






You ever open your CMDB and immediately feel like you’ve stumbled into the lost and found bin of your entire org’s tech history? Phantom EC2s from a sprint no one remembers. A GKE cluster labeled do_not_touch_plz. Ten different copies of the same SaaS license, all active, none assigned. And somehow, nobody knows who owns any of it. Classic.
That, right there, is the fallout from skipping proper IT asset management. Or treating it like just a line item on someone else’s checklist.
In this article, I’m walking you through what asset management in IT actually is. Not the textbook fluff — the real deal. How does asset management work when you’ve got dynamic infra, ephemeral workloads, and three clouds fighting for your attention.
We’ll break down discovery that doesn’t lie. Lifecycle rules that stick. Asset ownership that survives team turnover. And naming conventions that won’t make you cry during an outage.
Grab your ☕ — let’s untangle the mess.
What is asset management in IT?
It’s your way of keeping tabs on everything — cloud resources, on-prem hardware, software, SaaS tools, license keys, rogue S3 buckets, even that forgotten prod-backup-v2 server still quietly racking up costs.
From the moment an asset gets provisioned to the day you retire it with honors, it’s all about knowing what exists. And why it’s there. And who’s responsible. And what business services or dependencies it’s tied to.
The real-deal process usually looks like this:
- Asset discovery – auto-detected via agents, cloud APIs, IaC, or scanners
- CI classification – because untitled-instance-243 doesn’t help anyone
- Ownership assignment – no more hot-potato ops responsibility
- Lifecycle tracking – onboarding, active use, maintenance, offboarding
- Security & compliance mapping – link assets to policies, audits, controls
- Cost attribution – so you know which tag blew up the cloud bill
- Change impact visibility – “If this goes down, what else breaks?”
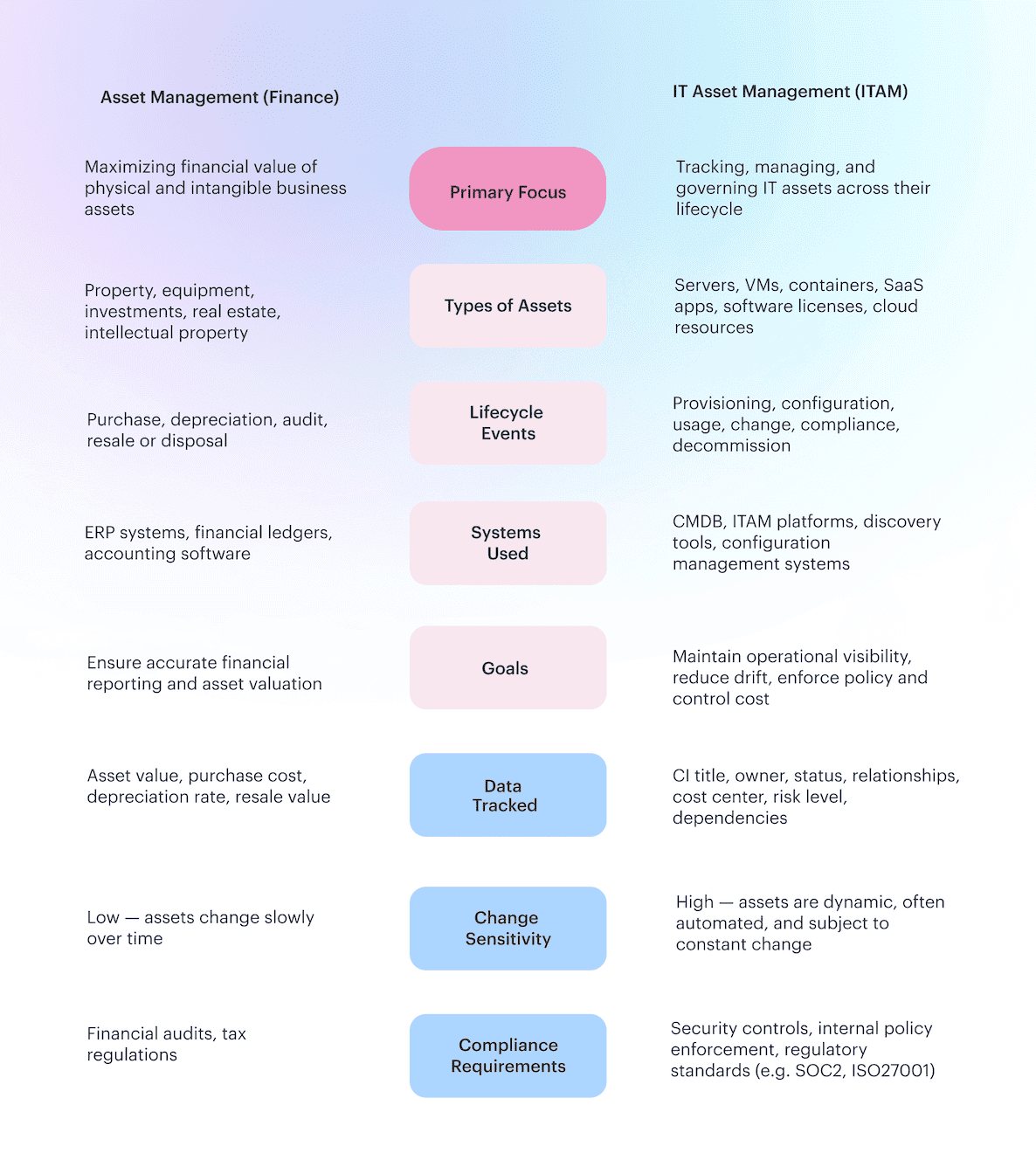
And nope — this isn’t financial asset management. We’re not managing retirement funds or tracking depreciation for office chairs. We’re managing live, moving, constantly-changing IT resources. The kind that can take down production services if someone touches the wrong thing without context.
One wrong click on an “unused” security group, and boom — your internal APIs go dark in five regions. Ask me how I know.
Asset management in IT is operational fire prevention. It’s deeply tied to your CMDB, where assets become CIs with relationships, owners, lifecycle stages, and risk flags. It’s the backbone of your change management process. Because you can’t evaluate impact if you don’t know what a CI connects to. Or who’s even responsible for that data flow or business service.
It also drives policy enforcement across clouds and teams. Wanna block public S3 buckets? Cool. Asset management needs to tell you which ones exist, where they live, and why they’re there.
Need to kill zombie workloads before the next budget meeting? ITAM is your flashlight in the fog of complex cloud setups. It’s real-time. It’s always on.
This isn’t accounting. It’s keeping your stack alive.
Now that we’ve named the dragon and poked at its ugliest fire-breathing parts, it’s time to talk about how to actually tame it.
Because asset management isn’t just a definition, but a living, breathing practice. It works in the middle of hybrid chaos, constant drift, tagging drama, and surprise software resources you definitely didn’t approve — but now somehow own.
7 Processes inside asset management
Let’s walk through what this actually looks like — a full-blown CMDB implementation inside a real hybrid cloud org. They’re running AWS, Azure, and GCP. IaC is Terraform. Identity sync runs through Okta. Tickets live in Jira. And Cloudaware sits in the middle, stitching it all together.
Here’s how Cloudaware runs asset management in real-world environments, with examples you’ll probably recognize from your own chaos 👇
Things were messy.
Three cloud providers. Terraform flying changes through CI. Infra popping up faster than it could be tagged. One environment had ten different cost center formats. Another had a Redis node labeled pls-dont-delete-v2. Classic.
Everyone had a CMDB. Nobody trusted it.
That’s when they brought in Cloudaware.
The goal? One place to see every asset. Not just what existed, but what it cost, who owned it, how it was behaving, and what would break if someone touched it.
Let’s walk through how they cleaned up the mess — with real ITAM muscle behind it.
🔎 Asset Discovery
It started with a deploy. A full analytics stack — web frontends in AWS, BigQuery ETL in GCP, logging in Azure. IaC-powered and Terraform-driven, pushed through the platform team’s CI pipeline.
The moment that terraform apply hit GitHub, Cloudaware’s IaC sync locked in. Combined with native cloud APIs, it began pulling in every deployed resource — agentless and real-time.
Assets showed up in the CMDB with full data context:
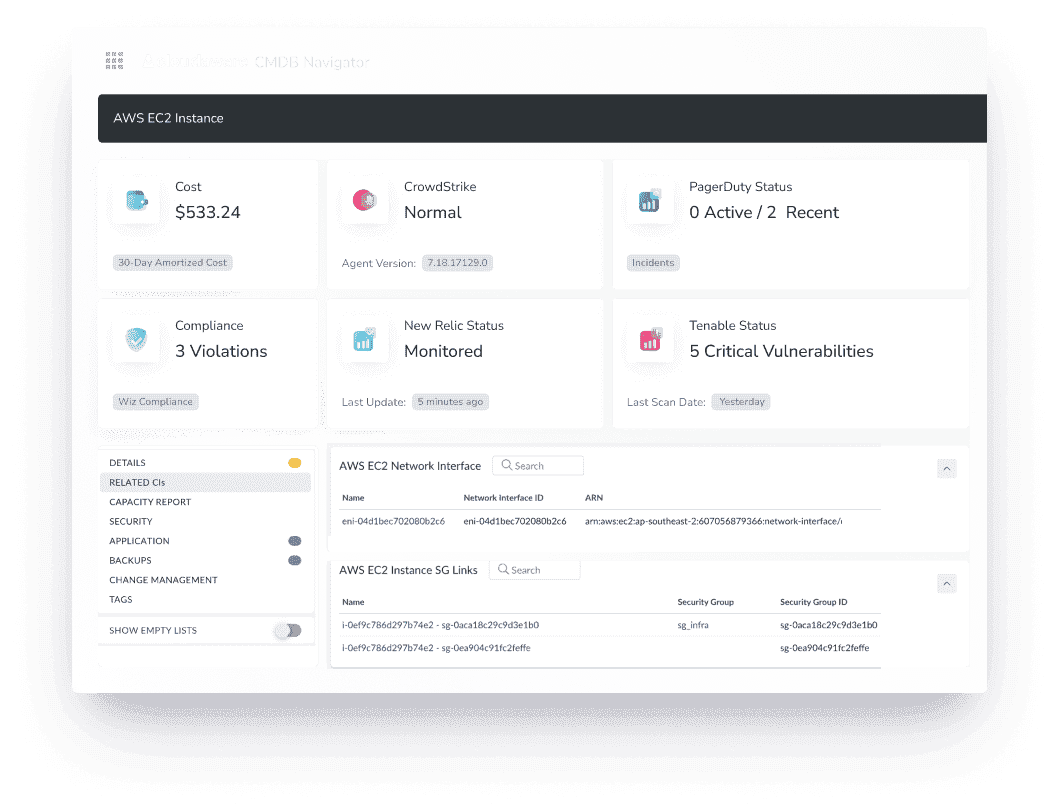
An example of the CI data in Cloudaware. Schedule a demo to see it live.
No one had to log a ticket. It was already there.
🏷 Tagging & Custom Grouping
Here’s where it could’ve gone sideways.
The assets came in — but the naming conventions? All over the place. final2-prod-test, frontend-final-V3, and a few that looked like keyboard smashes.
Instead of enforcing rigid classification, Cloudaware used dynamic tags and custom group rules to organize them automatically.
The ELB with the bad name? Now grouped under:
service_group: Analytics Web Tier - EU
class: Load Balancer
tags: [env=prod, project=analytics-v2, confidentiality_level=high]
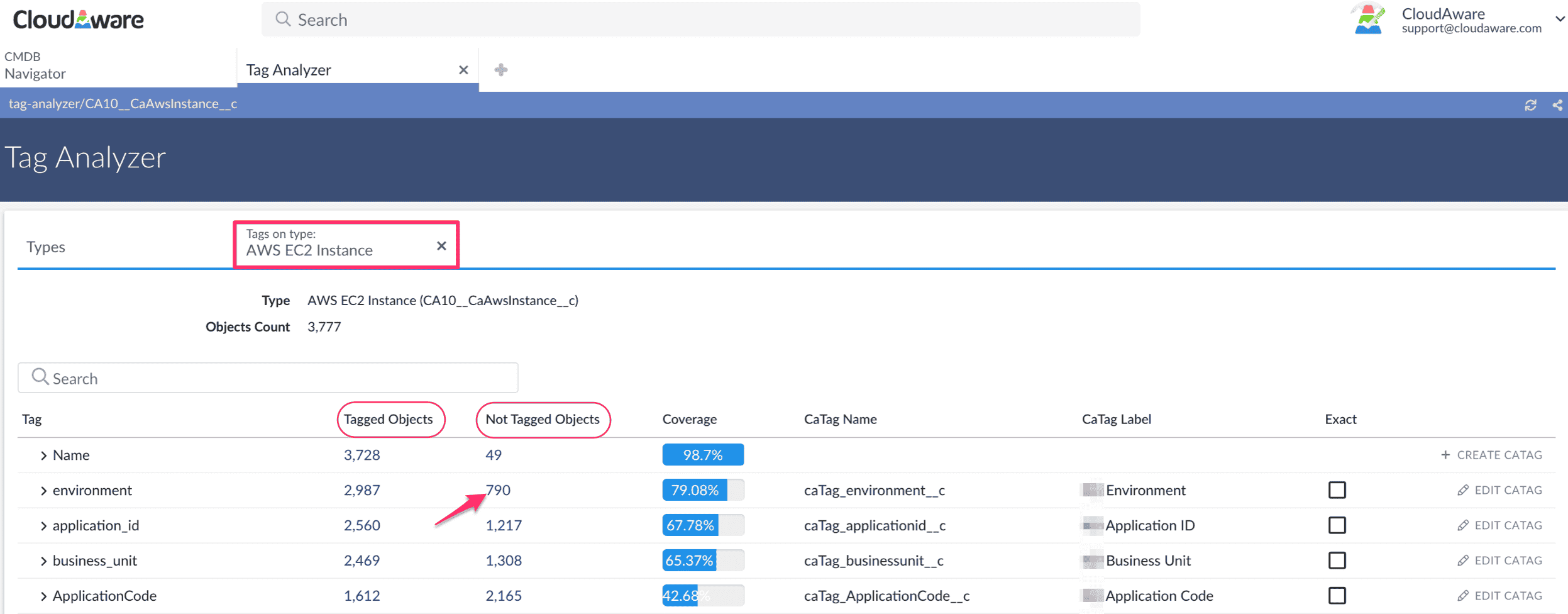
Tagging automation in Cloudaware. Schedule a demo to see it live.
Now the CMDB started making business sense.
👤 Ownership Assignment
Then came the ghost assets.
A few VMs popped in with no owner tags, no activity, and no documentation in sight. But Cloudaware traced their Terraform origin, pulled commit metadata, and matched that to Okta users.
Ownership restored:
ci_title: Session Worker - EU
primary_owner: alex.k@org.com
team: backend-platform
escalation_contact: lead.backend@org.com
source: terraform_commit
Those CIs now had someone to call when they misbehaved. Or worse — when they cost too much.
🔄 Lifecycle Tracking
Time passed. Workloads shifted.
Some CIs were humming. Others faded into silence. That’s where Cloudaware’s lifecycle logic kicked in.
Each asset moved between:
- provisioned
- in_use
- idle
- pending_decom
- retired
Driven by:
- Usage telemetry
- Cost deltas
- Runtime logs
- Infra change events
One VM hadn’t moved traffic in 37 days:
ci_id: gcp-compute-1093
lifecycle_state: idle
last_active: 2024-04-18T13:45Z
auto_flagged: true
ticket: CA-JIRA-3821
Three days later, it was marked for decommission. Cleaned out with a click.
🛡 Security & Compliance Mapping
Audit prep hit hard. But for once, the security team wasn’t scrambling.
Cloudaware had already mapped every CI against defined policies:
- All databases required encryption
- All ELBs had to be reviewed if public-facing
- Required tags: confidentiality_level, costcenter, env
Violations showed up automatically:
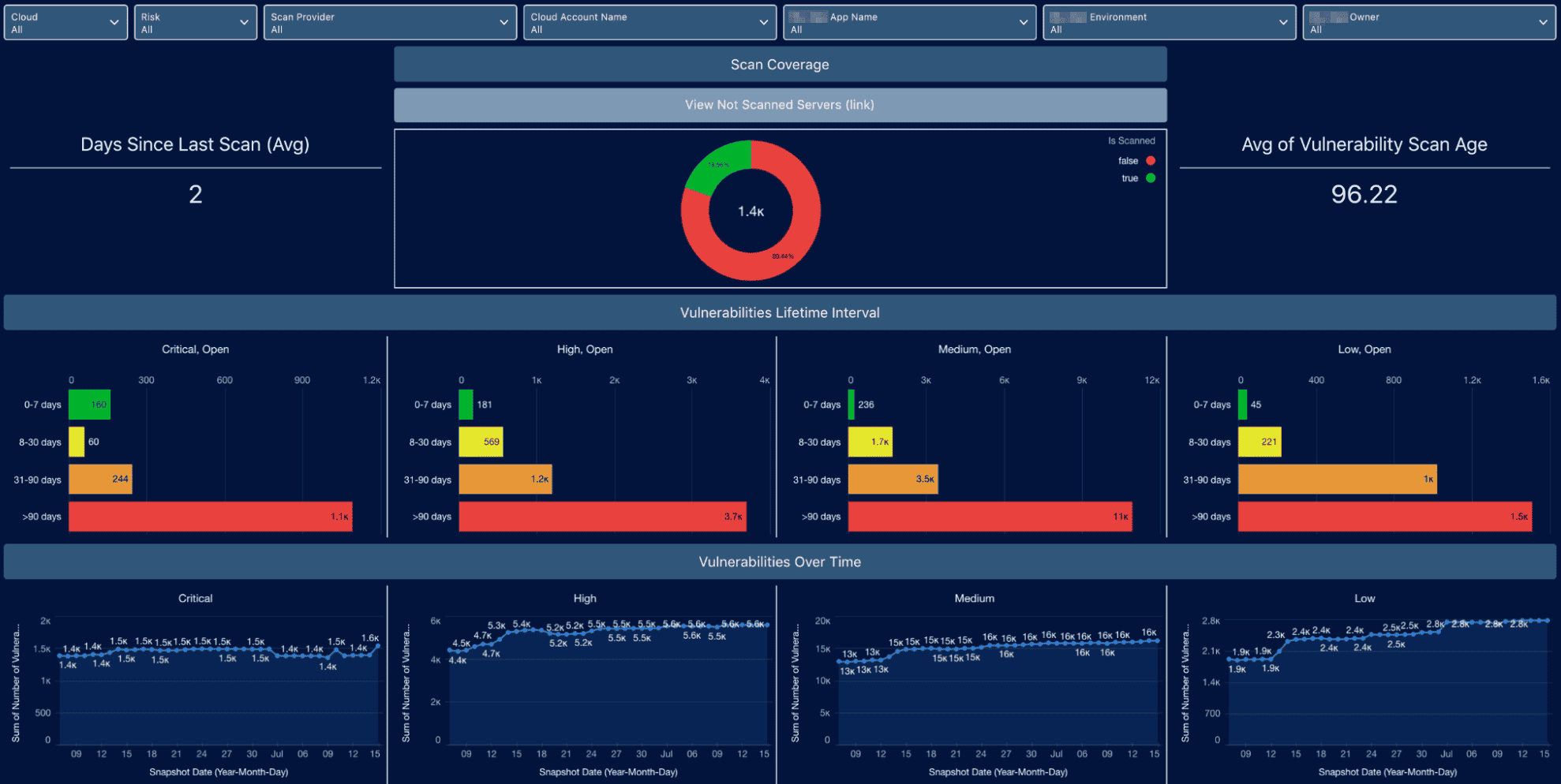
Vulnerabilities dashboard at Cloudaware. Schedule a demo to see it live.
The org filtered the dashboard by severity and knocked out tickets in batches.
💸 Cost Attribution
Mid-month, Finance pinged the ops lead: *“Hey...what’s this extra $4,200 in dev spend?*”
Cloudaware had already flagged it.
A load testing fleet was left running full-capacity in us-west-2. The CMDB tied cost directly to CI metadata:
ci_title: qa-loadtest-runner-dev-3
monthly_cost: 4,278.32
owner: qa-lead@org.com
lifecycle_state: idle
linked_project: analytics-v2
policy_alert: overspend-risk
This management insight gave the team full clarity and fast action. Here is how it looks live:
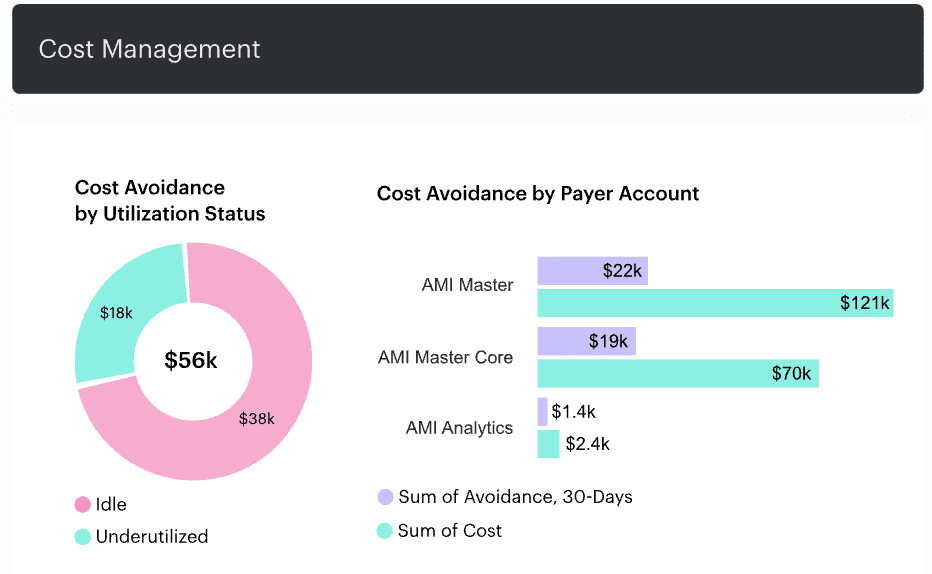
An element of the FinOps dashboard at Cloudaware. Schedule a demo to see it live.
🔧 Change Monitoring & History
Then came the update. A Redis version bump went out. Within hours, the login API started timing out.
Normally? Panic.
But now? You check the CI.
Cloudaware showed:
ci_id: redis-session-store-prod
change_type: version upgrade
changed_by: alex.k@org.com
previous_version: 6.2.9
new_version: 7.0.5
timestamp: 2024-05-07T10:14Z
related_cis: [login-api, auth-service, session-worker]
The timeline showed the entire workflow: what changed, who touched it, what it impacted, and when. The rollback took minutes.
Six months later, audit season hit.
The CMDB was up-to-date. Every asset had a name, a tag, a cost center, a lifecycle state, and an owner. Every software component was accounted for, every anomaly tracked, every violation documented.
The teams pulled reports. The finance lead pulled cost dashboards. The organization moved forward without firefighting.
That are IT asset management processes done right.
Read also: 15 DevSecOps tools. Software features & pricing review
Example of how does asset management work in multi-cloud setup
We’ve covered the theory. But let’s be honest — everyone has a policy doc. What matters is how it all actually works when stuff gets real, fast, and messy. So let’s look at a real-world setup from Coca-Cola. Yep, that Coca-Cola. Their ITAM game is tight, and honestly? It’s a great example of asset management done right.
They’ve got everything in the mix — AWS, Azure, VMware, and even a few stubborn on-prem workloads.
But the secret sauce? Everything flows into their Cloudaware CMDB. That thing is wired into their Terraform repo, CrowdStrike, CloudHealth, Okta, and Jira — turning their environment into a well-connected, real-time asset management platform.
Here’s how it plays out: every time someone drops a new stack via Terraform, Cloudaware picks it up instantly through IaC sync. The CMDB auto-discovers those assets, builds CIs with full metadata, maps service relationships, and runs real-time checks on ownership, tag compliance, and lifecycle status.
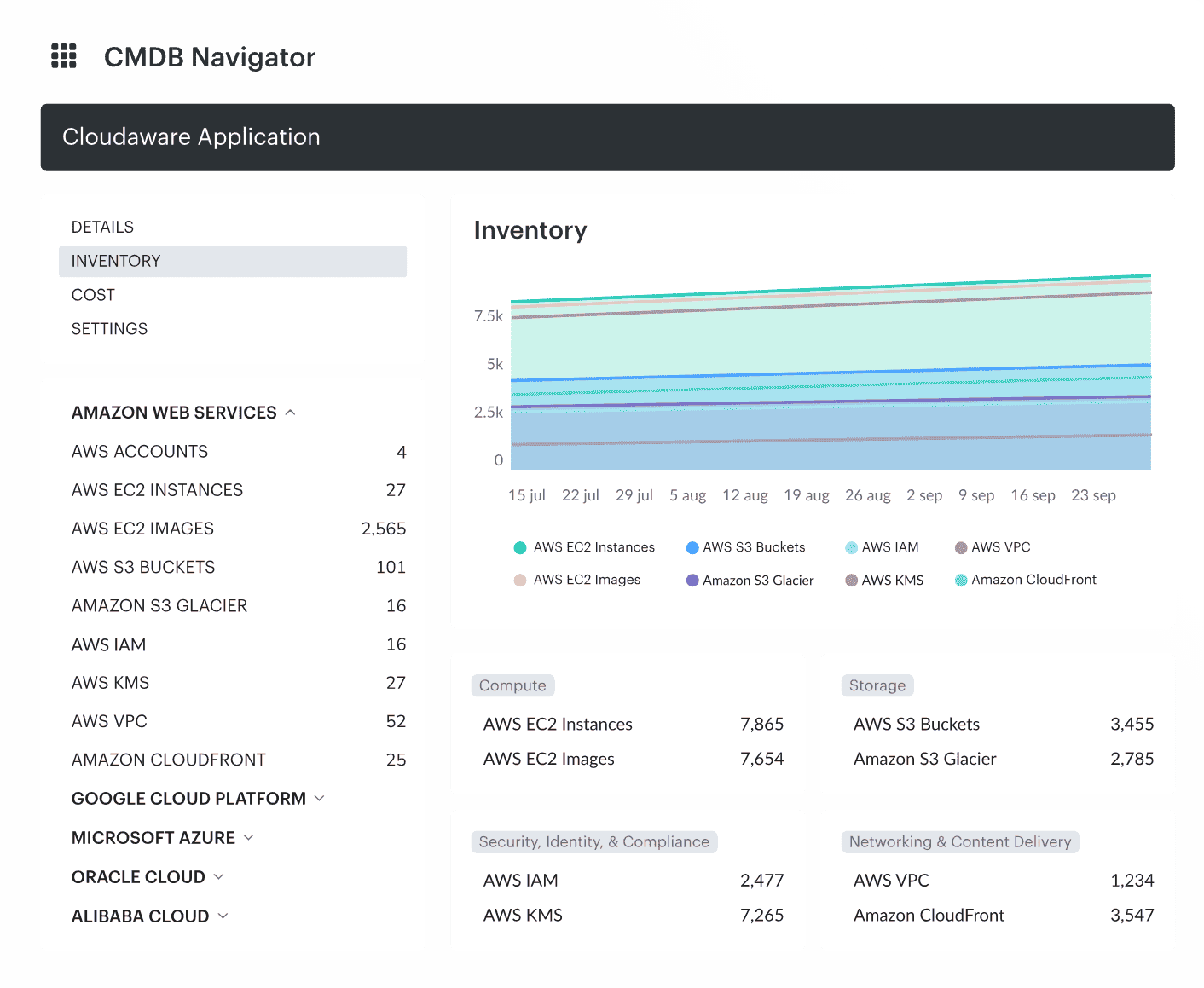
Then the orchestration kicks in:
- Ownership is mapped automatically using identity data from Okta.
- Cost centers are applied based on tags pulled from CloudHealth.
- Security posture data flows in from CrowdStrike for visibility and risk context.
- Tickets are triggered if a CI is missing required tags, metadata, or business context.
If something sits idle too long, Cloudaware flags it. The owner gets pinged. If there’s no response? Cloudaware opens a Jira ticket for review — keeping rogue resources from draining budgets.
The real magic shows up in change impact analysis. When someone wants to modify a core service CI, Cloudaware shows its upstream and downstream connections — load balancers, clusters, linked services — so teams have the full picture before rollout.
The result? Every asset has a known owner, purpose, and lifecycle status. Their CMDB isn’t just up to date — it’s powering daily decisions. From cost reporting and policy enforcement to incident triage, it’s all traceable and enforced.
That’s asset management done right — quietly holding your environment together while the chaos tries to break in.
Top 3 best practices on how to achieve that visibility from ITAM experts
IT asset management often ends up as a nice idea buried under tag sprawl, ghost CIs, and surprise invoices. And when you’re managing complex cloud environments with Terraform and multiple teams, you don’t need more theory. You need what actually works.
So I grabbed three pros from the Cloudaware crew — folks who’ve seen the mess and helped some of the biggest organizations bring order to it. These are the ITAM best practices that stick. Real advice. Real workflows. Ready to plug into your stack today.
Tag Like Your CMDB Depends on It
Iurii Khokhriakov, Technical Account Manager:
Automate the Ops You Keep Forgetting
Kristina S., Senior Technical Account Manager at Cloudaware:
Forecast Cost Like You Forecast Incidents
Mikhail Malamud, Cloudaware GM:
Visualize your multi-cloud infrastructure with Cloudaware
Cloudaware CMDB is built for infra teams, platform engineers, DevOps leads, and architects who are juggling AWS, Azure, GCP, Kubernetes, and whatever 12 other cloud things got approved without telling security.
Organizations like Coca-Cola, NASA, and global banks use Cloudaware not just to track infrastructure — but to own it. To control it. To finally make sense of their IT asset management strategy across clouds, accounts, and service owners.
It’s a real-time, deeply integrated system of record that maps every asset in your environment and keeps it in sync with the truth. So you can stop managing infra with a patchwork of spreadsheets, stale exports, and “I think this belongs to dev-data-core.”
It gives you a complete picture of the data behind your infrastructure — who built it, who’s using it, what it costs, and what it’s connected to.
- Real Time Asset Discovery across AWS, Azure, GCP, Kubernetes, and VMware — using cloud APIs, IaC sync (like Terraform), and config sources.
- Real-Time CI Lifecycle Tracking — provisioned → active → idle → decom → retired, with triggers for action.
- Custom CI Tag Validation with policy flagging for missing keys like costcenter, env, owner_email, confidentiality_level.
- Related CIs highlighted (compute, databases, ELBs, APIs, internal services) — so you know what’s impacted before you patch.
- Change History Logging per CI — who changed what, when, and why it matters.
- Slack/Jira/Ticket Integration to surface unowned, idle, or non-compliant CIs directly in your existing workflows.
- Cost Attribution Per CI using AWS CUR, Azure billing, and GCP exports — mapped to tags, accounts, and business units.
- Security & Compliance Reporting based on tag rules, encryption settings, and internal policy checks.
- Dynamic CI Groups & Dashboards — monitor env=dev and lifecycle_state=idle without writing custom queries.
- Identity Correlation Across Clouds — linking CI changes to Git authors, IAM roles, or software deployment events.
You get a living, breathing platform for your infrastructure — a system that updates itself, enforces your rules, and helps you manage every CI like it matters.
Every resource. Every tag. Every handoff between dev, ops, and security.