






Budgets spike while sprints ship faster than finance can blink. Infra gets spun up for experiments and hot fixes; a week after Black Friday, nobody scales it down — and the bill proves it. Engineers tweak a value, redeploy, and move on; the meter runs.
Sound familiar?
This article stops treating it as FinOps vs DevOps. It’s a cloud reality: financial accountability must sit beside delivery speed, cost management, and optimization across teams.
What will we unpack?
• Where do cadences, Images, and ownership truly diverge?
• Which decisions belong in code review, runbooks, or budgets?
• What metrics keep both sides honest without slowing releases?
Then we’ll show how to make them work together — step by step — with field-tested moves from experts like Viktor Farcic, Richard Fennell, and Damian Monafo. For example, how to
- bake Cost SLOs into the Definition of Done so PRs catch spend drift before merge?
- wire CI/CD to flag cost deltas and auto-block risky PRs — without slowing deploys?
- Eng, FinOps, and Procurement plan RIs/SPs alongside sprint scope — and who signs off?
- turn rightsizing into tickets with owners and SLAs, not a dashboard no one opens?
We’ll use real examples — ephemeral envs that sleep, autoscaling that actually scales down, and forecast reviews you can influence. First, we draw a clean line between goals, rhythms, and responsibilities so the collaboration plan fits how your org ships software — today.
What’s the difference between FinOps vs DevOps? Here is a comparison table
When velocity and the bill collide, “who owns what?” gets fuzzy. That’s why you’re asking about the difference: you need clean lines between delivery and financial accountability so sprints don’t fight budgets, and cost work doesn’t stall releases. Who approves RI/SP buys? Who fixes tags? Which metrics matter to which team — and when?
Before we show how to make them work together, let’s get crisp on what’s different. Scan the DevOps vs. FinOps comparison to align goals, owners, Images, cadences, and KPIs — then map it to your org.
Comparison table of FinOps and DevOps teams
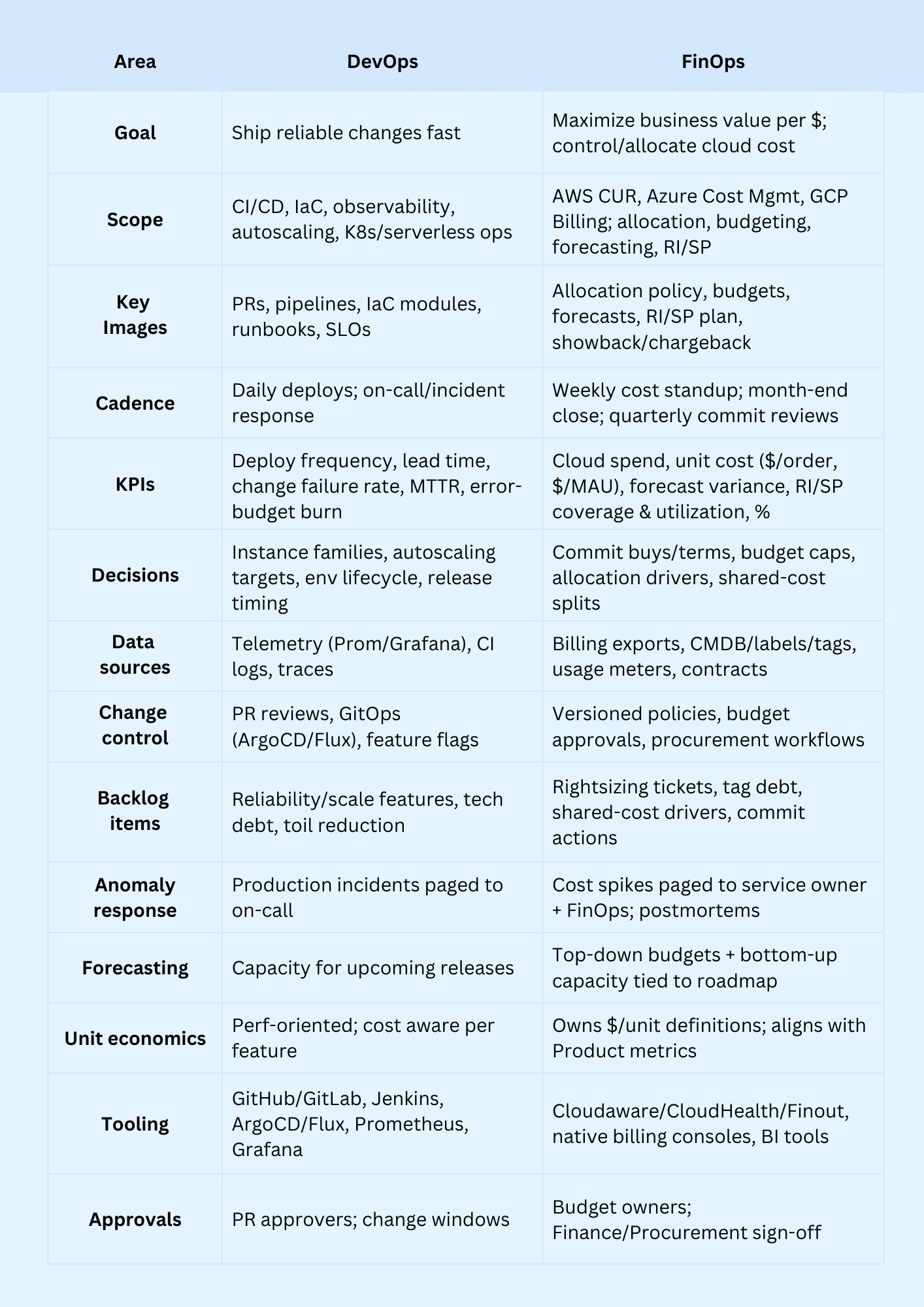
Primary focus areas and objectives
You’re in standup: deploys are humming, errors are down…then the financial team drops the cloud bill. Who owns the fix? DevOps says “keep shipping.” FinOps says “show me the drivers.” That’s why people ask the difference — so you can split responsibilities cleanly and stop the “who’s on first?” loop. Richard Fennell calls cloud FinOps “the bit that keeps you honest” about turning things off you spun up to experiment.
Viktor Farcic puts it bluntly: “Cheaper is just a side effect. You scale for no-downtime releases.”
DevOps optimizes flow and reliability; FinOps management maximizes business value per dollar through shared accountability.
Primary focus & objectives — FinOps vs DevOps

Keep this mental model as you read the comparison table: DevOps optimizes how you build and run; FinOps ensures you’re paying the right amount for the value you get.
Organizational scope
DevOps sits inside development + operations; FinOps spans finance, product, procurement, and engineering. It decides how costs are governed, where cost optimization lives, which practices stick, which tools plug in, and how it all connects back to software development.
Richard Fennell’s take: FinOps “keeps you honest” — turn off what you spun up when experimenting.
Viktor Farcic’s reminder: resilience comes first; “cheaper” is a side effect of scaling right.
And yes — FinOps runs across many personas and lines of business, so its cadence is more program-like than a sprint.
Organizational scope — DevOps vs. FinOps:
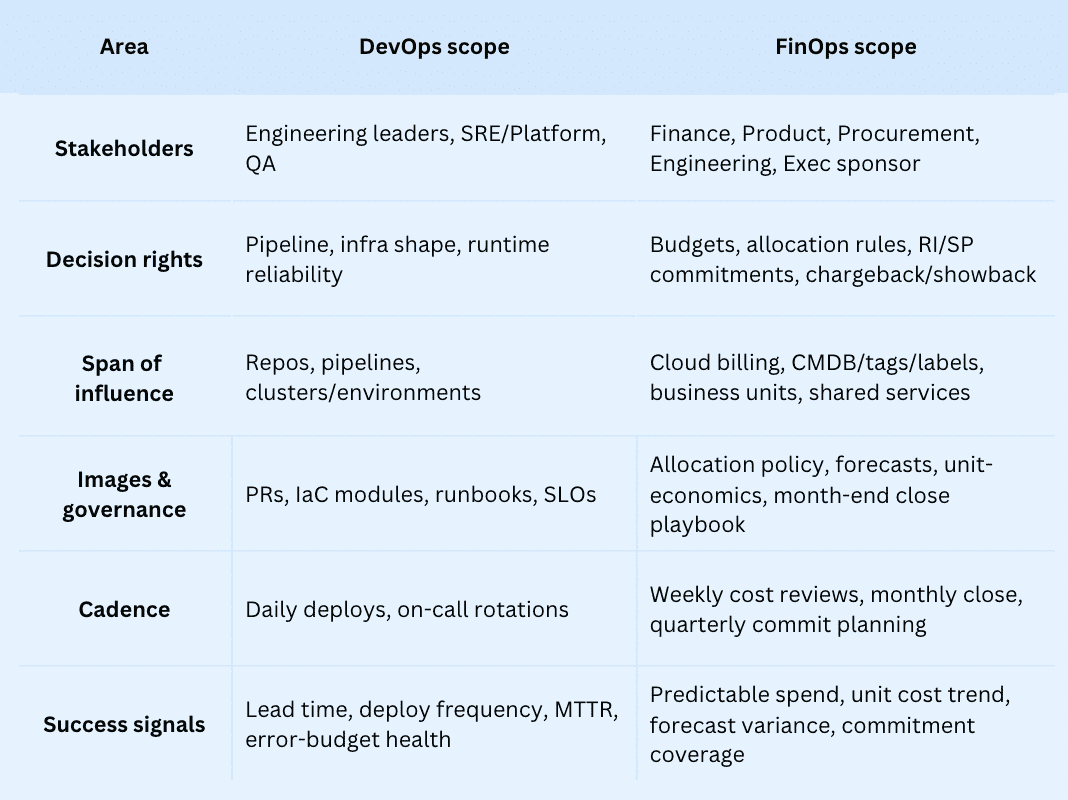
If you map scope this way, collaboration stops being fuzzy: DevOps optimizes flow and reliability; FinOps makes sure the money tracks the value — across the company.
Roles and responsibilities within FinOps and DevOps team
In the cloud, FinOps owns the financial guardrails and cost management; DevOps runs delivery and reliability, so work keeps moving with smart optimization across teams. Richard Fennell calls FinOps “the bit that keeps you honest” — turn off what you spun up to experiment. Viktor Farcic’s take: “Cheaper is a side effect; you scale for no-downtime releases.”
Roles & responsibilities — who does what
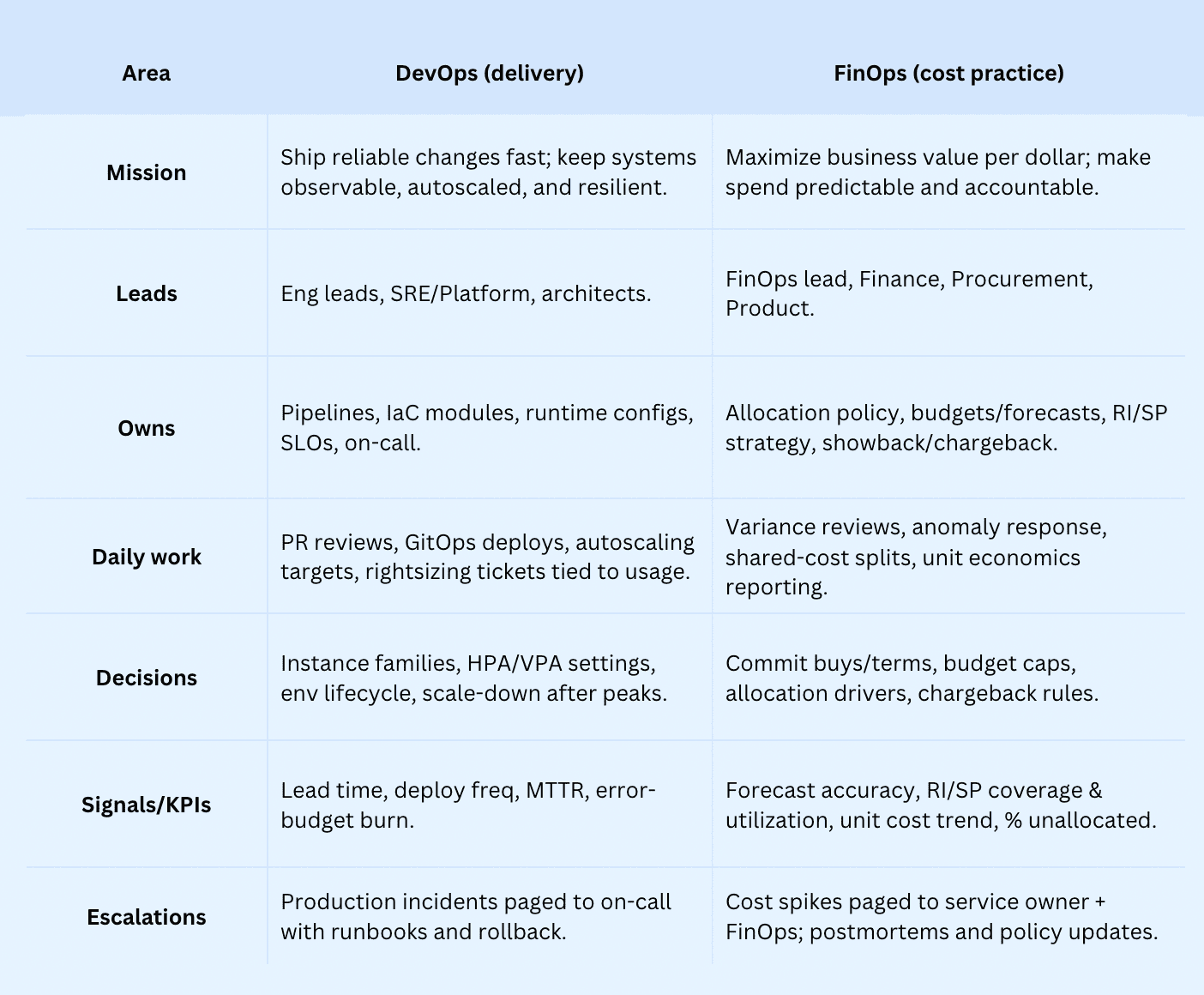
Two rules of thumb:
- DevOps chooses how to run it; FinOps decides what it should roughly cost and who pays.
- Surviving peak traffic isn’t the win unless someone verifies the downscale on Tuesday.
Core practices and processes
DevOps is about flow and reliability: ship, observe, fix fast. It runs on CI/CD, IaC, GitOps (pull-based deploys via Argo CD), solid secrets, autoscaling, and on-call playbooks. The work shows up as PRs, pipelines, runbooks, SLOs, and ephemeral envs that spin up for a PR and disappear after.
FinOps is a cross-org program: make spend predictable and accountable. It runs on allocation policy, tagging governance, showback/chargeback, anomaly response, budgeting/forecasting, RI/SP planning, and unit-economics reviews. Think month-end close, variance reviews, and quarterly commitment calls.
Two field notes from folks you’ll trust:
- Richard Fennell: FinOps “keeps you honest” — turn off what you spun up to experiment.
- Viktor Farcic: cheaper is a side effect; you scale for resilience — then remember to scale down after peak.
Core practices & processes — FinOps vs DevOps
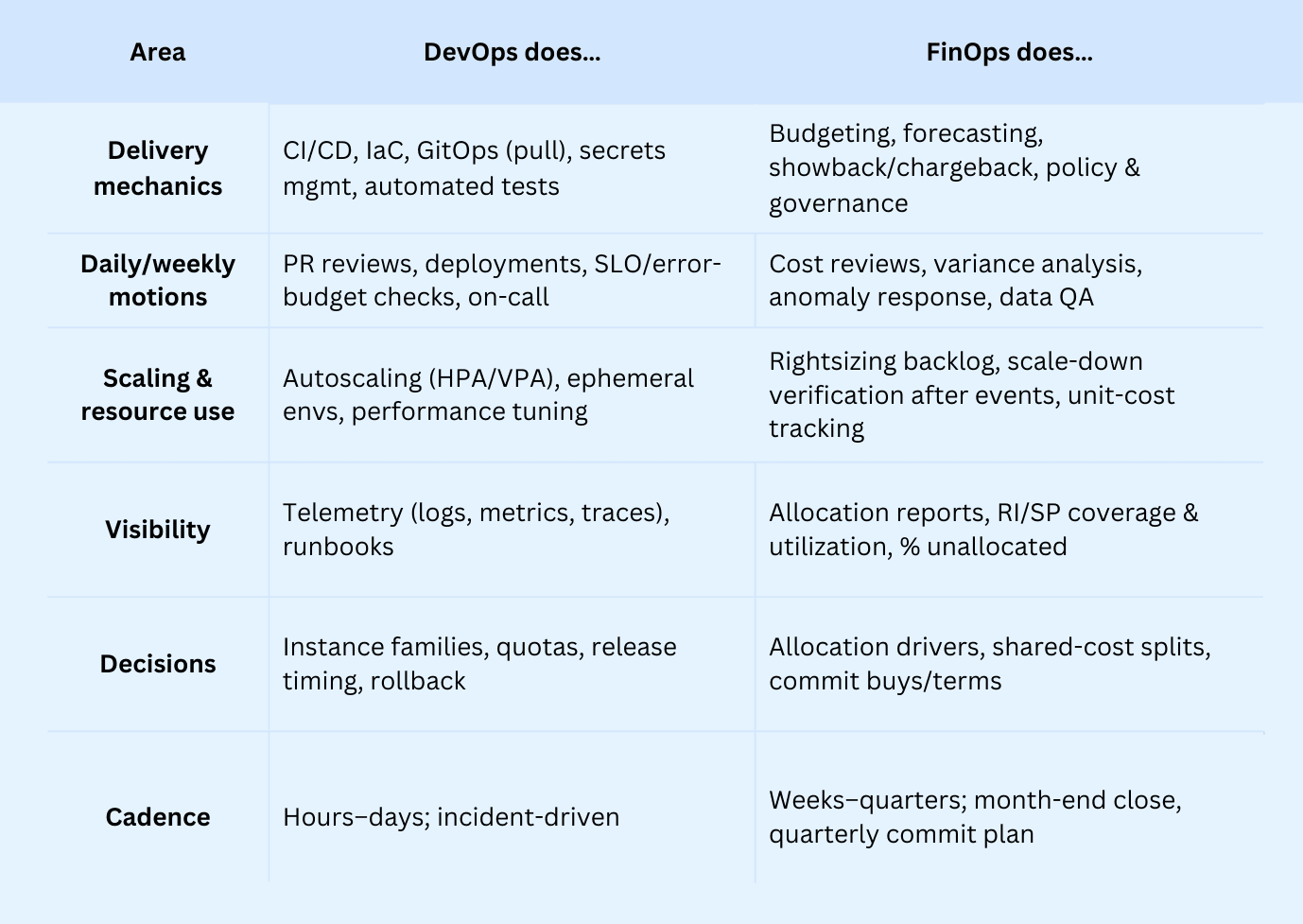
DevOps optimizes how you build and run; FinOps ensures you’re paying the right amount for the value you get — across the company. Bring them together and you go from “we survived Black Friday” to “we scaled back on Tuesday.”
Key metrics cloud FinOps and DevOps use
When deploys look green, but the bill spikes, you’re missing half the picture. DevOps proves you can ship fast and stay stable. Cloud FinOps proves the money tracks the value. Or as Richard Fennell puts it, FinOps “keeps you honest” about turning off what you spun up to experiment.
Viktor Farcic adds the guardrail: test in production with observability and automation — then scale back after Black Friday, not a week later.
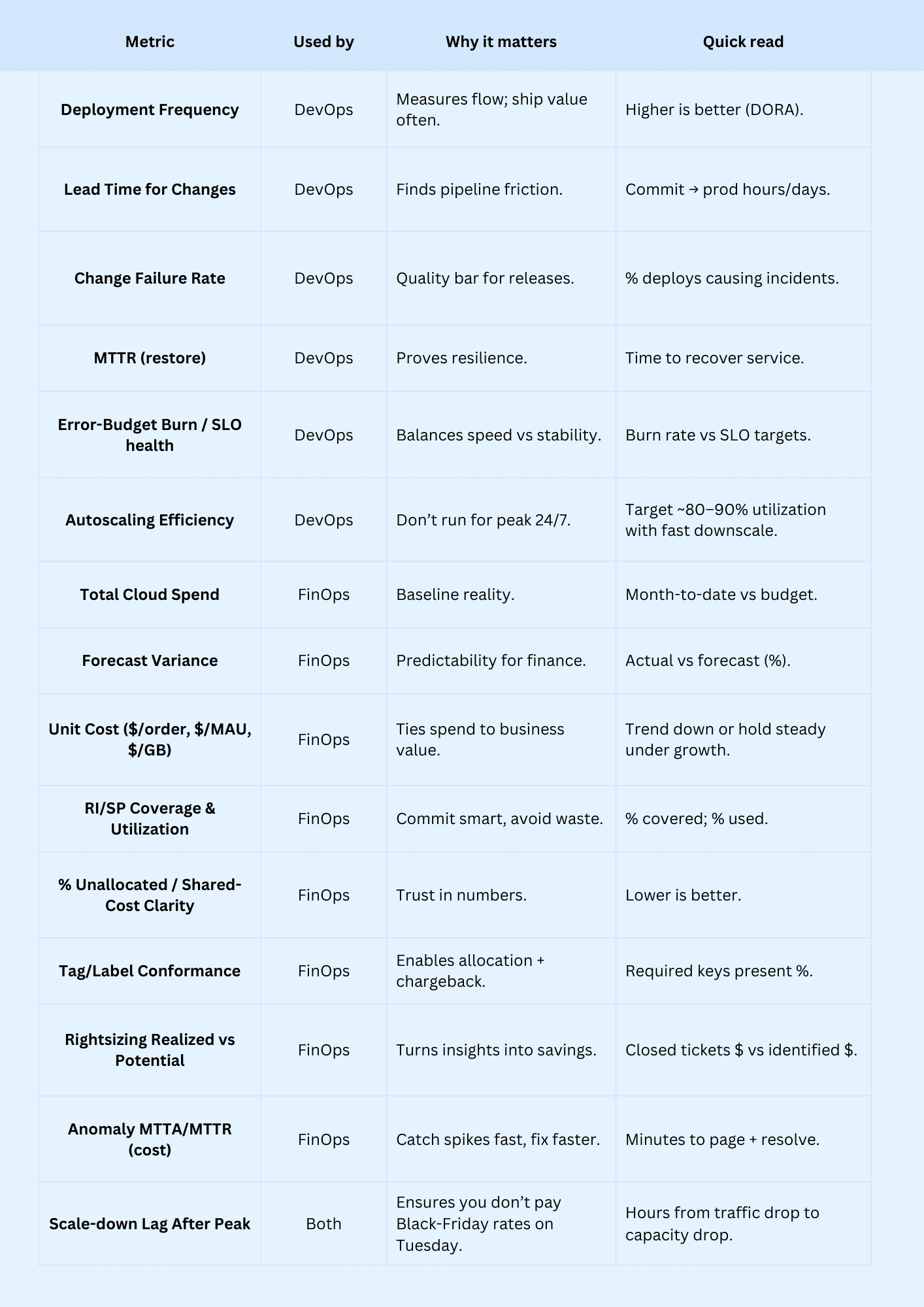
Use both sets together: DevOps proves how you deliver; FinOps proves you’re paying the right amount for that delivery — and that you stopped paying when the traffic did.
Tools and methodologies used
DevOps owns delivery mechanics; FinOps owns the money conversation. In the cloud, good management ties financial signals to engineering flow so cost optimization doesn’t slow teams. Viktor Farcic says it best: “Cheaper is a side effect — you scale for zero-downtime,” and Richard Fennell adds that FinOps “keeps you honest” about turning things off after you experiment.
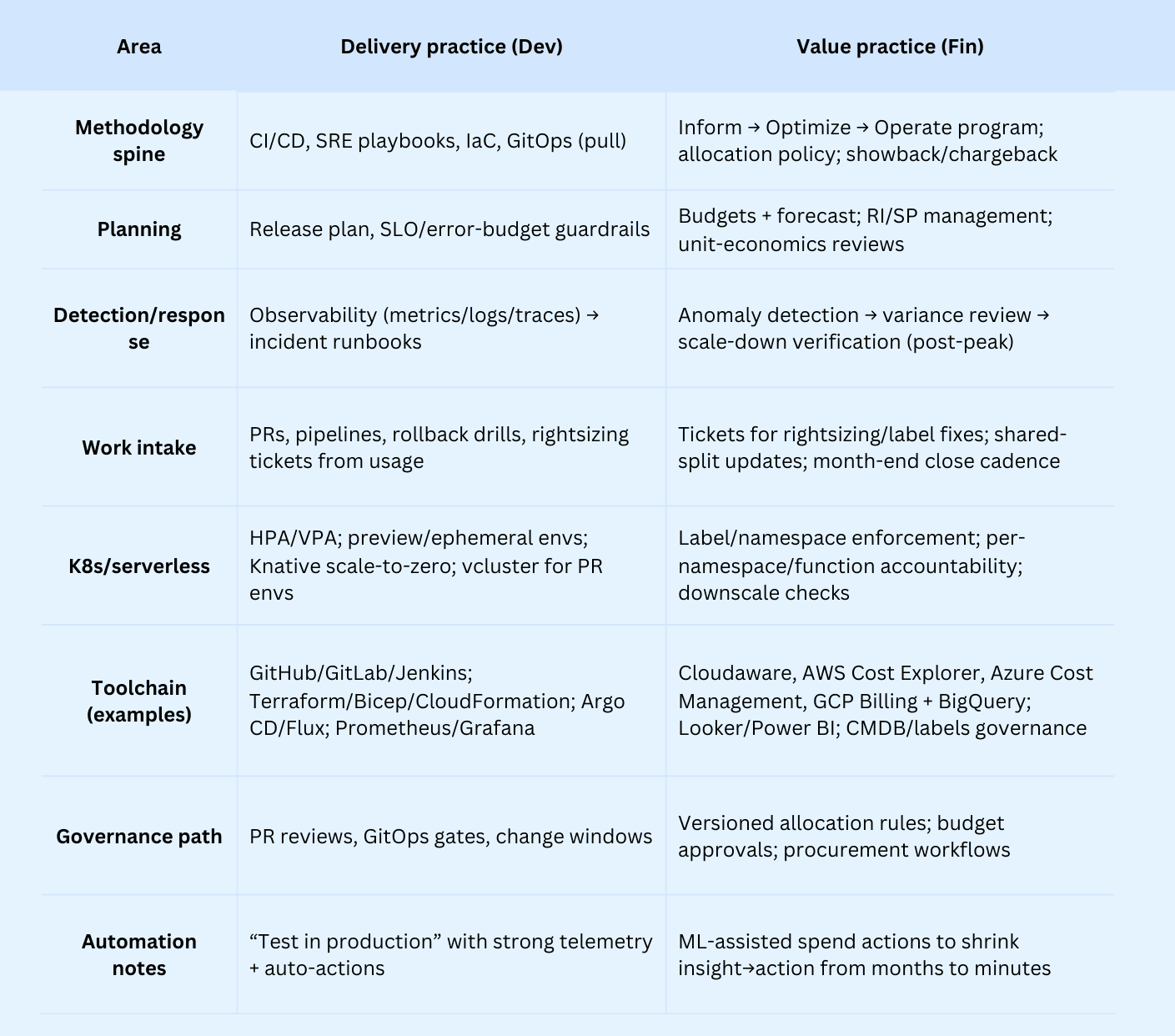
Field note: Surviving peak traffic isn’t the win — verifying the automatic downscale after peak is. Build that check into both runbooks and FinOps reviews.
Read also: What Is FinOps? Framework, Roles, Strategy & Tools in 2026
You don’t have to choose between DevOps vs FinOps team
You don’t need to pick sides. The real problem is silos: releases move, the bill climbs, and no one owns the “scale-down” after peak. Tag debt lingers. RI/SP buys happen without context from the roadmap.
That’s how budgets get burned and trust erodes across teams.
As Richard Fennell says, FinOps “keeps you honest” about switching off what you spun up to experiment; Viktor Farcic adds that “cheaper is a side effect” — resilience first, then verify the downscale.
Why align FinOps + DevOps
- One operating model, two lenses. Keep delivery speed and financial accountability in the same workflow: PRs carry cost impact; policies define who pays and why. This avoids handoffs and rework.
- Faster, smarter pre-merge decisions. Cost deltas on infra PRs plus guardrails stop regressions before they ship — no after-the-fact firefights.
- Predictable budgets without slowing releases. Tie RI/SP calls to sprint scope; review coverage/utilization alongside the release plan so Finance and Engineering make the same decision, once.
- Incident muscle for spend. Treat spikes like prod incidents: alert the owner, run the playbook, and confirm scale-down after events. The bill improves because operations improve.
- Better engineering outcomes. Right-sized resources and autoscaling discipline raise performance and lower cost — that’s resource optimization done right.
- Cleaner accountability. A versioned allocation policy engineers can influence builds trust; disagreements drop because the rules are documented and testable.
In cloud computing, treat FinOps as the value program inside your delivery engine — not a gate outside it. Focus on combining DevOps practices (CI/CD, IaC, GitOps) with your FinOps team playbooks (allocation, forecasting, anomaly response) to get durable management of cloud spend without sacrificing speed.
How to make FinOps & DevOps work together
When DevOps FinOps run side-by-side instead of together, you feel it: features ship, usage spikes, and no one owns the Tuesday scale-down in your cloud estate. Test stacks linger, tags drift, and surprise cost shows up — while your financial view and management dashboards can’t see which change triggered it. Optimization gets pushed after the bill instead of happening in-line with delivery.
Below are step-by-step, expert-backed practices to make these teams work together — drawn from leading industry voices and the Cloudaware team.
Make cost an NFR: ship Cost SLOs in your Definition of Done
In DevOps, every merge can nudge capacity and silently spike the bill unless you gate it pre-merge. Bring FinOps into the pull request with a simple $/unit guardrail engineers can influence.
In the cloud, elasticity is both superpower and trap, so estimate impact from IaC plans on every PR. Treat it as product governance, not management, so the rule lives next to the code.
You’ll get shared, real-time financial signals without slowing delivery. Define a Cost SLO per service, fail on breach, and page on drift like you would for latency. That rhythm turns reactive cleanups into steady optimization that sticks — and builds trust across teams.”
Result — what “good” looks like: On each PR, the pipeline reads the IaC plan, estimates the unit-price delta, posts a comment, and blocks if it breaks the threshold. After deploy, the dashboard tracks $/unit trend, alerts on sustained increases, waivers auto-expire, post-peak downscale is verified, and rightsizing tickets flow with owners and SLAs.
Here is how Cloudaware clients make it work:
- Model the target in CMDB. Add fields per service:
unit_metric__c,slo_target__c,warn_pct__c,block_pct__c,owner__c. - Enforce ownership tags. Require
application__c,environment__c,owner_email__c; run nightly conformance scans; auto-create Jira tasks for gaps via Flow. - Define controllable drivers. Version the allocation rulebook; document which levers a service can influence (instance family, storage class, concurrency).
- Wire CI to Cloudaware. Pipeline parses Terraform/Bicep/CFN plan, runs your estimator, computes $/unit delta, and posts to a
PullRequest__clinked to the service. A Flow comments on the PR and sets a block label if thresholds are exceeded or tags are missing. - Dashboards & alerts. Build a “Service Spend SLO” report (last-30-day unit price, variance, open waivers) and schedule a weekly digest to the service owner and finance partner; page on sustained breach.
- Production loop. Nightly job compares traffic drop vs resource drop; if downscale lag > 2h, open a rightsizing task with target size and acceptance criteria; auto-close when met.
- Cadence. Run a weekly review between the engineering lead and finance partner; monthly, tune thresholds and drivers; track KPIs: % PRs with unit-price comment, variance vs target, median downscale lag.
Wire CI/CD cost guardrails: block regressions pre-merge
Wire CI/CD guardrails, so expense creeps can’t hitch a ride to prod. Do the check where engineers live — pull requests — because that’s where software development decisions change spend.
Run your plan, estimate the impact, and fail to merge, so operations doesn’t discover it at 3 a.m. Make thresholds team-owned and testable; guardrails are engineering practices, not finance lectures. If a squad can’t influence a driver, don’t block — fix the policy so you only charge for costs they control.
Result — what “good” looks like:
Every plan in CI posts the projected $/unit change, blocks risky merges, tags exceptions with an expiry, and opens a follow-through ticket. Savings move from slides to backlog via development work items. Guardrails keep features shipping while driving continuous cost optimization. You get lightweight automation without swapping tools or slowing code reviews.
Here is how Cloudaware clients make it work:
- Define guardrails per service. Target $/unit with a warn at +5% and a block at +10%.
- Enforce ownership metadata. Require
application__c,environment__c,owner_email__c,cost_center; block on missing tags in CI and create tasks from Cloudaware scans. - Estimate pre-merge. Parse Terraform/Bicep/CFN plan, run a pricing estimator (e.g., Infracost), compute $/unit delta, and post the result as a PR comment.
- Post to Cloudaware. Send PR results to a custom object linked to the service; a Flow opens Jira tasks, applies a “block” label, or records a time-boxed waiver.
- Dashboards & alerts. Build a “Pre-merge Guardrails” report: last-30-day $/unit deltas, open waivers, blocked PRs; schedule a weekly digest to owners and finance partners.
Publish an allocation policy engineers respect
Publish an allocation policy engineers respect. It’s a living contract: who pays for what, and why — based on drivers people can actually influence. This is where FinOps earns trust.
In the cloud, elasticity can turn shared services into a black box; your policy makes them transparent. Treat it as product governance and management, versioned with a changelog, not a one-off PDF.
Translate platform usage into clear financial drivers with primary meters and pragmatic fallbacks. Charge only for cost drivers an owner can influence, then document the proxies when meters don’t exist yet.
That clarity turns insight into optimization that sticks.”
Result — what “good” looks like:
- The DevOps team designs with predictable price signals and fewer surprises.
- You move spend from arguments to improvements and lift business efficiency.
- Different groups share one playbook and one source of truth that aligns teams.
Here is how Cloudaware clients make it work:
- Model the policy. Create a versioned “Allocation Policy” object (Scope, Service/Shared, Primary Driver, Fallback Proxy, Meter Source, Weighting, EffectiveFrom/To, Owner, Changelog URL, ConfidenceScore).
- Bind drivers to services. On each Service CI, link to the policy; add
CanInfluence__cand the accountable owner; store target budgets for reference. - Enforce ownership metadata. Require
application__c,environment__c,owner_email__c, and a finance code; run daily conformance scans; auto-open Jira tasks via Flow; escalate if unresolved. - Plumb the meters. Ingest AWS CUR, Azure exports, and GCP Billing; join to CMDB labels; compute allocations nightly; publish showback dashboards and a monthly reconciliation report.
- Surface pre-merge impact. CI parses Terraform/Bicep/CFN plans, computes the driver deltas, and comments “allocation impact” on the PR; block when the owner or tags are unknown.
- Add an appeal path. Create
AllocationDispute__cwith SLA, reason, proposed fix, and evidence; route to the allocation owner; include a “Recompute Allocation” action that triggers a Flow. - Tame shared services. Define categories (egress, gateways, logging). Assign fair drivers (requests, vCPU-hours, GB-months). If a meter is missing, set a proxy and open a follow-up task to add telemetry.
- Track the health metrics. Target <5% unallocated, >90% spend covered by primary drivers, <10 business days to close disputes, and a weekly digest of policy changes to service owners.
Here is an example of how cost allocation report looks like:
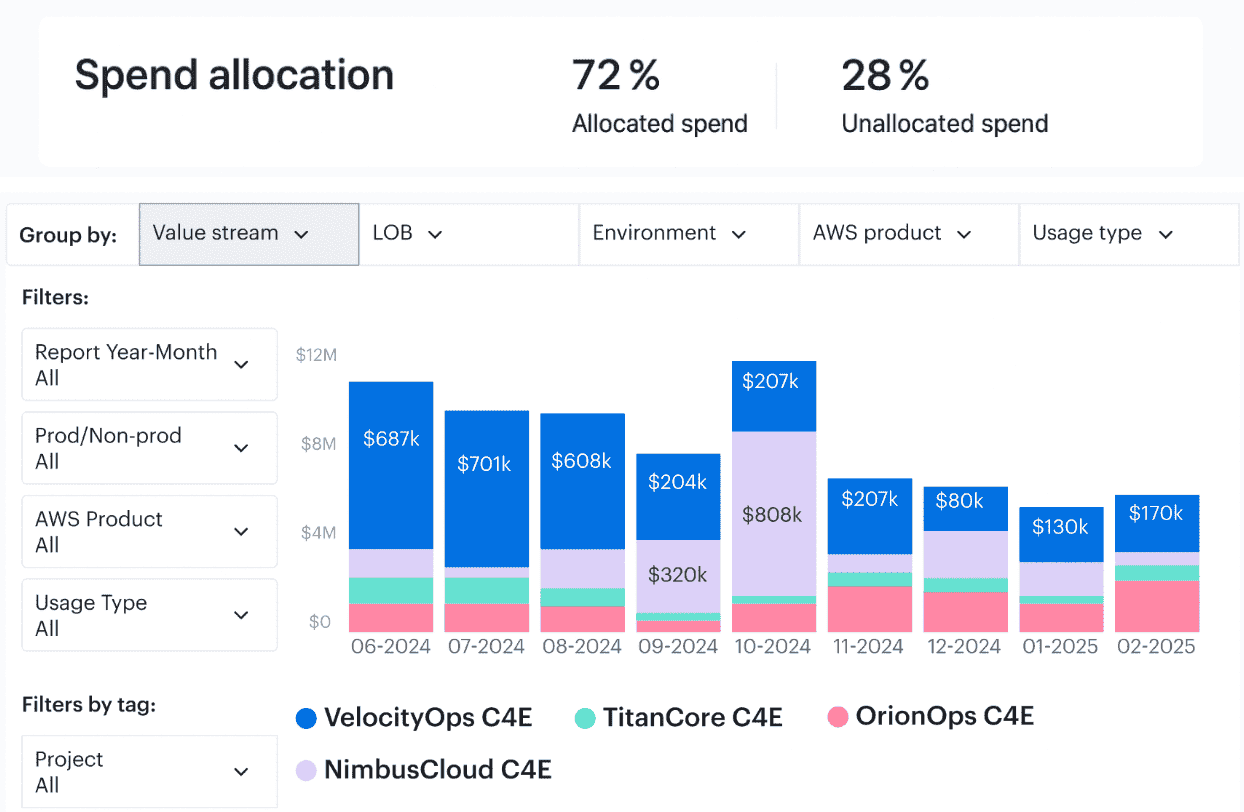
Cloudaware cost allocation dashboard element
Read also: 7 Best Cost Allocation Software 2025: Tools, Features & Pricing
Run rightsizing as backlog work, not dashboard watching
In FinOps, savings stick only when they live as tickets — with an owner, SLA, and a clear definition of done. Hook the recs into DevOps rituals: same PRs, same sprints, same reviews. Why? In the cloud, capacity drifts the moment a test stack lingers or autoscaling forgets to scale back.
Run it like product management: one backlog, one DRI, one DoD. Need an exception? Drop a one-liner with the financial reason and an expiry so no one does Slack archaeology later. Put a guardrail on cost per unit: if a PR blows past the cap, the merge is blocked — no debate.
Each recommendation is a mini change: target size, evidence from metrics, expected optimization, rollback plan. Do this and teams stop arguing about “should we” and start closing tickets.
Here is how Cloudaware clients make it work:
- Model the policy in CMDB. On each service CI, add fields for
rightsizing_target__c(shape),utilization_floor__c,warn_pct__c,block_pct__c,owner__c, andsla_days__c. - Enforce ownership metadata. Require
application__c,environment__c, andowner_email__c; run nightly conformance scans; auto-open Jira tasks via Flow for gaps. - Generate data-driven recs. Ingest metrics (CPU, memory, IOPS, network) and billing lines; compute candidate shapes using observed p95 utilization and burst history; attach graphs to each suggestion.
- Create tickets automatically. A scheduled job writes
RightsizingRecommendation__crecords and opens work items with: proposed shape, before/after unit-price, savings estimate, risk notes, and acceptance criteria (“p95 < 80% for 7 days”). - Wire PR checks. CI parses Terraform/Bicep/CFN plans, computes the unit-price delta, posts a PR comment, and applies a “block” label when thresholds are exceeded or tags are missing.
- Verify post-peak hygiene. A nightly rule compares request rate vs resource allocation; if capacity doesn’t drop within 120 minutes of traffic falling, open a task and page the owner.
- Set the cadence. Weekly review: backlog throughput, realized savings, and waived items approaching expiry; monthly tune thresholds and target shapes from production evidence.
- Track KPIs. Ticket SLA hit rate, realized-vs-identified savings, median downscale lag, percentage of services with current sizing, and PRs auto-blocked for sizing regressions.
Treat cost anomalies like incidents
Treat cost spikes like production incidents — same urgency, same ownership, same postmortem. In FinOps, that turns spend drift into a first-class signal instead of a month-end surprise. For DevOps, it’s the reliability muscle you already have, pointed at money.
When leadership sees a clean financial narrative tied to services, management stops guessing, teams move faster with fewer reversions, and your cloud infrastructure stops leaking dollars between deploys.
Make the process routine and predictability goes up while chaos goes down. That’s real optimization, not theater.
Here is how Cloudaware clients make it work:
-
Define anomaly classes. Set Sev1/Sev2 thresholds from baselines (e.g., 3σ over 60 minutes or >10% vs forecast) per service.
-
Map ownership. Link each service CI to an owner and escalation path; require
application__c,environment__c,owner_email__c,cost_center. -
Wire alerts. Create rules that raise an Incident when thresholds breach; route to Slack/Email/Pager with the CI, suspected driver, and rollback hint.
-
Attach runbooks. Store per-service steps (kill test stacks, reduce concurrency, scale down autoscaling groups, revert IaC change) and link them to the Incident layout.
-
Open follow-through. Force.com flow creates a Jira ticket for any temporary fix with an expiry, DRI, and verification task.
21-it-inventory-management-software-1-see-demo-with-anna
Marry commitment planning with sprint planning
Inside DevOps, price signals belong in the same conversation where scope gets locked. FinOps turns those signals into predictable runway instead of an end-of-quarter scramble. In the cloud, a single feature can bend your usage curve overnight, which makes timing the whole game.
Better management follows when buy decisions sit beside the release plan rather than outside it.
The result is real financial predictability because commitments match the next iterations, not stale averages. Reviewing buy/hold/convert before code lands prevents surprise cost later. Coverage sized to actual demand upgrades optimization quality beyond gut feel. Different teams row in one rhythm instead of chasing each other after the bill.
That, in a sentence, is cloud FinOps done right.
Here is a flow companies follow to make it real within Cloudaware:
- Stand up a commitment inventory in the Cloudaware CMDB and link items to services; use the built-in Reserved Instances Planner plus Force.com dashboards for coverage/utilization views.
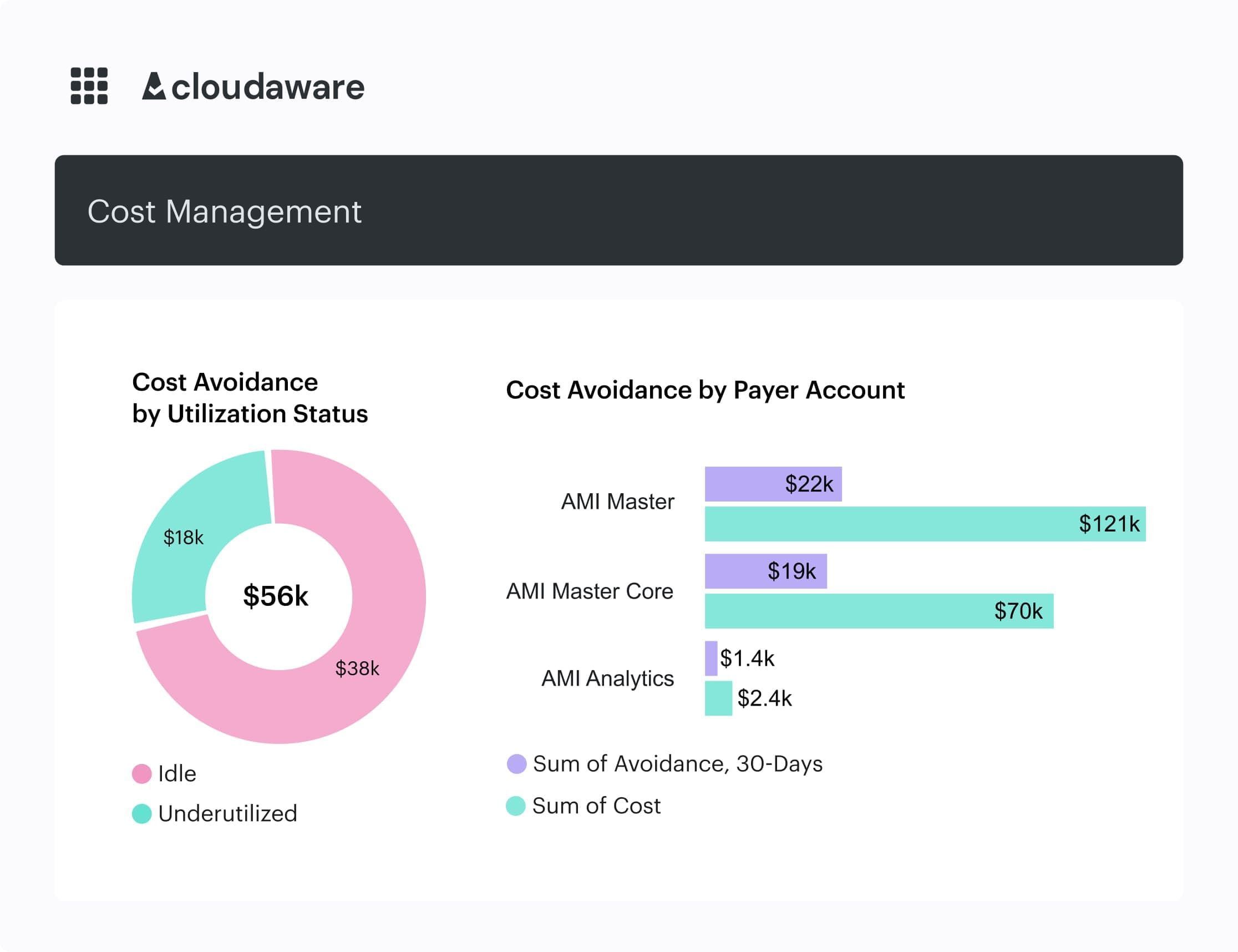
Cloudaware cost utilization report. Schedule demo to see how it works live.
- Ingest AWS CUR, Azure Enterprise billing, and GCP billing so coverage and utilization calculate per service and roll up cross-cloud.
- Use the report & dashboard builder to pair 90-day projections with release calendars; schedule summaries to stakeholders via email.
- Monitor reservation objects (AWS RI/SP, Azure Reservations) with the supported Cloudaware objects for coverage and utilization to validate decisions post-sprint.
- Enable budget alerts and forecasting so expiring or under-utilized positions surface before sprint review and proposed changes show impact.
Expose K8s & serverless costs where work happens
You ship a tiny tweak, pods swell, a fan-out doubles — and the bill tells the story before anyone does.
In DevOps, that signal has to show up exactly where you work — the repo, the PR, the dashboard you already watch. FinOps belongs in the same lane, turning raw meters into per-namespace and per-function guardrails you can act on.
Because in the cloud, nodes and functions shape-shift by the hour and yesterday’s assumptions go stale by lunch.
Pulling the money view into the platform gives management a shared truth instead of a month-end autopsy.
You want financial signals tied to a clear owner, not a hazy account total. When engineers see cost next to logs and deploys, they respond in minutes, not months.
That’s where real optimization happens — right at the commit, not after the invoice. And yes, it calms the room because teams stop arguing about who owns the number.
Here is a flow companies follow to make it real within Cloudaware:
- Connect billing exports from AWS (CUR), Azure (EA), and GCP; that data is first-class in the platform and updates daily, so your views stay current.
- Push cluster and function metadata into the CMDB via the open API, then join it to billing lines using tags/labels to attribute spend to namespaces and functions. (Yes, the API and analytics builder are built in.)
- Define an allocation policy by service line so shared resources don’t become a black box; use documented drivers and fallbacks to keep attributions predictable.
- Build per-namespace and per-function dashboards with the Force.com report builder; schedule PDF or Excel digests, so owners get a weekly “here’s the number” snapshot without chasing it.
- Turn on budget alerts against those dimensions so unexpected spikes page the right owner instead of landing as a month-end surprise.
- Use the waste policies to catch obvious leakage (idling disks, overprovisioned instances) that props up cluster bills; these policies are customizable and come out of the box.
This setup makes your K8s and serverless spend visible in the same places people plan, code, and review — so the signal turns into action, not archaeology.
Build a forecast you can influence (top-down + bottom-up)
It’s a living view of spend you can actually move with specific engineering actions, not a spreadsheet prediction.
In FinOps, that means the number updates the moment assumptions, pricing, or coverage change. For DevOps, it means the roadmap and infra plans are wired into the math before code lands.
In a cloud estate, one feature flag can bend the usage curve in a day. Leadership needs a forecast that’s part of management rhythm, not a quarter-end autopsy.
Here is an example of how it may look like:
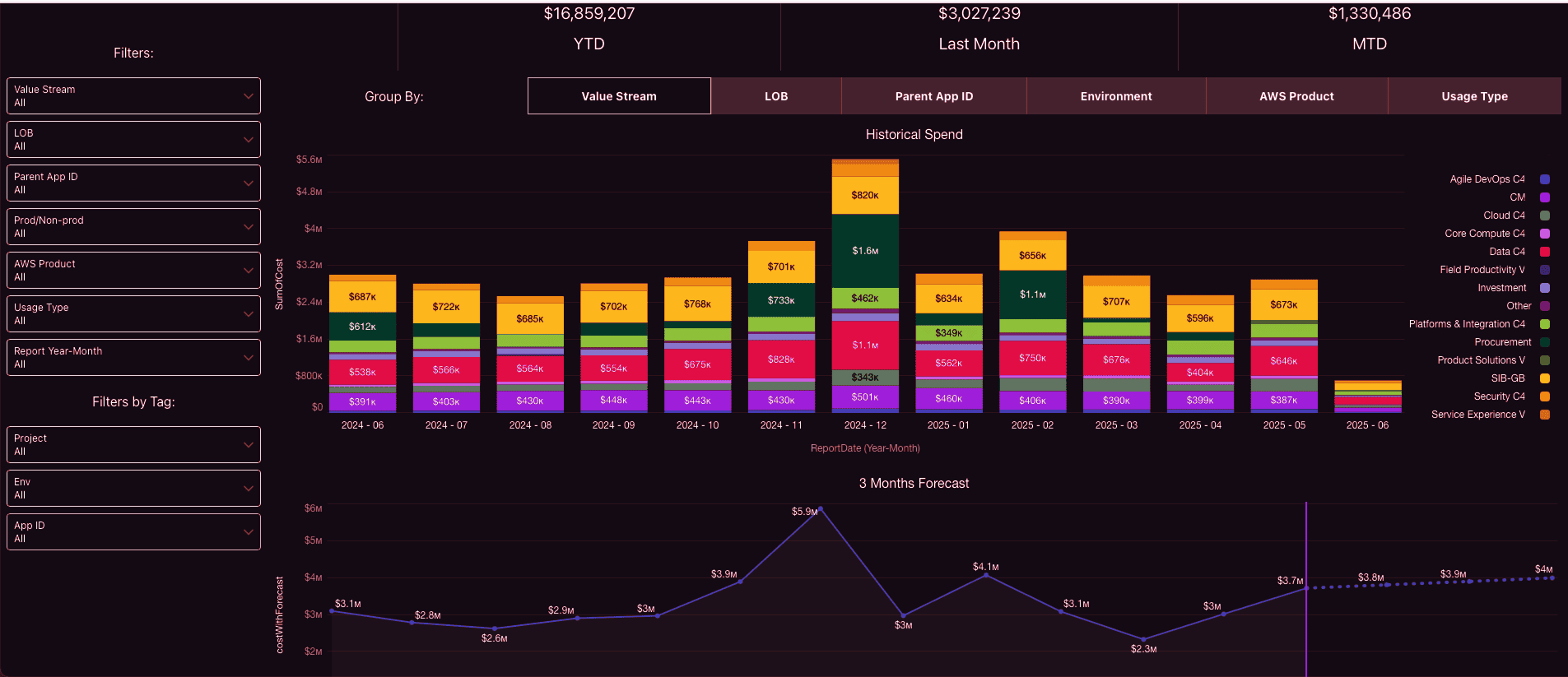
An element of the Cloudaware forecasting report. Schedule demo to see how it works live.
You want a financial signal tied to services, owners, and levers you control. When the cost line drifts, you already know which knob to turn and what it will save.
That’s how optimization becomes proactive instead of reactive. And it keeps teams aligned because the same forecast sits in planning, in CI, and in review.
Here is a flow companies follow to make it real within Cloudaware:
- Model the scopes. In the CMDB, add a “Forecast Scope” per service or product with fields for a top-down target, guardrails, and linked owners.
- Connect spend data. Ingest AWS CUR, Azure Cost Management exports, and GCP Billing; join to services via tags/labels and apply your shared-cost drivers.
- Bring bottom-up inputs. Import the release calendar and capacity plans (CSV/API) as a related object; capture planned deltas like new instance families, autoscaling targets, or storage class changes.
- Project scenarios. Use reports to compute 30/60/90-day projections under “as-is” and “proposed” assumptions, including current commitment coverage and a what-if view for new positions.
- Alert on variance. When actuals breach guardrails, trigger a Flow that opens a Jira task, assigns the owner, and pings them via Slack/Email with the suspected driver and a due date.
- Close the loop. At month-end, reconcile actual vs forecast, tag root causes (deploy/config/scale/price), and automatically tune the driver set for the next cycle.
Keep governance lightweight, GitOps-friendly
This is where FinOps stops being a month-end audit and starts being a design rule tied to code. For DevOps, it keeps the path to prod fast and traceable because the “gate” is just another CI check.
Leaders finally get management clarity because every policy change is versioned next to a service, not buried in a meeting note. Finance gets a financial view right beside the diff, so trade-offs are explicit — no archaeology later.
Surprise cost drops when guardrails sit where work happens, and approvals ride the same PR that ships. The win is durable optimization: rules improve through reviews and merge like any other artifact. Different teams stop debating “who said yes” and start iterating on the policy itself.
Over time, your cloud cost story becomes a tidy audit trail, not a scavenger hunt.
Here is a flow companies follow to make it real within Cloudaware:
-
Model policies as data. In the CMDB, store a versioned “Cost/Change Policy” record per service (scope, thresholds, approvers, effective dates). Use the Force.com report & dashboard builder to surface policy status and trends.
-
Wire in billing + allocation. Ingest AWS CUR, Azure EA, and GCP billing; attribute spend by service line so policy effects show up per owner, not just account totals.
-
Notify with the tools Cloudaware ships. Use Budget Alerts and scheduled email/PDF reports so policy breaches and exceptions reach the right people without extra portals. (Chatter/email are supported.)
-
Bring PR context into Cloudaware. Post CI metadata (commit, PR, tag state, projected impact) to a custom object via the Open API so approvals/waivers are recorded against the service.
-
Track coverage & risk. Add dashboards for “guardrails passed/failed,” “exceptions open/expired,” and “effective policy coverage” across applications. Pair with RI/SP coverage & utilization views for a single governance read.
21-it-inventory-management-software-1-see-demo-with-anna
Add “cost blast radius” reviews for risky changes
It matters because one flag can triple egress or storage overnight, and you only notice when month-end hits.
In software development, that risk hides inside harmless-looking PRs. On the operations side, it shows up as a hot cluster and a cold sweat at 2 a.m. For leaders, the question is simple: what will these costs look like if traffic triples in 48 hours and no one scales down?
Model the blast radius, and you can plan quotas, limits, and rollbacks without throttling delivery.
The point isn’t to stop change; it’s to make room for cost optimization without hand-wringing. Turn it into shared practices, so everyone speaks the same language when risk shows up. Keep it where work happens, and use the same tools you already trust.
It keeps development bold and accountable at the same time.
Here is a flow companies follow to make it real within Cloudaware:
- Capture risky changes as data. Add a custom “Change Risk” record in the CMDB linked to the service CI (fields: change type, region, risk level, predicted $/day and $/unit delta, rollback plan, verification metric, effective dates).
- Feed PR context automatically. From CI, post the PR ID, commit, IaC plan summary, and any price-estimation output to that record via the Open API, so decisions are tied to the exact change.
- Run scenarios where owners live. Use the report/analytics builder to compare “as-is / best / worst” 30–90-day impacts, factoring current commitment coverage and allocation rules, then surface it on the service dashboard.
- Decide and document. Record a buy/hold/limit decision, the approver, and a time-boxed waiver (if any) using a Force.com Flow; notify via email/Chatter so there’s an auditable trail.
- Verify after rollout. Schedule a job to check post-event spend and inventory against the predicted drop; if variance persists (e.g., >10% after 2 hours), auto-create a follow-through task for the service owner.
- Track the health like a product. Build a dashboard for “risky changes reviewed,” “predicted vs actual impact,” “time-to-downscale,” and “open waivers nearing expiry”; include a weekly digest to stakeholders.
Check how Cloudaware FinOps solution automates this process
If your FinOps and DevOps workflows live in different tools and meetings, Cloudaware pulls them into one system of record. We ingest your billing once a day, join it to the services and environments you already track in the CMDB, and put allocation, forecasts, and savings signals where owners can actually use them.
The result: a shared truth for engineering speed and financial accountability — with less swivel-chair work.
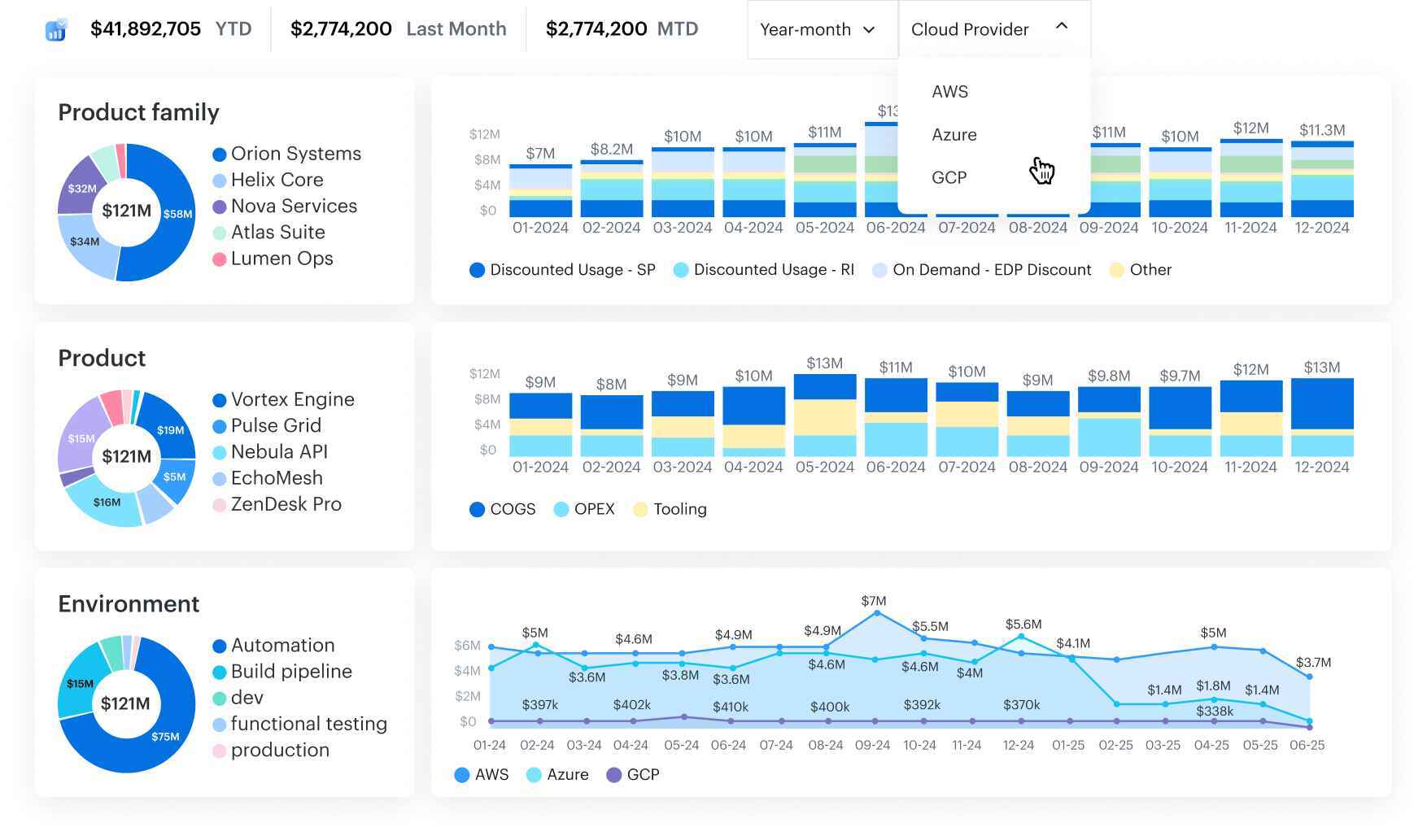
Clouds supported: AWS (DBR/CUR + Cost Explorer), Azure (Enterprise Agreement), Google Cloud (Billing), Oracle, Alibaba. Cross-cloud dashboards come standard.
CMDB-enriched views: Costs are attributed by service line using tags/labels, then rolled up to apps, envs, and owners — so showback/chargeback reflects how you run. (GCP note: per-instance views require instance-level tags.)
Most popular features:
- Cross-cloud cost analytics with blended/unblended rate analysis and daily updates.
- Allocation & chargeback by service line tied to CMDB owners for predictable accountability.
- Waste detection (idle/unused) from a large policy library — customizable in the Compliance Engine.
- Rightsizing analysis on interactive dashboards alongside RI/SP coverage/utilization.
- Forecasting & budget alerts so variances surface before month-end.
- Reserved Instances Planner + objects for AWS/Azure reservations to improve coverage/utilization.
- Tagging visibility across providers to raise attribution quality and reduce “unallocated.”
- Reports & dashboards (Force.com builder) with scheduled email/PDF digests for stakeholders.
FinOps gets timely data and controllable drivers. Engineering gets service-level views baked into how they work. Finance sees forecasts next to coverage/utilization, not in a separate spreadsheet. Net: fewer surprises, faster decisions, clearer ownership.