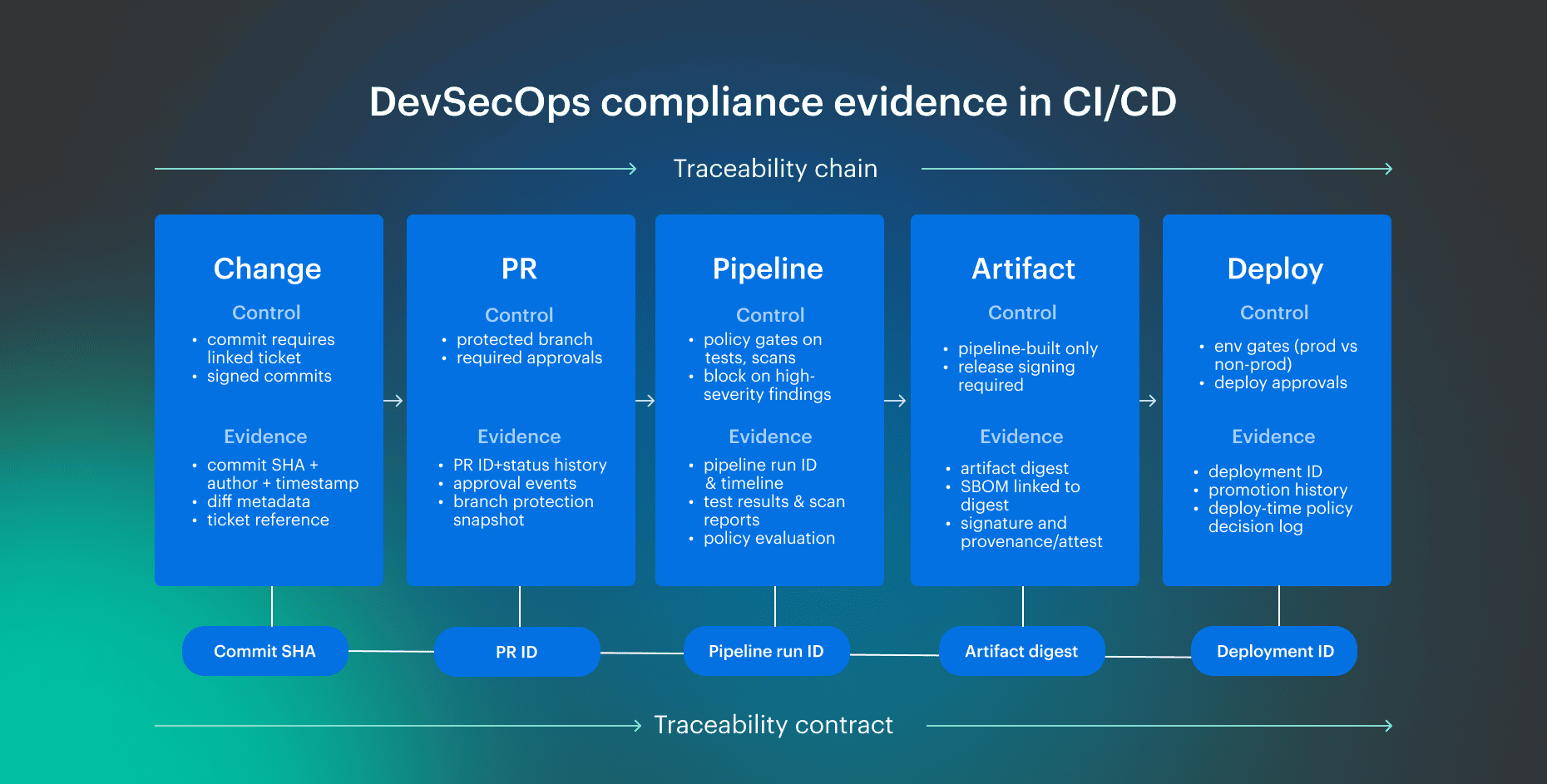 A control is the enforcement point in your workflow, plus the system record that it executed. If a requirement says “production changes require review,” the control isn't the sentence in a handbook.
A control is the enforcement point in your workflow, plus the system record that it executed. If a requirement says “production changes require review,” the control isn't the sentence in a handbook.
Evidence is the set of machine-generated artifacts that lets a reviewer validate the control without interpretation.
Traceability links those artifacts into a single chain. You should be able to start from what is running in production and walk backward deterministically.
This spans the development process and operations, because access, deployment, and cloud audit logs live outside code review.
Why periodic audits break in the cloud
High-velocity delivery plus infrastructure-as-code makes “audit season” a structural mismatch. When you ship daily and rebuild cloud environments through code, you cannot reliably reconstruct control execution weeks later from scattered exports and human memory.
If controls aren't enforced in-path and evidence isn't emitted continuously, audit prep becomes a parallel project that competes with delivery work.
In practice, one-time compliance fails not because teams refuse to follow rules, but because momentum matters. When requirements sit outside the delivery process, they become stop factors that slow shipping and push work into manual audit preparation.
Modern approaches embed compliance as you go, so controls execute inside CI/CD, and evidence is emitted continuously as part of normal workflows.
What actually breaks during audit prep:
- Evidence is spread across SCM, CI, artifact registry, CD, and ticketing, with no consistent link keys
- Pipeline runs aren't retained long enough, or logs aren't immutable or queryable
- Deployments cannot be tied back to a single artifact digest and pipeline run
- Configuration drift means “what is running” doesn't match “what was deployed”
- Access changes (RBAC, break-glass) aren't traceable to time windows and environments
- Exception approvals live in chat threads with no expiry or audit trail
- Screenshots substitute for system records, so verification becomes subjective
- Teams produce “evidence packs” that differ by service because there is no evidence standard
Continuous compliance as an operating model
Continuous compliance isn't “more checks.” It is a control system designed to run at the same cadence as delivery. Controls execute automatically at defined points in CI/CD, evidence is emitted as a byproduct, and exceptions are governed like change, not like informal approvals.
The practical goal of governance is to preserve delivery speed without losing control. Policies must apply automatically in the pipeline stages, not manually at the end. The best setup makes risk visible early so engineers can fix it before shipping, not at release time.
Gates and warnings
Blocking everything kills delivery. Warning on everything creates noise and trains teams to ignore security output. A workable model separates enforcement into gates and warnings based on impact, confidence, and environment.
Gates are for high-confidence, high-impact outcomes where shipping is objectively unsafe or noncompliant, especially in production.
Typical gate candidates are: leaked secrets, critical vulnerabilities with known exploitability in a shipped component, prohibited licenses, unsigned release artifacts, and deployment to a restricted environment without required approval.
Warnings are for signals that need triage, not an immediate stop.
These include low-confidence findings, informational issues, early maturity rules you are still tuning, and results that require human context. Warnings should still produce evidence, open tickets, and be tracked to closure, but they should not block the pipeline by default.
| Low confidence | Medium confidence | High confidence | |
|---|---|---|---|
| Low severity | Ignore | Warn | Warn |
| Medium severity | Warn | Warn | Gate in prod, warn elsewhere |
| High severity | Warn | Gate in prod, warn elsewhere | Gate |
Read also: DevSecOps Automation Stages Across CI/CD
Rules for expiring exceptions
Exceptions are normal in real systems. The failure mode is permanent exceptions that become hidden policy debt. Every exception must have an owner, a clear justification, the risk being accepted, compensating controls, an expiry date, and closure criteria.
- Treat exceptions as first-class objects in the delivery process. Store them in a system of record, scope them to specific services and environments, and link them to the exact control they override (for example, “block deploy on critical CVEs”).
- Reviews must run on a fixed cadence. Expiry must be enforced with automated notifications, and the default behavior on expiry must be deterministic: fail closed or require explicit re-approval. Otherwise, you recreate audit season in slow motion, with unmanaged waivers accumulating across services.
- Use a consistent exception schema so auditors and engineers see the same thing. The schema should support machine enforcement in CI/CD and human review in governance workflows.
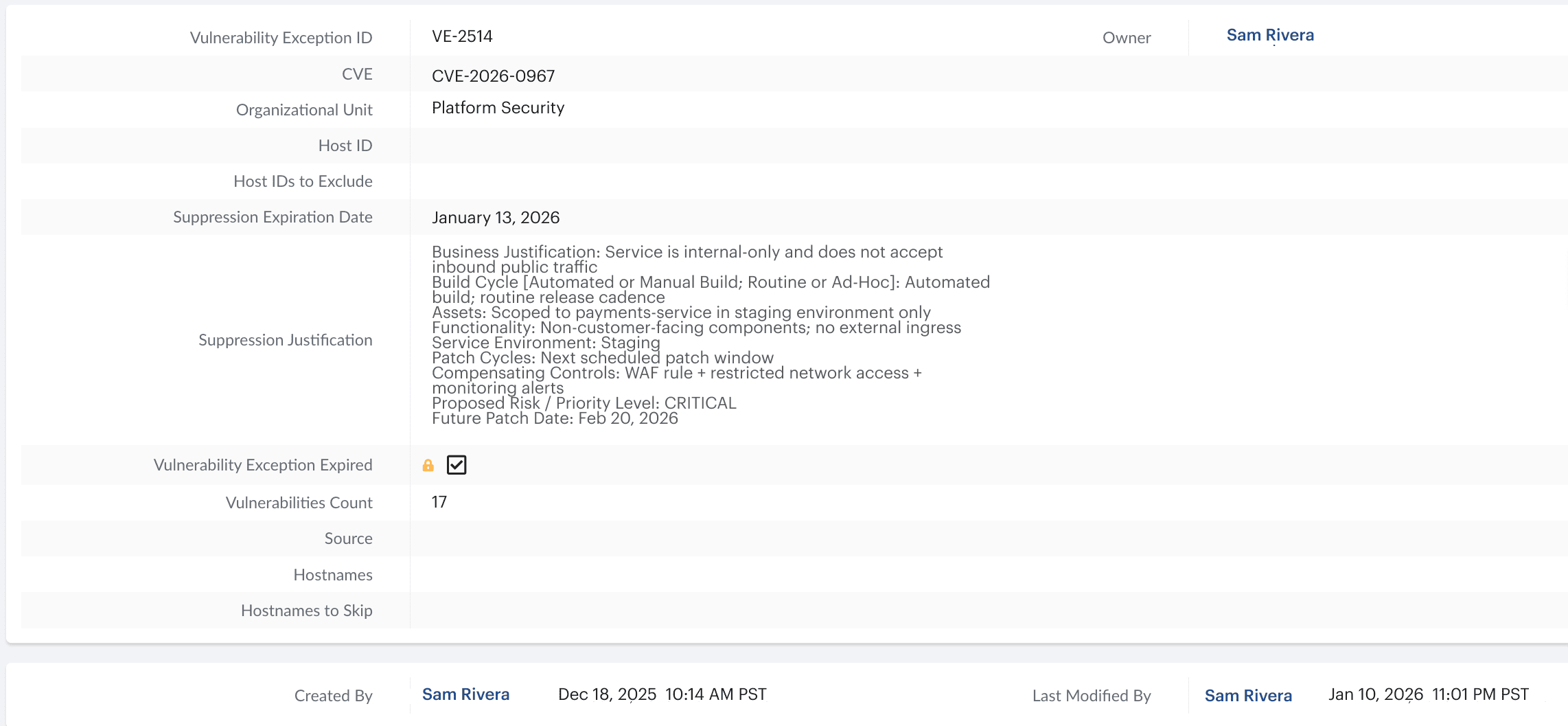 Example of a time-bound exception object in Cloudaware. This prevents permanent waivers and keeps exception debt visible.
Example of a time-bound exception object in Cloudaware. This prevents permanent waivers and keeps exception debt visible.
Exception template:
- Exception ID:
- Control overridden:
- Scope (service/env):
- Owner:
- Reason:
- Risk statement:
- Compensating controls:
- Expiry date:
- Closure criteria:
- Approver:
- Evidence link(s): (PR, pipeline run ID, ticket)
Read also: DevSecOps Architecture Reference Model Teams Use
Compliance as enforceable policy
Most requirements fail because they remain human-only. If a control exists only as wiki text, it will be bypassed, interpreted inconsistently across services, or “fixed” during audit prep. The implementation target is explicit: requirements must become enforceable workflow rules, and the system must emit a record every time those rules evaluate.
Treat every commit as a trigger. The delivery system evaluates policy automatically and emits evidence without manual collection. Coverage should include the codebase, container artifacts, and, where applicable, deployed inventory. The objective is enforcement at delivery cadence with outputs that are queryable after the fact.
Policy-as-code with reviews and ownership
Policies should behave like production code. They must be version-controlled, reviewed, tested, and rolled out safely. If a policy change alters what can ship, it is a risk change and requires change management and traceability comparable to infrastructure changes.
Start with an explicit ownership model:
- Policy owner: who owns the policy domain (branch protections, artifact integrity, deployment approvals)
- Approvers: who can approve policy changes and under which conditions
- Change workflow: how policy updates are proposed, reviewed, tested, and rolled out
- Enforcement mode: what is gated vs warned, and where (by environment)
- Exception authority: who can grant exceptions, for what scope, and with what expiry
- Tuning accountability: who reduces false positives without weakening controls
- Evidence mapping: what evidence each policy emits and where it is stored
Use a simple lifecycle and apply it consistently:
- Draft: write the policy intent and scope (service, environment, severity).
- Review: require platform and security sign-off with explicit approval boundaries.
- Test: run in warn mode on real pipelines to measure noise and false positives.
- Rollout: enable enforcement gradually, starting with production or high-risk paths.
- Monitor: track outcomes, exception volume, and time-to-remediation.
- Iterate: tune thresholds and reduce noise without weakening controls.
Control points across the CI/CD pipeline
In cloud environments, access changes and deployment events must be captured as evidence with the same IDs as CI/CD outputs. Audit-ready delivery requires deterministic evidence at each control point. Evidence must be emitted by the delivery system, and each stage should produce machine-generated records that are validated without interpretation.
At the code and PR boundary, every change is tracked and tested. This is the change-management core audit team expects: who changed what, how it was reviewed, which checks were executed, and which policies were evaluated.
In CI, the pipeline run is the unit of proof. It ties test outcomes, scan results, and policy decisions to a specific commit and PR. Build outputs must then be immutable and verifiable so a release can be proven after the fact.
Artifact integrity and provenance
Building evidence should prove integrity and provenance. Use reproducible builds where possible. Require signed release artifacts and retain metadata that proves inputs were controlled (for example, dependency locks). Provenance or attestation should capture the chain of custody: who built it, what inputs were used, and what outputs were produced.
Deploy evidence and change trace
Deploying evidence should prove the promotion rules and the policy enforcement. If approvals are required, the approval event is evidence.
Promotion history must show how an artifact moved across environments. Change trace must remain intact end-to-end: PR to pipeline run to deployment event to the version that is running. At deploy time, rules must auto-enforce, and access must be tightly controlled. If enforcement and access logging are weak, evidence fragments across tools and becomes non-verifiable.
Use the pipeline checkpoint table below as a cheat sheet:
| Stage | Control/check | Evidence artifact | Where stored |
|---|---|---|---|
| Code/PR | Protected branch + required approvals | PR approvals + review timeline | SCM (PR system) |
| Code/PR | Required status checks | Check results bound to PR/commit | SCM + CI |
| CI | Pipeline execution | Pipeline run ID + job timeline + logs | CI system |
| CI | Security scans (SAST/SCA/secrets/IaC) | Scan reports + policy decision (pass/fail) | CI/security tooling |
| Build | Reproducible build + locked inputs | Build metadata + lockfiles | Repo + CI artifacts |
| Artifact | Signing + provenance | Artifact digest + signature + attestation | Artifact registry |
| Deploy | Environment policy + approvals | Deployment record + approval event | CD system/environment controls |
| Access | RBAC changes tracked | RBAC audit log entries | Cloud/IAM audit logs |
Read also: DevSecOps Change Management for audit-ready releases
Evidence automation without screenshots
Automation value is not adding another scanner. It is the delivery system taking ownership of checks, evidence, and traceability. When pipelines validate against regulatory requirements, you get a repeatable proof line: check outputs, policy decisions, change history, and access-control records in a format an assessor can verify without manual assembly.
The evidence pipeline
Treat evidence as an engineered dataset with explicit guarantees: retention, integrity, access control, and deterministic retrieval. Define a minimum dataset and make it non-optional:
- Change events: PR merges, approvals, branch protection state at merge time
- Pipeline runs: run ID, job graph/timeline, required check outcomes, scan outputs, policy decisions (pass/fail + rule version)
- Artifact metadata: digest, build metadata, SBOM/provenance pointers, signatures
- Deploy events: deployment ID, environment, who/what/when, promotion path, deploy-time policy decisions
- Access/RBAC changes: grants/revokes, role changes, break-glass usage, time windows
- Exception lifecycle: exception ID, scope, owner, justification, compensating controls, expiry, approvals, re-approvals, closure
Store evidence in systems that enforce retention and integrity guarantees. Use tamper-evident semantics (append-only logs, immutable object storage, or verifiable hashing) and a consistent indexing scheme so evidence is queryable by service, environment, and date range.
The evidence library
Audits slow down when each service invents its own evidence pack. Standardize evidence types and fields so outputs are consistent across services and environments. Use naming conventions and indexing that support deterministic retrieval: service, environment, control_id, date_range, source_system, immutable_id (run ID, digest, deploy ID). Cloudaware example: a policy violation routed to Jira as a system-of-record evidence item with required documentation, status, timestamps, and an attached evidence artifact.
Cloudaware example: a policy violation routed to Jira as a system-of-record evidence item with required documentation, status, timestamps, and an attached evidence artifact.
Read also: DevSecOps Maturity Model - Scorecard You Can Measure
SOC 2 control mapping to pipeline proof
Most SOC 2 questions reduce to one requirement: prove controls without manual screenshots. The only scalable approach is to show that evidence is generated during delivery. Every change is tracked, policies are enforced, access is controlled, and reporting is produced from a single evidence trail.
Use the matrix below as a copy/paste starting point. Read it left to right: control theme, where it is enforced, what evidence is emitted, where it is stored, and how an external reviewer can validate it. A strong maturity signal is when multiple frameworks can be enforced concurrently, and reporting and policy enforcement are centralized instead of being recreated per compliance audit.
This mapping approach also works for ISO/IEC 27001.
Control-to-evidence matrix
| Control theme | Where enforced | Evidence | Location | Auditor checks |
|---|---|---|---|---|
| Change approval | PR rules | PR approvals + review timeline | SCM | Verify required approvals and reviewers |
| Branch protection | SCM settings | Protected branch config snapshot | SCM | Verify no direct pushes, required checks enabled |
| Required checks | CI gate | Required check results bound to PR/commit | SCM + CI | Verify checks passed at merge time |
| Build integrity | CI/build | Build metadata + run ID | CI | Verify run ties to commit and job timeline |
| Artifact integrity | Registry | Artifact digest + signature | Registry | Verify digest/signature match deployed artifact |
| Provenance | CI/registry | Attestation/provenance linked to digest | CI/Registry | Verify who built, inputs, outputs |
| Vulnerability management | CI scans | Scan report + policy decision | CI/Sec tooling | Verify decision and remediation linkage |
| Secrets control | CI scan | Secrets scan result + block/warn decision | CI | Verify secret findings are gated |
| Access control changes | IAM/RBAC | RBAC change events + actor + timestamp | Audit logs | Verify access changes around release windows |
| Production deployment control | CD env gates | Deployment approval + deploy record | CD/Env controls | Verify approvals and target environment |
| Logging/monitoring | Observability | Alert rule inventory + alert events | Monitoring | Verify alerts exist and events are retained |
| Incident linkage | IR process | Incident ticket linked to alert/deploy ID | Ticketing | Verify incident timeline and closure |
Keeping evidence continuous
Automate collection and add periodic sampling (weekly or monthly) to detect gaps early. Treat drift as a control failure. If pipeline behavior, policies, or log retention changes, update the matrix immediately. Keep exception logs current. Every active exception should have scope, owner, expiry, and approval history, and expired exceptions must fail closed or require explicit re-approval.
Governance without slowing teams
Governance fails when it relies on manual policing. Engineers bypass controls when enforcement is inconsistent, exceptions are informal, or approvals block delivery without clear risk justification.
The goal is operational governance that is predictable for engineers and verifiable for auditors. That means two things: enforced defaults in CI/CD, and a controlled exception path that is faster than bypassing.
Exception workflow that auditors accept
Exceptions must be first-class objects with lifecycle, scope, and expiry. The workflow must be consistent across services and environments, and it must auto-generate evidence.
The minimum workflow is: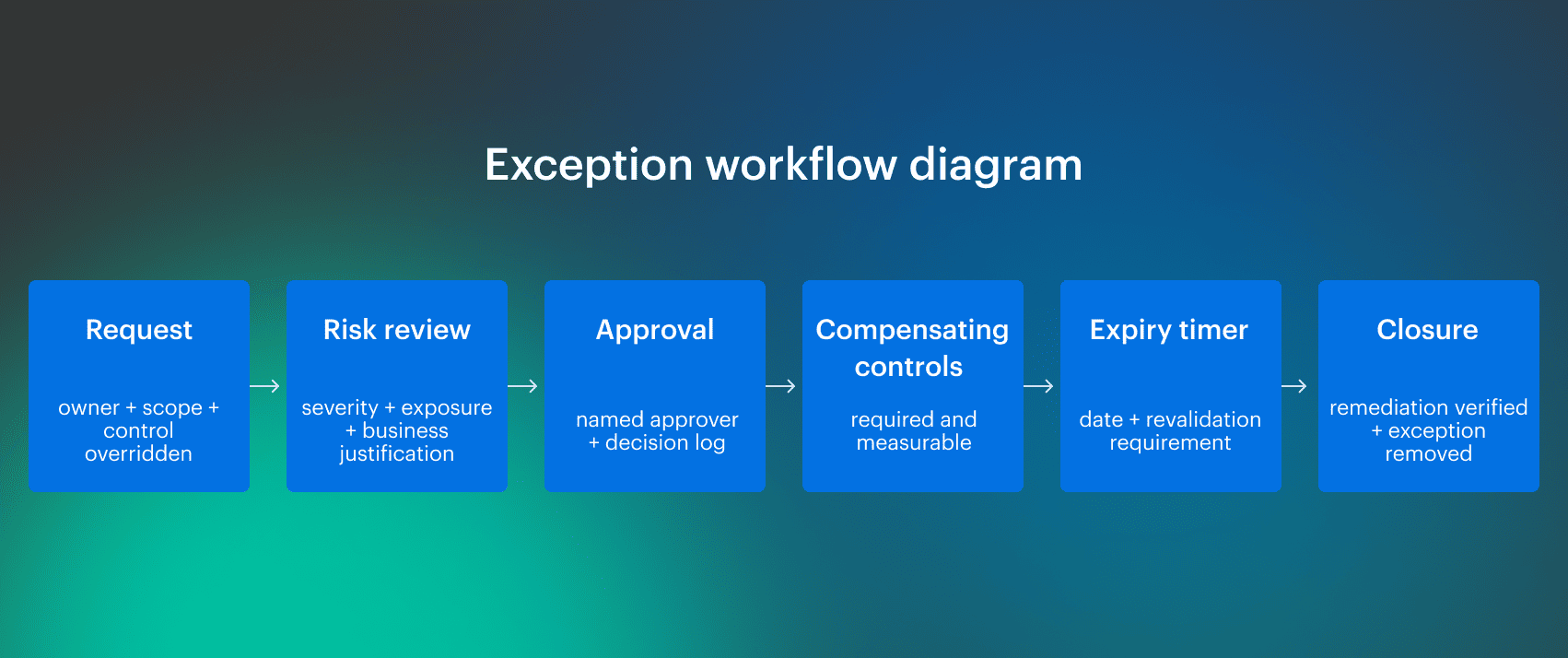 Automate the boring parts. Expiry reminders should fire automatically, and extending an exception should require revalidation. Every exception needs links to the evidence and the system record showing who reviewed it, who approved it, and where it applied.
Automate the boring parts. Expiry reminders should fire automatically, and extending an exception should require revalidation. Every exception needs links to the evidence and the system record showing who reviewed it, who approved it, and where it applied.
Anti-patterns (what breaks audits and gets bypassed):
- Permanent waivers with no expiry or closure criteria
- Justification in chat threads with no approver and no audit trail
- Exceptions that apply globally instead of scoped to service and environment
- Bypassing gates by disabling checks instead of issuing a time-bound exception
- Missing compensating controls or compensating controls with no verification signal
- Exceptions that aren't linked to remediation work and never close
Read also: 10 DevSecOps Best Practices That Actually Survive Production
Tools evaluation for audit-grade evidence
DevSecOps tools are parts of your delivery stack that produce or enforce audit-grade evidence. In practice, they include control gates in CI/CD, SAST/DAST/SCA, and secrets/IaC scanning, artifact signing/provenance, deployment controls, and identity/audit logging.
Live demo checklist for security teams
In a live demo, focus on three main proofs:
- Traceability chain in one view. Show a single change traced through PR, pipeline run, artifact metadata (digest/signature/attestation), and deployment record, using real IDs.
- Policy enforcement plus expiring exceptions. Show a gate firing on a high-severity condition, then show an exception workflow with owner, scope, and expiry, including what happens when the exception expires.
- Auditor-grade exports. Show exportable reports for deployment history, access changes, active/expired exceptions, and policy decisions bound to run IDs and artifact digests.
Use this checklist to scorecard vendors:
| Capability | Why it matters | How to test live | Red flags |
|---|---|---|---|
| End-to-end traceability | Proves change lineage | Pick one PR and trace to deploy record with IDs | Manual stitching or screenshots |
| Policy gating | Enforces controls at ship time | Trigger a failure and show the gate decision | Alert-only, no enforce mode |
| Expiring exceptions | Prevents permanent waivers | Create/inspect exception with expiry and history | No expiry, no owner, no history |
| Evidence integrity + retention | Evidence survives audit windows | Show retention and tamper-evidence model | Short retention, editable logs |
| Multi-environment coverage | Controls hold across envs | Show env gates and promotion history | “Prod is manual” gaps |
| Access change trace | Proves who could approve/deploy | Pull RBAC/IAM changes for a release window | Missing actor/time linkage |
| Audit-ready reporting | Reduces audit lead time | Export evidence with stable IDs | Summary-only exports |
Cloudaware as the evidence layer
When you run this as a DevSecOps program, the hardest part is keeping context consistent across tools. You need one view of ownership, deployment scope, approvals, drift, and audit evidence, without turning it into another dashboard war.
Cloudaware is built around that “context + verification” layer. It uses CMDB context to normalize findings across cloud accounts and environments, group them into fixable units, and support risk-based prioritization beyond technical severity.
- Audit-ready dashboards and exports with drill-down to evidence and exact check results
- Immutable trail where findings and state changes are recorded, not overwritten
- Failed checks become first-class “rule finding” objects with owner, SLA, evidence, and lifecycle
- One-click Jira/ServiceNow tickets from findings, with evidence attached
- Policies as files in Git with PR review, unit tests, and diff-before-rollout workflow
- CMDB-based evaluations and scoping (not ad hoc cloud API scrapes) plus time-boxed exceptions