






When you’ve been around multi-cloud long enough, you stop treating a single provider as a serious isolation boundary. Mike Gibbs points to Oracle-backed numbers showing that 98% of enterprises already use or plan to use multi-cloud or hybrid multi-cloud architectures, which lines up with what most of us see in real environments.
That is why a multi cloud security architecture should not be thought of as a pile of cloud-native tools spread across providers. In this guide, we will focus on what a multi-cloud security architecture actually looks like when you work across different providers/teams/controls/compliance boundaries.
Key insights
- A multi-cloud security architecture defines how identity, network, workload, and data controls stay consistent across providers with different IAM models, networking primitives, and enforcement mechanisms.
- Control consistency across providers requires aligning policy intent with different implementation models in AWS, Azure, and GCP.
- The highest-risk layers are shared systems such as control planes, routing, and DNS, where a single issue can impact multiple environments.
- Identity models differ across providers, and these differences accumulate into over-permissioning, inconsistent trust boundaries, and exposure.
- Visibility remains provider-scoped by default, which limits correlation and makes system-level behavior harder to detect across environments.
- Policy intent degrades during translation into provider-specific controls, introducing drift between expected and actual enforcement.
- Detection requires context to operate at scale, with ownership, application, and environment attached to findings for prioritization and remediation.
What is multi-cloud security architecture?
A multi-cloud security architecture is a structured model for applying consistent identity, network, workload, and data protection controls across multiple cloud providers. This way policies, visibility, and response workflows stay aligned even when the underlying platforms, APIs, and enforcement mechanisms differ.
The reason you need it is: providers do not expose the same IAM models, networking primitives, or control points, but the control outcome still has to be the same. The job of the architecture is to preserve that outcome by tying policy intent, scope, visibility, and response together instead of letting each provider define security on its own.
Why architecture matters more than tools
Most teams already have tools in each cloud. The problem is that those tools follow provider logic:
- IAM behaves differently on each platform
- Networking primitives are not equivalent
- Even basic controls like firewalling or logging are implemented differently
As highlighted in cloud provider guidance, such as the AWS Well-Architected Framework and Google’s BeyondProd model, controls need to be defined at the level of intent rather than tied to specific implementations. Once enforcement is bound to provider-specific mechanisms, consistency breaks across environments.
There is also a deeper issue most teams run into: shared infrastructure layers. Cloud platforms rely on centralized control planes and large-scale network systems to orchestrate resources. When those layers fail or behave unexpectedly, the impact can go beyond a single workload or account.
Multi-cloud vs hybrid cloud security architecture
People mix up multi-cloud and hybrid cloud security architecture all the time, mostly because vendors blur the terms and treat both as “more than one environment.”
From a security standpoint, the overlap is real, but the control problem is not identical. In one case, you are aligning across multiple public providers. In the other, you are aligning across private and public infrastructure that operate very differently.
| Area | Multi-cloud security architecture | Hybrid cloud security architecture |
|---|---|---|
| Core setup | Two or more public cloud providers | On-prem or private cloud plus public cloud |
| Main challenge | Different IAM models, APIs, networking constructs, and control planes across providers | Consistent controls across private infrastructure and public cloud services |
| Identity problem | Access models differ by provider, so policy translation gets messy fast | Identity has to bridge legacy systems, enterprise directories, and cloud IAM |
| Network problem | Segmentation and traffic control vary by provider | Connectivity between data center and cloud becomes a primary risk area |
| Control-plane risk | Multiple provider control planes with different dependencies and failure modes | Fewer provider control planes, but more operational dependency on integration points |
| Security drift pattern | Same intent, different implementation across clouds | Same intent, different maturity between on-prem and cloud environments |
| Typical use case | Best-of-breed services, resilience, regulatory separation, reduced provider concentration risk | Gradual modernization, data locality, legacy app support, private workload retention |
| What teams usually underestimate | How hard it is to normalize controls across cloud-native models | How much manual work remains at the boundary between old and new environments |
The reason this matters is simple: a multi-cloud security architecture is usually harder to normalize because every provider brings its own control logic.
A hybrid setup still has complexity, but the problem is often integration between cloud environments and private infrastructure, not constant translation between multiple public-cloud models.
Why multi-cloud changes the security model
Most teams expect multi-cloud to be a scaling problem. In reality, it is a control problem. The moment you move beyond one provider, your assumptions about identity, visibility, and failure isolation stop holding, and real challenges in cloud security show up.
Shared responsibility multiplies
Each provider defines responsibility boundaries differently, and those differences do not cancel out, they stack. Security teams end up translating the same requirement across multiple control models, which increases the chance of gaps.
Cloud provider frameworks such as AWS Well-Architected Framework explicitly call out that shared responsibility varies by service and provider, which means control ownership shifts depending on where workloads run. At scale, this becomes less about enforcement and more about coordination and management across environments.
Identity becomes fragmented
Identity is the first place where consistency breaks. Each provider implements IAM differently, including role structure, service identities, and default trust models.
According to Google Cloud, modern architectures rely on identity as the primary security boundary rather than the network perimeter. In multi-cloud environments, inconsistent identity models directly increase the risk of over-permissioning and unintended access paths.
Visibility becomes provider-scoped
Native logging and monitoring are designed per provider, not across them. You can have full visibility inside each cloud and still miss the system-level picture.
Verizon repeatedly shows that detection delays are strongly correlated with fragmented visibility, where signals exist but are not correlated across systems. In multi-cloud setups, this fragmentation becomes structural.
Control plane becomes a shared failure domain
Everything runs through the control plane: provisioning, scaling, and configuration changes. When it fails or behaves incorrectly, it affects multiple services at once.
Major cloud incidents analyzed by organizations like Google SRE consistently point to control plane and orchestration layers as sources of cascading failures, where a single issue impacts multiple services simultaneously.
DNS and service discovery dependencies
DNS is easy to overlook because it usually works. But when it fails, service discovery breaks, dependencies collapse, and systems stop communicating.
Industry incident analyses and reliability guidance from providers such as Microsoft Azure highlight DNS and routing as critical dependencies that can turn partial outages into systemic failures, especially when architectures rely on centralized or provider-coupled resolution mechanisms.
Read also: Top 10 Cloud Financial Management Software Review 2026
Core components of a multi-cloud security architecture
A multi-cloud setup breaks down when teams assume coverage equals control. Most failures happen at the boundaries between identity, network, workloads, and data, not inside any single tool. The goal here is to define the security surfaces that must be controlled.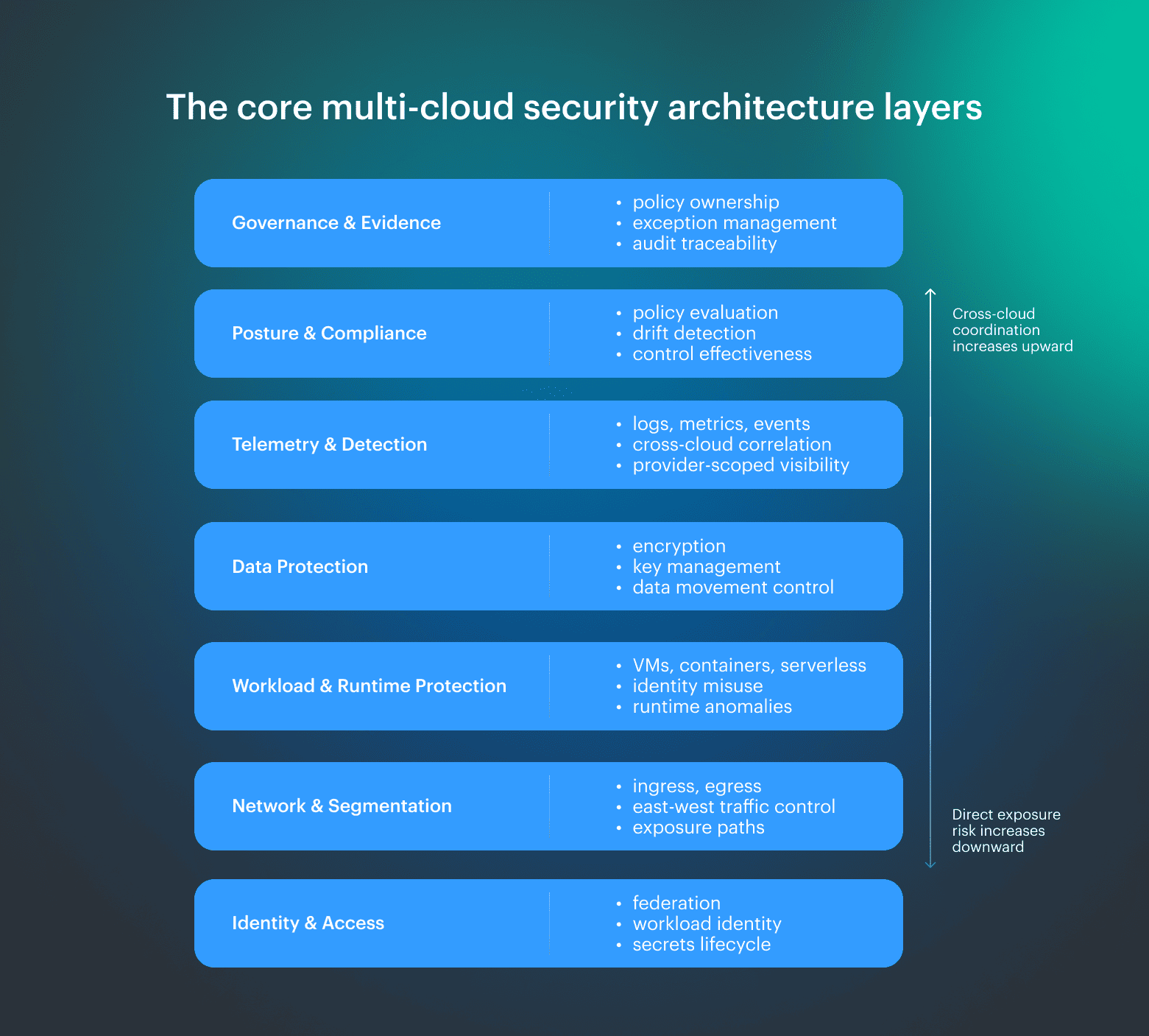 A practical security architecture separates these domains so each one has a clear responsibility and a known failure pattern:
A practical security architecture separates these domains so each one has a clear responsibility and a known failure pattern:
- Governance and evidence. Policy ownership, exception management, and audit traceability. This is where security decisions are made and justified. It fails when risk is accepted without accountability or when evidence cannot be produced for audit and remediation.
- Posture and compliance. Continuous evaluation of configuration and controls against defined policy. This layer identifies misalignment between intent and reality. It fails when findings lack prioritization, ownership, or actionable context.
- Telemetry and detection. Collection and correlation of logs, metrics, and events across environments. This layer provides visibility into system behavior and fails when signals remain provider-scoped and cannot be correlated across clouds.
- Data protection. Encryption, key management, and control of data movement across environments. This layer fails when encryption policies are inconsistent, keys are poorly managed, or data flows are not constrained across providers.
- Workload and runtime protection. Protection for VMs, containers, and serverless workloads after deployment. This is where configuration drift, identity misuse, and runtime anomalies become visible.
- Network and segmentation. Ingress, egress, and east-west traffic control. This layer defines exposure boundaries and fails through implicit trust, weak segmentation, or unintended connectivity paths.
- Identity and access. Federation, role design, workload identity, and handling of secrets. This is the foundation layer where access is enforced. It fails through overprivileged access, inconsistent service identity models, and poor credential lifecycle management.
Read also: A Step-by-Step Guide on How to Conduct a Cloud Security Assessment
Multi-cloud security reference architecture
A multi-cloud security architecture only starts working when you start thinking in terms of where decisions are made, how they are enforced, and how they survive changes across providers.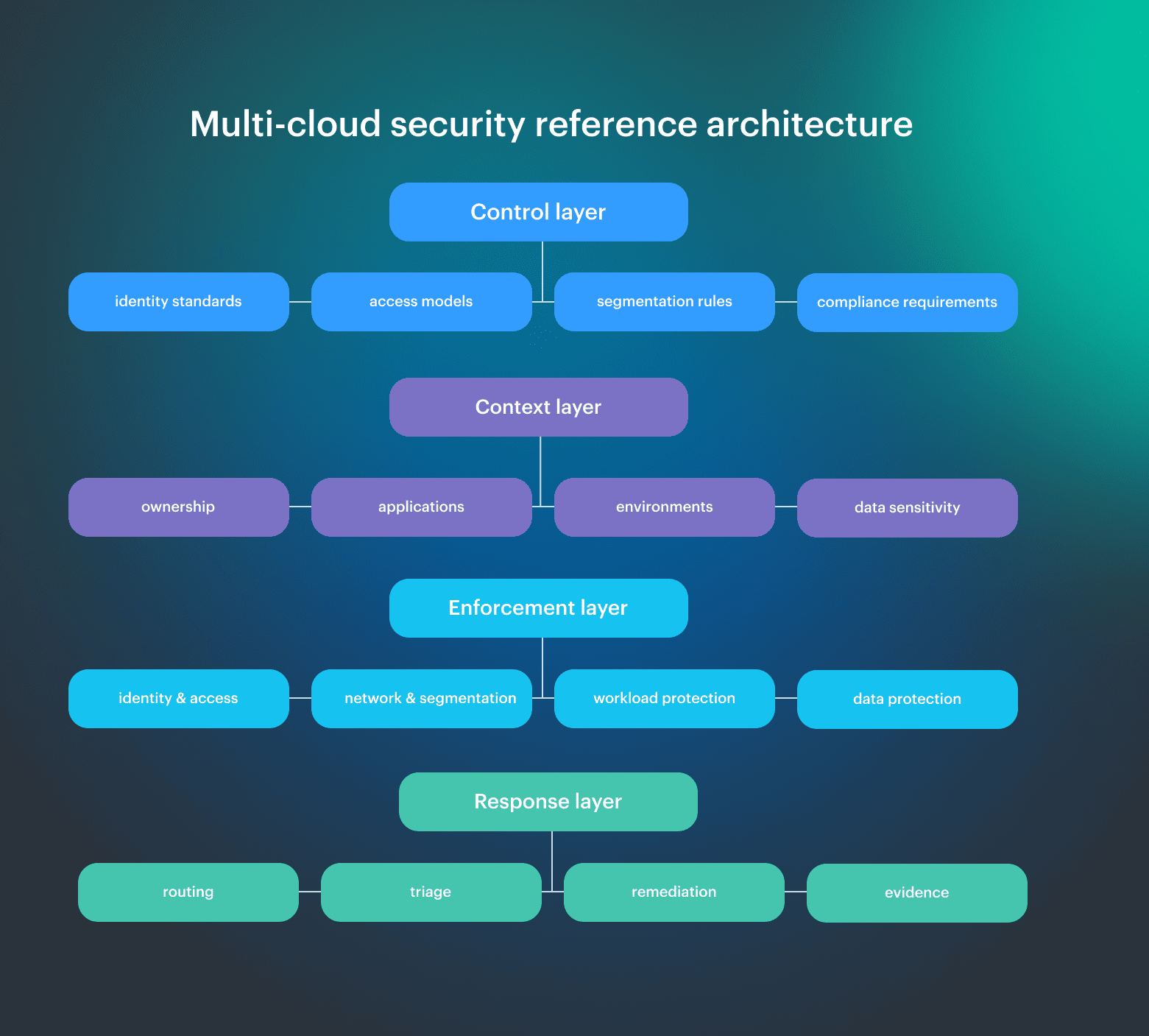 In a working multicloud architecture, control is distributed across layers that must stay aligned:
In a working multicloud architecture, control is distributed across layers that must stay aligned:
- Control defines intent
- Context scopes that intent
- Enforcement applies it
- Response validates and corrects it
Let’s dive into the details:
- Control layer. Policy intent lives here: identity standards, access models, segmentation rules, and compliance requirements. If this layer is inconsistent, everything below turns into provider-specific improvisation.
- Enforcement layer. Controls are applied here using a mix of cloud-native mechanisms and external systems. The same rule maps to different implementations across providers, which is where drift typically appears.
- Context layer. The layer most teams are missing. It links resources to ownership, applications, and environments. Without it, findings cannot be scoped, policies lose precision, and remediation cannot be routed. This is where a CMDB-style model becomes critical.
- Response layer. Signals turn into action at this stage. Alerts are routed, incidents are triaged, remediation is triggered, and audit trails are recorded. Without it, detection remains disconnected from control.
The value of this multi cloud architecture security approach comes from consistency. The same decision is made once, enforced everywhere, and evaluated with the same context. When those connections break, control fragments and teams fall back to per-cloud fixes instead of a working system.
How failure domains map across the architecture
The reason this structure matters is that failures do not happen evenly across layers. They concentrate on shared systems and propagate through dependencies:
- Control plane failure. Policy cannot be applied or updated consistently, leading to drift across environments
- Network failure. Routing issues expand blast radius beyond a single service or region
- Provider outage. Controls tied too closely to a single platform fail together with it
- DNS and service discovery dependency. Systems lose the ability to locate each other, turning partial outages into systemic failures
Read also: Cloud Security Assessment - Methodology, Checklist, Best Practices, and Remediation
Design principles for a strong multi-cloud architecture
Most organizations struggle because controls drift across providers, ownership gets fuzzy, and decisions do not survive change. A strong security architecture keeps those decisions consistent even when the underlying platforms behave differently.
- Standardize policy intent, not provider syntax. Define the rule once as an outcome, then translate it per provider. “Sensitive data must not be publicly accessible” is a real policy. S3 policies, Azure RBAC, and GCP IAM bindings are just implementation details. When teams standardize syntax instead of intent, policy enforcement fragments.
- Design around failure domains, not features. Do not build your model around feature lists or vendor promises. Build it around the things that actually fail together: control planes, DNS, routing, shared identity systems, and provider-managed services. A workable solution assumes dependencies will break and contains the blast radius when they do.
- Make controls context-aware. The same rule does not mean the same thing everywhere. A public endpoint for a test app is not the same risk as a public endpoint tied to regulated data in production. Controls need ownership, application, environment, and data sensitivity to be useful.
- Design for drift and constant change. Multi-cloud environments are always moving. New services appear, permissions change, workloads move, and temporary exceptions become permanent if no one cleans them up. If your model depends on manual review to stay accurate, it will drift.
- Build for evidence, not screenshots. Every meaningful decision should leave a trail: what was checked, what policy applied, what exception was approved, and what changed. If audit evidence has to be assembled by hand, the architecture compensates for missing controls.
- Route findings to owners. Detection without ownership is just a backlog. Findings should already know which team, application, and environment they belong to, so remediation starts with the right people instead of a central queue trying to guess.
5 common multi-cloud security architecture mistakes
Common failures in multi-cloud environments start with the wrong assumptions. Teams often assume that if a control exists in each provider, it will behave consistently across all of them. It will not.
From an architecture standpoint, these are the mistakes that tend to break multi-cloud security first:
- Treating tools as architecture. One of the most common mistakes is assuming that buying the right stack in each cloud is enough. It is not. A CSPM in AWS, native controls in Azure, and separate detection in GCP may all work on their own, but that still does not give you a system.
- Ignoring control plane risk. Most teams design for workload failure and stop there. In practice, control planes are one of the real shared failure domains. When orchestration or provisioning breaks, teams can lose the ability to create resources, apply policy changes, or scale services, even while the underlying compute is still available.
- Copying controls across providers instead of translating intent. A network rule, IAM pattern, or access boundary that makes sense in one provider will not map cleanly to another. The mistake is to copy syntax instead of preserving intent. Once that happens, one cloud becomes the “real” model, and the others become partial imitations.
- Operating without an asset and ownership context. A finding that is not tied to an application, owner, or environment is just noise with better formatting. Teams usually discover this too late, after they already have hundreds of alerts and no practical way to route them.
- Treating compliance as reporting instead of control. This is another mistake that looks fine until you try to operate it. Teams generate reports and prepare audit evidence, but the underlying policy is not continuously enforced. So the report looks clean while the environment drifts underneath it.
Best practices for multi cloud architecture security
Most guidance on multi cloud architecture security stays high-level. In practice, the difference between a working system and a fragmented one comes down to a small set of operational decisions that consistently show up across cloud provider guidance, security frameworks, and real environments.
The practices below reflect patterns seen across AWS, Azure, and Google Cloud architecture guidance and have been validated against how multi-cloud security actually operates in production environments.
Normalize asset inventory first
Every control depends on knowing what exists. Before policy, detection, or compliance, teams need a normalized inventory across all environments.
Cloud providers expose asset data differently, which means raw data is inconsistent by default. Industry frameworks like NIST CSF and CSA CCM both emphasize asset visibility as a foundational control.
Separate policy intent from enforcement
This is a core principle across AWS, Azure, and Google Cloud guidance: define policy once, enforce it many ways.
Policy intent should be provider-agnostic:
- “No public access to sensitive data”
- “Production workloads require least privilege”
Microsoft’s Zero Trust model and Google’s BeyondProd both reinforce this idea: policy logic must be decoupled from enforcement mechanisms.
Add ownership and environment context
According to multiple FinOps and cloud governance reports, one of the biggest blockers in cloud management is lack of ownership metadata.
Controls become effective only when they are tied to an application, an environment such as production, staging, or development, and a responsible team. Without that context, findings are hard to scope and even harder to route.
Automate checks, exceptions, and evidence
If teams rely on manual reviews or screenshots, the architecture is compensating for missing automation. Frameworks like NIST SSDF and CIS Benchmarks consistently point toward:
- Continuous validation
- Automated enforcement
- Audit-ready evidence
Checks should run continuously, exceptions should be tracked with ownership and expiry, and evidence should be generated by the system rather than assembled later.
Re-evaluate architecture per new service
AWS and Google both highlight this in their architecture guidance: every new service changes the risk model. New services introduce new identity models, new data paths, and new exposure patterns.
A working multi cloud security architecture treats every new service as a trigger to re-evaluate controls.
Read also: 25 Cloud Security Best Practices with a Strategy & a Checklist
How to implement a multi-cloud security architecture in phases
A multi-cloud security architecture is not something you deploy all at once. Teams build it in phases, and the order matters. Each phase reduces a specific class of failure that tends to show up later if it is skipped.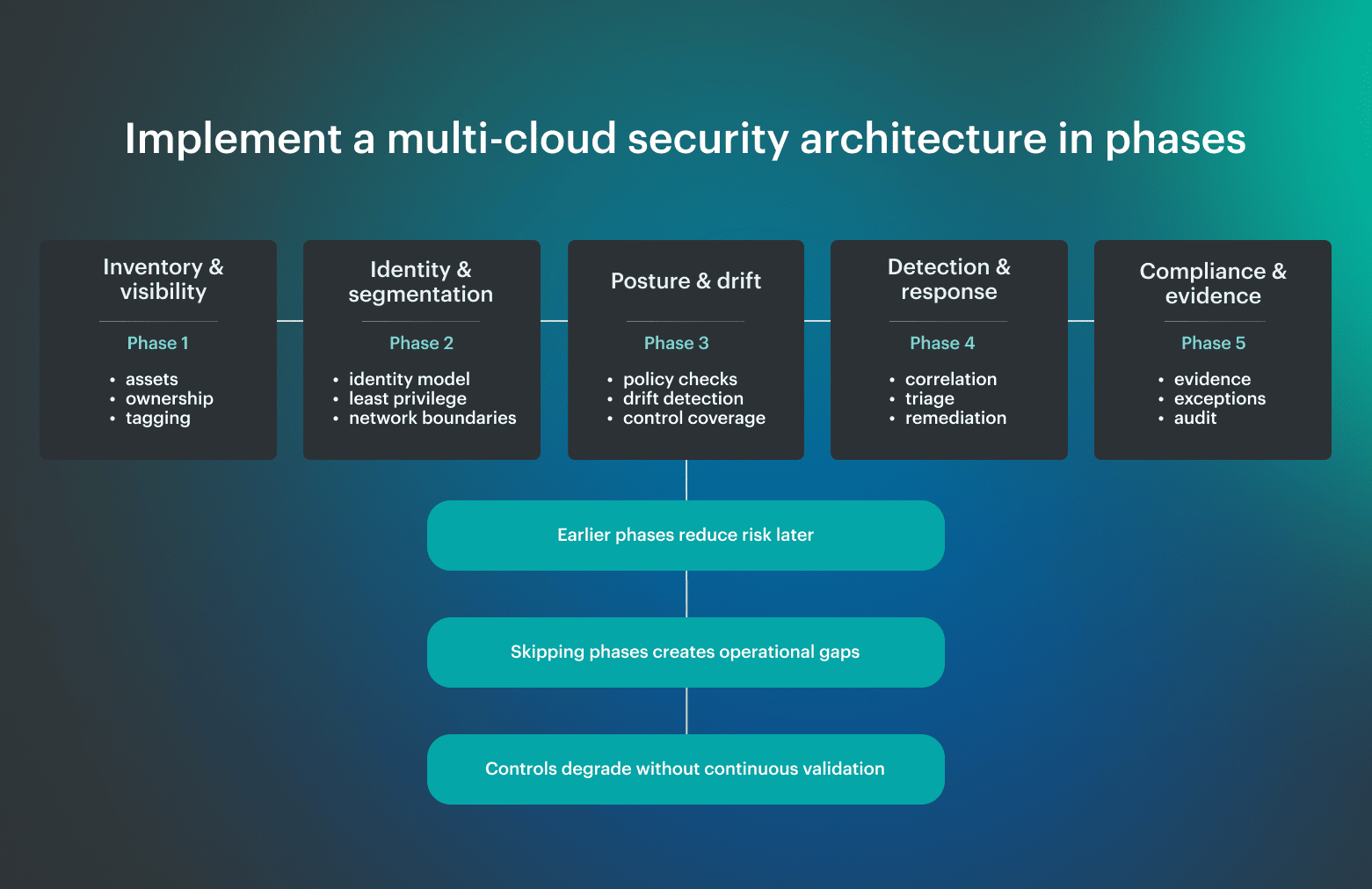 A working multicloud security model builds from visibility to enforcement to validation, so controls stay consistent as environments evolve.
A working multicloud security model builds from visibility to enforcement to validation, so controls stay consistent as environments evolve.
Phase 1: Inventory and visibility
Don’t underestimate how inconsistent asset data is across providers. AWS, Azure, and GCP all expose inventory differently, and without normalization, you do not have a reliable system view.
In practice, failures here are simple but critical: resources exist that no one owns, services are deployed outside expected patterns, and dependencies are not visible. Once that happens, every downstream control becomes partial.
Phase 2: Identity and segmentation
This is where multi-cloud complexity shows up fast. Each provider has a different IAM model, different service identity behavior, and different defaults.
From real architecture experience, most exposure does not come from a single misconfiguration, but from accumulated identity decisions: over-scoped roles, long-lived credentials, and implicit trust between services. Once deployed, these patterns are hard to unwind without breaking workloads.
Phase 3: Posture and drift detection
Cloud environments do not stay in their intended state. Emergency fixes, scaling events, and service updates introduce drift continuously.
In real systems, this is where problems become visible. Not because they started here, but because this is the first place they can be measured. Without continuous validation, drift remains silent until it turns into an incident.
Phase 4: Detection and response workflows
At this stage, systems start producing signals, but signals alone do not reduce risk.
In practice, one of the most common failure patterns is fragmented visibility. Each provider produces logs and alerts, but they remain isolated. Without correlation and routing, incidents span multiple services while teams see only partial signals. This is where response and management start to break down.
Phase 5: Compliance and reporting
This phase reflects everything below it. When earlier layers are weak, compliance becomes manual.
In real environments, teams end up assembling evidence after the fact, because systems were not designed to produce it continuously. The result is reporting that looks complete, but does not reflect the actual system state. A phased solution avoids that by making evidence an output of the architecture, not a separate exercise.
Metrics that show the architecture is working
Most organizations measure activity when they need results. Number of alerts, number of checks, number of tools. None of that proves the architecture works. A working model shows up in consistency, response, and how well the system behaves under stress.
Here are the most important metrics your security architecture needs:
Coverage metrics
These answer a basic question: do you actually see your environment?
- % of assets discovered across all environments
- % of assets with owner, application, and environment assigned
- % of resources included in policy evaluation
Gaps here mean everything else is built on incomplete data. If coverage is not close to complete, risk is being missed by design.
Control consistency metrics
Use them to confirm that the architecture is working from a complete asset base:
- % of policies applied across all clouds
- Number of exceptions by environment and provider
- Age and drift rate of exceptions
Response metrics
Use these metrics to verify that detection turns into action:
- Mean time to route (MTTRoute)
- Mean time to remediate (MTTR)
- % of findings with assigned owner
The failure mode here is clear: alerts exist, but nothing happens. Effective management means issues reach the team that can act and get resolved within expected time.
Failure resilience metrics
Use them to see whether failures stay contained:
- Blast radius of incidents (how many services or environments affected)
- Recovery time after control plane, network, or service failure
- % of incidents contained within one environment
Governance metrics
Use these metrics to track whether decisions remain accountable over time:
- % of findings with documented exceptions
- % of exceptions with expiry and owner
- % of controls producing audit-ready evidence
If governance is weak, controls degrade silently. Decisions get made, but they are not tracked, and over time, the system drifts away from its intended state.
How Cloudaware supports multi-cloud security architecture
In multi-cloud environments, the hard part is usually keeping inventory, policy logic, and ownership connected as the environment changes. Once those drift apart, teams lose consistent scope, findings become harder to route, and remediation turns into manual coordination.
Cloudaware solves that problem by connecting normalized inventory, policy evaluation, ownership context, and remediation workflows in one operational layer that works across providers.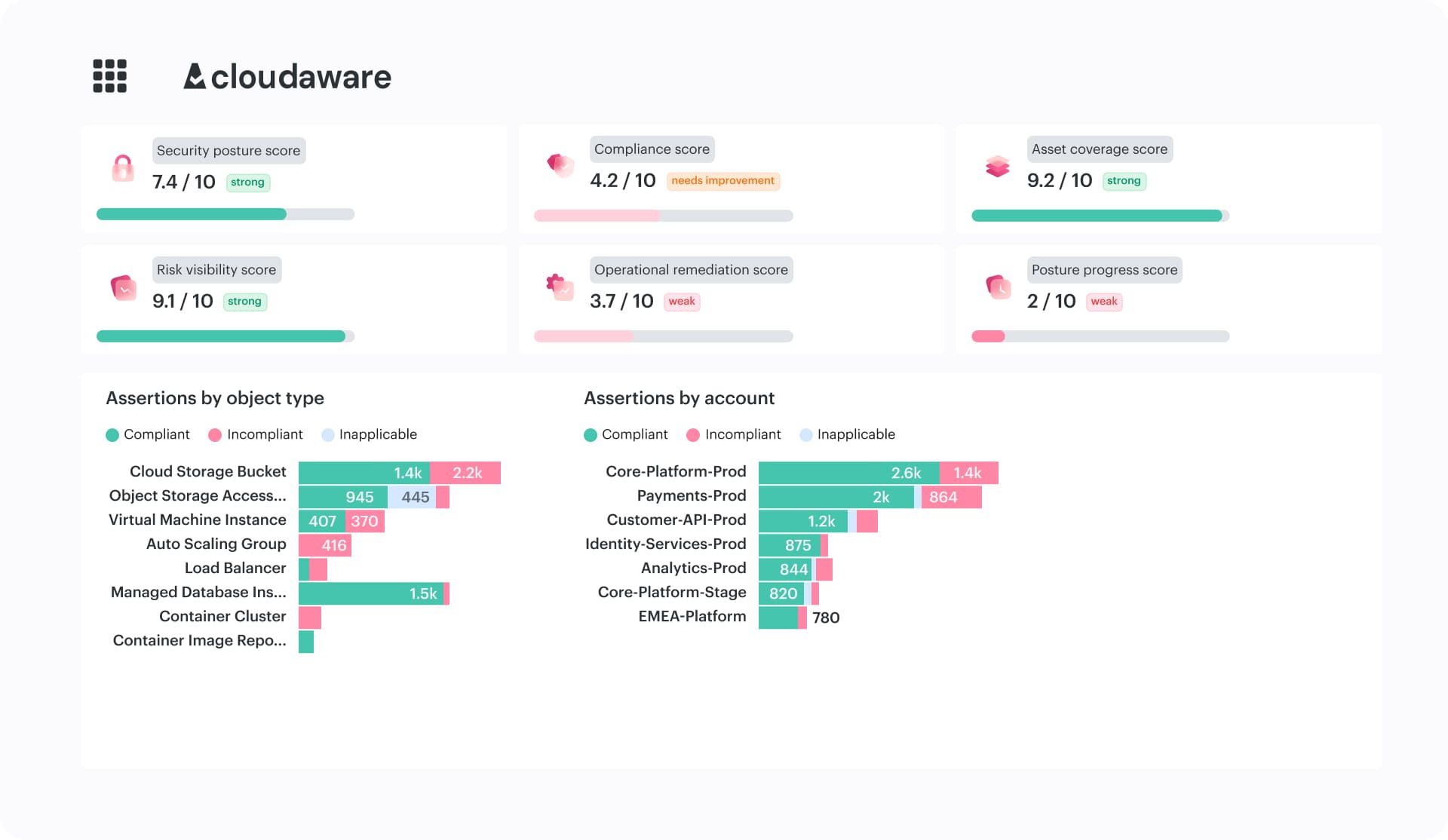
Key capabilities:
- Unified visibility across AWS, Azure, GCP, and hybrid environments. Cloudaware maintains a normalized, near real-time CMDB-backed inventory across providers, including assets, relationships, and ownership.
- Context-aware security findings. Findings are evaluated on top of CMDB data, so each result already includes ownership, application, and environment context.
- CMDB-driven policy enforcement across environments. Policy is defined centrally and evaluated across cloud and hybrid infrastructure using a unified data layer.
- Exception and scope management. Exceptions are handled as part of the system, with ownership and expiration built in.
- Remediation workflows and ticket integration. Findings are routed directly into operational systems such as Jira, ServiceNow, or PagerDuty, so issues are assigned to the teams that own the affected resources and resolved within existing workflows.
- Continuous evidence and audit readiness. Compliance evidence is generated as part of ongoing policy evaluation, with full traceability of violations, exceptions, and remediation actions over time.