






You know that moment when someone asks, “What does this Lambda connect to?” and five people open five different tools? That’s when you realize your infrastructure has ghosts — orphaned resources, undocumented dependencies, and zero traceability across clouds.
That’s the cost of ignoring ITSM configuration management. Without a solid config manager strategy, every change feels like a gamble, and every incident escalates fast.
This guide gives you the clarity you’ve been chasing:
- Why config chaos kills uptime and team velocity
- How to design a cross-cloud config process that actually sticks
- Lessons from teams wrangling thousands of CIs in the wild
- The best tools to anchor your configuration management strategy
It’s time to give your team answers instead of guesswork.
What is ITSM configuration management
ITSM configuration management is the practice of tracking, structuring, and keeping tabs on every single CI — every configuration item that makes your environment tick. Not just assets, but the actual context: which IAM policy hits which Lambda, what’s downstream from that S3 bucket, which container relies on a legacy DNS entry someone swore was gone.
It’s not about building a pretty list — it’s about knowing how all your moving parts connect, so when something goes sideways, you don’t.
At the center of all this? The CMDB. But not one of those static, rotting spreadsheets someone updates once a quarter. I’m talking real-deal, dynamic, synced-up ITSM CMDB software.
Something your configuration manager can wire into the stack — Terraform state, Git commits, AWS Config, Azure Resource Graph, Kubernetes manifests, even those weird edge cases in your on-prem. It’s all gotta flow in clean, because your agile team moves too fast for stale config.
Here’s how it looks in the wild:
You’re mid-sprint, juggling two projects, and suddenly a production service goes dark. It’s chaos — Slack’s blowing up, Datadog’s screaming, and no one knows where the change landed. You pop open the CMDB. Boom. That CI? Tied to an SNS topic, which hooks into a webhook, which failed because someone pushed a configuration change without review. You trace it in minutes. No guessing, no praying to the logging gods.
That’s why configuration management ITSM isn’t optional anymore:
- It shortens MTTR on your worst days
- It protects you from invisible vulnerabilities
- It gives your automation and orchestration something real to work with
And when infra stretches across five teams, three clouds, two continents, and one stubborn legacy system that no one wants to touch — this is the glue.
The configuration manager becomes your behind-the-scenes hero. Connecting the dots between assets, services, dependencies, and risk. Feeding real-time intel into your incident, change, and service management pipelines.
This is how modern ITSM is done. Real data, clean config, and CMDBs that actually help — not just checkboxes for audits.
You don’t need more dashboards. You need something you trust when the fire starts. That’s the role of ITSM configuration management. And yeah — when it’s working right? It’s game-changing.
Read also: What is & How Does Asset Management Work Across Hybrid IT?
Key objectives it focuses
If you’re running hybrid infra and don’t have a handle on your config data, it’s only a matter of time before something blows up — and no one can trace what depends on what. That’s where ITSM configuration management steps in. Not as a box to check, but as the backbone of clean service management.
Here’s what solid configuration management ITSM actually helps you pull off — especially when your world moves fast and breaks often:

🎯 Keep configuration data accurate and reliable
Your CMDB is your reality check — not just a record of things, but your go-to when stuff hits the fan. Every asset, from EC2s and GKE clusters to that one on-prem DB nobody admits to owning, lives here — with all its dependencies.
You’ve been there: An incident takes down a critical service. You check the CMDB, trace it to a misconfigured load balancer, and see it’s tied to an API deployed last night. You fix it, fast — without pinging five teams.
🎯 Track and manage every asset, everywhere
This isn’t about static inventory. It’s about knowing how things connect. On-prem, multi-cloud, SaaS — every asset, every service, and every relationship is mapped. So when you make a move, you’re not flying blind.
You’re mid-project: updating a legacy app that’s tied into three other systems through old middleware. Your CMDB maps it all out, so you avoid breaking downstream services and keep the rollout smooth. That’s config clarity in action.
🎯 Protect the integrity of configurations
Bad configuration changes happen. But with proper change management in place, they don’t have to become outages. Your ITSM platform flags risky changes, checks compliance, and ties everything back to the CI and the change request.
Scenario: someone tries to tweak a security group on a production VPC. The CMDB flags it as critical and blocks the change. You don’t lose sleep — or uptime.
🎯 Manage the entire lifecycle of every service and asset
From provisioning to retirement, every asset and service goes through a tracked, repeatable lifecycle. Baselines are set. Changes are logged. Drift gets flagged automatically. And yes, it works across cloud and on-prem.
Cleanup day: you’re decommissioning legacy infra. The CMDB helps you identify which apps, users, and APIs are tied to that aging Windows box. You migrate cleanly — no ghost dependencies, no angry PMs.
🎯 Keep a complete history of configurations
Need to know what changed last sprint? Or what your infra looked like last Black Friday? Your CMDB has it. That historical data helps with audits, scaling plans, and forecasting what’s coming next.
Getting ready for holiday surge: You check usage patterns in the CMDB from last year and use them to inform your autoscaling and failover strategy. The cloud management platform flexes — users never notice. Your team? Hero status.
ITSM configuration management isn’t just for auditors or ITIL folks. It’s your tool for real visibility, real traceability, and real control. It’s how you give your team — whether you’re a configuration manager, cloud architect, or DevOps lead — the ability to respond fast, automate with confidence, and scale smart without taking on unnecessary vulnerability.
It keeps your projects moving, your agile teams in sync, and your orchestration running clean. And honestly? It’s the difference between being reactive and actually running the show.
Now let’s talk about what this does for your team’s day-to-day flow 👇
Read also: Everything you should know about IT Asset management in 2025
Top 5 reasons why companies implement ITSM config management
Terraform’s pushing changes, someone’s doing hotfixes in the console, Jenkins is mid-deploy — and your CMDB hasn’t caught up in days. Ownership? Blurry. Impact analysis? Slow. Then a core service goes down, and suddenly everyone’s in war-room mode trying to trace a config that no one updated. That’s the tipping point. That’s when teams finally say, “We need real ITSM configuration management.” Something that makes change management, incident response, and CI relationships actually work. No more guessing. No more finger-pointing. Just clean visibility.
The five benefits I’m about to share come straight from working with ops teams across multi-cloud environments — where config chaos is the default, and clarity is earned.
1. Visibility is what keeps outages short and fingers calm
Most outages aren’t wild explosions — they’re quiet chain reactions from missing context. A CI gets updated, and suddenly a downstream service breaks because no one saw the link.
That’s why smart teams use ITSM configuration management to map dependencies, track ownership, and surface change impact before rollout. In Cloudaware, every CI — from EC2s to VPNs to Terraform modules — is traceable, tagged, and linked to its blast radius.
One of our multi-cloud customers — running across AWS, Azure, and on-prem — cut unplanned outages by 60% after rolling this out. Why? Because change reviews finally had data: what’s connected, who owns it, and what breaks if you touch it.
Less guessing. More control. And way fewer “whoops” moments at 2 AM.
2. New hires shouldn’t need a treasure map to find context
Onboarding into a messy setup is brutal. The config’s unclear, half the systems aren’t documented, and ownership is a guessing game. If your CMDB is solid, it becomes the system of record — and your configuration manager’s best friend.
🛠️ Citrix was deep in that mess, with 250 AWS accounts and 1.5 million assets. Before Cloudaware, onboarding was slow and painful. After? New engineers could explore infra through the CMDB, trace every service, see relationships, and find CI owners — all from day one.
Result? Ramp-up time dropped by 28%, and the team stopped burning cycles explaining the basics.
3. Real-time compliance, no manual cleanup
Compliance isn’t a one-time checklist. It’s a constant background process. But if it’s not wired into your config management workflows, it turns into chaos fast.
That’s why the smart move is baking compliance into your CMDB setup. Cloudaware pulls real-time data from your assets, checks them against your org’s policies, and flags issues as they happen — not three weeks into audit prep.
Element of the compliance tracking in Cloudaware. Request a demo to see it live.
We saw this with Warner Bros. Discovery. 100+ cloud accounts, zero central control. Once Cloudaware’s Compliance Engine plugged into their CMDB, they activated 300+ rules across AWS, Azure, and GCP — instantly.
They slashed exception-handling time by 48%. Fewer Slack threads. Fewer “who owns this?” emails. More focus on actual risk, less chasing ghosts.
4. Cloud cost control starts with clarity — not hope
Budgets don’t blow up from one big mistake. They bleed out slowly — through idle assets, orphaned resources, and services no one remembers owning.
The fix? Visibility that ties usage to ownership. When your CMDB links every compute node, database, and reserved instance to a real business service and team, you finally see where the spend is coming from — and what can go.
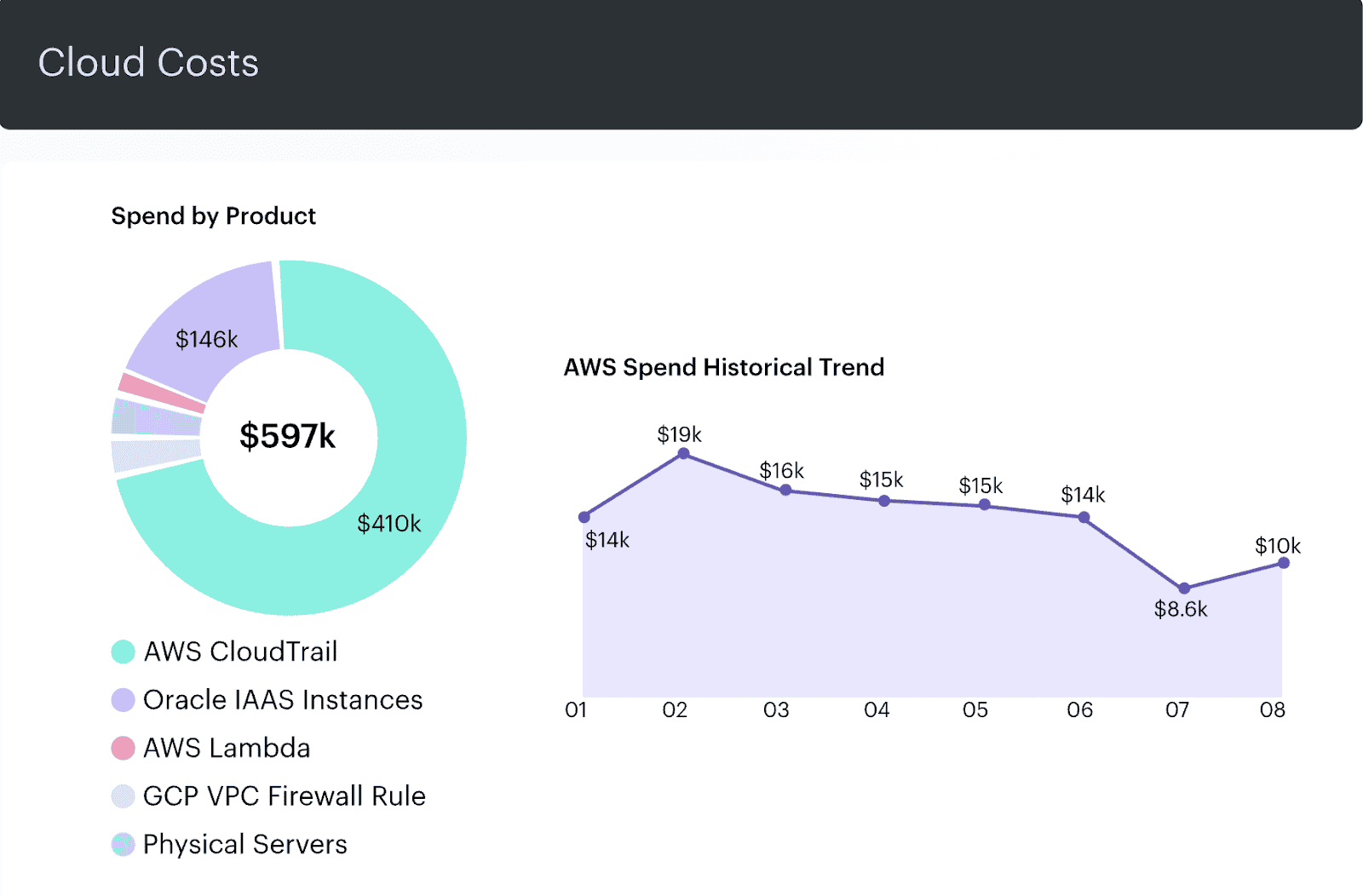
Element of the FinOps report in Cloudaware. Request a demo to see it live.
Citrix connected Cloudaware’s FinOps automation engine to their config data, and the results were brutal: $500K in annual waste. We’re talking unused RIs, idle cloud software, and environments with no traceable purpose. The kicker? Most of it had tags. Just not the right ones.
Now, every dollar is traceable. If it’s not tied to an owner, a workload, or a lifecycle state? It’s flagged, reviewed, and — if needed — shut down.
That’s not just optimization. That’s ITAM with teeth.
5. Security and ops finally speak the same language
A security alert without context is just noise. But tie it to a CI, a change, an owner, and a service, and now it’s actionable. That’s where incident response levels up.
🛠️ NASA connected their security stack to their Cloudaware CMDB — syncing incident and Vulnerability Management data straight into config records. Now when an alert triggers, both ops and security teams see the full picture: what was touched, when, by whom, and what it’s tied to. No more chasing ghosts. Just clean triage.
So yeah, ITSM configuration management isn’t about tidying up a spreadsheet.
It’s how real teams make their service management systems work under pressure. It keeps your infra resilient, your engineers sane, and your operations scalable — even when your environment spans continents, clouds, and compliance regimes.
If you’re ready to stop flying blind and actually own your environment, this is where it starts.
ITSM configuration management process flow
Theory’s fine — but it doesn’t fix broken configs at 2 a.m. Let’s walk through what ITSM configuration management really looks like when you’ve got thousands of CIs, constant changes, and teams moving fast — like Coca-Cola does.
We helped their global platform team bring order to config chaos. Here’s how the process unfolded — not on paper, but in real environments, with real constraints, and very real impact.
1️⃣ Continuous discovery — because you can’t manage what you can’t see
Configuration management ITSM begins with continuous discovery. This is where you identify every configuration item, map it to ownership, and feed your CMDB with real-time data. The goal? Visibility across all your platforms — cloud, on-prem, hybrid — and every layer of your infrastructure.
At Coca-Cola, we connected Cloudaware’s ITSM CMDB software to AWS Organizations, Azure subscriptions, and on-prem VMware. No agents. Just API-level access. Within two days, they had full visibility into EC2s, RDS, Azure VMs, containers, NSGs, IAM roles — every asset, every resource, every forgotten dependency.
Inventory dashboard in Cloudaware. Request a demo to see it live.
One of the first wins? Uncovering a legacy EFS volume in APAC tied to a retired service — still costing money and still reachable from the public internet. Discovery gave them more than visibility — it gave them back control.
2️⃣ CI Structuring — turn raw data into a working system map
Once discovery loads your CMDB, the real work starts: structuring. This is where you assign CI classifications, align them with owners, relate upstream and downstream connections, and map them to real services. Otherwise, you’re just cataloging clutter.
For Coca-Cola, structuring involved standardizing tags, classifying configuration items, and mapping dependencies across service configurations. From ALBs linked to ECS clusters to IAM roles inherited across dev and prod — we turned their raw inventory into an intelligent CMDB model.
The result? Their service management teams could trace the full context behind any change or incident. No more scrambling. No more “who owns this?”
3️⃣ Baselines — because if you don’t define “healthy,” you’ll never catch drift
Baselining is a pillar of ITSM configuration — it defines what “correct” looks like. Once that’s in place, any deviation signals risk. Baselines drive security, compliance, and clean operations.
At Coca-Cola, we deployed over 500 baseline policies tied to real-world platform expectations. Encryption? Mandatory. Flow logs? Enforced. Tagging? Strict. AMI usage? Controlled. IAM roles? Scoped.
Cloudaware’s baseline engine flagged drift the moment a policy was violated. Someone forgot a backup tag? Or used a public AMI without approval? It showed up in the CMDB, tied to the configuration state of that asset, and assigned to the right manager. Issues didn’t hide. They got actioned.
4️⃣ Change Management — approvals backed by real impact data
Change management isn’t about slowing teams down — it’s about making configuration changes traceable, assessable, and auditable. When tied to a living CMDB, it becomes a precision tool.
Before Cloudaware, Coca-Cola’s change reviews relied on best guesses. Risk? Unknown. Impact? Assumed. Owners? Often missing. After we integrated with ServiceNow, every change linked directly to the affected CIs. Reviewers could see what services would be impacted and what policies might be violated.
Critical changes triggered review chains. Routine updates moved fast. And rollback planning? Built into every ticket, thanks to full service configuration mapping in the ITSM CMDB software.
5️⃣ Configuration Monitoring — because drift happens silently
Monitoring isn’t just for uptime. In strong configuration management ITSM practices, you monitor for drift, policy breaks, and unauthorized changes — because those are the quiet killers of stable environments.
Coca-Cola’s team set up real-time alerts for port exposure, privilege creep, tag deletion, and baseline violations. When a sandbox VPC exposed port 22 to the world, the CMDB triggered an alert — tied it to the CI, the change record, the user, and the impacted service.
This wasn’t noise. It was clean signal. And for the manager responsible for that environment, it meant fewer surprises and faster remediation before small problems turned into major incidents.
6️⃣ Reporting & Audit — connect data to decisions
Once everything else is in place, ITSM configuration management pays off in reporting. It’s where CMDB data becomes decision support — for finance, GRC, engineering, and leadership.
Coca-Cola’s teams pulled live dashboards showing:
- Service health and asset compliance
- Vulnerability exposure by CI class
- Change volume by region and team
- Cost attribution by tag, environment, and service configuration
- Audit trails across all tracked configuration changes
No one had to compile spreadsheets. No one guessed. From CFOs to SecOps to service managers, everyone pulled insights directly from the same real-time config source.
Ready to tame the chaos and take control? Let’s make it happen.
8-steps plan on how to implement ITSM config management
Rolling out ITSM configuration management doesn’t have to be a grind — not when you’ve got the right game plan. I’ve seen teams go from chaotic change logs and blind spots in their CMDBs to clean, connected environments in just a few sprints. The secret? Structure, automation, and tight alignment between ops, security, and service owners.
Baked with years of Cloudaware ITAM pros experience working with multi-cloud enterprise companies, here’s the 8-step rollout plan we use to make config clarity a reality 👇
1. Set clear goals and get buy-in
Before you even think about discovery or tagging policies, you’ve got to align on the “why.” Because configuration management ITSM isn’t just another process — it’s the backbone of how your team controls, secures, and understands your stack.
So what’s the outcome you actually care about?
- Is it faster, cleaner change management?
- Cutting down audit prep from weeks to minutes?
- Building traceability between CIs, owners, and services?
- Or just having a reliable, real-time CMDB your team actually trusts?
Here’s how I’ve seen it work: platform teams map their top 3 daily headaches — config drift, noisy reviews, zero CI accountability — and reverse-engineer the goals from there. Security flags blind spots in policy enforcement or IAM sprawl. Leadership asks for clean dashboards, audit-ready reports, or compliance by design.
When all three groups (ops, security, and leadership) agree on where config clarity is needed most, you’re not just implementing ITSM configuration — you’re solving real friction with purpose. And that alignment makes every step after way smoother.
2. Start with discovery and inventory
With Cloudaware, that means connecting all your cloud providers via native API integrations — AWS Organizations, Azure Management Groups, GCP projects — no agents, no babysitting. Just instant CI ingest from source-of-truth platforms like AWS Config, Azure Resource Graph, and Google Asset Inventory.
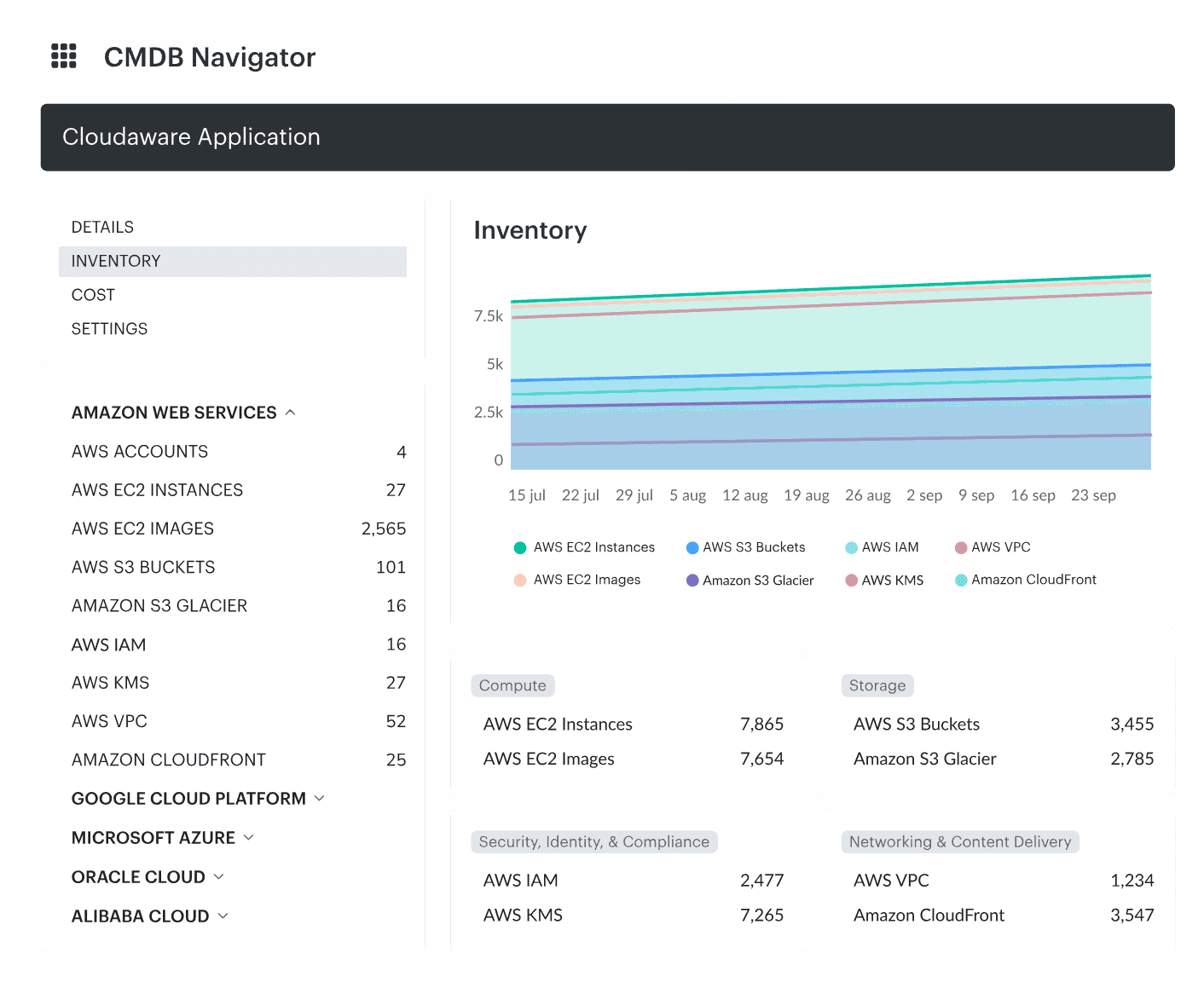
Element of the Inventory dashboard in Cloudaware. Request a demo to see it live.
For on-prem? That’s where Breeze Agent comes in. Drop it into your vCenter or bare metal, and it feeds the CMDB with structured data on VMs, physical boxes, IPs, and even OS-level configs.
Element of the on-prem inventory report in Cloudaware. Request a demo to see it live.
Every discovered asset — whether it’s an EKS cluster, a Lambda function, or a forgotten VMware image — lands in your ITSM CMDB software with lifecycle state, ownership, service relationships, and provisioning metadata.
At this stage, we’re not enforcing rules or tagging baselines. This is pure visibility. You walk away with a living inventory that reflects the current state of your hybrid stack — no gaps, no guesswork. That’s your launchpad for configuration management ITSM done right.
3. Organize and categorize your assets
Once discovery is done, your CMDB isn’t empty anymore — it’s overflowing. You’ve pulled in EC2s, Azure Functions, GKE clusters, IAM policies, load balancers, shared VPCs, even some dusty unmanaged VPN configs from your on-prem edge. All of it — mapped into Cloudaware.
But raw inventory alone won’t help you during an incident or while prepping for a compliance audit. Now it’s time to organize and structure that data — so it reflects how your environment actually runs.
Cloudaware’s CMDB categorizes your CIs automatically by type, platform, and region — but that’s just the starting point. What makes it powerful is what happens next:
- You define ownership using metadata (
Owner,Team,OpsContact) and tagging policies - You apply environment classification (
prod,dev,qa,sandbox) to group by deployment stage - You set up business context through custom tags like
BillingCode,RecoveryTier, orComplianceScope - You group CIs into Virtual Applications — logical service groupings that show everything a service touches
Let’s say your platform team owns the Order-Fulfillment-Core stack. It’s not just a bunch of compute. It’s a virtual app made up of: 2 ECS clusters, 1 shared RDS, 6 Lambdas, 3 internal APIs, 1 SQS queue, and IAM roles scoped to each CI.
All of that is mapped as a virtual application group inside Cloudaware. You assign ownership to the DevOps team, link it to the RetailOps cost center, and flag it as RecoveryTier 1. Now when a configuration change hits that queue or a change request touches the DB, your team has one place to investigate, one context for approvals, and one clean view of service configuration.
Over at Warner Bros. Discovery, this approach let them clean up and structure over a million CIs. They enforced consistent tagging (Environment, Owner, ServiceName), and mapped out hundreds of virtual apps across their AWS and Azure estates. The result? Better incident triage, faster onboarding for new engineers, and a 39% boost in policy coverage — just from structured asset organization.
4. Baseline configurations to define the standard
Setting baselines is one of those deceptively powerful moves in ITSM practices. On the surface, it sounds simple: define what “healthy” looks like for your infrastructure. But what you’re really doing is locking in standards that make everything else — from change management to incident resolution — faster, cleaner, and way less stressful.
When we worked with Coca Cola, they had platform teams running infra across multiple AWS accounts, Azure regions, and some hefty VMware clusters. Everyone had slightly different practices — and config chaos was creeping in. So we sat down with their ops, GRC, and security teams and turned tribal knowledge into hard baselines. These covered things like:
- Mandatory encryption for every storage service
- Tagging rules for cost center, environment, and business unit
- IAM roles scoped with least privilege + expiration tags
- Specific AMI versions for each workload class
- Auto-expiration and backup requirements for non-prod systems
And Cloudaware didn’t just enforce them quietly — it showed exactly which CIs drifted, who changed what, and what the impact was on connected services. We even auto-assigned those drift alerts to the right manager, so nothing slipped through the cracks.
Here’s what one of those baselines might look like in your world:
Imagine you’re managing dozens of AWS accounts, and EC2s are spun up all the time. You want to lock in a baseline that ensures:
✅ Every EC2 has the tags Owner, Environment, and CostCenter
✅ Only encrypted EBS volumes are attached
✅ Only approved AMIs from your golden image pipeline can be used
✅ No public IPs unless explicitly marked Public=true
✅ All non-prod instances expire after 7 days
Once this is codified inside your ITSM CMDB software, Cloudaware watches every new configuration item. A dev spins up an untagged instance? Flagged. A volume skips encryption? Flagged. Someone reuses an old AMI from three versions ago? You get the picture.
Element of the compliance report in Cloudaware. Request a demo to see it live.
It’s all tracked, logged, and sent back to the CMDB, where the change is tied to that asset’s lifecycle. And if you’re doing this at scale? This is what turns config chaos into predictable, auditable, secure infrastructure.
5. Design and roll out change management processes
And no, I’m not talking about drowning in tickets. I’m talking about smart, contextual workflows that actually help you sleep at night.
The trick? You wire your configuration management process right into tools your team already uses — Jira, ServiceNow, even Git pipelines. Every configuration change gets tied to a CI. Not just "EC2-i-don’t-know-who-spun-this-up" — we’re talking tagged, traced, and related to the actual service it supports, the asset owner, and the blast radius if it goes sideways.
You can set thresholds too. Minor memory bump on a dev box? Auto-approved. Policy tweak on a prod VPC that hosts customer data? That one gets routed to CAB with full dependency context from the CMDB.
And once this is up and running? No more last-minute fire drills because someone skipped a review. You’ve got clean trails, scoped approvals, and the kind of change control that doesn’t slow you down — it actually protects the stuff that matters.
6. Monitor continuously for anomalies
Once your baselines are locked and changes are under control, the next layer is constant, config-aware monitoring. Not the “is this VM up?” kind — I’m talking real-time visibility into configuration changes, non-compliance, policy drift, and service health, all tied back to your live CMDB.
Here’s how it plays out in practice: We helped NASA’s SecOps and platform teams hook Cloudaware into their CI pipelines and event streams — AWS Config, GuardDuty, Security Hub, Azure Defender, plus Kubernetes audit logs. Anytime a CI deviated from its expected state (think public S3 bucket, revoked encryption key, missing ownership tag), the system flagged it instantly.
The alert wasn’t just noise — it was linked to the exact service configuration, the impacted asset, and the last known change.
7. Set up detailed reporting and analytics
By this point, your CMDB’s no longer a static inventory — it’s alive with context. Now it’s time to turn that configuration data into something strategic.
This step is about wiring up reporting and analytics that actually reflect how your infrastructure runs: usage patterns, configuration drift, baseline violations, change velocity, and service health — all sliced by CI class, owner, region, or business unit.
We usually start by plugging config insights into dashboards that speak the language of your stakeholders. Think:
- Security views tied to policy non-compliance and vulnerabilities
- Ops dashboards tracking high-churn assets and risky configuration changes
- Finance-aligned cost views grouped by service or project
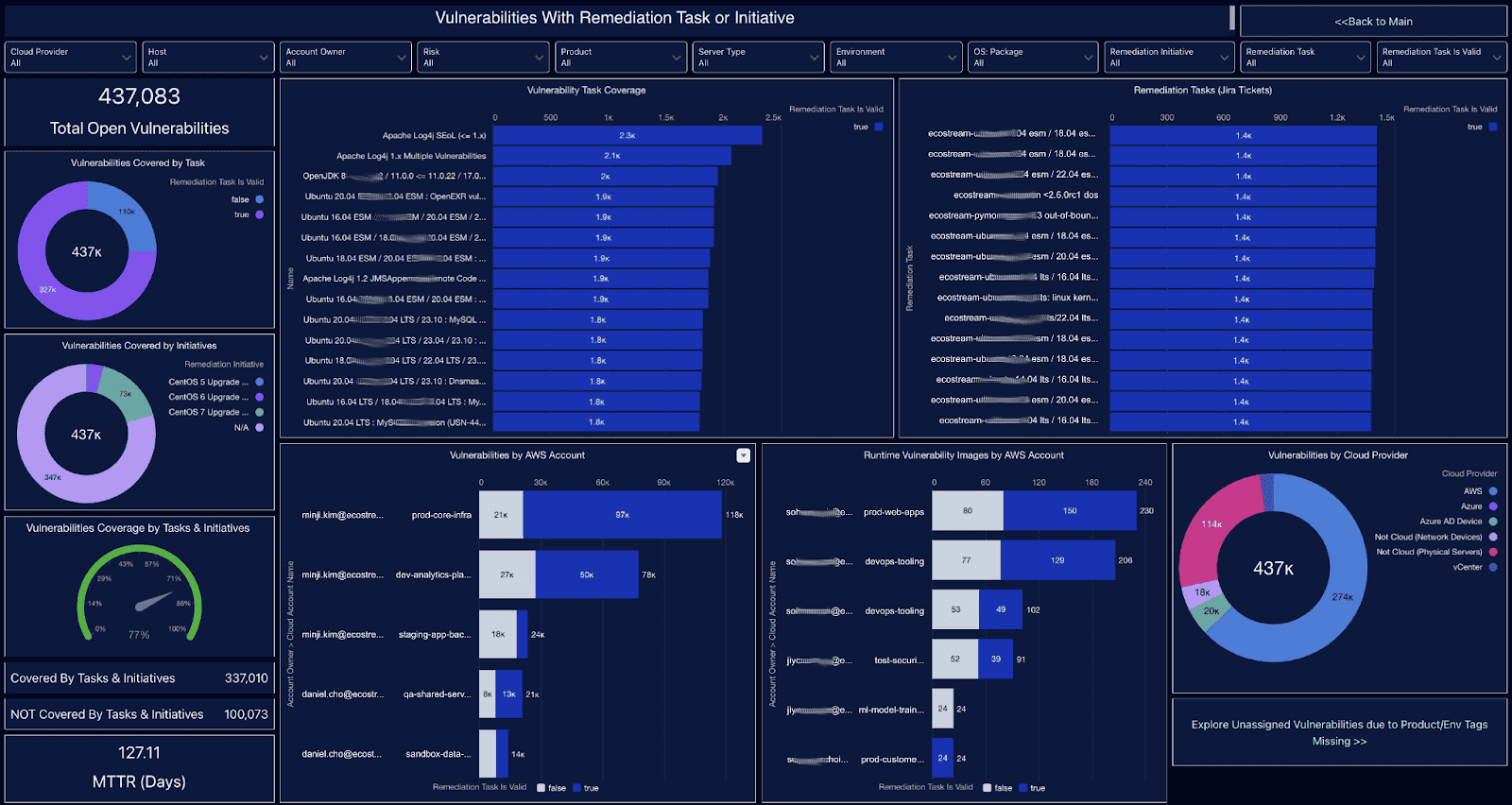
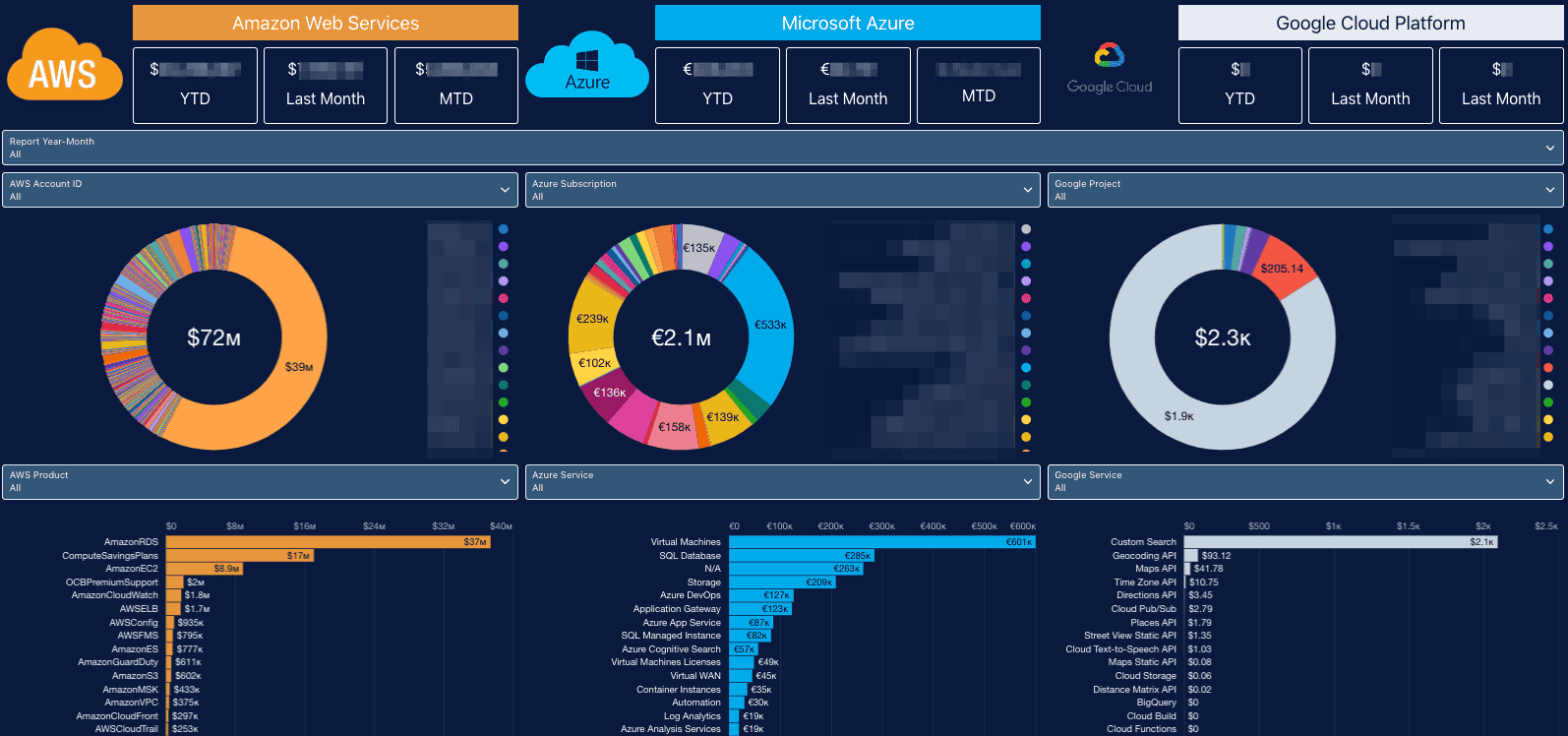
Examples of reports and dashboards in Cloudaware. Request a demo to see them live.
At Citrix, we helped their team align CMDB metrics to fiscal calendars. That one move turned weekly cost fire drills into clean, predictable reporting. With a few targeted views, they gave service managers, security, and finance shared visibility — without drowning anyone in noise.
And the best part? It’s automated. Dashboards update as your config evolves. You focus on what matters — not building reports in spreadsheets at midnight.
Top 5 Configuration Management Challenges in ITSM
I asked the Cloudaware CMDB crew to spill the tea on the biggest issues they see when companies try to roll out configuration management in ITSM. These aren’t Google-search-level answers. These are lived experiences from folks who work deep in the guts of hybrid infra — across IoT, cloud-native stacks, and legacy setups — managing some of the world’s messiest projects.
These five? They’re the ones that can derail your entire service asset management strategy if left unchecked:
1. Treating the CMDB Like a Static Inventory
Mikhail Malamud, Cloudaware GM:
2. No Ownership Model for Configuration Items
Technical Account Manager Iurii Khokhriakov:
3. Patching Configs Without a Change Management Layer
4. Confusing Tags with Configuration Data
5. Skipping the Baseline Step
Kristina S., Senior Technical Account Manager at Cloudaware:
Top 3 expert best practices
I asked around the Cloudaware crew — “What actually makes a CMDB work in real-world hybrid environments?” Not theory. Not best-practice fluff. Just the orchestration moves that keep change clean, visibility sharp, and services stable.
Here’s what they shared — three moves that shift your ITSM configuration management from checkbox to control tower, based on real projects, real ITSM practices, and the kind of agile pace modern teams actually operate at.
1. Build a relationship-first CMDB architecture
Listing assets is easy — your CMDB is full of them. But if it’s not showing how those assets, services, and infrastructure connect, you’re flying blind.
You want a CMDB that tells stories. Not just “this EC2 exists,” but “this EC2 supports this app tier, which powers this API, which feeds the frontend your users see.”
One project team I worked with integrated their CMDB with AWS Config and Azure Monitor. Suddenly, they could trace how Lambda functions triggered APIs and which App Services were stitched into the flow. When the API Gateway flaked out, they found it in minutes. No guesswork, no war room fatigue.
If you’re serious about configuration management, use service blueprints and dependency maps. Show not just systems, but how your CI/CD pipelines rely on object storage, secrets managers, or even Slack for deploy workflows. This kind of service configuration awareness shifts your whole management game from reactive to proactive.
2. Go event-driven for real-time accuracy
Scheduled scans are the relics of yesterday’s ITSM practices. In modern agile environments, config drift happens in the blink of an eye. You need event-driven orchestration to close the gap between config change and visibility.
Plug your CMDB into CloudTrail, AWS Config, Azure Activity Logs, or ServiceNow. When someone adjusts a security group, deploys to Kubernetes, or touches a Salesforce setting — your ITSM CMDB software should know immediately.
We’ve seen teams cut incident resolution time by automating config updates. At Cloudaware, we connect to everything from VMware to EKS, ensuring your CMDBs pull in live data, not stale snapshots. Every CI, every change, every service — tracked. That’s how you stay ahead of creeping vulnerability risks.
3. Tie configuration data to operational context
Configuration data in isolation? Meh. It’s just noise unless it’s tied to operational metrics. You need to know: did that change wreck performance? Spike cost? Trip an incident?
One FinOps team we worked with hooked their CMDB into spend dashboards. So when someone resized EC2s without considering Reserved Instances, they caught the cost jump in real time.
Another team integrated with ServiceNow and PagerDuty. During incident management, they instantly saw which CIs were involved and pulled change history to pinpoint what broke. That’s not just better response — that’s smarter service management.
Want to scale that? Connect your configuration data to performance tools, SLA trackers, and cost metrics. Now your manager sees the full picture. Because configuration management isn’t just tracking what changed — it’s understanding what that change means.
The best cloud configuration management tools for your ITSM
My teammates and I tested almost all the existing solutions on the market. And as for the company with multiple cloud and on-prem setup, here are some of the best software👇
Cloudaware CMDB software {#cloudaware-cmdb-software}
Cloudaware is your config command center. It pulls all your scattered infra into one clean, searchable brain. You get full visibility across everything: AWS, Azure, GCP, Oracle, Alibaba, and even on-prem.
It’s made for the kind of complex, messy, hybrid stacks.
And the beauty of this ITSM CMB software? It doesn’t just list assets like “here’s your EC2.” Nah, it goes deep. Each CI gets enriched with cost data, vulnerabilities, tagging context, even application mapping. It builds those juicy relationships between cloud services, apps, and environments so you can actually understand what connects to what — and what’s at risk.
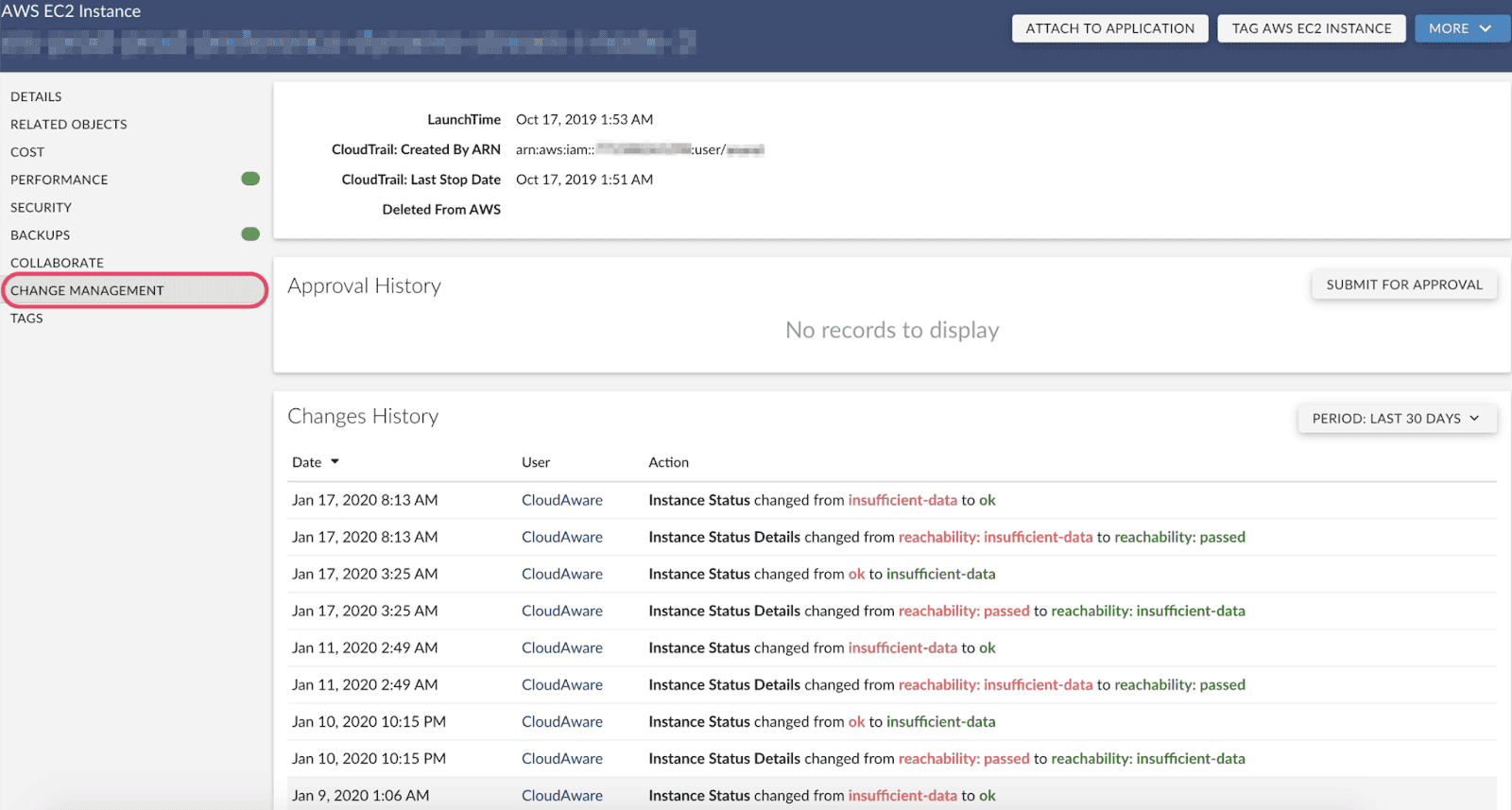
Let’s say you’ve got an EC2 instance:
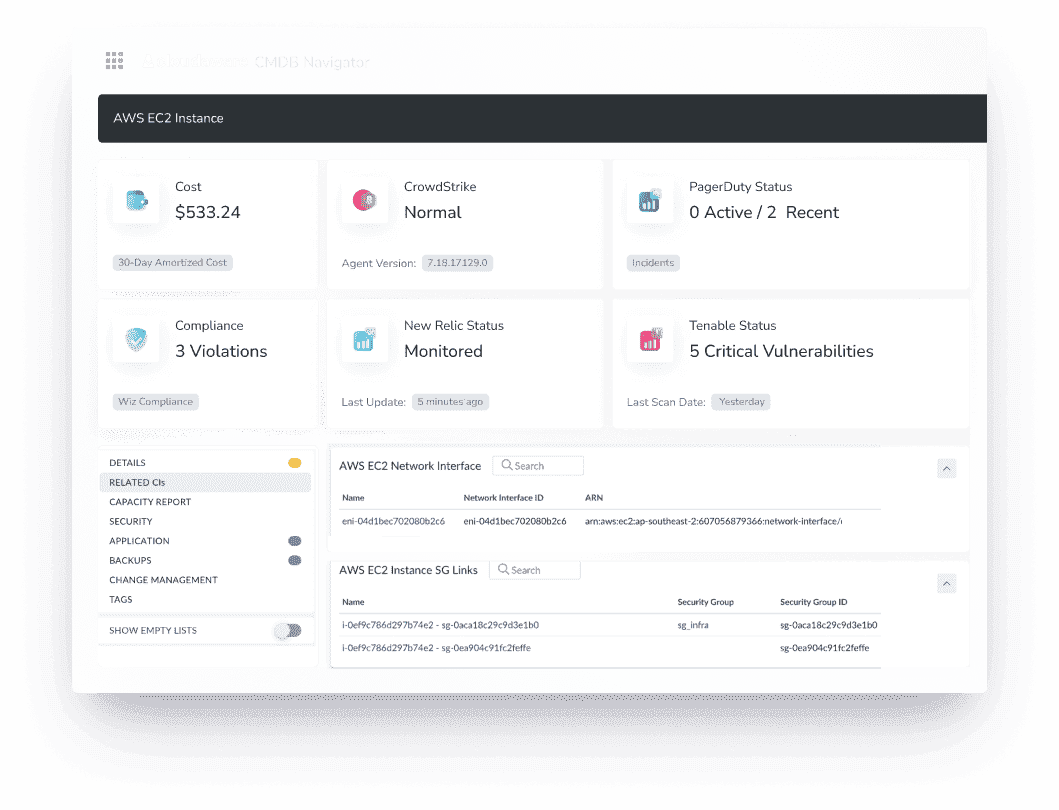
Boom — not just infra, but context. Now you know exactly what it’s doing, how it’s costing you, what risks it’s carrying, and how it fits into your overall service configuration. That’s config intelligence, not just config tracking.
Features
- Asset chaos? Cloudaware auto-discovers and normalizes everything — AWS, Azure, GCP, VMware, Oracle, on-prem, even Alibaba if you’re wild like that. EC2s, EKS, GKE pods, vSphere VMs — it grabs it all, including that dusty NAT gateway no one claims but keeps eating budget.
- Lifecycle tracking? From the dev who spun up a box at 2AM to the day you finally kill that zombie region — it’s tracked. Owners, cost centers, hardware age? All there.
- Custom CIs? LambdaFunction, SSMManagedInstance, FirewallRule — built in. Got weird infra or SaaS edge stuff? Define your own CI types. No drama.
- Tagging? Chef’s kiss. Auto-policies add Owner, Environment, CostCenter tags. Manual tweaks? UI or API, whatever works. It’s smarter-than-your-average asset tag management.
- Relationship mapping? See who owns the EC2, what RDS cluster it talks to, and which sketchy SG is exposing SSH. Infra with full service context.
- Change tracking? Track every config flip. Who opened port 22? When did that S3 go public? Time-machine mode, with real answers — not intern guesses.
- FinOps views? Built in. Slice cloud costs by CI, tag, or project. Spot idle, oversized, or zombie assets. Trim waste without breaking things.
- Compliance? Easy. CIS, SOC 2, HIPAA — covered. Non-compliant assets show up with proof, mapped to the CI. When audit week hits, you’re chill.
- Vuln management? Cloudaware pulls from Inspector, Sentinel, Defender, Qualys — and ties each vuln to the right CI. No more shouting into the ticket void.
- Security posture? All your signals — GuardDuty, Security Hub, Sentinel — in one place, with context. See the full picture. Fix fast.
Pros & Cons
✅ Covers it all – VMs, containers, serverless, SaaS — it doesn’t flinch
✅ Multi-cloud ready – Manage across AWS, Azure, and more with zero drama
✅ One view to rule them all – On-prem, cloud, whatever — it’s all in one place
✅ Beyond discovery – Pulls in billing, compliance, security context — automatically
❗ The interface can feel overwhelming for new users. To address this, each user gets a dedicated assistant to help set up the solution based on their needs.
Yeah, the interface can feel like a lot at first. It’s powerful — and that comes with buttons. But don’t worry — you get a dedicated Cloudaware assistant to walk you through setup and make sure it’s tailored to how your team works.
📌Read also: Master Cloud Configuration Management: Tools & Tips
ServiceNow CMDB
If you’re managing a stack that spans cloud, on-prem, and everything in between, ServiceNow CMDB’s got your back. It’s not just a database — it’s like the command center for your service configuration, keeping your ITSM setup sharp and steady.
Why companies swear by it:
✔️ Plays nice with others. Hooks right into incident, change, and problem management. One ecosystem, no duct tape.
✔️ Live visibility. It tracks your assets and how they’re all wired together — so you’re not left guessing what broke what.
✔️ Built for hybrid beasts. Whether it’s AWS, VMware, or your old-school data center, it all flows in.
And the best parts?
- Auto discovery from tools like AWS Config, vSphere — so you’re not hunting down assets by hand.
- Dependency mapping shows how services hang together — so a dropped API call doesn’t turn into a war room session.
- Insightful dashboards make sure your data actually tells a story — one that helps you make faster, better calls.
Read also: Cloudaware CMDB vs. ServiceNow
Asset Panda software
Asset Panda is built for businesses that care more about where the laptops are than what service mesh they’re tied to. Think retail, schools, manufacturing — teams who need clear asset records, not config sprawl.
Why it works:
🛠️ Simple tracking. Laptops, mobile devices, on-site servers — log 'em, tag 'em, done.
🛠️ Custom fields & workflows. Tailor it to how your org runs without a ton of setup.
🛠️ Secure but chill. Role-based access and encryption keep your data locked tight.
What it’s not?
It’s not for managing complex service configurations or tracking dependencies in a hybrid cloud setup. Updates are manual, and support is more self-serve than hand-holding.
Perfect if you want asset management tool that’s clean, not complicated.