






Kubernetes security still gets treated like a parallel project: a few scanners, a checklist, and a dashboard nobody trusts. Meanwhile, delivery teams ship faster, clusters multiply, and “we will fix it later” becomes the default until a misconfiguration, leaked secret, or permissive workload turns into an incident. The hard part is wiring security into the same paths that ship software, across multiple clouds, without turning CI/CD into a bottleneck.
This article is the playbook I wish I had when I started. It is built from hard-earned lessons. Everything here is designed to be copied, adapted, and enforced with policy-as-code, pipeline gates, and operational patterns that survive real org constraints.
In this playbook, you will get:
- Stage-by-stage control points (PR to CI to CD/GitOps to admission to runtime)
- Platform-specific implementation notes (AWS, Azure, GCP)
- Rollout plan (adoption with ownership routing)
- Best DevSecOps practices you can enforce as guardrails
Implementation blueprint for Kubernetes DevSecOps
This isn't a theory guide. It is how I onboard teams into security controls, starting from the current posture, especially when the product is already running, and the blast radius is real. The first move is to map what exists today across the delivery path and the runtime boundary, then decide what must be enforced immediately versus what can be phased in without breaking releases.
Risk compounds in layers:
- Application layer
- Infrastructure layer
- Network layer
- Runtime layer
Securing the interfaces between those layers matters more than chasing individual findings. The output is a reusable blueprint that turns “best effort” into repeatable controls for DevSecOps Kubernetes programs, with clear ownership and failure criteria.
The blueprint: a control map with an owner, a signal, and an action per gate, plus a minimum Kubernetes security baseline that scales across clouds and clusters.
Everything else in this playbook expands the three checkpoints: what to check before merge, what to block at deploy, what to watch in production, and how to implement it without turning CI/CD into a negotiation. Note: Do not build a control catalog that you cannot implement. A blueprint is only real when enforcement and ownership are operational on day one.
Note: Do not build a control catalog that you cannot implement. A blueprint is only real when enforcement and ownership are operational on day one.
Why Kubernetes DevSecOps breaks and how to fix it
Speed vs security is constant. The fix isn't more tooling. It has automated guardrails and a clean message about impact. Most Kubernetes DevSecOps initiatives fail because they attempt to bolt controls onto an already moving delivery line, then wonder why teams bypass them.
The most common failure mode is uncontrolled sprawl inside the Kubernetes environment. Different teams ship to the same cluster with varying assumptions, risk tolerances, and release pressures. Security becomes “a set of checks” that fire late, produce noise, and land in nobody’s queue. That is how you end up with too many checks, inconsistent policies, and a backlog that never goes down.
Fix it by treating security controls like platform capabilities, not approvals. Automate the guardrails, define ownership per control, and make outcomes measurable. On the defensive side, it often feels like nothing changes, because the best security work is invisible until it prevents an incident. If you don’t turn that into metrics and reporting, it will be deprioritized every quarter.
Non-technical stakeholders don’t buy “more security.” They buy reduced business risk. Frame every enforcement decision in terms of trust, revenue impact, and regulatory exposure, then ship the automation that makes it real.
Threat model and security controls across the stack
Security work gets cleaner when you stop arguing about tools and start classifying controls. In this playbook, every control falls into one of three types:
- Detective: observe and alert
- Preventive: block and reject
- Corrective or deterrent: contain, rollback, or fix automatically
Threat modeling is like a routing table. Track three leverage points attackers use to move fast: identity, network reachability, and workload execution. Since most incidents start from misconfigurations that quietly expand privileges or connectivity, lock enforcement at the Kubernetes cluster boundary. Keep it non-negotiable, because that is where “best effort” becomes a reality in a cluster.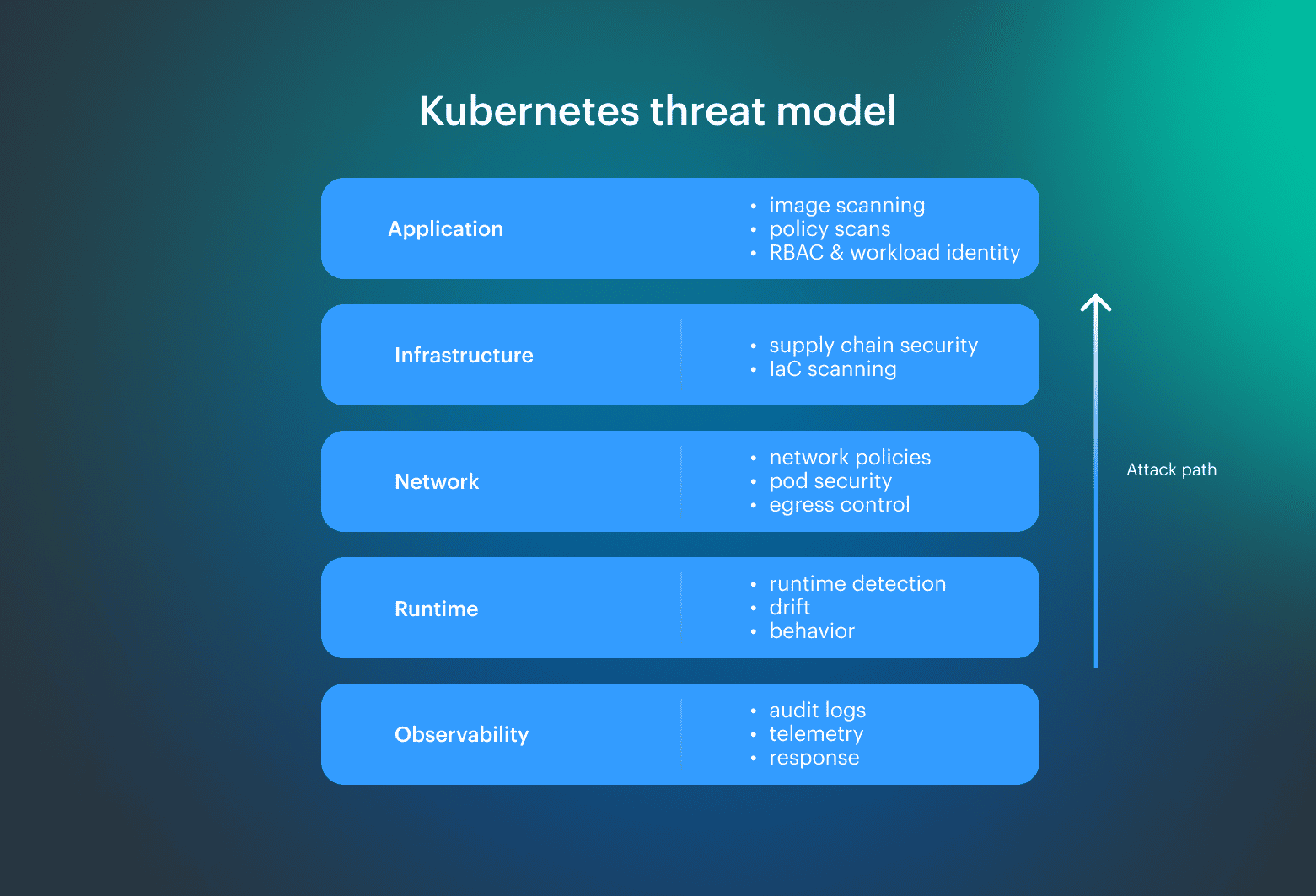 Vulnerability scanning can be detective or preventive, depending on where it runs. If it only produces a report after build, it is a detective. If it blocks a pipeline or rejects a release at deploy time, it is preventive; that distinction matters because it changes behavior.
Vulnerability scanning can be detective or preventive, depending on where it runs. If it only produces a report after build, it is a detective. If it blocks a pipeline or rejects a release at deploy time, it is preventive; that distinction matters because it changes behavior.
Use one shared analogy set so teams stay aligned:
| Control type | Mental model | Typical output | Rollout note |
|---|---|---|---|
| Detective | Cameras plus a guard in a store | Alert, ticket, dashboard signal | Easiest to ship first, low risk |
| Preventive | TSA and real ID | Blocked build, rejected admission, failed gate | Best ROI when tuned, reduces exposure |
| Corrective or deterrent | Fix the broken lock after a break-in | Rollback, quarantine, auto-remediation | Hardest to operate, requires ownership, and safe automation |
By the way, access control is the highest leverage preventive control in the stack. If identity is loose, everything else becomes cleanup.
Read also: DevSecOps Vulnerability Management: A Weekly Loop That Survives Critical Spikes
DevSecOps flow: stage-by-stage control points
This section is the operating workflow for putting security controls where they change outcomes. Usually, I start with assessment and interviews; then pick scanning based on business impact, because controls that ignore impact quickly become either bypassed or resented.
Run the flow in this order:
- Assess posture and interview the dev team on existing controls
- Select control types by risk and application impact
- Onboard tools only after control points are defined
- Automate in the pipeline so every commit gets feedback
- When architecture changes, rerun threat modeling and risk assessment
Manual scans are not the value here; the value is pipeline feedback per commit. A control point must either block, route, or record evidence. If it does not do one of those, it is noise. Treat guardrails the same way: if it isn't enforced at a control point, it becomes optional, and teams will eventually ship around it.
This is where Kubernetes DevSecOps becomes operational security. It defines what must be verified early, what must be enforced at release, and what must be monitored in the running environment so controls stay tied to decisions.
To keep this workflow stable under delivery pressure, enforcement has to be anchored at explicit decision points with clear owners and failure criteria. Next come the checkpoints that turn this workflow into enforcement.
Read also: DevSecOps vs CI/CD: How to Build a Secure CI/CD Pipeline
Checkpoint #1: pre-merge security gates
In this playbook, “pre-merge security gates” are the decisions enforced before changes hit main. This checkpoint keeps risky code and config from turning into an incident downstream, when the cheapest fix is already gone. The gate only blocks deterministic, high-impact outcomes. Everything else stays informational and gets routed without blocking.
PR checks that prevent misconfigurations
Minimum PR gate pack, run on every change set:
- SAST for code (examples: Checkmarx, Snyk)
- SCA for dependencies and transitive graph (example: Black Duck)
- IaC and manifest scanning for misconfigurations (examples: Trivy, Snyk)
- Secret scanning so secrets never land in git
Attackers can look up public CVEs and weaponize them quickly; reducing known vulnerabilities reduces exposure. For IaC and YAML, treat the repo as a production surface and block the deltas that change blast radius.
Add at least one rule that catches container configuration mistakes in manifests, since one bad flag can invalidate multiple layers of security at once. This is also where misconfigurations are cheapest to fix, because context is still inside the PR.
PR gates developers will not bypass
Shift left to meet developers where they work; automation beats approvals. Use secure defaults so reviewers mostly approve intent, not re-litigate baseline hardening, and make exceptions explicit so they are easy to audit later.
The checkpoint should produce a single actionable outcome per failure, with a clear owner, so security fixes stay in the same PR and don’t become a separate queue.
Read also: Six pillars of DevSecOps. Practical Guide to Their Implementation in a Pipeline
Checkpoint #2: admission control and security policies
Checkpoint two is the enforcement line at the deployment boundary. It is the moment where preventive controls stop unsafe changes from entering a cluster, even if they passed earlier stages, and it is where policy becomes non-optional.
In a DevSecOps Kubernetes model, this checkpoint is the difference between “we recommend” and “we enforce” for security.
Admission is designed for preventive decisions. If a workload violates security policies, it gets rejected during deployment. That is how you prevent misconfigurations from becoming production reality.
Pipeline gates can be preventive too when they block high or critical findings, but admission is the last consistent point of control because it evaluates what is actually being applied to the API, not what the pipeline assumed.
Keep this checkpoint explicit:
- One enforcement layer at the control plane
- One set of policies per environment baseline, with documented exceptions
- One enforcement decision per failure, with clear ownership and a remediation path
Automatic correction is the hard part. Start with prevention and detection, then add correction only when rollback paths and ownership are mature. Otherwise, you will create unstable automation that breaks delivery under load.
OPA Gatekeeper vs Kyverno
Pick one admission engine and standardize, but don’t run two engines for the same class of rules, because duplication becomes drift.
Gatekeeper when you want OPA and Rego, strong governance patterns, and centralized policy lifecycle
Kyverno, when you want Kubernetes-native policy definitions, simpler authoring, and a tight fit with YAML workflows
Whichever you choose, treat policy authoring like code: version it, test it against real manifests, and promote it through environments the same way you promote application changes. This checkpoint only works when the rules are predictable and consistently enforced across every cluster.
Supply chain integrity
“Supply chain integrity” means controlling what becomes a deployable artifact before it ever touches Kubernetes. The container image is often the first line of defense, because everything else inherits from it. Harden early in the pipeline, then make the artifact verifiable later when it moves across registries, environments, and clusters.
Start from two realities: Teams don’t write everything from scratch, so dependency risk is always present. Also, image content changes faster than most governance processes, so you need controls that scale without manual review. Keep this checkpoint focused on repeatable artifact guarantees: what went into the container, where it came from, and whether it can be trusted.
Supply chain baseline you can enforce
Minimum baseline for container security:
- Generate an SBOM for every container build and retain it with the image metadata
- Attach provenance that ties the build back to the source code and build context
- Sign the container image and verify signatures at pull and deploy points
- Restrict pulls to trusted registries and approved base images
- Run one pass of image and dependency scanning as part of the build flow
This checkpoint is where “secure” becomes measurable. Here you are trying to prevent unknown and untrusted artifacts from entering your delivery system, while keeping security decisions fast enough to ship. When teams accept that dependencies are a supply chain, hardening stops being a one-off effort and becomes a default security posture.
Read also: 9 DevSecOps Benefits for Security Leaders [With Proof]
Pod security in 2026: PSP vs PSA/PSS
Pod security in 2026 is an enforceable baseline built on Pod Security Admission and Pod Security Standards, applied per namespace with restrictions where they matter and a strict exception workflow so posture does not collapse as teams and clusters scale. Kubernetes applies these restrictions at the namespace level, which makes namespace strategy the control surface rather than an afterthought.
The model changed when PodSecurityPolicy was removed. PSP relied on custom policy objects and admission controllers. PSA with PSS provides a built-in Kubernetes mechanism that applies security profiles through namespace labels.
Use the table below as a quick comparison:
| Capability | PodSecurityPolicy (PSP) | Pod Security Admission + PSS |
|---|---|---|
| Status | Deprecated and removed | Current Kubernetes-native model |
| Enforcement model | Custom policy objects evaluated by admission controller | Built-in admission with namespace labels |
| Scope | Cluster-wide policy objects | Namespace-level enforcement |
| Operational complexity | High. Requires policy lifecycle management and RBAC bindings | Lower. Profiles applied through labels |
| Policy model | Fully customizable but operationally heavy | Standardized profiles (privileged, baseline, restricted) |
| Exception handling | Custom logic and bindings | Namespace-level overrides and scoped exceptions |
| Adoption path | Legacy clusters only | Recommended baseline for modern clusters |
Migrating from deprecated PodSecurityPolicy to PSA/PSS safely
Do this migration if you have PSP-era intent anywhere in the platform, or if you need a consistent workload baseline across clusters without custom glue.
The goal is simple: replace legacy enforcement with native namespace-based profiles, then make exceptions auditable and timeboxed. Kubernetes removed PSP, so keeping “PSP-like” behavior typically means drift and inconsistent enforcement.
Migration flow:
- Export PSP intent and group it by namespace and workload class.
- Map namespaces to target PSS profiles, then label them in audit first.
- Fix top violations in templates and repos, not by patching live objects.
- Enable warn, then switch to enforce once violations stabilize and exceptions are live.
- Require exceptions with owner and expiry; review expirations on a cadence.
Read also: DevSecOps vs Agile Explained for Delivery Teams
Kubernetes secrets management
The most important thing outside of all of those is Kubernetes secrets and data protection, because apps still have to reach out to get secrets. Treat them as an access path, not a storage feature, and design for the two failure modes that matter: exposure in repos and exposure in prod through identity.
The hard part is that secrets rarely live only inside the cluster. A common pattern is cloud identity bridging during deployment, then execution-time access to an external system of record.
Example in AWS: a service account maps to an IAM role outside the cluster, that role grants permission to reach the database, and the app retrieves credentials or tokens on demand. That chain is where most security gaps appear, because each hop becomes another place to over-permission or lose auditability. Keep the chain short, scoped, and observable.
Secret delivery without long-lived credentials
Use a secure delivery pattern that matches how your platform actually runs:
- Encrypt secrets at rest and enforce encryption for the control plane
- Prefer external secret stores with short-lived credentials, then sync or inject at runtime
- Rotate on a schedule and on incident triggers, then validate that rotation actually invalidates old values
- Limit read scope to the minimum identity, then audit reads and failures
This section should leave you with one clear link into the next checkpoint: least privilege isn't optional. Secrets and identity are the same problem in different layers and security posture.
Read also: DevSecOps Statistics (2026): Market, Adoption, and AI Trends
Access security: RBAC and workload identity
Least privilege has to work at two levels: the pod or service account, and the underlying node. If either layer is over-permissioned, you will end up doing cleanup work after an incident instead of preventing it. Here treats identity as part of the platform contract, because it is the control that decides what happens after the first foothold.
That chain is normal in Kubernetes across AWS, Azure, and GCP, but it becomes fragile when it is managed informally or copied between teams. Keep identities scoped to the minimum for the workloads they serve, make permissions explicit, and keep the blast radius bounded to a namespace and environment.
RBAC design that scales
Treat RBAC changes as high-impact, review them like application changes, and keep drift visible so security posture stays stable over time. Use this RBAC design principles table as the baseline. It keeps role sets standard, prevents role explosion, and makes break-glass and drift visible. Start with a small set of standard roles per namespace, prefer aggregation over one-off roles, and keep break-glass access separate with strict controls and visibility.
Start with a small set of standard roles per namespace, prefer aggregation over one-off roles, and keep break-glass access separate with strict controls and visibility.
Read also: DevSecOps Roles and Responsibilities. Who Does What?
Network segmentation with namespaces and policies
Here, we solve one problem: stop lateral movement inside the Kubernetes cluster without turning every release into a ticket. The baseline is default-deny per namespace, a small allow-list of shared flows, and a controlled egress path so a compromised container cannot roam. That is securing the network layer in a playbook.
Use namespaces as the segmentation boundary. Each namespace gets default-deny for ingress and egress, then you open only the flows required to run.
Minimum allow-list flows most namespaces need:
- DNS to the cluster DNS service
- Metrics scraping to your telemetry stack
- Ingress from the approved ingress gateway
- Egress to approved shared services and endpoints
Do not let workloads talk directly to the internet. Route outbound traffic through an egress gateway or proxy where you can enforce allow-lists, log, and revoke quickly.
Store baseline rules and per-namespace overlays in the delivery repo, and assign an owner for each namespace policy surface. This improves security without slowing delivery.
Runtime security: detection, response, and drift control
Runtime security starts with detection tied to action; alert-only is not a control. Treat the runtime as “cloud inside a cloud” and monitor what executes, what escalates, and what reaches out inside the cluster.
Here, drift turns yesterday’s baseline into today’s misconfigurations, and one compromised container can pivot fast if exec, privilege changes, or outbound paths are open. Keep signals high-signal and owned, and response steps short and safe.
Signals that matter in runtime
The most important signals are the ones that show attacker progress. Track them with a small, stable toolchain and route signals to owners by namespace and workload.
- Interactive exec into pods. Unexpected exec, shell spawn, or debug tooling inside a running workload. Tool: Falco for event detection; Grafana for triage view.
- Privilege escalation attempts. New capabilities, privileged flags, sensitive mounts, or suspicious process behavior tied to escalation. Tool: Falco for escalation patterns; Prometheus for counters and alert thresholds.
- Anomalous egress. Sudden outbound spikes, new destinations, unusual DNS patterns, or traffic bypassing approved routes. Tool: Prometheus for rate anomalies and baselines; Grafana for destination and timeline correlation.
How to contain fast and roll back clean
Runtime detection without response is visibility without control: triage scope first, then contain fast:
- Confirm scope: namespace, node, identity, recent change
- Contain: isolate workload, cut egress, revoke credentials where possible
- Preserve evidence: logs, events, execution traces
- Roll back: deployment rollback is often the fastest containment
Read also: 8 DevSecOps Container Security Vulnerabilities and How to Fix Them
Observability and audit evidence for compliance
In a Kubernetes environment, a common failure mode is missing timelines. Teams scramble to reconstruct “what happened when” from logs and screenshots, then hope nothing is missing when auditors ask for evidence.
What auditors typically care about is a defensible chain: who changed what, when it was approved, what ran in prod, and so on. Build the chain once, then reuse it across audits and incidents.
Use a small, stable stack for this. Cloudaware fits here as the system that stitches context and ownership around evidence in your cluster by mapping assets and relationships, then connecting change context and telemetry to specific workloads so evidence is queryable by service, namespace, owner, and environment.
Platform-specific implementation notes
In Kubernetes DevSecOps, the platform details change, but the control points stay the same. Treat cloud integrations as implementation adapters; keep your Kubernetes security baseline portable so you can enforce it across any cluster without rewriting your model.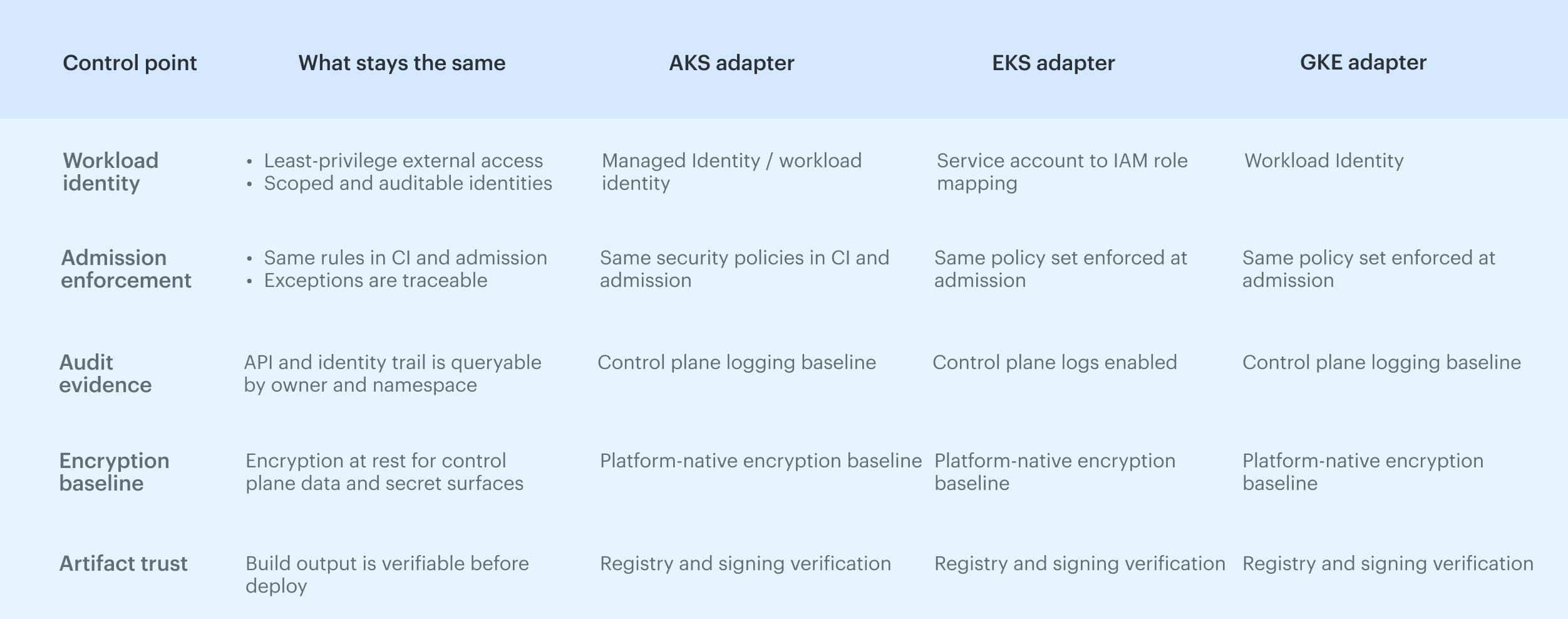 The only platform-specific rule that matters: use native identity primitives for external access, then verify them with the same guardrails you apply to everything else, including container provenance, admission enforcement, and audit evidence.
The only platform-specific rule that matters: use native identity primitives for external access, then verify them with the same guardrails you apply to everything else, including container provenance, admission enforcement, and audit evidence.
DevSecOps Kubernetes rollout plan
This DevSecOps Kubernetes rollout works for most teams because it follows control points that already exist in the delivery path, regardless of tooling. It is grounded in practical patterns that scale: baseline security guardrails at the cluster boundary, phased enforcement, and automation that keeps security controls stable as the cluster and teams grow. Use this rollout as a baseline, then adapt the enforcement point to your stack. The sequence stays stable because it is tied to code templates, artifact promotion, policy decisions, scanning coverage, and runtime evidence; that is how DevSecOps Kubernetes scales across accounts and clusters while staying secure and consistently securing the delivery flow.
Use this rollout as a baseline, then adapt the enforcement point to your stack. The sequence stays stable because it is tied to code templates, artifact promotion, policy decisions, scanning coverage, and runtime evidence; that is how DevSecOps Kubernetes scales across accounts and clusters while staying secure and consistently securing the delivery flow.