






If you’re running hybrid + multi-cloud, assets don’t “sit” anywhere. They appear, change shape, get redeployed, inherit tags, lose tags, pick up risk, and quietly rack up spend. That’s why ITAM isn’t a quarterly spreadsheet exercise anymore but a living system: discovery, ownership, controls, and proof.
This guide is written for teams who need asset data that stands up during a security incident, a licensing true-up, and a budget review—without turning IT into a ticket factory.
Key IT asset management best practices
Here are 5 ITAM best practices teams use to keep asset data accurate, costs explainable, and audits boring:
- Run continuous automated asset discovery across AWS/Azure/GCP + on-prem so new resources don’t slip through untracked.
- Maintain one centralized authoritative asset inventory with required fields (owner, service, environment, lifecycle state, last seen) to stop “who owns this?” chaos.
- Reconcile inventory with billing weekly so every dollar maps to a real asset and a real owner.
- Standardize tagging + ownership rules (and enforce them) so assets don’t become orphaned, misclassified, or impossible to charge back.
- Operationalize lifecycle actions (quarantine → review → decommission → disposal) so idle resources and shelfware don’t turn into permanent spend.
Now let's dive into details 👇
Eliminate idle assets
Quick reality check. If your cloud spend is climbing while your release calendar is quiet, you’re paying rent on stuff nobody lives in.
Idle assets come in two flavors:
- Ghosts: the record exists, the resource doesn’t. Think: a VM still listed as “Active” in your inventory, but the instance was terminated weeks ago. Your reports look bigger than reality. Audits get messy because you can’t prove what existed when.
- Zombies: the resource exists, the purpose doesn’t. Unattached EBS volumes, stopped-but-not-deleted VMs, orphaned load balancers, old snapshots, forgotten Cloud SQL instances. They sit quietly and bill quietly. That’s how budgets bleed.
The cost side is obvious. The security side bites later. Unused identities and stale infrastructure expand your attack surface and trip benchmarks:
- CIS AWS 1.11 flags unused IAM credentials because they’re a gift to attackers.
- CIS GCP 2.9 cares about default service accounts because “default + broad permissions” is how you get surprise access.
- CIS Azure 6.2 is the classic “why is this VM still here?” moment—especially when it’s running with old configs and nobody remembers the owner.
So yeah, you clean this up for savings. You also clean it up so compliance and incident response don’t turn into archaeology.
How to implement this ITAM best practice
You don’t need heroics. You need a repeatable loop: find → reconcile → quarantine → delete → prevent.
1) Detect drift with continuous discovery
Run continuous discovery across AWS/Azure/GCP (and on-prem if you’ve got it), then normalize everything into one inventory view. You’re looking for drift patterns:
- Asset exists in cloud, missing in inventory
- Asset exists in inventory, missing in cloud
- Asset exists in both, but metadata is stale (owner missing, tags missing, lifecycle state wrong)
In Cloudaware terms: treat your CMDB as the place where “last seen” timestamps and asset state come together, because “we think it’s there” isn’t an operational truth.
2) Reconcile billing to inventory every week
This is the fastest way to catch zombies because money doesn’t lie.
Here’s a clean IT asset management example you can run in 10 minutes:
Pick any line item on your AWS bill (say, an EC2 instance + attached storage). Now ask: does that cost map to a CI with an owner, an app/service name, and an environment tag?
If the answer is “no,” you’ve found a zombie with a credit card.
What to enforce in the reconciliation:
- Every cost line must map to one inventory record (no “misc spend” bucket)
- Every inventory record must have owner + cost center + environment
- Missing data triggers a workflow, not a shrug
3) Flag idle candidates with hard thresholds
You’re not guessing “idle.” You’re using signals.
Set thresholds by asset class, because idle compute is different from idle storage:
- Compute (VMs): CPU under ~1–2% average for 14–30 days + near-zero network
- Storage (EBS / disks): unattached volumes immediately suspicious; old snapshots with no referenced workload
- Databases: low connections / no reads-writes for 30+ days (careful: some are “quiet but critical”)
- Network: load balancers with no targets; public IPs unattached; stale DNS records
In Cloudaware terms: this is where your discovery + related-item context matters—idle signals become meaningful when you can see what the asset is connected to (or not connected to).
4) Quarantine before you delete
Deletion without a safety rail is how people get gun-shy and stop cleaning.
Use a quarantine state:
- Tag / set lifecycle state: Pending Deletion
- Auto-notify the recorded owner (or owning group)
- Start a timer: 7–14 days is typical for non-prod; longer for prod if change control requires it
- Take a snapshot/backup if policy demands it (and label it so it doesn’t become the next zombie)
No response by the deadline? Auto-close the loop: terminate + archive evidence (what it was, who was notified, when it was removed).
5) Prevent the comeback with two guardrails
This is where most teams fail. They do one cleanup sprint, then the swamp grows back.
| Guardrail A: mandatory metadata at creation No owner tag, no environment, no app/service name? The asset gets flagged immediately. In mature setups, the asset gets quarantined until tags are fixed. | Guardrail B: expiry for dev/test Dev and test workloads should ship with an expiration date. If someone needs more time, they extend it—explicitly. You want defaults that remove clutter automatically. |
What to measure
Pick a small KPI set and review it weekly:
- Orphan rate: % of assets with no owner
- Unmapped spend: $ amount not tied to an inventory record
- Idle coverage: % of inventory evaluated against idle thresholds
- Time-to-clean: median days from “flagged idle” to “terminated”
- Exception age: how long “Pending Deletion” assets sit without action
If those numbers move in the right direction, your cloud gets leaner, your CMDB gets sharper, and compliance stops surprising you at the worst possible time.
Automate asset discovery process
This is the moment every cloud team has lived through.
Security pings you: “Hey, what’s this instance?”
Finance pings you next: “Also, why did spend jump?”
Then someone drops the classic: “Just check the CMDB.”
You check. Nothing. No CI. No owner tag. No linked service. No ticket trail. The asset exists in the cloud, but it doesn’t exist in your process. That’s the problem.
Because once a resource can spin up without being seen, it can also:
- sit there for weeks and rack up cost
- drift away from baseline configs
- trigger compliance findings when nobody’s watching
And yep, the blast radius is real. One “mystery” workload with sloppy storage or identity settings can end up tripping controls like CIS AWS 2.1 when access gets misconfigured and you’re left explaining how something internet-facing had no accountable owner.
Automated discovery turns that chaos into a boring, repeatable routine. That’s the point.
How to implement this ITAM best practice
Treat this as an ITAM best practice: discovery isn’t a project. It’s a continuously running system with reconciliation and enforcement built in.
- Turn on continuous discovery across your estate
Run discovery across AWS/Azure/GCP (and on-prem if you’ve got it) and make sure the feed is frequent enough to catch short-lived assets.
What you want captured on ingest:
- asset type + unique ID (instance ID, volume ID, DB identifier)
- account/subscription + region
- tags/labels (including owner + app/service + environment)
- first seen / last seen
- relationships (attached volumes, security groups, IAM role/profile, VPC/subnet)
In Cloudaware terms: your CMDB gets updated as assets appear and change, so “unknown” becomes an exception state, not a mystery thread.
- Normalize identities so duplicates don’t poison trust
Discovery is useless if the same thing shows up as three different records.
Set a consistent identity rule per asset class (cloud-native IDs first, then fallbacks like name + account + region if needed).
Also: decide what wins when sources disagree.
Example: cloud provider metadata wins for “exists/doesn’t exist,” CMDB wins for “business owner,” billing wins for “cost signals.”
- Reconcile discovery against billing + ownership rules
Do a weekly reconciliation loop that answers one question: Can we explain every dollar with an owner and a purpose?
Practical rules:
- If it’s on the bill but not in inventory → flag as Untracked
- If it’s in inventory but not seen for X days → move to Stale / Review
- If it has no owner tag → flag as Orphan
- If cost spikes without a mapped service → alert the owning team (or escalate to platform)
Cloudaware makes this easier because you can line up discovered assets with CMDB context and cost signals in the same operational view. The goal is simple: no spend without accountability.
- Auto-classify and enforce baseline policies on ingest
Don’t wait for quarterly audits to find out an asset is risky.
On ingest, auto-classify assets using the signals you already have:
- environment (prod vs non-prod) from account/subscription rules and tags
- criticality from connected services and exposure (public IP, internet-facing load balancer)
- lifecycle state from “first seen” + activity patterns
Then run validation checks on the assets that matter most (internet-facing, regulated scope, prod).
If something violates baseline controls, create an exception record and route it to the right owner team.
Example output
Daily “Untracked Assets” report (sample rows):
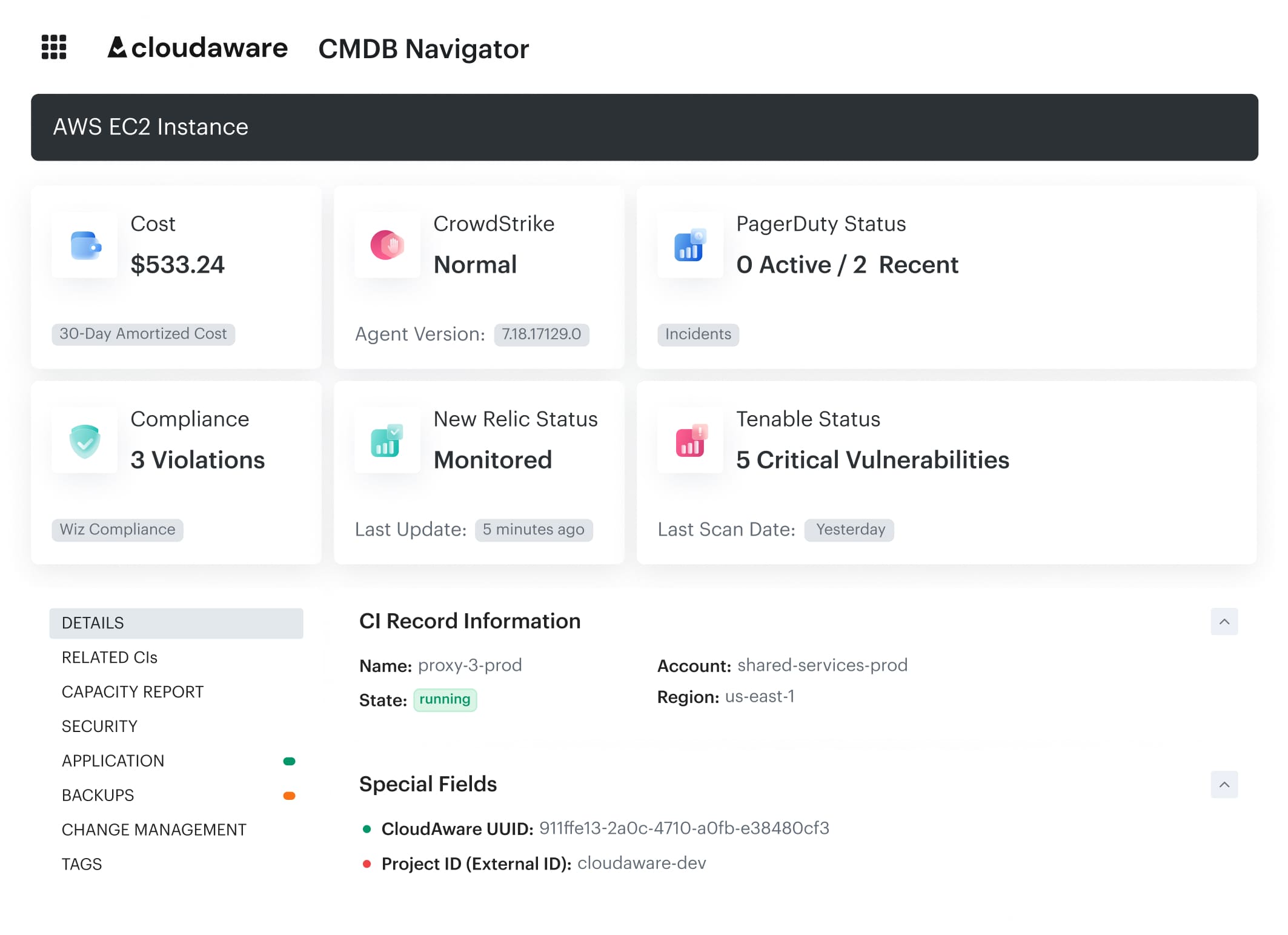
That’s what “discovery working” looks like: asset, context, owner gap highlighted and action path defined.
What to measure after all
- Discovery coverage (%): % of cloud accounts/subscriptions actively feeding assets into inventory.
- Orphan asset rate (%): % of assets missing an owner (or owning team) after 24 hours of first seen.
- Reconciliation match rate (%): % of billed resources that map to a valid inventory record with owner + service context.
Maintain a centralized inventory
"Everything looked fine… until it wasn’t."
That’s how the Head of Cloud Operations at a global fintech company opened up on our demo call. This is an IT asset management example where company spent 72 hours firefighting an issue that never should’ve happened.
A critical payment API went offline during peak transaction hours. The alert hit their NOC first, then DevOps, then Security. Chaos unfolded — where was the problem? Which system failed? No one could answer.
Logs pointed to a missing database instance.But when the team went digging through AWS, Azure, and even the on-prem servers — nada. The CMDB was blank. FinOps couldn’t tie it to a single line item. Finally, after someone practically played cloud detective and reverse-engineered the app stack, boom — there it was. A dusty old instance still humming away in GCP, forgotten by everyone but still racking up charges like it owned the place.
It was business-critical — yet it existed in no inventory, had no owner, and wasn’t tagged properly. It lacked required labels, making it impossible to track its cost or touch its security posture.
That’s when they knew: they needed a centralized IT asset management (ITAM) solution — an ITAM best practice they had overlooked.
How to implement this ITAM best practice
Cloudaware’s CMDB unifies all asset management across AWS, Azure, GCP, and on-prem into one intuitive dashboard. No more asset hide-and-seek — everything is visible in real time.
- Every Configuration Item (CI) in Cloudaware comes fully loaded: tags, ownership, cost, compliance, even security posture. You get the full story — no more blind spots, no more mystery resources lurking in the shadows.
If it’s unlabeled or untracked? It gets flagged. Field required, my friend. Accountability built in. - Multi-Cloud Navigator lets you see the big picture — it maps dependencies between services, apps, and infrastructure so you’re not flying blind.
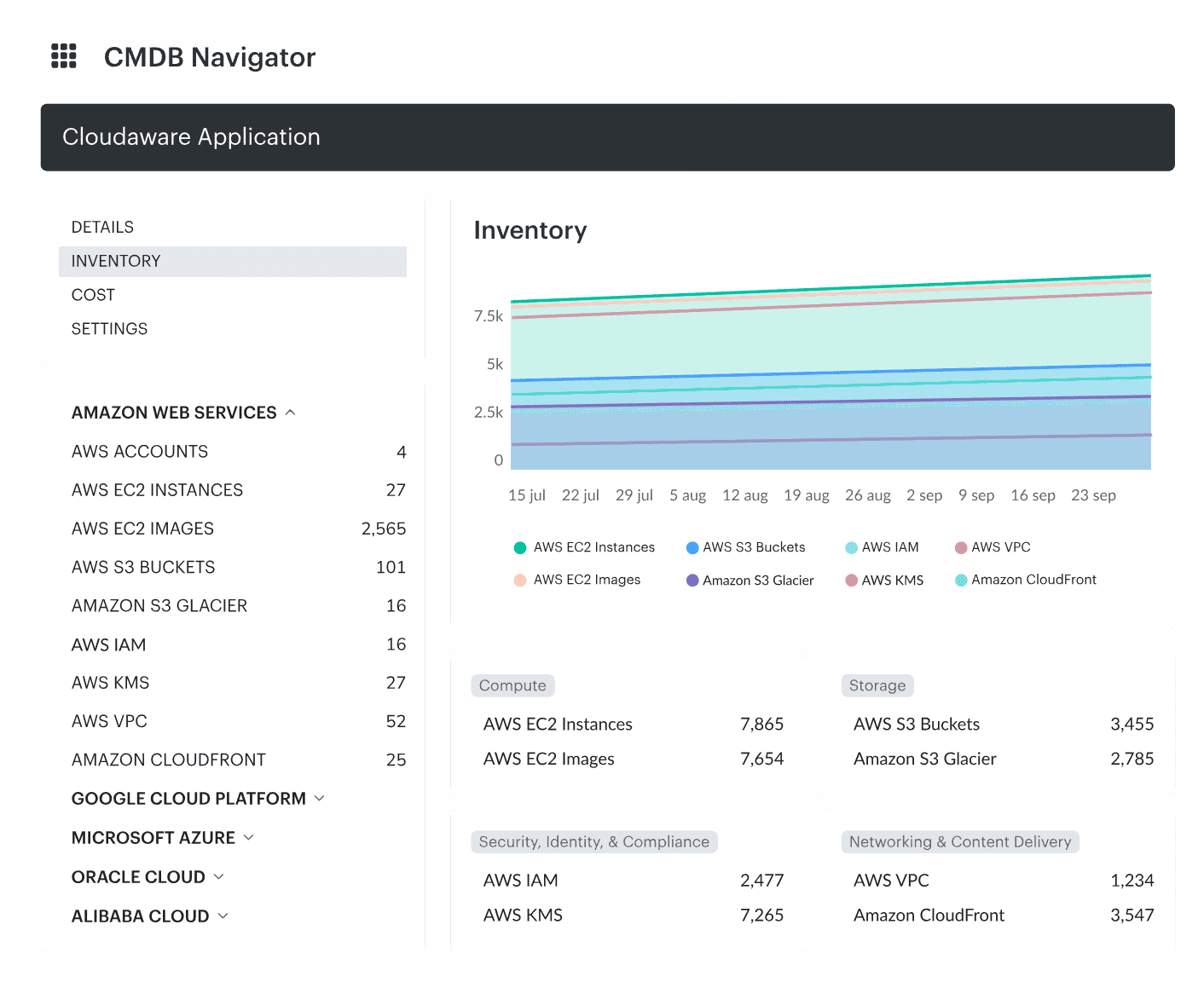
Track everything, explore relationships, and automate the grunt work. It's IT asset management best practices… but finally usable.
Conduct audits to avoid compliance penalties
It’s a peaceful morning. Coffee in hand, you’re skimming through dashboards, everything looks normal. Then — a new manager pings you.

You pull up the audit report and immediately spot the problem — hundreds of virtual machines running outdated OS versions with critical vulnerabilities. No patching, no tracking, no security monitoring. Some of them aren’t even tagged properly, making it impossible to tell which team owns them.
The compliance team isn’t happy. The company’s CIS AWS 3.1 – Ensure EC2 instances are using approved AMIs and CIS Azure 4.4 – Ensure VM images are regularly updated policies have been ignored. Now, you’re looking at security risks, a failed audit report, and a mad rush to patch everything before leadership steps in.
All of this could have been avoided — with regular IT asset management (ITAM) audits and structured reporting.
Must-have ITAM reports for compliance & security
Audits don’t wait. And compliance? It's not a checkbox — it’s a system. If your asset data lives in ten tools and five spreadsheets, you're not compliant — you're guessing. Here's your essential Cloudaware-powered ITAM report lineup:
✅ Asset Inventory. One list to rule them all. AWS, Azure, GCP, on-prem — all your assets, tied to owners, cost centers, and activity logs. Zero ghost gear.
✅ Compliance Snapshot. OS versions, app installs, licensing gaps, EOL alerts. Your first line of defense against fines and finger-pointing.
✅ Patch Intel. See every unpatched system and every outdated binary before your CISO does. Aligned with CIS benchmarks, so you can skip the guesswork.
✅ Access & Permissions Audit. IAM roles, service accounts, and way too many permissions? This flags orphaned logins, excessive access, and MFA no-shows.
✅ Drift Detector. Compares baseline configs to what’s actually running. Catch those “minor changes” before they become security incidents.
✅ Untracked Asset Report. Unlabeled, still running, and burning budget? Not anymore. This surfaces the rogue stuff no one's claimed.
✅ Cost & Usage Breakdown. What’s running, who’s paying, and which app just exploded your budget. FinOps dream, finance team relief.
✅ Compliance Trendline — Track how far you’ve come (or fallen). Great for quarterly reviews, even better for audit receipts.
All this? Live. Automated. Delivered on your schedule. And when leadership needs something custom for next week’s board meeting? Your ITAM team’s got templates ready.
With Cloudaware CMDB, reporting isn’t a chore — it’s your power move.
Auto-tag assets based on workload behavior
Static tags age fast. Like, way too fast. They’re fine on day one — but three weeks later, when workloads shift, ownership changes, or infra gets repurposed mid-sprint? Those cute little Environment:Dev and Owner:Team-X tags turn into misinformation machines.
And in IT asset management, bad tags = bad decisions.
You can’t secure what you can’t track.
You can’t optimize what looks idle but isn’t.
You can’t troubleshoot if alerts are routed based on stale metadata.
If you're serious about IT asset management best practices, your tagging system needs to reflect how assets behave — not just what they were labeled when they launched.
Here is the IT asset management example from my experience as ITAM expert supporting Cloudaware clients
Midway through a product launch, the team got slammed with latency alerts. APIs slowed to a crawl, dashboards lit up like a holiday tree, and incident calls started flying.
Every EC2, RDS, and Lambda was tagged — but not accurately.
🚨 A “Test” instance was quietly carrying live traffic.
🚨 Escalation alerts went to a team that had rotated off the project.
🚨 Budget reports flagged critical workloads as low-priority — and cut resources mid-load.
It was a full-on tagging fail. And it wasn’t that tags were missing — they were just outdated. That’s what made the whole thing worse.
How to implement this ITAM best practice
1️⃣ Implement behavior-based tagging
Manual tagging is like trying to manage a smart city with sticky notes. It works until it really, really doesn’t.
We turned on Cloudaware’s Tag Analyzer, and let asset behavior drive the metadata. Real usage, real time — no guesswork.
- EC2 pegging CPU for 10+ minutes? Auto-tag:
High-Load. That tag then feeds our autoscaling policy. - Orphaned EBS volume lurking since last quarter? Auto-tag:
Decommission, and schedule for cleanup. - Database no one's touched in two weeks? Auto-tag:
Idle, flagged for review by the ops team.
Suddenly our asset data wasn’t just labeled — it was living. Tags updated as reality changed, and that changed everything.
2️⃣ Automate it, let it roll, and stop babysitting tags
Here’s where it gets smooth: you can automate the entire tagging lifecycle.
Inside Cloudaware: Setup → Tag Resources → Define Rules
You can trigger on CPU, memory, network, disk I/O, even last API call. Stack up conditions, nest logic, and let the platform do the grunt work.
- New resources? Tagged right out of the gate.
- Long-running stuff? Updated automatically as usage shifts.
- Old junk? Uncovered, retagged, and handled without drama.
This isn’t just an ITAM best practice — it’s how you future-proof your asset visibility, cut down on false alerts, and finally give your FinOps and SecOps teams a tagging layer they can trust.
We’ve cleaned up tagging fires, dodged misrouted incidents, and even saved real $$$ — all because our tags now evolve with our infra.
And once more ITAM best practice on tagging 👇
Define a clear tagging asset management policy
Not the “oh, we tag stuff sometimes” kind. I mean real, structured, no-room-for-shrugs tagging. Because if I had a dollar for every time someone asked, “who owns this thing?” and got dead air in response, I’d have enough budget to fund a whole DR region.
We were spinning our wheels. Tags were there — sure — but every team did their own thing. Some labeled by project, others by vibe. Finance tried to pull cost reports and got a spaghetti mess. Security asked for a list of unpatched VMs and ended up on a scavenger hunt.
The problem wasn’t the lack of tags. It was the lack of policy.
So here’s the move — a tagging strategy built on best practices for IT asset management. One that actually works across hybrid, multi-cloud chaos.
How to implement this ITAM best practice
✅ Environment (Prod, Dev, Test, Sandbox, DR). Because no one wants to autoscale a staging cluster like it’s Black Friday traffic. Tagging the environment helps us apply the right guardrails where it counts.
Environment = Prod? That baby gets alerts, backups, and VIP treatment.
✅ Owner (Team, Person, Bot). Every CI needs a name on the lease. Whether it’s Owner = SecOps or Owner = YuliiaK, someone’s gotta be accountable — especially when patch Tuesday rolls around and the zero-days are flying.
✅ Cost Center (Project, Client, Dept). Cloud bills don’t lie. But they do get confusing fast without tags like CostCenter = CustomerSuccessInitiative. This one’s Finance’s favorite — and it saves DevOps from those awkward budget syncs.
✅ Compliance Level (HIPAA, PCI, ISO, InternalOnly). Because running a database without Compliance = HIPAA when it holds medical records? That’s how you land in audit hell. Tag it right and your controls kick in automatically.
This setup took us from reactive fire drills to proactive asset intelligence. Now when someone asks “what is this?” we actually know. No chasing. No guessing. Just clean data, full visibility, and a tagging policy that actually scales with us.
If you’re serious about best practices for IT asset management, this is the hill to build your tagging kingdom on. Let’s not fight chaos with sticky notes anymore.
Automate remediation for untracked assets
You know that split-second panic when a critical vulnerability scan lights up red — and the asset it flagged? No owner. No tags. No record in the CMDB. Nada.
Happened to me last quarter. It was a database fully exposed to the internet, default creds, no MFA, and billing had zero idea who approved it. The only thing louder than the alert was the compliance report that followed: CIS AWS 1.14 – MFA not enabled.
And here’s the kicker — it wasn’t just one forgotten DB. It was part of a pattern. An entire layer of ghost assets: costing money, slipping past controls, and inviting risk in like it's got a standing invite.
That was our wake-up call. Now? We’ve got a no-mercy workflow for untracked assets.
How to implement this ITAM best practice
2️⃣ Always-On asset discovery. If it breathes cloud, we see it.
- Discovery across AWS, Azure, GCP — synced straight into the CMDB and ITAM process.
- Anything missing tags or ownership? Flagged.
- Shadow IT doesn’t get a head start.
2️⃣ Define the “review or remove” criteria. Not every orphaned asset is evil — but every one gets evaluated.
- We scan for missing tags, skipped security steps, or config gaps.
- CIS benchmarks baked in — like Azure 6.5 for security group oversight.
- If it’s noncompliant and unmanaged? It’s on the clock.
3️⃣ Let the workflow eat the work. Cloudaware Workflows took us from alert fatigue to action.
- Missing tags? Auto-filled from team metadata.
- No owner? Slack and email notifications go out immediately.
- Unauthorized? Decommission flow kicks in, no hesitation.
- Public-facing without controls? Access shut. Fast.
4️⃣ Audit on autopilot. This is where the IT asset management best practices lock in.
- Recurring scans? Yep.
- Remediation logs for compliance? Built-in.
- Monthly report showing how much we saved killing off unapproved infra? Oh yeah.
Since we turned this on, no more “who deployed this?” drama. Every untracked asset gets one of three fates: tagged, owned, or terminated. And when compliance asks for evidence? It’s already in the dashboard.
Cloudaware’s low-code automation means we sleep better. Because in this cloud game, it’s not the fire you see — it’s the one hiding in the shadows that burns the loudest.
Read also: Top 10 Enterprise Asset Management Software: Features & Pricing
Avoid unnecessary IT expenses
Let’s be real for a second. Most teams don’t blow their budget on one big mistake — they bleed it out slowly through a hundred small ones. It’s not negligence, it’s visibility. When your assets live across clouds, accounts, and regions, the real cost of what’s running, what’s idle, and what’s totally abandoned gets buried in the chaos. And that’s exactly where IT asset management (ITAM) comes in.
Good ITAM isn’t just a spreadsheet of assets.
It’s a system that prevents overspending, streamlines accountability, and gives you total control over what’s deployed, who owns it, and what it’s costing you — down to the last tagged byte.
But when you skip the fundamentals? That’s when budgets crack, teams scramble, and zombie workloads rise from the dead.
Let me tell you a little DevOps horror story. Solid team. Smart folks. Thought they had their IT asset management handled. Then Finance came knocking with that tone — you know the one — “Hey, why is our cloud spend triple what we forecasted?”
What we found? A graveyard of expensive mistakes:
- Zombie instances still running after QA wrapped — no shutdown, no tagging, no ownership.
- Orphaned volumes hoarding data no one touched in months.
- Beefy VMs clocking in at 2% CPU but costing like a sports car.
- Duplicate services in AWS and Azure because nobody checked what already existed.
By the time anyone blinked, thousands were already gone. Not spent — lost.
How to implement this ITAM best practice
So if you’re wondering how to do IT asset management that actually protects your budget, here’s the play:
Step 1: Get eyes on every dollar. Cloudaware’s FinOps module gives you real-time cost visibility across AWS, Azure, GCP, and even your on-prem zoo.
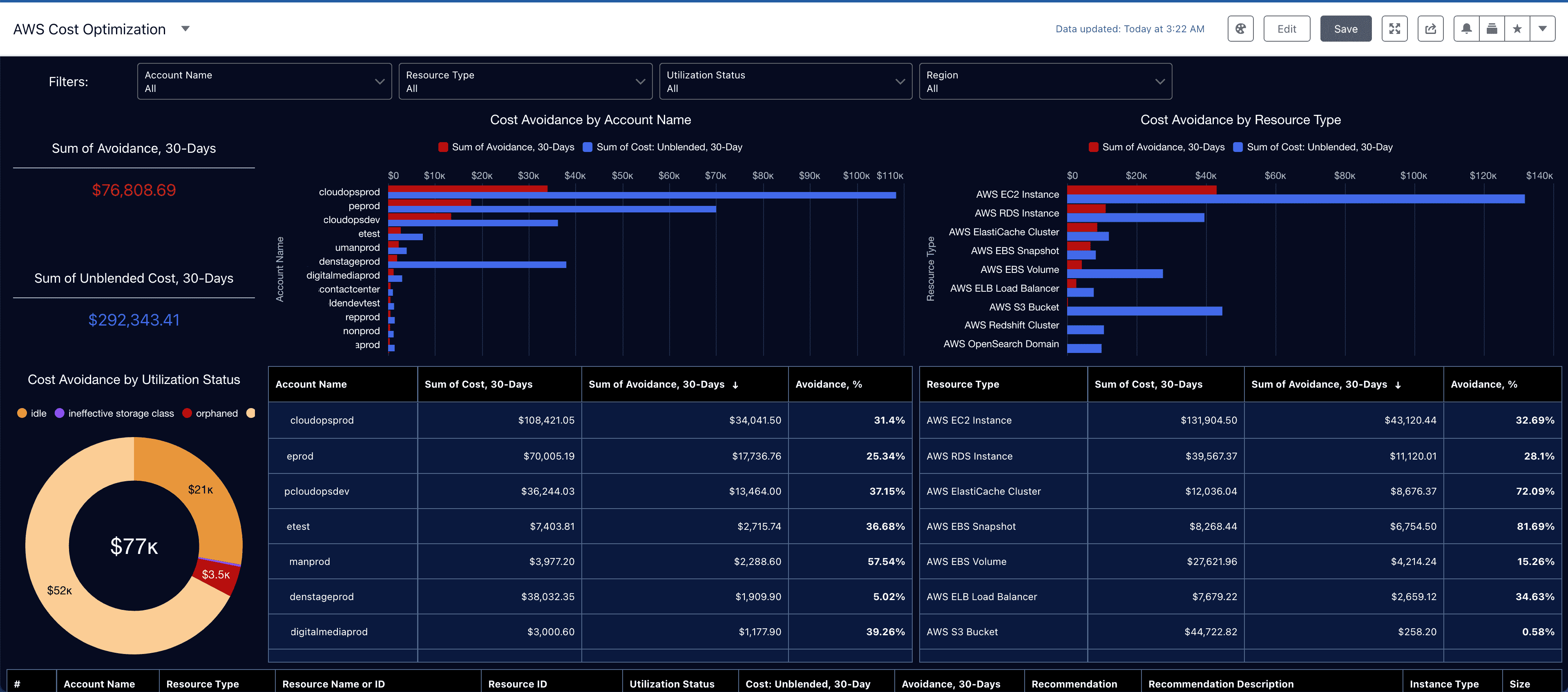
✅ Slice spend by project, team, or product.
✅ Spot anomalies before the QBR panic kicks in.
✅ Auto-tag everything so mystery line items become a thing of the past.
Step 2: Fix the waste before it hits the bill. We don’t just watch the numbers — we clean up the mess behind them.
✅ Identify idle VMs and downshift them automatically.
✅ Sniff out orphaned storage and zombie resources, and shut them down without drama.
✅ Auto-scale based on demand so you’re not paying for air.
Step 3: Lock in smart budgeting. Nobody likes surprises — unless it’s coffee showing up at your desk. So we bake budget controls into every asset decision.
✅ Alerts when teams start trending over budget.
✅ Forecasting based on real historical spend — not wild guesses.
✅ Chargeback reports that spell out exactly who’s burning cash, and why.
✅ “Field required” for cost ownership — no tag, no deploy. Period.
If you’re serious about best practices IT asset management, this is it. No more waiting for Finance to play detective. Cloudaware makes cost awareness part of your engineering culture — like CI/CD, but for your wallet.
Link IT asset data to Incident Management systems
You know that pit-in-your-stomach moment when alerts start popping off in Slack and PagerDuty, and everyone’s asking: “What just broke?” Been there. Sat in on that war room. And let me tell you — if your team doesn’t have asset context at their fingertips, you’re not fixing the problem... you’re guessing.
Let me walk you through a real one: A high-traffic app crashed out of nowhere. Critical path. PagerDuty exploded. Everyone jumped in, but nobody knew what the app was tied to. No one had a clean view of the impacted infra.
And since the CMDB wasn’t connected? It was pure chaos.
🚨 No linked asset data = no context.
🚨 Engineers wasting hours digging through logs just to ID what was involved.
🚨 The wrong folks got paged, response dragged, and users noticed — fast.
By the time they found the root cause? Damage done. Revenue missed. Trust dented.
How to implement this ITAM best practice
So how do we make sure that never happens again?
Step 1: Build a single source of truth. Cloudaware pulls in asset data from AWS, Azure, GCP, Alibaba, Oracle Cloud, VMware, Kubernetes, and on-prem — all in one CMDB. This isn’t just an inventory list; it’s living, breathing visibility.
✅ Follow IT asset inventory management best practices to keep assets clean, tagged, and fully mapped.
✅ Understand service-to-service dependencies before they become liabilities.
✅ Apply mandatory tags and labels, so nothing runs unaccounted.
Step 2: Sync CMDB with PagerDuty for real-time response. Here’s where it gets good: Cloudaware integrates directly with PagerDuty. So when an alert hits, it comes packed with full asset context.
✅ The impacted CI is already tagged — no scrambling to figure out what’s affected.
✅ Escalation rules fire based on infra context — the right team, the first time.
✅ Every incident gets linked back to past events on that same asset — patterns, trends, all there.
Step 3: Move from reactive to proactive response. We’re not just closing tickets. We’re tightening the whole response loop.
✅ Use historical incident data tied to assets to spot failure patterns early.
✅ Adjust escalation paths based on what’s actually breaking, not what might break.
✅ Cut MTTR by slashing the time spent “figuring it out” — because you already know where to look.
With Cloudaware’s CMDB and PagerDuty in sync, you're not just reacting to fires — you're building muscle memory across your ops.
This is what IT asset inventory management best practices look like when they actually work in the real world.
Protect your assets from theft
“We didn’t even know it was gone.”
That’s what the CISO of a fast-growing SaaS company said when they discovered a compromised IAM role had been silently exfiltrating sensitive data for weeks.
It started with an unsecured S3 bucket — one that no one knew existed. A developer had spun it up for testing, but because it was missing proper tags and CMDB tracking, it never got secured. No MFA, no access restrictions, no logging.
An attacker found it, created a rogue IAM role, and slowly siphoned out customer data. When Security finally caught it, the damage was done. Compliance teams flagged violations of CIS AWS 1.14 – Ensure MFA is enabled for all IAM users, and leadership had to disclose a security breach.
The worst part? The data theft could have been prevented — if they had full asset visibility and proactive security enforcement.
How to implement this ITAM best practice
1️⃣ Lock it down like a pro
Cloudaware gives you automated guardrails, so misconfigurations don’t slip through the cracks.
- Auto-detects policy violations — think public S3 buckets, IAM roles with God-level access, and anything that violates your baseline.
- Enforces CIS benchmarks across cloud services — so your security posture isn’t just “best effort,” it’s “audit-ready.”
- Revokes or tightens permissions on the fly if something looks shady. No lag, no manual hunt.
- Applies mandatory security labels and access controls across all assets — so nobody’s deploying anonymous resources on your watch.
2️⃣ Know when something moves
Cloudaware integrates with your SIEM (Splunk, Sentinel, whatever your flavor is) to keep one eye open 24/7.
- You get the full trail — every time someone touches a CI, Cloudaware logs it. Who made the change, when it happened, where it came from. No more mystery edits.
- If someone starts messing with roles, bumps up privileges, or moves data around in ways that don’t make sense — you’ll know right away. Alerts hit before the damage does.
- And instead of jumping between consoles trying to figure out what’s secure and what’s exposed, you’ve got one clear view across all your clouds and assets. No toggling. No tab chaos.
Because when security is part of how you run your assets — not just how you react to problems — you don’t leave doors unlocked. Cloudaware keeps the protection baked in, always watching, always in context, always a step ahead.
Read also: 15 DevSecOps tools. Software features & pricing review
Leverage application-level monitoring
Tagging is a good start. But if you’ve ever tried to pull a clean cost report or track down what’s burning cloud budget by team, you know — tags alone won’t cut it.
A DevOps crew I worked with had textbook tagging hygiene. EC2s, RDS, Lambdas — labeled to perfection. Owner, environment, department. The works.
Then Finance came in hot: “Can you break out infrastructure costs by department… like, today?”
Cue panic. Because all those tags? Scattered. No structure, no ownership logic, and no clean way to say, “Here’s what Sales owns, here’s what Support runs, here’s what’s blowing up our AWS bill.”
So they used Virtual Applications in Cloudaware to flip the script:
📌 Finance App → EC2 (Billing Engine), RDS (Transaction DB), API Gateway (Payments)
📌 Support App → K8s Cluster (Chatbot), DynamoDB (Ticket Storage), SNS (Alerts)
Now Finance had clear spend by team. DevOps could troubleshoot by app stack, not chase rogue instances. And suddenly, IT asset management best practices weren’t theoretical — they were operational.
What Else Can You Do with Virtual Applications?
🔹 Group by department (HR, Sales, R&D) to expose per-team costs and spot inefficiencies
🔹 Map full app stacks — clusters, databases, functions — into one logical view
🔹 Segment compliance-critical assets (PCI, HIPAA) to enforce tighter controls
🔹 Define DR apps across regions to validate failover strategies
🔹 Build isolated, customer-specific environments — better security, easier SLAs
How to implement this ITAM best practice in Cloudaware:
1. Create a Virtual Application
Head to Navigator → Applications → New Cloudaware Application
Name it. Define your tiers (Web, API, DB — whatever fits your architecture logic).
2. Attach Resources
Pick the assets — instances, storage, services — and assign them to the right tier. This is where structure replaces guesswork. You’re not dragging icons around — you’re applying IT asset management best practices that scale.
3. Automate It
Go to Setup → Process Automation → Flows and define rules so any new asset gets auto-attached to the right app. No more manual updates. No more “Why isn’t this tagged?” headaches.

With Cloudaware Virtual Applications, you’re not chasing assets. You’re managing systems.
And that’s the whole point of doing IT asset management best practices right.
Because look — without structure, hybrid cloud becomes a liability. Shadow IT slips through. Costs spiral. Security gaps multiply. And every audit turns into a blame game.
That’s why companies like Coca-Cola, Schwab, and NASA run Cloudaware CMDB — to make structure the default.
Summary on how to do IT asset management
Here’s your no-fluff checklist of IT asset management best practices — in the order teams actually run them. Use it to sanity-check your process fast: if you can’t produce the “Example output” for a step, that’s the exact gap to fix next.
| Best practice focus | What to do | What “done” looks like |
|---|---|---|
| Define scope + sources | List every environment you must cover: AWS/Azure/GCP accounts, on-prem, endpoints, SaaS, core apps. | Scope register with account/subscription IDs, data sources, owners, onboarding status. |
| Continuous discovery | Turn on always-on discovery and capture IDs, tags, relationships, first/last seen. | New asset feed (last 24h) with asset ID, type, account, region, owner tag, last seen. |
| Normalize identity | Set one unique key per asset type and dedupe across sources. | Duplicate report + merge rules; each resource maps to one CI record. |
| Build an authoritative inventory | Enforce a minimum asset record: owner, service, environment, lifecycle, cost center, last seen. | Inventory completeness dashboard (% assets with required fields). |
| Ownership + tagging enforcement | Require tags at creation and map owners to real teams/on-call rotations. | Orphan list (missing owner) + auto-ticket routing to the right team. |
| Reconcile inventory with billing | Weekly: every billed resource must map to a CI with owner + purpose. | Unmapped spend report ($ and count) + list of resources “on bill, not in inventory.” |
| Detect idle + stale assets | Apply thresholds by asset class (idle compute, unattached storage, unused IPs). | Idle candidates queue with signals (CPU/network/last attachment) + recommended action. |
| Quarantine before deletion | Mark “Pending Deletion,” notify owner, set 7–14 day timer, snapshot if required. | Quarantine log with timestamps, notifications sent, expiry date, snapshot ID. |
| Automate cleanup + prevention | Auto-close unclaimed assets; enforce dev/test expiry and policy checks on ingest. | Auto-remediation summary (terminated assets, saved cost estimate, exceptions opened). |
| Audit + compliance evidence | Store proof: last seen, change history, ownership, exceptions, remediation actions. | Audit pack export: asset history + ownership + policy status + remediation trail. |
| Lifecycle + disposal governance | Track EOL/EOS, warranty/support, decommission, wipe/dispose for physical assets. | Lifecycle status report (EOL/EOS, pending disposal, custody chain, wipe certificate links). |
| KPIs + weekly ops review | Review 3–5 KPIs and assign owners for exceptions. | Weekly ITAM ops scorecard: orphan rate, reconciliation match rate, unmapped spend, time-to-clean, exception age. |
To implement this you don’t need more tools. You need your cloud to make sense. And that’s what Cloudaware does 👇
Implement IT asset management best practices easily with Cloudaware
Managing IT assets across multiple clouds and on-prem shouldn’t feel like a never-ending game of hide and seek — but without the right system, that’s exactly what happens. Shadow IT, cost overruns, compliance gaps — pure chaos.
That’s why global enterprises like Coca Cola, Charles Schwab, and even NASA rely on Cloudaware CMDB to implement best practices for it asset management.
Implement IT asset management best practices easily with Cloudaware:
🔹 Live asset tracking across every cloud and on-prem stack — all in one unified dashboard you can actually search without crying.
🔹 Automated discovery that finds every EC2, GKE pod, orphaned disk, and zombie VM that’s been ghosting your cost reports.
🔹 FinOps baked in — see spend by team, project, or product before Finance calls you into another “budget conversation.”
🔹 Compliance + incident context in the same view — map assets to policies, frameworks, and real-world alerts. When something breaks, you know where it lives and what it impacts.
🔹 Auto-tagging that works like a bouncer — you set the rules, Cloudaware enforces them based on how your workloads actually behave.
🔹 Enriched CIs packed with metadata: compliance status, dependencies, known vulnerabilities, and cost metrics — so every asset tells a full story, not just its name.
What you get? Full visibility. Tight security posture. Asset chaos turned into clean, trackable, automated flow.
That’s how to do IT asset management without burning out your team or blowing up your budget.