






Cloud cost savings have become one of the hardest challenges for engineering and FinOps teams in 2025.
Budgets are tightening, cloud usage keeps growing, and CFOs expect teams to do more with less – yet most organizations still struggle to translate cloud optimization efforts into real, measurable savings.
Across DevOps and FinOps communities, the same pattern repeats. Engineers say they’re drowning in idle resources. In popular industry discussions, practitioners admit the same problem: cloud isn’t automatically cheaper.

That’s exactly the reality engineering teams face today. Cloud savings aren’t guaranteed – they’re earned. And the gap between what companies expect and what they actually achieve usually comes down to visibility, ownership, and day-to-day operational discipline, not discounts or one-time cleanups.
In this guide, we break down what actually works. You’ll see:
- Why companies fail to achieve cloud cost savings, even with FinOps in place
- Four real examples from Cloudaware clients, including $1.5M in verified savings
- Expert insights from Cloudaware FinOps experts on what reduces costs reliably in 2026
- Practical opportunities teams consistently overlook
Why do many companies still fail to achieve cloud cost savings
Even with FinOps programs, automation, and modern cloud management tools, many organizations in 2025 still fail to achieve meaningful cloud cost savings. When you read what real engineers discuss in DevOps and sysadmin communities, the same problems appear over and over again – and they explain why savings rarely match expectations.
1. Dev/Test environments running 24/7
Teams often spin up development or testing environments “for a quick task,” but those workloads stay up for days or weeks. So those temporary environments are one of the biggest sources of waste.
In a popular DevOps thread, an engineer explained how simply scheduling non-production resources created dramatic savings:

Teams that don’t automate shutdowns or rely on manual cleanups rarely succeed with cloud savings, simply because idle non-prod environments accumulate continuously.
Read also: What Is Rightsizing in Cloud Cost Optimization? Pro Insights
2. Untagged resources = no owner = no cleanup
Untaggable environments (no owner, no cost center, no application relationship) block every initiative related to hybrid cloud cost reduction, forecasting, or anomaly detection.
When a resource has no owner, nobody wants to delete it – and unowned resources silently consume budget for months.
This governance gap is one of the main reasons companies fail to achieve sustainable cost reduction in cloud computing.
Read also: Proven FinOps Tagging Guide
3. Egress shock and unpredictable data movement
Unexpected egress fees are still one of the top reasons why optimization efforts fail.
Cross-region transfers, large data exports from analytics systems, multi-cloud replications, or misconfigured data pipelines create surprise bills measured in thousands or tens of thousands of dollars.
Once egress is triggered, cloud cost savings statistics instantly fall apart – even if everything else is optimized.
Read also: 9 Cloud Cost Management Strategies for 2026
4. Idle snapshots and unmanaged storage growth
Storage bloat is a silent but very real problem. Teams regularly discover years’ worth of:
- Stale snapshots
- Forgotten log archives
- Unattached disks
- Orphaned volumes
Without lifecycle policies, even advanced FinOps teams struggle to achieve cloud-native cost reduction. Storage inflation grows slowly but relentlessly and is difficult to reverse once it gets out of control.
Read also: How Cloud Experts Use 6 FinOps Principles to Optimize Costs
5. Multi-cloud increases cost without unified governance
A lot of teams still walk into multi-cloud believing it will somehow lead to automatic savings. It sounds good in theory – pick the “best” service from each provider and pay less overall. But the real world is not that tidy.
Most companies end up running the same things twice (sometimes three times), with different IAM rules, monitoring setups, networks, backup jobs, regions, and so on.
When nobody is looking at the whole picture, cost starts leaking from everywhere: duplicated clusters, services that exist only because “we already had them on provider X,” cross-region replicas and etc. Multi-cloud can be done right, but it requires strict governance.
Read also: Hybrid Cloud Cost: How to Optimize and Manage Mixed Infrastructure in 2026
6. Architectural decisions create costs before anything is deployed
System can look clean when it’s drawn on a diagram, but as soon as you start paying per resource, tiny choices begin to matter: too many microservices, extra API layers “just in case,” small workloads that sit idle most of the time but still trigger full compute, networking, and security overhead.
One engineer described this issue:
By the time FinOps gets involved, the architecture is already in production – and changing it becomes slow, political, and expensive. That’s why architectural waste is one of the most damaging forms of cloud waste: it hides under “best practices” until the cloud bill exposes it.
Read also: Why Is Cloud Cost Management So Difficult? 7 Hard Truths
Cloud cost savings in practice: 4 real examples from Cloudaware clients
Real cloud savings become clear only when you look at what actually happens inside large, complex environments. Below are four Cloudaware case studies from Boeing, Caterpillar, Coca-Cola, and NASA, each showing how visibility, ownership, and automated governance translate into clear, verifiable cloud cost savings.
Taken together, these real-world results amount to more than $1.5M saved, making them worth a closer look.
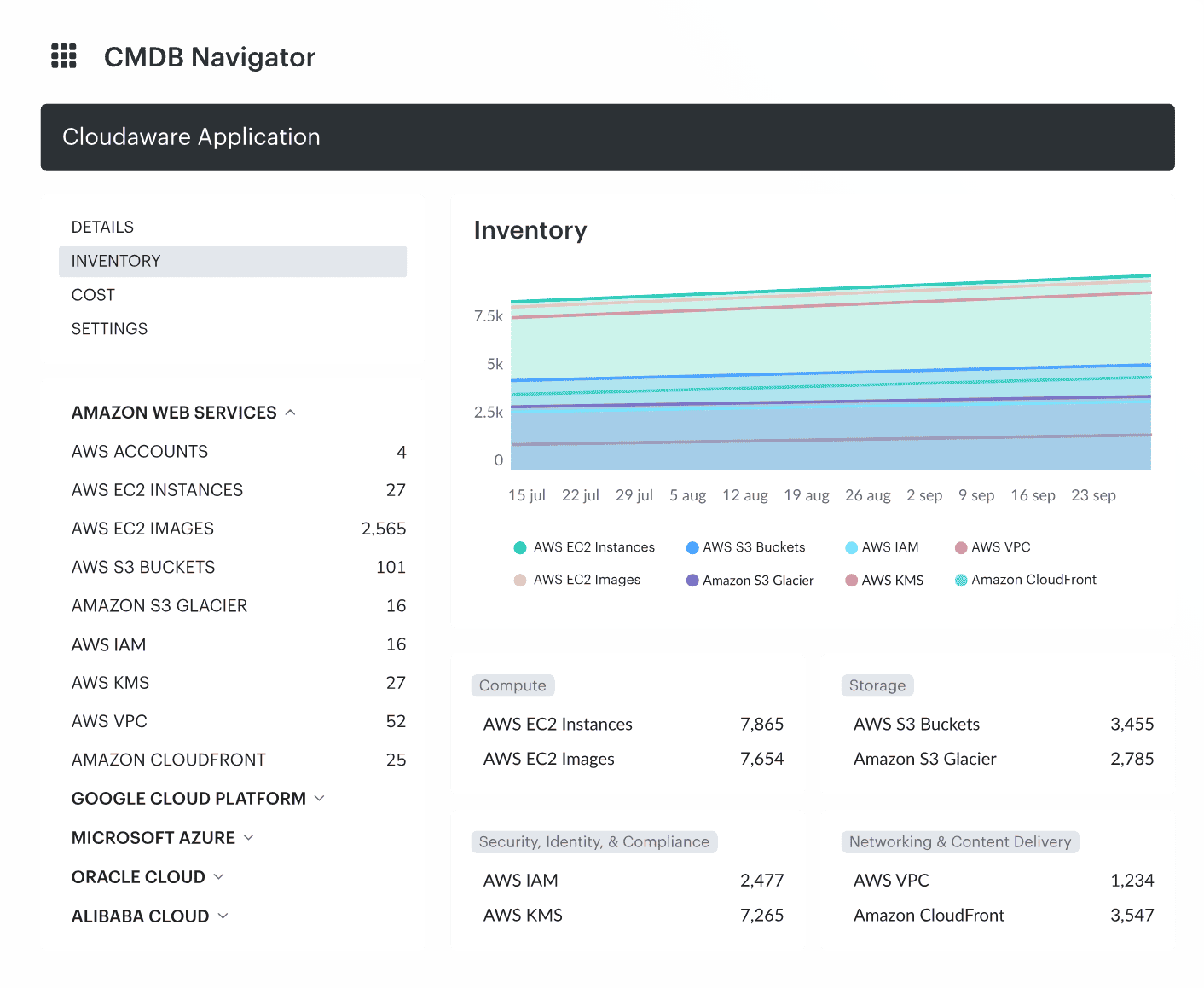
Boeing. $958k/year saved through visibility & AI cost control
Challenge:
Boeing runs a large mix of AWS, Azure, and GCP, and a big part of their spend recently shifted into AI platforms – Azure OpenAI, AWS Bedrock, and SageMaker.
The FinOps team could see the overall bill, but they couldn’t trace which AI models, token types, or accounts were driving cost spikes. Storage usage and RI/SP coverage were also scattered across different consoles, making it hard to manage spend across clouds.
What Cloudaware surfaced:
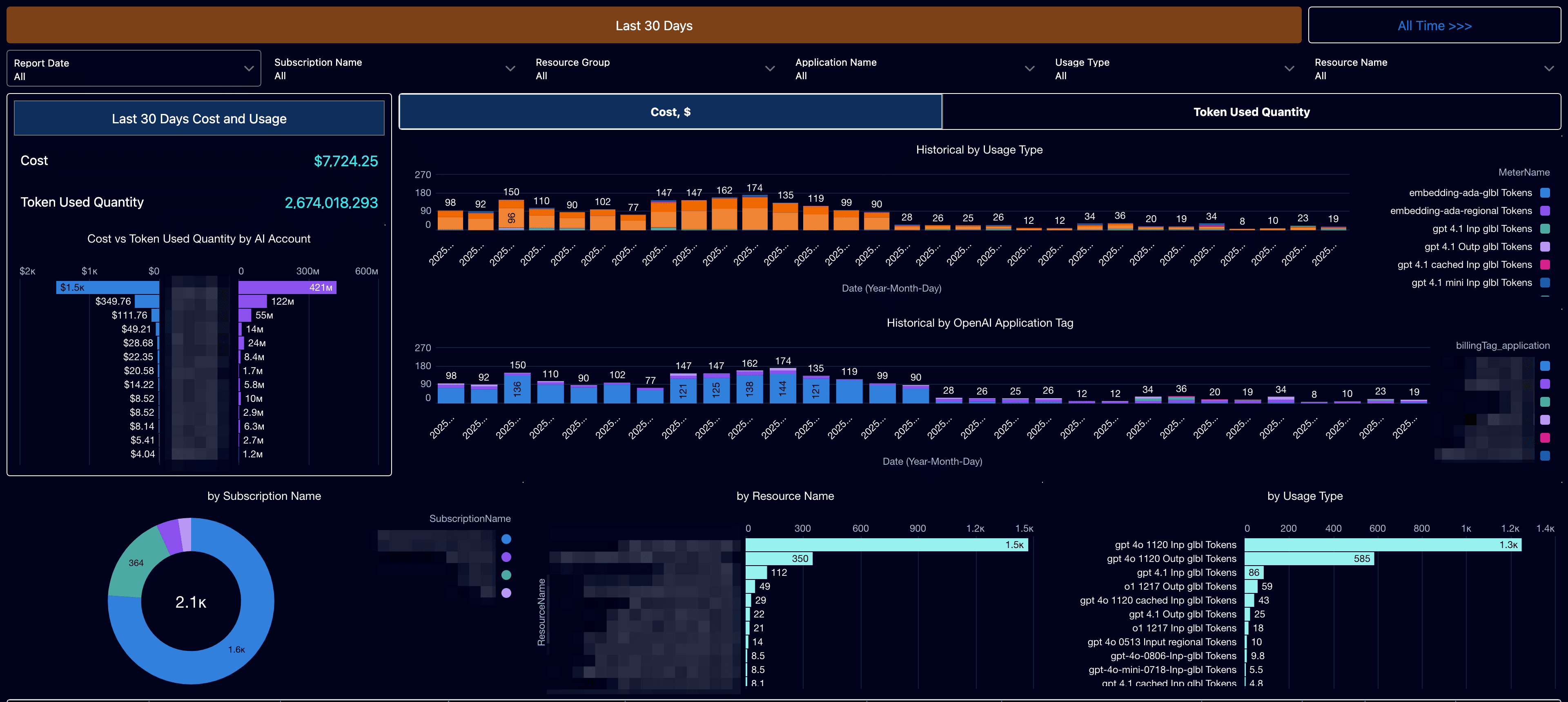
With Cloudaware’s CMDB, the team finally had one place where all usage made sense. The platform highlighted:
- Azure OpenAI spend by model, token type, and account
- Bedrock and SageMaker activity patterns
- Idle and orphaned storage buckets
- Where RI and Savings Plan coverage didn’t match real usage
Need this level of insight? Schedule a demo.
Individually, these insights were small, but together they gave Boeing the visibility they were missing to actually reduce cloud costs.
Outcome:
After cleaning up unused storage, tightening RI/SP alignment, and controlling fast-growing AI workloads, Boeing captured $958,250 in annual cloud cost savings in roughly 90 days. Most of the improvement came from many small, continuous corrections – a pattern common in large environments once real visibility is in place.
This case shows how unified insight and ownership context quickly translate into measurable cloud savings, especially when AI spend is accelerating.
Read also: 10 Best Practices for Azure Cloud Cost Optimization from FinOps Pros
Caterpillar. $627k/year through multi-cloud optimization
Challenge:
Caterpillar runs workloads across AWS, Azure, GCP, and SCCM-managed on-prem systems. As the number of accounts and services grew, the team ran into a common problem: every cloud showed costs and usage differently.
Tagging wasn’t consistent everywhere, some workloads were oversized, and several services were duplicated across clouds. Without one place to see everything together, it was hard to spot waste or figure out where real multi cloud cost savings could come from.
What Cloudaware surfaced:
With everything unified in one CMDB-driven view, Cloudaware became their practical cloud cost savings tool, making cross-cloud comparisons and fixes a lot easier. CMDB immediately highlighted:
- Workloads with missing tags or owners
- Idle or oversized compute
- Duplicated services across AWS, Azure, and GCP
- Places where RI/SP usage didn’t match real demand
- Visibility gaps that blocked cleanup
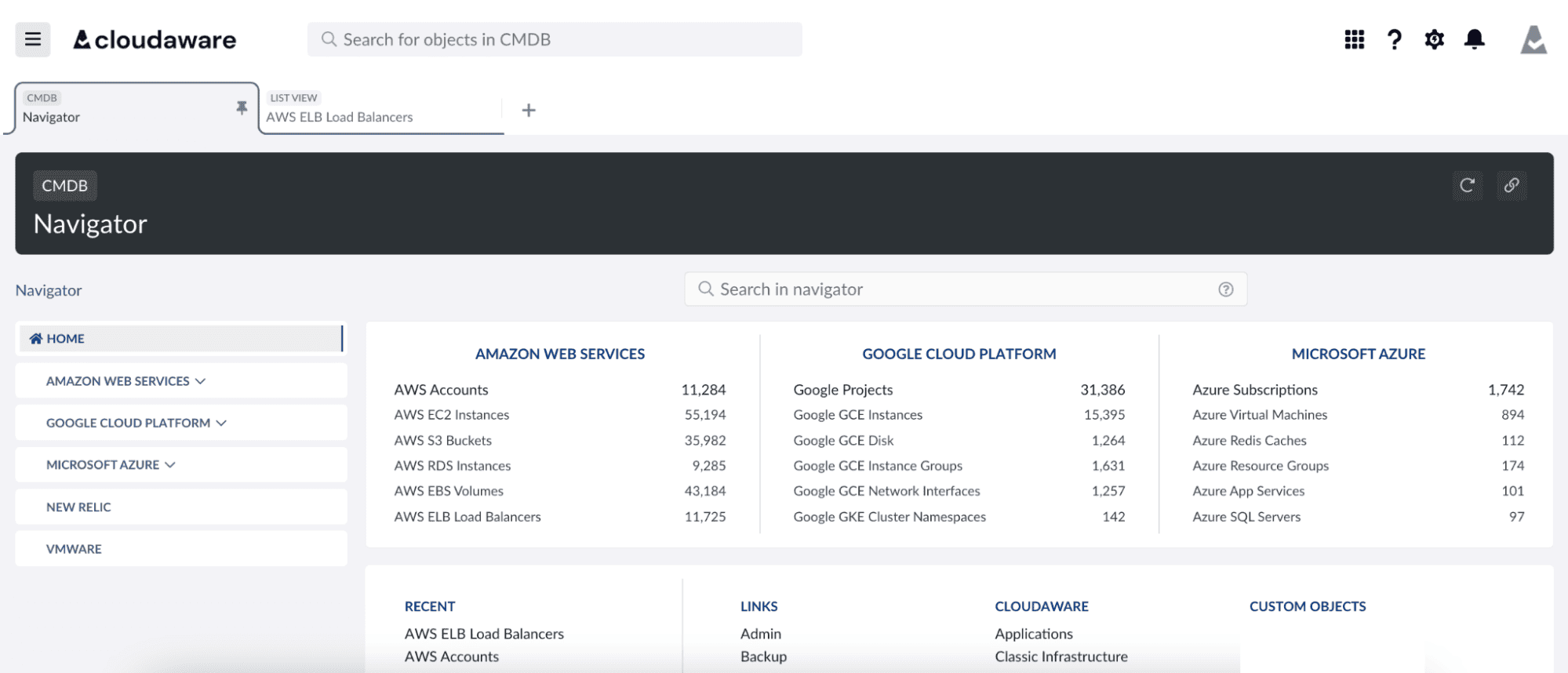
Unified inventory of cloud assets across AWS, Azure, and GCP.
Outcome:
Within the first 90 days, Caterpillar captured $627,000 in annual cloud cost savings, mostly by rightsizing and removing redundant workloads spread across providers. They also cut compliance violations by 42% and gained full visibility across all cloud and on-prem environments.
With that foundation, the team could finally make informed decisions about where workloads should run – a key driver of real multi-cloud cost management savings and future cloud portability cost savings US.
Read also: 12 Cloud Cost Management Tools: Software Features & Price
Coca-Cola. Visibility + governance = measurable savings
Challenge:
Coca-Cola operates across AWS, Azure, and several on-premises data centers. Before Cloudaware, the team had a hard time answering basic operational questions: which cloud a server was running on, which account it belonged to, or who owned the application behind it.
Cloud monitoring alerts weren’t tied to CMDB records, tagging was inconsistent across platforms, and cost tracking was fragmented – making it difficult to identify waste or use any form of cloud cost savings software effectively.
What Cloudaware surfaced:
After onboarding, Coca-Cola finally had a single system that connected assets, applications, costs, and governance. Cloudaware helped them:
- Standardize tagging with Tag Analyzer
- Unify cost and inventory data across AWS, Azure, and on-prem
- Correlate alerts and incidents with CMDB records
- Enforce compliance with 300+ policies
- Centralize their application catalog for clearer ownership and chargeback
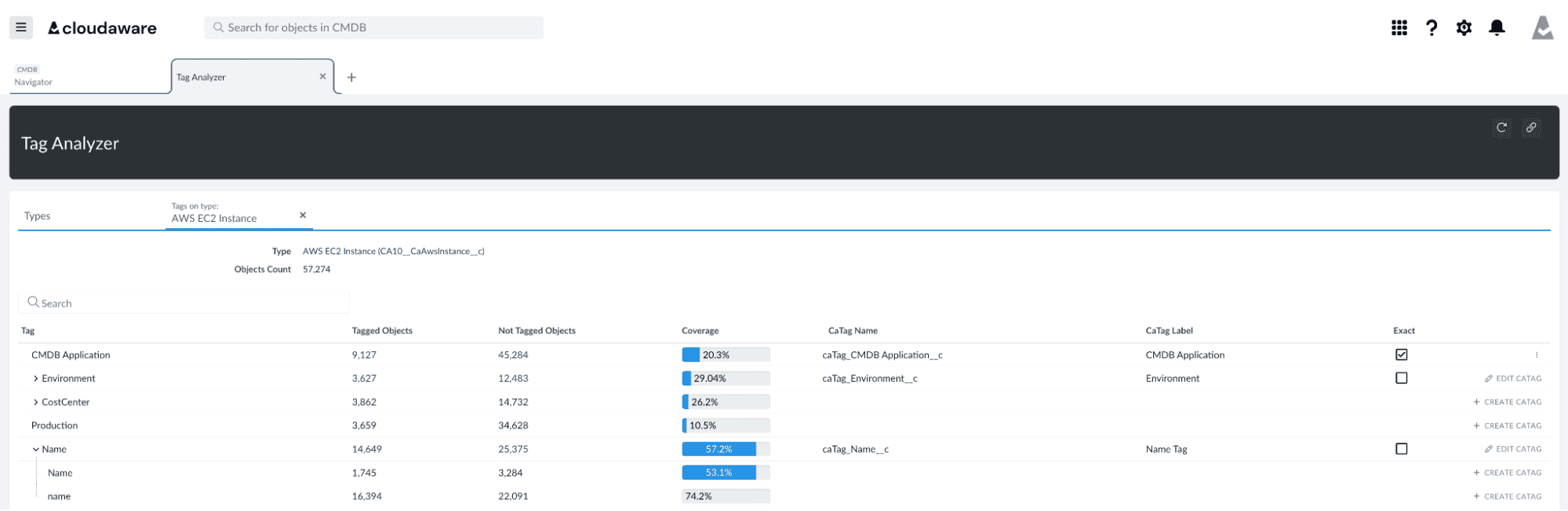
Cloudaware Tag Analyzer.
This combination gave teams the visibility they were missing and replaced multiple tools with one platform – a real gain in software cost savings cloud environments.
Outcome:
Within six months, Coca-Cola reported a 41% drop in compliance violations, a 53% improvement in tagging accuracy, and a 27% reduction in duplicate tooling.
Read also: AWS Cloud Cost Management: A Practical Guide
NASA. Full-stack visibility enabling cost governance
Challenge:
NASA runs one of the largest AWS footprints in the public sector – more than 5,000 EC2 instances and nearly every major AWS service across 30+ programs. With many teams deploying independently, it became challenging to see what was running, who owned it, and whether configurations met security and compliance requirements.
Without a unified view, it was almost impossible to control spend or spot waste – a common blocker for meaningful cloud cost savings.
What Cloudaware surfaced:
Cloudaware delivered a full inventory of NASA’s AWS environment and tied every resource to a CMDB record. This included:
- Real-time discovery of EC2 instances and configurations
- Compliance checks for FISMA, HIPAA, PCI
- Automated detection of non-compliant changes
- Incident correlation and threat visibility
Cloudaware Incident Management
With this, teams finally had a single cloud cost savings tool instead of scattered consoles.
Outcome:
Unified visibility allowed NASA to enforce consistent policies, prevent misconfigurations before they became expensive, and maintain stronger governance across projects. While the case focuses on security, the same visibility foundation enables practical hybrid cloud cost reduction in large federal environments.
Read also: 6 Ways to (not) Fail AWS Cloud Cost Optimization in 2026
Insight #1. Real cloud cost savings start with deep visibility
Insight from Mikhail M., Cloudaware GM
The biggest misconception in cloud optimization is that savings start with tuning resources. In practice, they start much earlier: with the ability to see what’s happening across accounts, workloads, services, and teams.
In many companies, cloud bills arrive as a single number with no context. Inside that number sit dozens of components: AI workloads, Kubernetes namespaces, staging environments, shared networking, forgotten storage, and data processing pipelines.
Without separating these, engineering teams focus on spikes instead of the quiet structural waste that burns the most money over time.
Where visibility usually fails
- Costs grouped by account, not workload
- Inconsistent tagging across AWS/Azure/GCP
- No owner mapping → no accountability
- SKUs (storage, egress, AI tokens) growing unnoticed
- Duplication across environments or clouds
What becomes possible with real visibility
When spend is tied to owners, applications, and configurations, teams see patterns that were invisible before:
- Idle services that still consume cost
- Workloads where spend grows faster than usage
- Egress-heavy flows hidden inside service-to-service traffic
- AI accounts generating unexpected spikes
- SKUs that drift out of baseline
Cloudaware enables this by merging cloud billing, AI usage, and Kubernetes/infrastructure inventory into a CMDB-backed model. Once everything is connected, cost patterns stop being guesswork.
Read also: Cloud Cost Optimization: The Complete 2026 FinOps Guide
Insight #2. Kubernetes waste stays hidden until you track requests, usage & ownership
Insight from Daria L., ITAM & asset lifecycle expert
Kubernetes often feels like a black box from a cost perspective. Nodes autoscale, pods restart, workloads shift – and the cloud bill grows while no one can explain why.
According to Daria, the root problem is simple: requests are set once and rarely revisited, even as workloads evolve. Her observation captures it: “Requested doesn’t equal used. And the gap is usually what you’re paying for.”
Where Kubernetes waste hides
- CPU and memory requests set once and forgotten
- Workloads slimming down, but keeping old high requests
- Node pools running under 40-50% utilization
- Oversized pods preventing better bin-packing
- Inactive namespaces still carrying baseline costs
Teams rarely connect this waste to cost because Kubernetes telemetry lives in one tool, and ownership in another.
How teams make this actionable in practice
Cloudaware doesn’t replace metrics, but it provides context that metrics alone can’t:
- Automatic discovery of clusters, nodes, pods, workloads
- Mapping each workload to an owner, app, and service through CMDB
- Policy checks for misconfigurations and drift
- Lifecycle visibility for pods, nodes, and deployments
With the workload–owner–configuration chain visible, FinOps and platform teams can finally connect cost to behavior, identify oversized workloads, and prevent configuration drift – the kind that quietly inflates cloud bills in Kubernetes-heavy environments.
Insight #3. The fastest savings come from removing unused resources (safely)
Insight from Anna M., Technical Account Manager, multi-cloud operations
One thing Anna notices in almost every multi-cloud environment is that a surprisingly large part of the bill comes from resources nobody touches anymore. Old test machines that were supposed to live for a week, disks left behind after an instance was terminated, temporary workloads that quietly became permanent.
What a safe cleanup process usually looks like
- Find resources with no real activity for 30–90 days
- Check whether anyone actually owns or still needs them
- Notify the presumed owner and wait for a response
- Only decommission after a short grace period
This slower approach avoids accidents while still removing a lot of the quiet, hidden waste that builds up over time.
How Cloudaware fits into this workflow
Cloudaware doesn’t delete anything on its own. What it does is the groundwork that makes cleanup safe:
- Continual discovery across AWS, Azure, GCP, and on-prem
- Linking resources to applications and owners through CMDB relations
- Surfacing idle compute, unattached volumes, and “orphaned” assets
- Routing cleanup candidates through ITSM so teams can review or approve
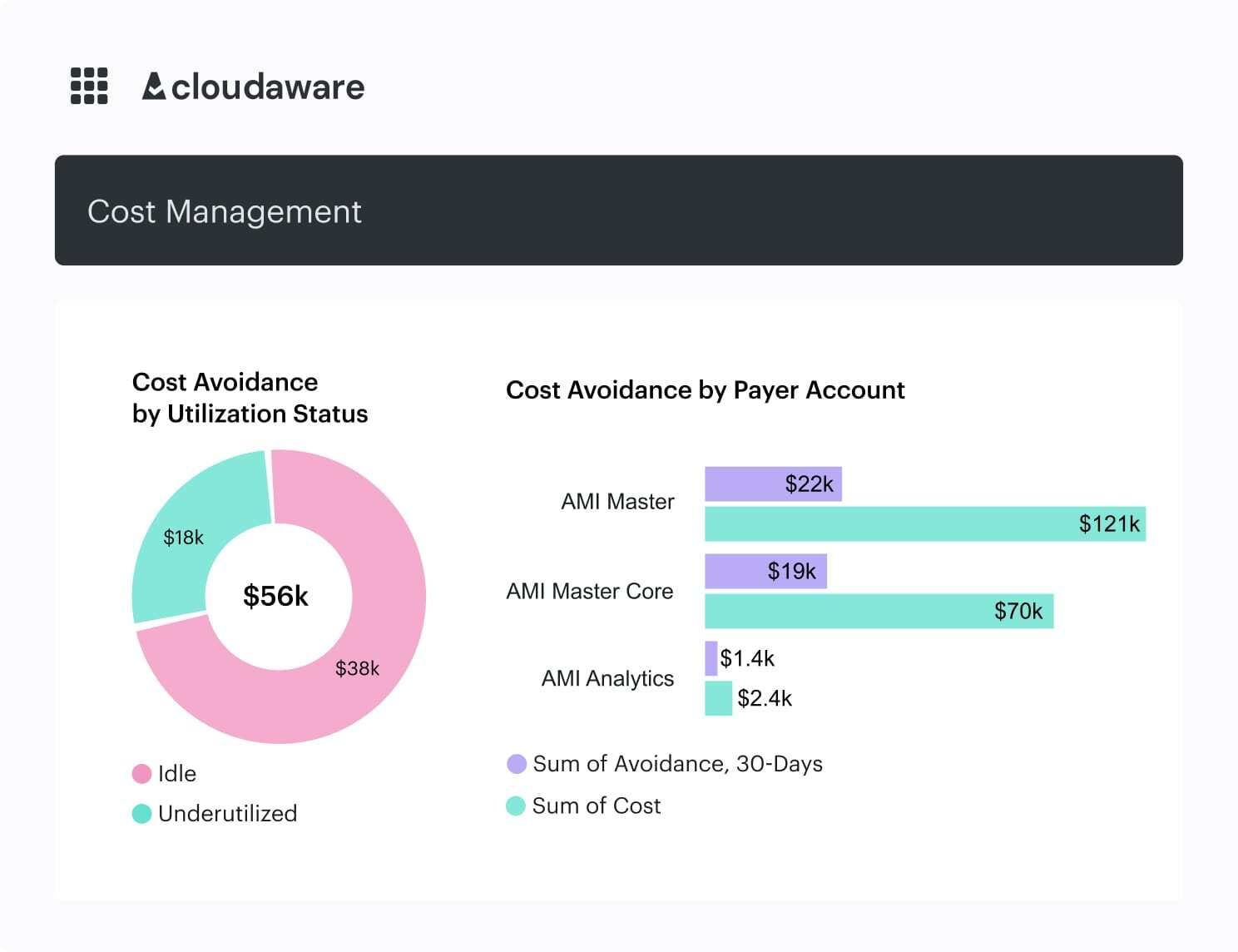
In Anna’s experience, this mix is where many organizations see their first real cloud cost savings, long before they get into more complex optimization work.
Read also: Cloud Cost Optimization Metrics: 18 KPIs FinOps Track
Insight #4. Cloud costs aren’t linear (and they’re not supposed to be)
Insight from Alla L. – ITAM & configuration management expert
One thing Alla sees repeatedly is a misplaced expectation that cloud optimization should create a clean, steady drop in spend. In real environments, it almost never works that way.
After the obvious waste is cleaned up costs usually level out for a bit and then rise again. Not because the team “lost discipline,” but because of new features, new regions, more traffic, experiments with ML or AI, or entire teams moving workloads around.
The real problem is when nobody can explain why it happened. Without tying spend to applications, owners, and architectural changes, the bill looks random. With proper context, the pattern becomes predictable.
What healthy cloud cost behavior actually looks like
- Initial drop after removing unused resources
- A short period of stability
- Gradual growth tied to product releases or workload expansion
- Occasional spikes tied to migrations or one-off workloads
- Clear distinction between business-driven growth and pure waste
Read also: Cloud Migration Costs for Enterprises: Forecasting, Risks, and Savings Controls
How teams make this actionable in practice
Teams that manage this well don’t stare at the total billing number. They connect spend movements to the rest of their operational picture:
- Linking costs to the applications and teams behind them
- Correlating spend jumps with deployments, scaling, or environment growth
- Separating structural waste from growth that’s intentional
- Viewing AWS, Azure, and GCP as one architecture instead of three bills
- Using CMDB relationships to understand what changed and who changed it
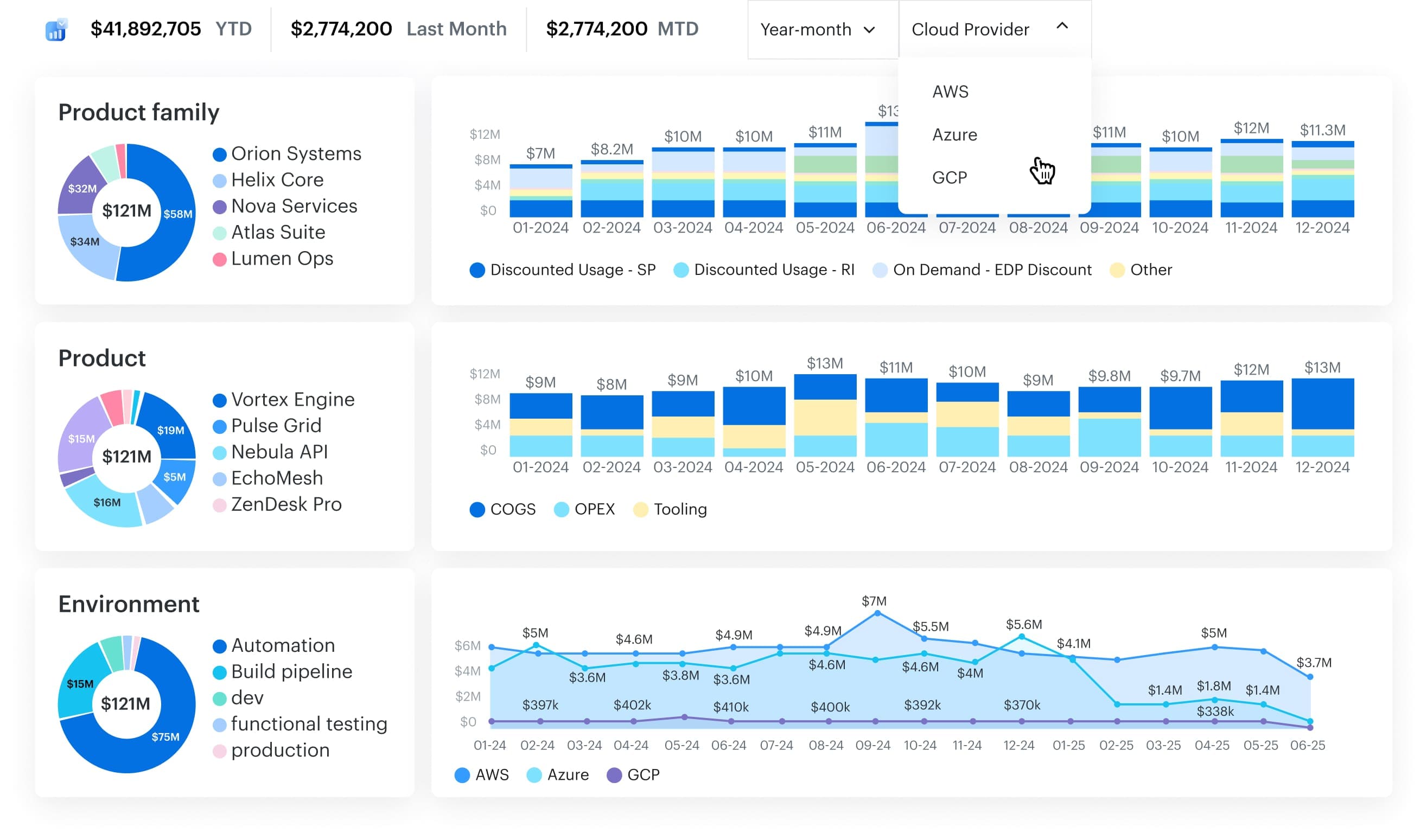
Insight #5. AWS cloud cost reduction: what works in real environments
Insight from Katherine L. – Senior consultant, cloud visibility & compliance
Katherine often works with companies that spend heavily on AWS. Many of them focus almost entirely on tuning workloads – rightsizing, autoscaling, off-hours scheduling.
Those efforts help, but in larger AWS environments, the biggest reductions usually come from somewhere else: commitment agreements. Enterprise Discount Programs, Savings Plans, and Reserved Instances can cut costs dramatically – but only if they’re based on a realistic view of consumption.
The challenge isn’t choosing the discount model. The real challenge is knowing how much you can safely commit to without overshooting.
Where AWS forecasting usually breaks down
- Finance and engineering forecast in isolation
- Usage is scattered across many accounts
- ML/AI workloads fluctuate unpredictably
- Teams don’t know which services are stable vs. volatile
- Negotiations happen without clean, historic consumption data
How to turn this into a working process
The organizations that negotiate effectively with AWS tend to do a few specific things:
- Review historical EC2, EBS, networking, and compute usage at the service level
- Identify which applications consistently drive consumption
- Look at product roadmaps to understand where legitimate growth will occur
- Separate stable workloads from spiky experimental ones
- Factor in multi-cloud usage to avoid committing based on partial visibility
Cloud savings opportunities you might be missing
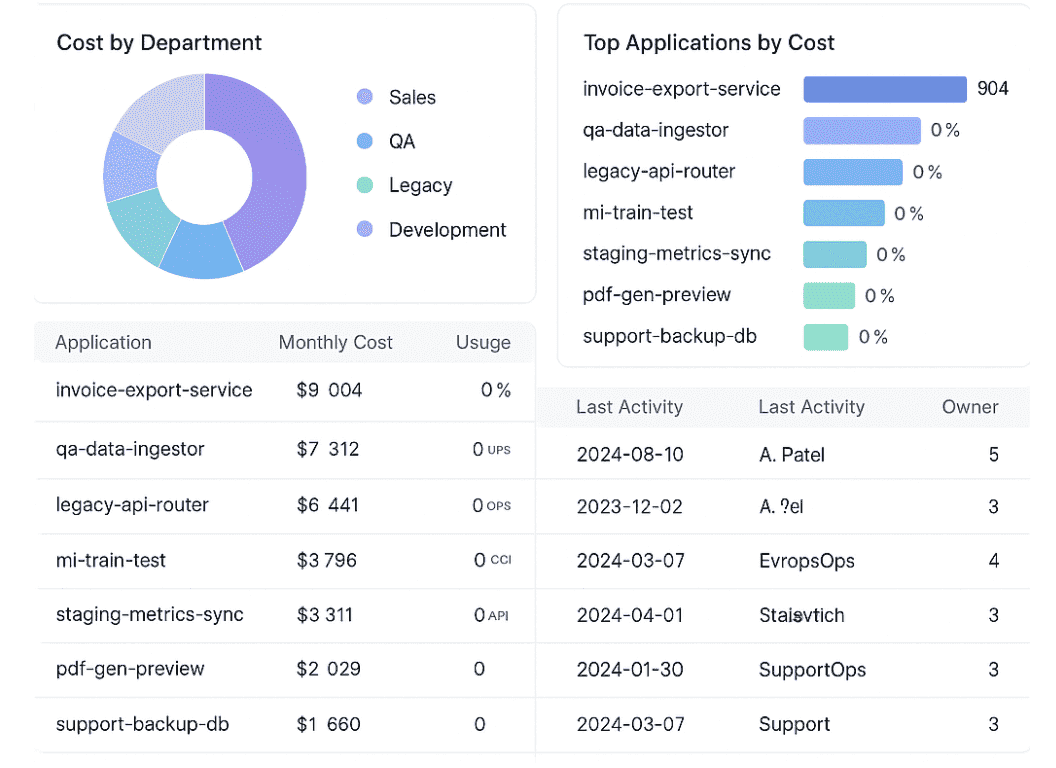
Even experienced cloud teams overlook patterns of waste that aren’t visible from a single console or a monthly bill. Many savings opportunities sit not in tuning individual services, but in how ownership, architecture, and lifecycle interact. When those pieces drift apart, cloud costs grow in ways that feel “normal” – but aren’t.
Across multi-cloud and hybrid setups, several categories of cost reduction in cloud computing consistently stay underutilized:
1. Growth vs. Waste (the visibility gap).
Cloud bills rise and fall naturally. What matters is whether spend changes match what engineering teams are actually doing.
When spend increases but nobody can tie it to deployments, traffic, or AI workloads, structural waste tends to hide behind “expected growth.” This is why generic cloud cost savings statistics often fail to diagnose real patterns.
2. Lifecycle waste.
Idle compute, orphaned storage, outdated snapshots, forgotten test clusters – these stay unnoticed because ownership is unclear. Automating detection helps, but cleanup still needs a controlled decommission flow to automate cloud cost reduction safely.
3. Multi-cloud without alignment.
Organizations expect multi-cloud cost savings, but without consistent tagging, ownership mapping, and service modeling, each cloud evolves differently. Teams end up duplicating logging, security, networking, and storage across clouds.
4. Hybrid mismatches.
Hybrid footprints increase the chances of drift – old on-prem VMs mapped to deprecated cloud workloads, duplicate storage pipelines, zombie servers no one tracks. The hardest part of hybrid cloud cost reduction is correlating lifecycle data across both worlds.
5. Missed discount opportunities.
AWS/GCP/Azure commitments can deliver massive reductions – yet teams often avoid them due to unreliable forecasts. Even cloud portability cost savings (US) scenarios depend on knowing which workloads are stable enough to commit to.
Read also: 10 Cloud Cost Optimization Benefits or Why It’s a Must In 2026
How to reduce cloud costs: Top overlooked opportunities
Below is a distilled view of the top overlooked opportunities that experienced FinOps and cloud governance teams tend to uncover once they get proper visibility across accounts, clouds, and environments.
| Opportunity area | What teams typically miss | Why it matters for savings |
|---|---|---|
| Environment sprawl | Departments silently spin up dev/test environments that never get cleaned up; no central visibility into who created what | Drives recurring waste across regions and clouds; common in multi cloud for cost savings efforts |
| Misaligned storage tiers | Data stays on expensive storage even after lifecycle changes; no movement to long-term archival or cooler tiers | Significant savings potential, especially for logs, ML artifacts, and backup snapshots |
| Cross-team duplication | Multiple teams run similar pipelines, VPCs, or queues without knowing others already have one | Eliminates hidden duplication that inflates cost reduction cloud computing goals |
| IAM-driven cost drift | Overly broad access leads to accidental resource creation or oversized selections (e.g., bigger nodes than needed) | Quiet “permission-driven waste” that grows slowly but hits multi-cloud bills |
| Data movement patterns | Teams don’t know which apps trigger cross-region or hybrid transfers; egress fees remain a mystery | Critical for hybrid cloud cost reduction and cloud portability cost savings US |
| Underused managed services | Teams pay premium for managed offerings (Kafka/SQS/BigQuery/etc.) but use 5–10% of capacity | Downsizing or architectural swap creates recurring savings |
| Intermediary resources | NAT gateways, transit gateways, load balancers left after migrations or refactors | Often overlooked line items that add up across accounts |
| OCI & niche cloud drift | Side workloads in Oracle Cloud or specialized regions evolve outside governance | Opportunity for Oracle Cloud Infrastructure cost savings through consolidation |
Sustainable savings usually come from deliberate cloud cost optimization strategies, not one-off cleanup exercises.
How Cloudaware helps to turn gaps into cloud savings
Cloudaware doesn’t try to optimize workloads automatically or replace native cloud tools. What it does is give teams the missing layer that makes optimization reliable: a complete, connected view of what they run, who owns it, and how it changes over time.
The strongest foundation comes from CMDB-backed ownership mapping. Every cloud asset is tied to an application, service, and owner. Large organizations like Coca-Cola, Caterpillar, and NASA rely on this because it removes the guesswork behind cost anomalies and lifecycle decisions.
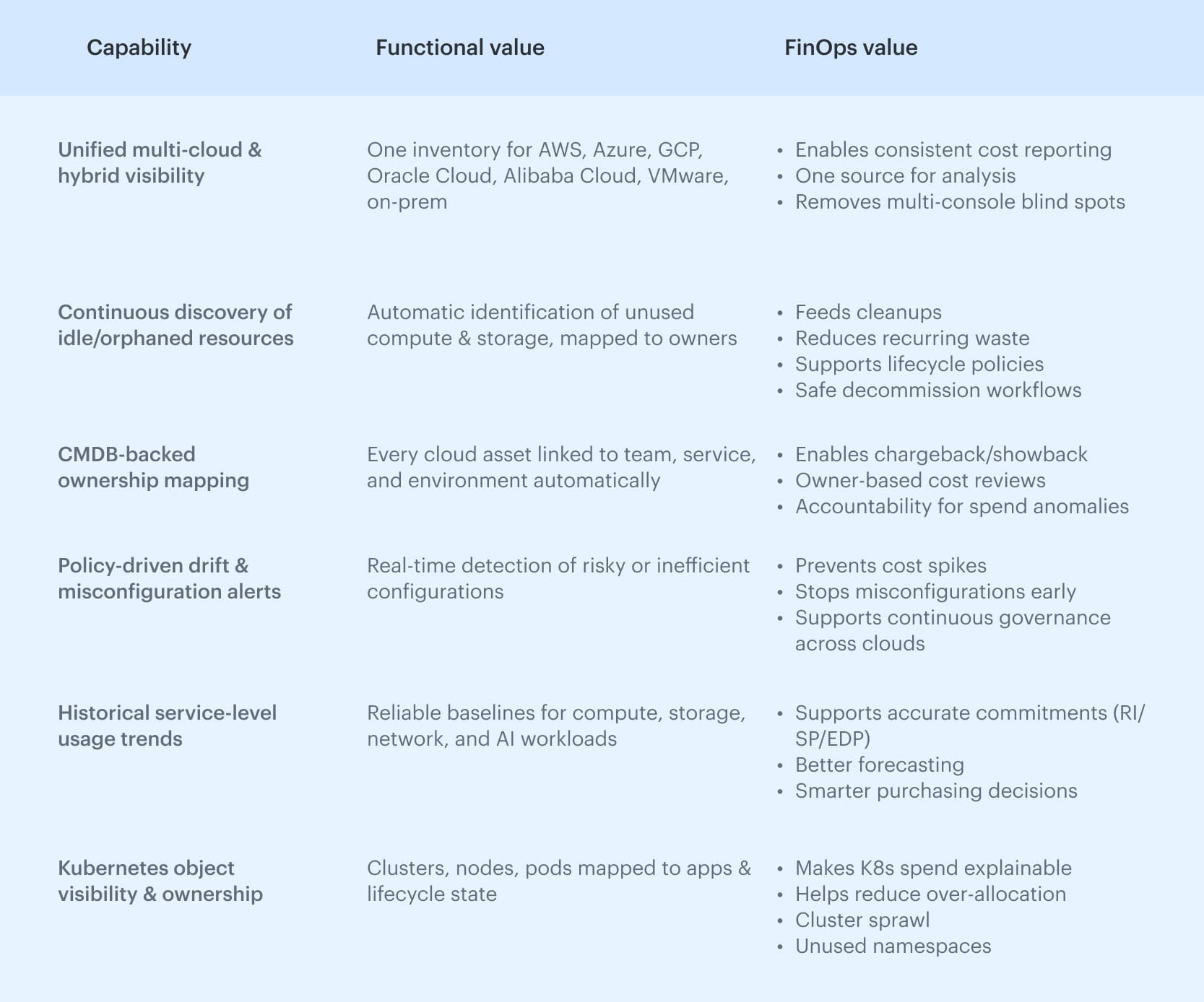
Cloudaware doesn’t replace optimization – it enables it. By showing why spend changes, who drives it, and which assets drift out of alignment, it gives teams the clarity needed to sustain cloud savings rather than chase short-term fixes.