






Pipelines that used to be predictable begin to stall once security gates are added. Application security findings keep showing up late in the development lifecycle, when fixing them means rework, exceptions, or uncomfortable trade-offs between speed and risk. Cloud environments drift out of policy even though everyone agreed that security was already “shifted left.”
At first, teams assume this is a tooling problem. Maybe the scanners are misconfigured. Maybe the rules are too strict.
This is usually the moment when the SecDevOps vs DevSecOps difference becomes a real discussion instead of an abstract one. Not because teams enjoy debating frameworks, but because the current approach no longer matches how the organization actually builds, deploys, and operates software in the cloud.
In this article you’ll see:
- How DevSecOps vs SecDevOps actually plays out in real cloud teams
- Why organizations keep switching between these models
- Where security decisions land across the development lifecycle
- Which security controls create value and which create friction
- How Cloudaware helps connect development intent with runtime reality
Why teams argue about SecDevOps vs DevSecOps at all
Most teams already practice some form of DevSecOps. They scan code, run tests, and gate deployments. Yet security incidents still happen, and pipelines still feel fragile.
Pipelines that once ran predictably begin to stall. Security checks fail inconsistently, and engineers learn to work around them. Vulnerabilities surface when features are already merged, tested, or even deployed. Cloud environments drift out of policy despite the presence of “shift-left” controls.
At that point, teams look for an explanation, and the SecDevOps vs DevSecOps debate becomes a convenient shorthand for a deeper operational problem.
Why each role experiences the same problem differently
The disagreement persists because each group feels the failure in a different place.

Platform teams tend to see security as a delivery problem. AppSec teams see it as a timing and context problem. Cloud security teams see gaps that never pass through pipelines at all. SecOps sees the consequences when prevention fails. Leadership sees all of it translated into cost and uncertainty.
Why the argument keeps resurfacing over time
When DevSecOps feels too reactive, teams start pushing security earlier, hoping to reduce late-stage surprises. When SecDevOps feels too restrictive, teams loosen controls to regain speed. Without shared visibility and clear ownership, organizations oscillate between the two models.
Processes get renamed, tools change, but the underlying issue remains: security decisions are not consistently aligned with how software is built, deployed, and operated in cloud environments.
Until teams agree on where security decisions should live and who owns their impact, the argument will keep coming back — regardless of which term is currently in fashion.
Read also: DevSecOps vs DevOps. What’s the Difference [Explained by a Pro]
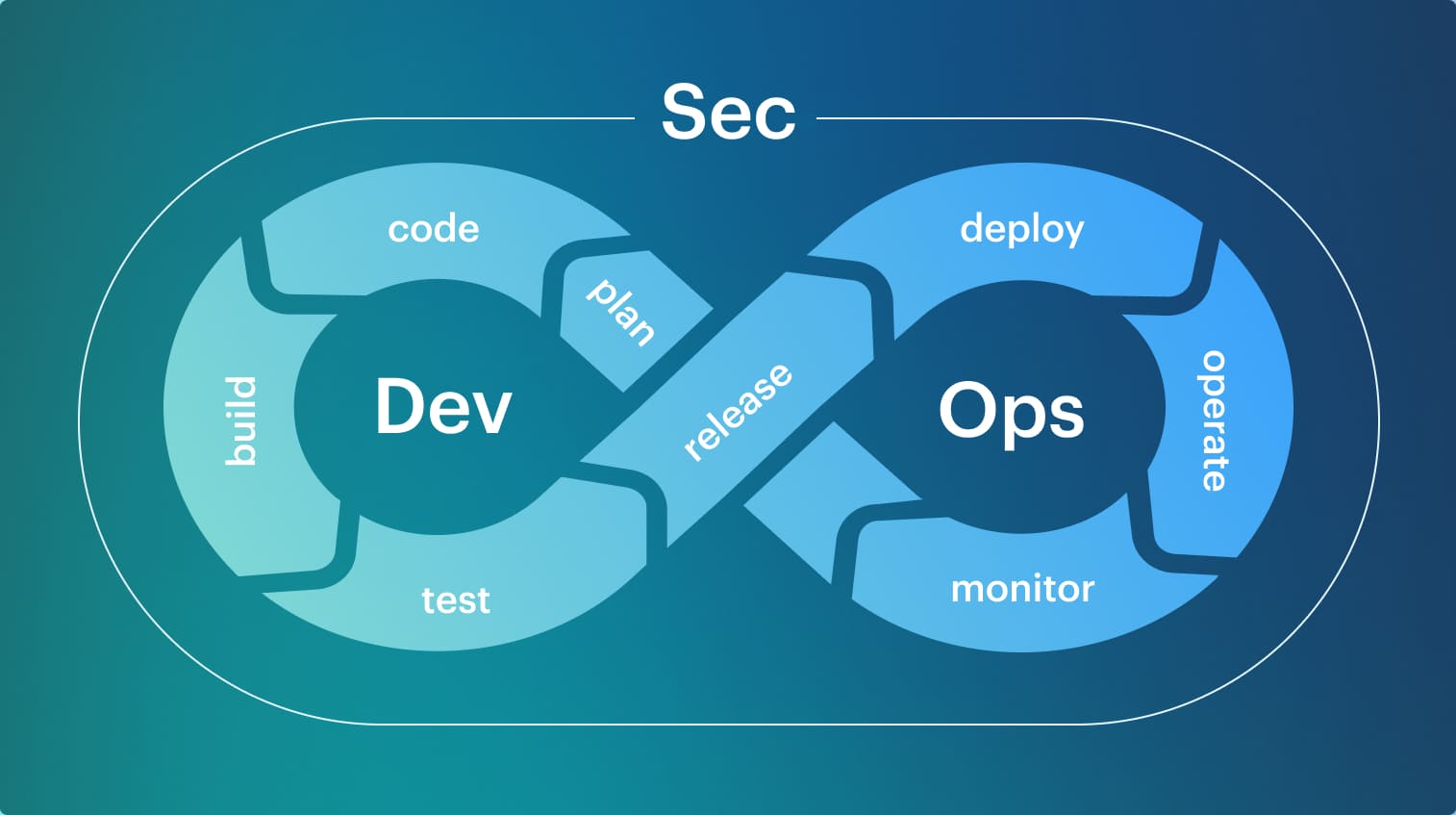
DevSecOps vs SecDevOps: definitions and explanations
The most practical way to understand the SecDevOps vs DevSecOps difference is to look at where security decisions are enforced across the development lifecycle. The same controls behave very differently depending on whether they trigger during design, build, deploy, or runtime.
In DevSecOps, most security decisions surface during build and deploy. You can learn more in our guide “What Is DevSecOps: Definition, Security, and Methodology.”
In SecDevOps, many of those decisions are made earlier, before development accelerates.
Read also: 4 DevSecOps Implementation Steps That Hold Under Release Pressure
What DevSecOps actually means for security teams
In real teams, DevSecOps is rarely a clean transformation. Nobody wakes up and declares a new operating model. What usually happens is simpler: security tooling gets pulled into an existing DevOps flow because releasing fast without any checks stopped feeling safe.
DevSecOps, in practice, means security shows up where developers already work. Scans run in CI, policies fail builds, findings land in pull requests. The expectation is straightforward: if a change introduced a problem, the team that made the change fixes it.
Most working DevSecOps setups share a few traits:
- Security checks are automated and run by default
- Feedback is fast enough to act on without context loss
- Ownership stays with the delivery team
- Manual approvals are treated as exceptions, not the norm
This model holds up well when problems are local and fixes are cheap. It starts to crack when issues depend on architecture, identity design, or cloud runtime behavior — things that cannot be fixed by adjusting a single commit.
Read also: DevSecOps vs Agile - Agile DevSecOps Explained for Delivery Teams
What SecDevOps emphasizes differently
SecDevOps flips the order of influence. Instead of asking how security fits into delivery, it asks what delivery is allowed to look like in the first place.
In teams leaning toward SecDevOps, security has a stronger voice earlier. Architecture choices, trust boundaries, and data handling rules are shaped before development gains momentum. Some designs never make it into a backlog because the risk is already understood.
In practice, SecDevOps usually shows up as:
- Early security involvement in design discussions
- Predefined patterns for identity, networking, and data flows
- Fewer “fix it later” decisions
- Less surprise after deployment
This reduces late-stage rework and uncomfortable trade-offs, especially in regulated or high-impact environments. The cost is paid upfront. Decisions take longer. Exploration is more constrained. For some teams, that is a fair trade. For others, it feels heavy.
The difference between DevSecOps and SecDevOps becomes easier to reason about when you strip away the labels and look at where friction actually comes from.
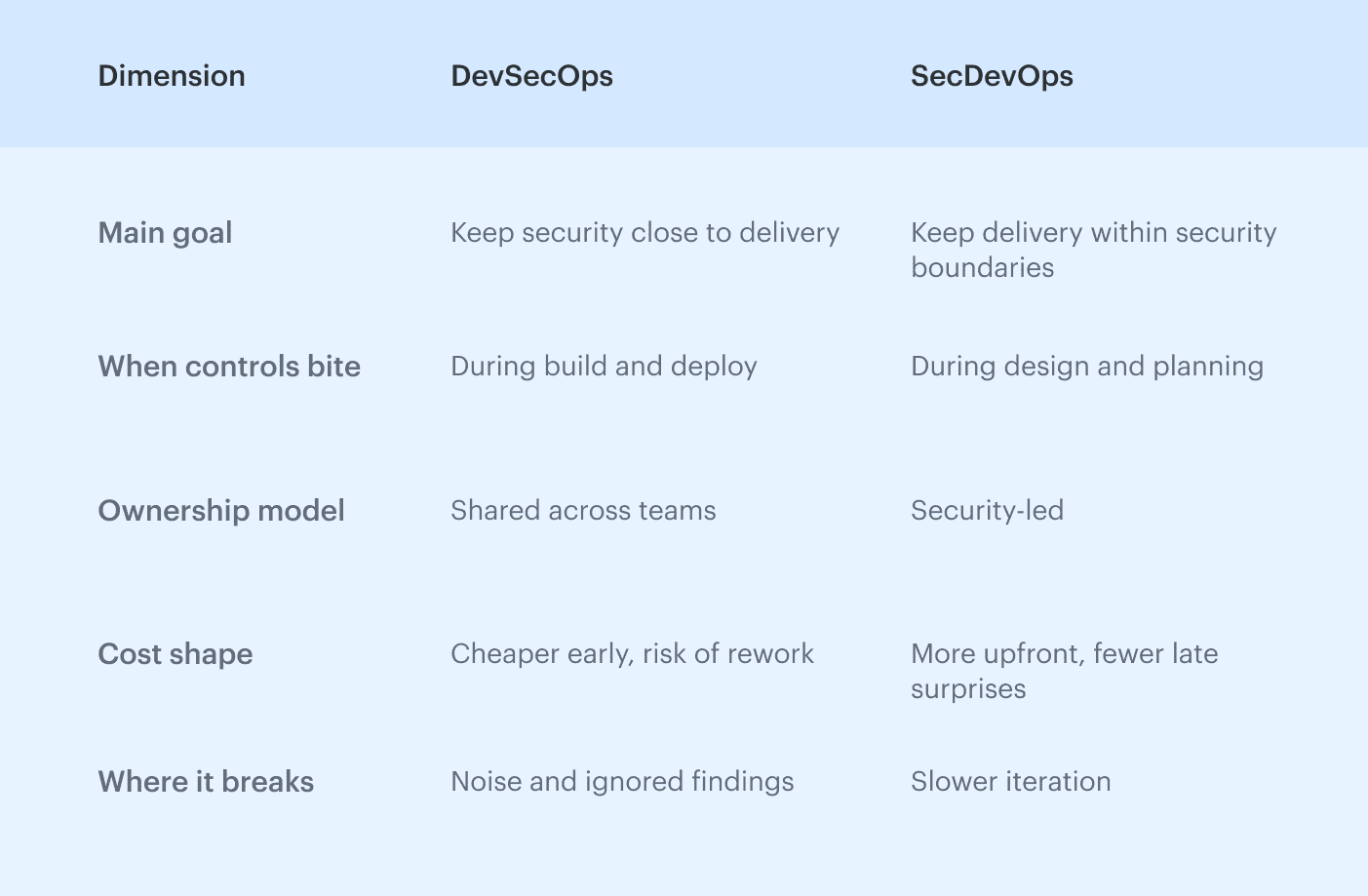
DevSecOps vs SecDevOps difference across the development lifecycle
How DevSecOps behaves across the lifecycle
Across the development lifecycle, DevSecOps tends to concentrate security activity where change is fastest. The model assumes that most meaningful risk is introduced while code and infrastructure definitions are actively evolving, and that fast feedback is more valuable than early constraint.
What this looks like in practice is not a checklist of tools, but a pattern of behavior:
- Security findings appear close to commits and pull requests
- Teams expect to remediate issues within the same sprint
- Failures are tolerated as long as they are reversible
- Runtime is treated as relatively stable once deployment succeeds
This approach aligns well with teams that ship often and rely on iteration to refine both functionality and security. Risks that emerge slowly tend to escape attention because they are not tied to a single change event.
DevSecOps does not ignore these risks by design, but it rarely prioritizes them unless something breaks.
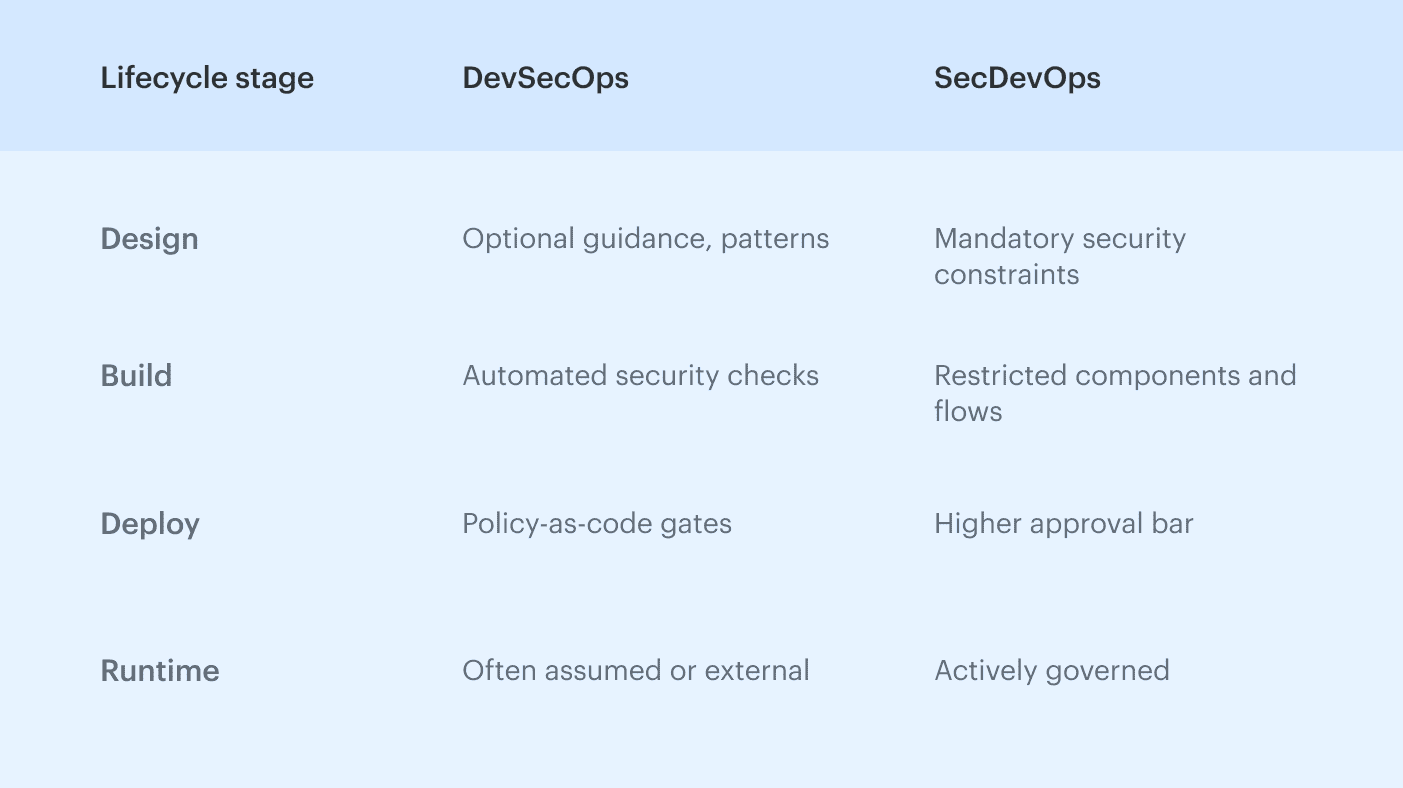
How SecDevOps behaves across the lifecycle
SecDevOps distributes security pressure differently. Instead of concentrating it around change events, it spreads constraints across the lifecycle, starting earlier and persisting longer.
In teams operating closer to SecDevOps, the lifecycle behaves differently:
- Design stages carry explicit security expectations
- Architectural choices reduce the number of possible failure modes
- Deployment is less flexible, but more predictable
- Runtime governance is an extension of design intent
The practical effect is fewer surprises after systems are live. Many issues never appear because the conditions that enable them were ruled out earlier. The cost is paid upfront. Decisions take longer, and experimentation requires stronger justification.
This is not accidental friction. It is a deliberate choice to trade speed for control in environments where late fixes are unacceptable.
Read also: DevSecOps Framework in 2026 - NIST, OWASP, SLSA, and How to Choose the Right One
How DevSecOps security controls actually work
Controls that fit naturally into DevSecOps pipelines
DevSecOps security controls work best when they behave like engineering feedback, not like approvals. In practice, the controls that fit naturally into DevSecOps pipelines share one thing: they fail in a way developers can immediately understand and fix.
Typical examples include:
- Application security scans tied directly to code changes
- Dependency and package analysis during build
- Container and image scanning before deploy
- Infrastructure-as-code validation against explicit policies
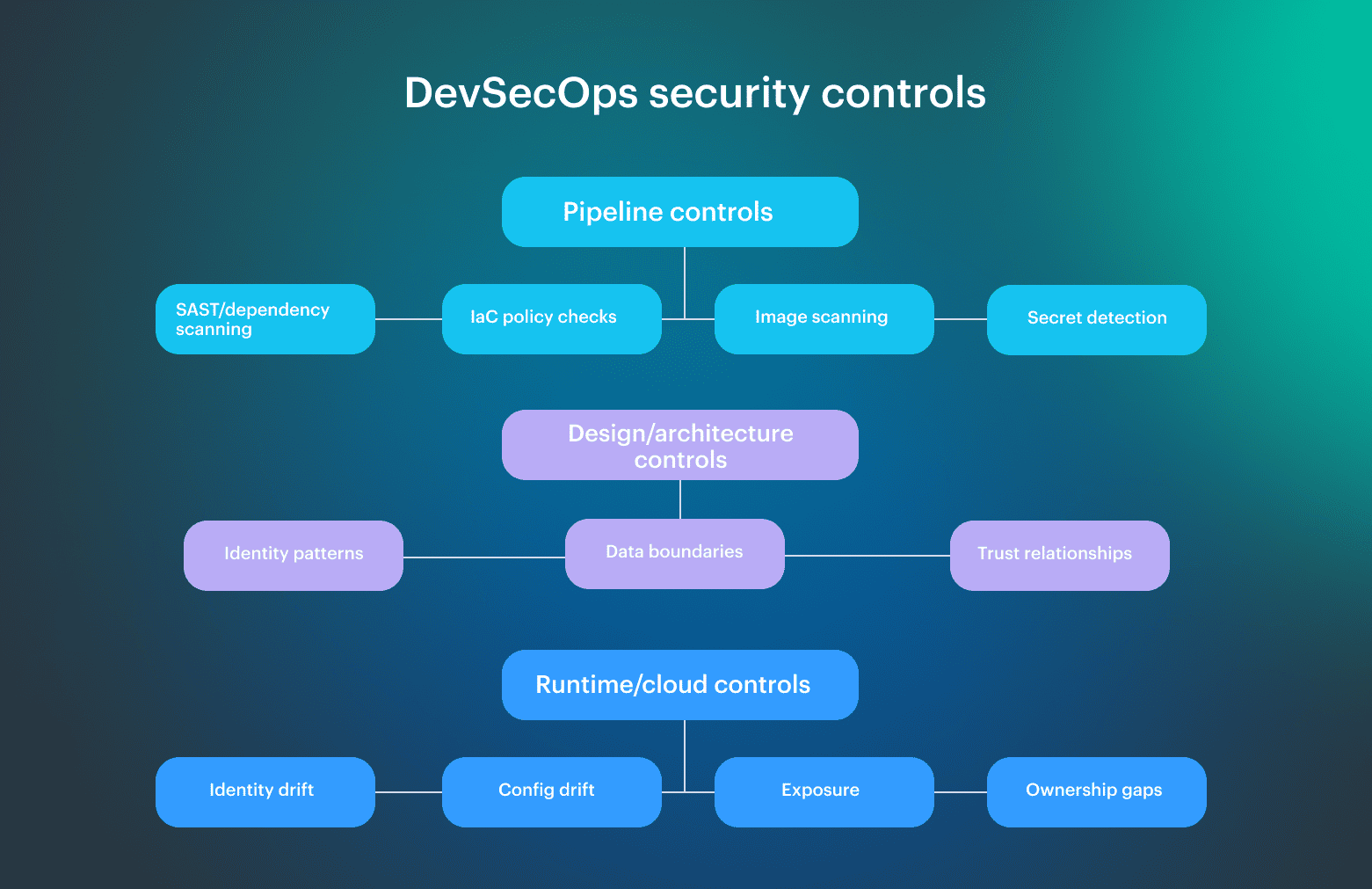
These controls align well with how developers already think. A failure maps to a commit, a pull request, or a template. Ownership is obvious, but fixes are local. This is where DevSecOps security controls actually reduce risk instead of generating backlog.
From an AppSec perspective, this is also where signal quality matters most. When findings are specific and actionable, teams fix them. When findings are vague or systemic, they get deferred.
Read also: 15 DevSecOps Tools. Software Features & Pricing Review
Controls that usually push teams toward SecDevOps
Some controls technically can be automated, but consistently cause friction when enforced late in the pipeline.
Typical examples include:
- Identity and access models that span multiple services or accounts
- Data handling and isolation requirements
- Cross-environment trust relationships
- Controls that depend on runtime context rather than code
When these controls fail in CI/CD, developers often cannot act on them meaningfully. Fixing the issue may require architectural changes, coordination across teams, or risk acceptance decisions. At that point, the control stops being feedback and starts functioning as a gate.
This is usually when teams begin drifting toward SecDevOps patterns, even if they still call their approach DevSecOps. The issue is not automation itself, but timing.
Read also: DevSecOps Architecture (A Practical Reference Model Teams Actually Use)
Automated security versus manual gates
The tension between automation and manual review is often misunderstood. The real problem is not automation versus humans, but where judgment is applied.
| Approach | What works | What breaks |
|---|---|---|
| Automated controls | Scale, consistency, fast feedback | Noise if signal is weak |
| Manual gates | Context-aware decisions | Bottlenecks and delays |
Effective security DevSecOps setups use automation to enforce known rules and reserve human review for decisions that genuinely require context. When everything becomes a gate, pipelines slow down. When nothing is reviewed, risk slips through unnoticed.
This balance is difficult to maintain once systems are live and changes happen outside CI/CD. Cloudaware helps by tracking changes across cloud and on-prem environments, validating them against policy, and recording approvals and audit trails. That visibility makes it possible to manage security debt and understand which changes were made, where, and with whose approval.
DevSecOps vs cloud security and runtime reality
DevSecOps is often described as the bridge between development and security. In practice, it is a very effective bridge — but only up to a certain point. That point is deployment.
Once workloads are live, cloud environments keep changing in ways that pipelines were never designed to observe or control. This is where cloud security and runtime reality start to diverge from DevSecOps assumptions.
Why DevSecOps stops at the pipeline
DevSecOps security controls are built around change events. A commit triggers a build. A build triggers tests. A deployment triggers policy checks. As long as change flows through CI/CD, DevSecOps has visibility and leverage.
The problem is that much of what changes in the cloud never passes through a pipeline. Permissions are adjusted manually. Shared services are reused. Temporary access becomes permanent. These changes are invisible to pipeline-based controls because no new code was deployed.
Read also: DevSecOps Statistics (2026). Market, Adoption, and AI Trends
Where cloud-native systems introduce new risk
In cloud environments, risk almost never appears as a single breaking change. It builds up gradually. A permission added here, a configuration adjusted there, a service reused for a purpose it was not originally designed for. None of these changes look dangerous on their own, but over time they accumulate.
What teams usually run into looks like this:
- Roles and service accounts slowly gaining permissions “just in case”
- Configurations drifting across regions and accounts as environments evolve
- Services exposed outside the original delivery workflow
- Resources that still function but no longer have a clear owner
Each of these is easy to ignore in isolation. The problem only becomes visible once their combined effect surfaces. A permission that once seemed harmless ends up protecting sensitive data. A small network change exposes a service no one remembers deploying. By the time this is noticed, the original context is gone.
Read also: 13 DevSecOps Metrics for 2026. What to Measure and Why?
Why neither SecDevOps nor DevSecOps fully solves runtime drift
SecDevOps pushes security decisions earlier and reduces certain categories of risk, but it does not stop environments from evolving after deployment. Even tightly governed systems change. Exceptions accumulate. New dependencies appear.
DevSecOps, on the other hand, often assumes that what passed the pipeline remains valid in production. In dynamic cloud environments, that assumption degrades quickly.
Both models struggle with the same reality: runtime drift exists outside their primary control loops.
Read also: How to Build a Secure DevSecOps Toolchain Without Alert Fatigue
When to choose SecDevOps or DevSecOps (and why most teams don’t fully choose either)
At some point, most organizations stop asking which model is “better” and start asking a different question: what kind of failure can we afford, and when do we want to catch it?
That shift in framing is what separates theoretical debates from real decisions.
High-risk and regulated environments
In environments where failure has clear legal, financial, or safety impact, SecDevOps tends to dominate — even if nobody calls it that explicitly.
These teams optimize for predictability and risk reduction. Architectural constraints are accepted early. Security requirements shape design choices before delivery speed becomes a concern. Fewer things are allowed to change freely, and that is intentional.
The upside is fewer late-stage surprises and fewer uncomfortable conversations with auditors or regulators. The downside is slower experimentation and higher upfront cost. For CISOs in these environments, that trade-off is usually acceptable. The cost of a late fix is simply too high.
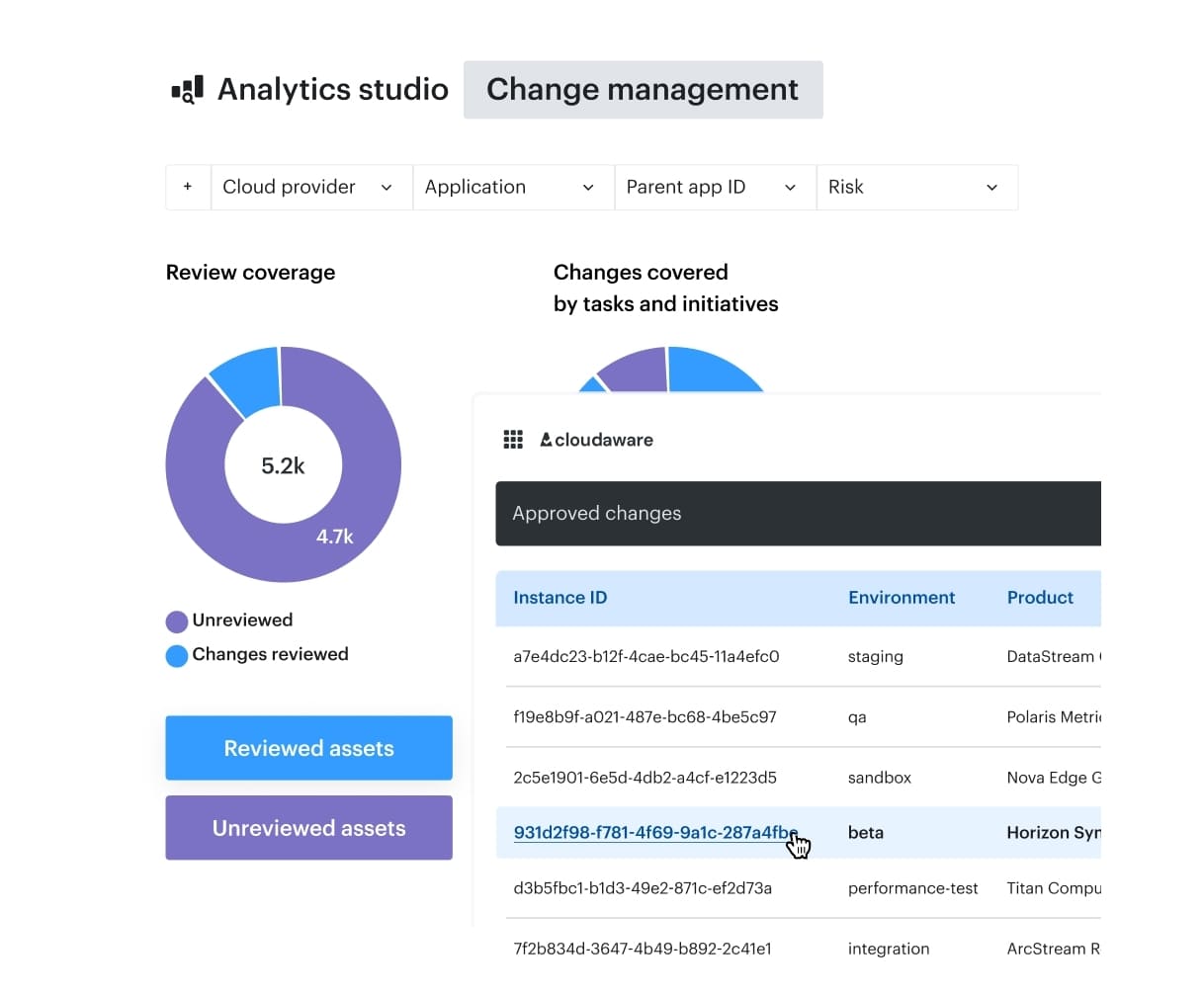
Cloudaware supports these environments by tracking infrastructure and configuration changes across cloud and on-prem systems, validating them against policy, and recording approvals with a complete audit trail.
Product teams optimizing for speed and scale
Product-driven teams face a different pressure. They ship frequently, learn from production, and rely on iteration to improve both functionality and security. For them, DevSecOps usually produces better outcomes.
Security controls are embedded into delivery workflows. Feedback arrives fast enough to act on. Ownership stays close to the teams making changes. Risk is managed incrementally rather than eliminated upfront.
This model works as long as security signals remain actionable and runtime risk does not drift too far from what pipelines can see. When that drift grows, speed turns into blind spots.
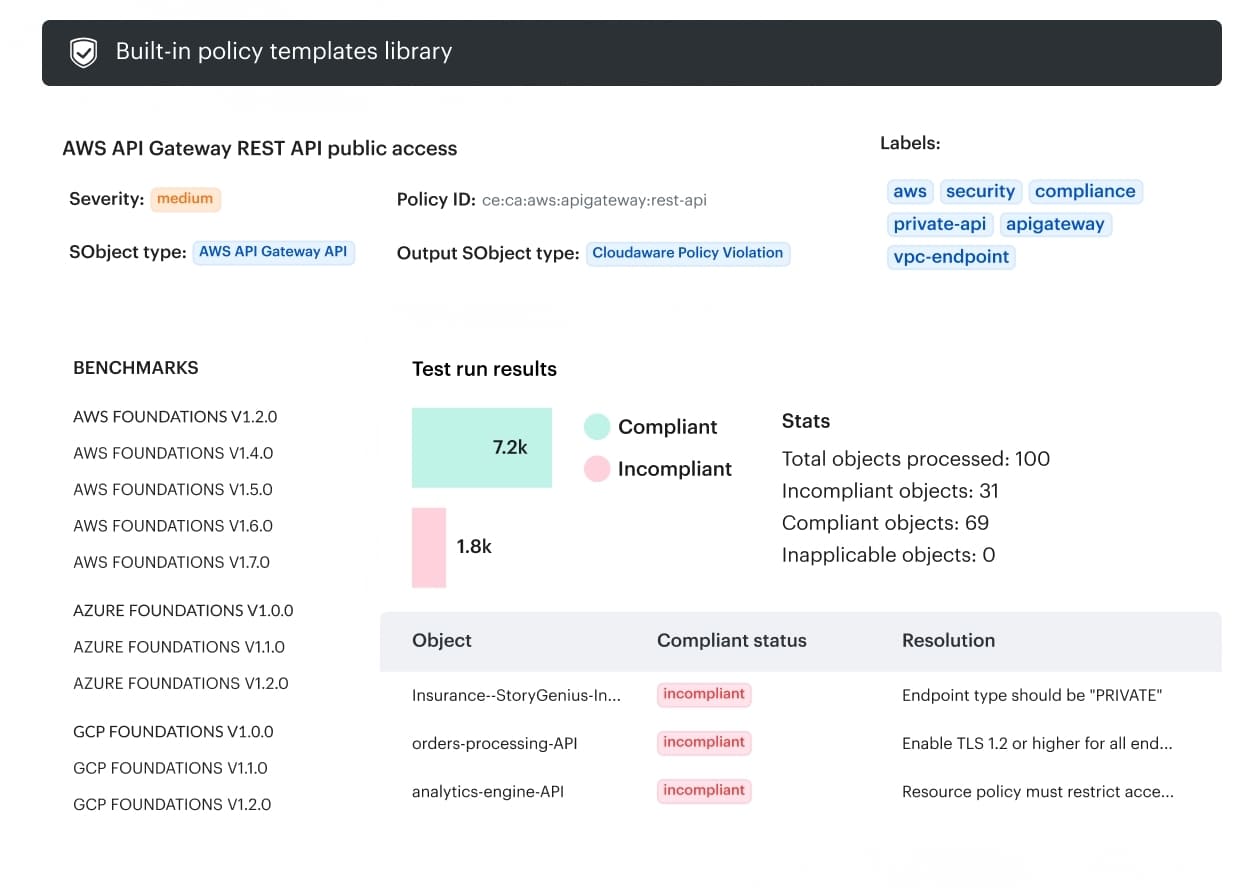
Here, Cloudaware acts as a stabilizer. It gives fast-moving teams visibility into what is actually happening in the cloud without slowing delivery. Runtime issues are surfaced with ownership and context, not as generic alerts that derail roadmaps.
Why most organizations converge on a hybrid model
In practice, most organizations do not live entirely in either world. Different parts of the same company often require different trade-offs.
What usually emerges is a hybrid approach:
- Non-negotiable security constraints defined early
- DevSecOps automation for day-to-day delivery
- Continuous runtime visibility to catch drift
- Clear ownership across engineering and security
From a CISO perspective, the goal is not to enforce a single model everywhere, but to ensure that risk is visible, ownership is clear, and controls remain effective as the organization grows. Platforms like Cloudaware support this by providing a shared, continuously updated view of security across design, delivery, and runtime — without forcing teams into a one-size-fits-all framework.
The organizations that mature fastest are usually the ones that stop arguing about labels and start aligning models to risk, scale, and reality.