






Imagine this — you’re the IT Manager juggling AWS, Azure, and on-prem servers like a high-stakes circus act. Security wants asset visibility. DevOps needs dependency mapping. Finance is hounding you for cost allocation. And compliance? They’re one audit away from a full-blown meltdown.
Your cloud infrastructure spans thousands of accounts, services, and regions. CI names are inconsistent. Teams deploy resources faster than you can track them. Shadow IT? Oh, it’s thriving. Meanwhile, you’re expected to maintain a clean, accurate CMDB — except where do you even start?
Here’s the deal: CMDB Discovery is your best bet for untangling this mess. It automatically finds, normalizes, and updates configuration items (CIs) across all your environments. No more guessing. No more outdated spreadsheets. Just real-time visibility into your IT assets and their relationships.
In this guide, I’ll break down how CMDB Discovery works and share the top 10 best practices I’ve learned working with Cloudaware clients — so you can implement it the right way, from the start.
Let’s start with a theory 👇
What is CMDB discovery?
CMDB discovery is the process of automatically identifying, adding context about related items, and updating all the CIs in your IT environment — cloud, on-prem, SaaS, you name it.
Instead of manually tracking infrastructure across multiple clouds, accounts, and teams (aka a one-way ticket to burnout), discovery does the heavy lifting for you. It scans, detects, and keeps your CMDB accurate in real time — without throttling or slowing down your infrastructure.
How does CMDB discovery work?
Let’s say you’re managing a hybrid infrastructure spread across AWS, Azure, and on-prem servers. You’ve got:
- Cloud Architects spinning up new instances
- DevOps deploying CMDB-based application discovery
- Security enforcing policies on critical assets
- Compliance chasing after missing asset data
- Finance trying to track cloud service costs
And let’s be real — half of these assets exist in someone’s head, a Jira ticket, or a forgotten Excel sheet.
Enter CMDB Discovery Tools. These tools automatically scan your environments in real time using native APIs, pulling information on instances, networks, dependencies, and software versions — without interfering with performance.
Found an orphaned EC2 instance? It’s logged.
A Kubernetes cluster misconfigured across multiple regions? Flagged.
A rogue SaaS app draining budget? Caught.
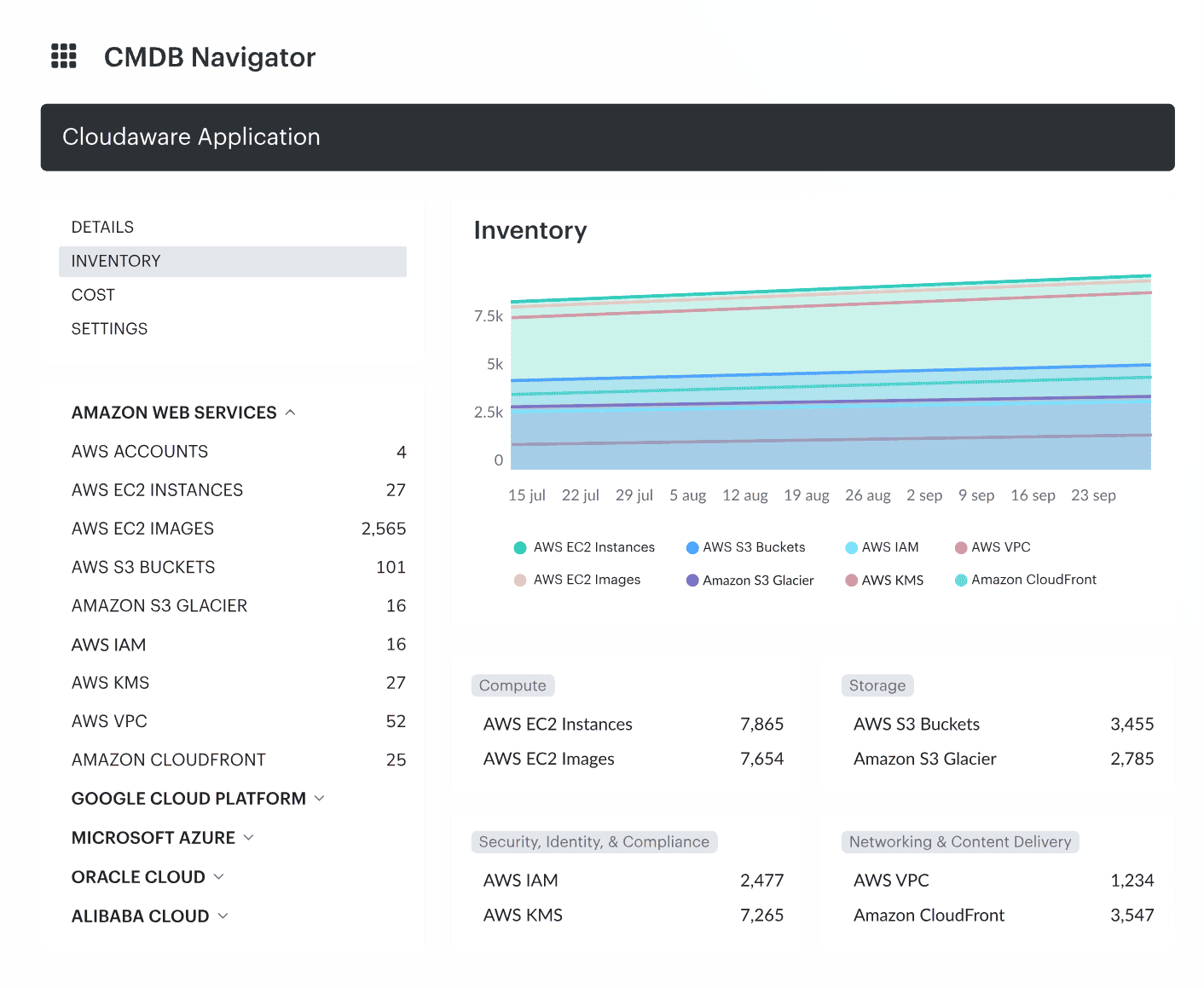
Even better — discovery doesn’t just collect data. It correlates and normalizes it. That means when a server gets decommissioned, business service dependencies update. When a new asset appears, it gets categorized. No outdated records, no blind spots — just real-time, accurate visibility without slowing down your operations.
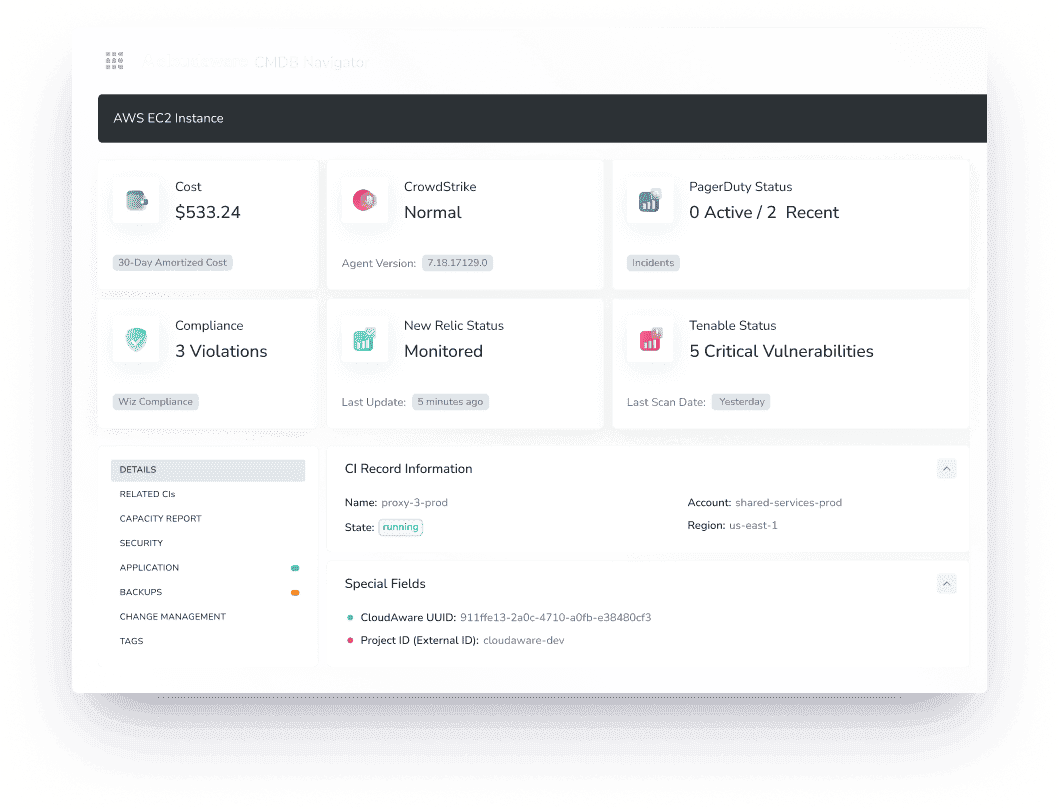
But here’s the thing — not all CMDB discovery tactics are created equal. The way you approach discovery can determine whether your CMDB stays clean and reliable or turns into an unmanageable mess.
So, let’s break it down. In the next section, I’ll walk you through the different types of CMDB discovery tactics, when to use them, and how to get the most out of each one. Let’s go.
4 CMDB discovery techniques
“The biggest mistake teams make with CMDB? Treating discovery like a checkbox. If you don’t choose the right technique for the job, you either miss critical assets or overload your CMDB with noise. And both wreck your visibility.” — Kristina S., Senior Technical Account Manager at Cloudaware
Each CMDB discovery technique has its own purpose, strengths, and best-use scenarios. Some work best for cloud environments, others are a must-have for on-prem data centers, and the best setups use a combination of them all.
1. API-based discovery
This is your always-on, cloud-native powerhouse. You connect your CMDB to cloud-native APIs — like AWS Config, Azure Resource Graph, GCP Asset Inventory, or VMware vCenter. That’s when auto discovery CMDB kicks in.
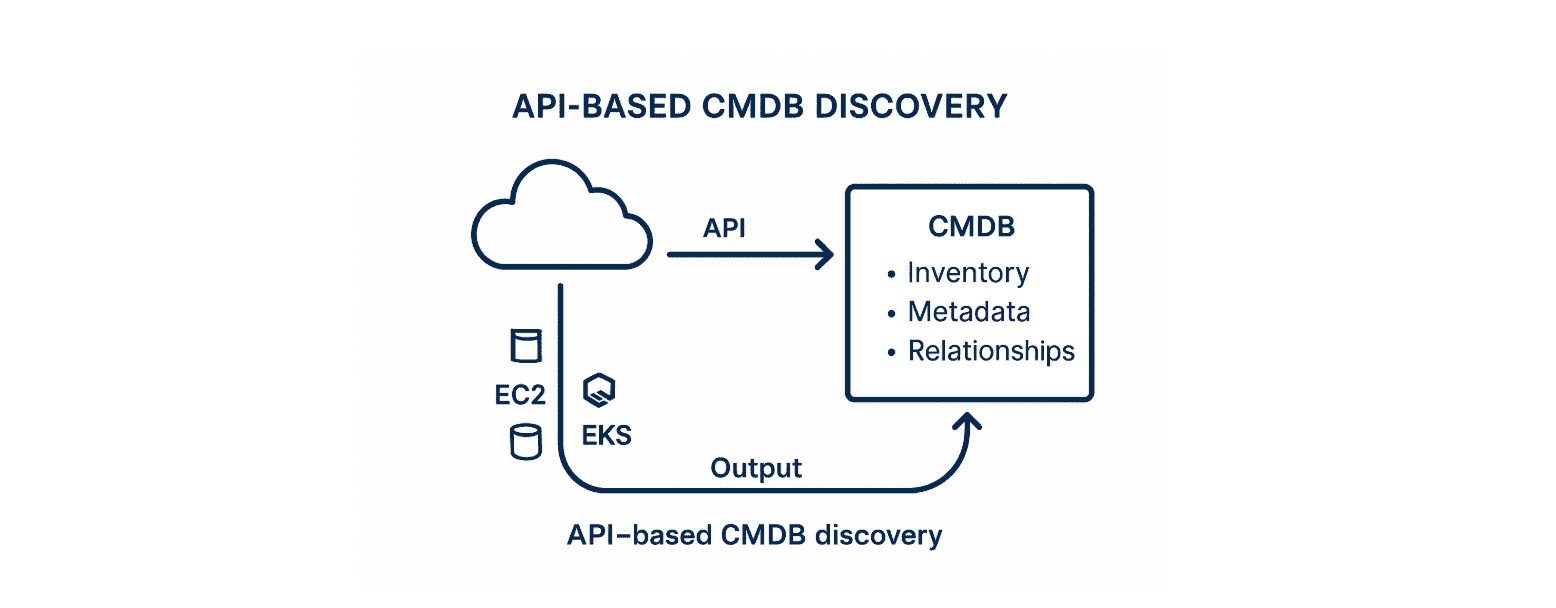
It pulls structured data straight from the source of truth. You don’t just get resource IDs — you get encryption status, region, runtime state, cost_center, and timestamps. It tracks change deltas continuously. That makes it ideal for reconciling Infrastructure-as-Code, monitoring policy drift, and feeding lifecycle status into ITAM automation.
Where it saves you:
You’re managing 200+ AWS accounts and a fleet of GCP projects. Some teams deploy through Jenkins, others use GitHub Actions.
Cost centers? Inconsistent.
Ownership? Often missing.
Cloudaware pulls in every EC2, EKS, S3, and Pub/Sub — enriched with service owner and business metadata. It drops straight into your CMDB, mapped against CIS Control 1 requirements. No gaps, no guessing.
Read also: What is service mapping: How It Works. Best Practices for IT Teams
2. Agent-based discovery
Old school? Yep. Still essential? Every day. This one drops a lightweight agent on your systems — from VMware to edge Linux nodes — and surfaces what APIs miss.

We’re talking OS patches, installed software, logged-in users, file systems, firewall configs, and BIOS serials. Data that matters when you’re managing legacy or unscanned systems.
Where it saves you:
You’ve got a cluster of Windows 2012 boxes in prod that nobody wants to own. But they run critical finance workflows. With agents deployed, you capture asset-level information on patch status, logged-in users, last restart, and missing updates. It’s all fed into your CMDB.
That becomes your evidence trail for CIS Controls 2 and 6 — and your shield when someone yells about EOL exposure.
Read also: Top 7 CMDB best practices for 2026
3. Credential-based discovery
No agents, no install scripts, no footprint. This method authenticates over SSH, WinRM, or APIs to run configuration checks directly on the node.
You still get granular visibility — just without touching the host. It’s ideal for environments where agents are banned, but compliance data is non-negotiable.
Where it saves you:
You’ve got a PCI-zoned Red Hat cluster inside a VPC with tight access controls. SecOps needs proof of FIPS mode, MFA enforcement, and audit logging — but you can’t deploy agents. You configure bastion-host access.
Cloudaware runs the policy checks and returns actionable data. Everything flows into the CMDB, with risk scores, ownership links, and service context attached.
4. Passive discovery
This one listens quietly. No access needed. It reads flow logs, DNS traffic, NetFlow, and even firewall events to infer what’s running, where, and how it’s talking to the rest of your environment.
You won’t get file system details. But you will find shadow infra, rogue deployments, and unsanctioned network paths no one confessed to creating.
Where it saves you:
You’re preparing for a zero-trust rollout across prod and staging. You enable VPC flow logs in AWS and Azure. Cloudaware cross-references those logs with your declared CMDB entries.
Suddenly, there’s a dev instance talking to a production SQL node — with no tags, no owner, no record. That discovery triggers an alert, generates a ticket, and gives you a shot at fixing the problem before it hits incident status.
Each CMDB discovery technique unlocks a different view of your reality. When you combine all four in Cloudaware’s auto discovery CMDB, you get a continuous, policy-aware system. It feeds asset data, config information, and service context straight into your ITAM workflows.
Now you’re not just tracking what’s out there. You’re running a management layer that actually reflects how your business runs — and where it’s exposed.
Which CMDB discovery tactic should you use?
Short answer? A combination of them all. A strong CMDB discovery tool like Cloudaware brings all these techniques together into one auto-discovery CMDB solution — giving you full visibility across your entire infrastructure without overloading your network or slowing down your systems.
With the right CMDB discovery approach, you get real-time, accurate information, streamlined IT management, and complete control over your IT environment.
And the best part? Cloudaware does all of this automatically — so your team can focus on actual IT strategy instead of constantly updating the CMDB.
Next, let’s talk best practices — because discovery is only as good as the strategy behind it.
10 best practices to optimize your CMDB discovery
You can run discovery on every region, every subnet, every service — and still not know what’s really running. That’s why the Cloudaware team doesn’t just talk about coverage. We talk about accuracy, strategy, and how to keep your CMDB from turning into an expensive bucket of incomplete records.
These ten practices? Direct from our field team. They’ve sat through audits, untangled IaC drift, and turned asset chaos into clean, governed reality. Each one includes what they learned, what they’d never do again, and how they help our clients get discovery right — without needing a PhD in inventory pain.
1. Tag Discovery Jobs by Purpose, Not Just Platform
Mikhail Malamud, Cloudaware GM:
“Instead of running one massive discovery job that scoops up everything, split your discovery flows by purpose. Seriously — treat each one like a product.
- Have a job specifically for drift detection.
- Another just for regulatory assets in PCI or HIPAA scope.
- A third for cost center tagging validation.
- Then tie each flow to its own enrichment and reporting logic.
That way, when SecOps asks, ‘What’s not encrypted?’ they don’t get a dump of 800k CIs — they get a filtered list of S3, SQL, and GCS buckets.
One client had this exact problem. After splitting discovery by intent, they shaved their CMDB size by half and finally got clean, goal-specific reports into the right hands.”
2. Protect Your Bastions Like They’re Root DNS
Kristina S., Senior Technical Account Manager at Cloudaware:
“If you’re using credential-based discovery, don’t treat your bastions like just another jump box. Lock them down like your CMDB discovery tool accuracy depends on it — because it does.
One client had a failed scan across their PCI subnet, and instead of guessing, they pulled the bastion session logs, traced the SSH handshake, and found the problem in five minutes. No war room.
Here’s how we lock ours down on every engagement:
- Use ephemeral SSH certs from Vault or Teleport with short TTLs (1–2 hours max)
- Enforce MFA and SSO for every session, even automation
- Pipe full session logs to your SIEM and flag anything unexpected
- Record shell commands if supported — not just connection logs
- Whitelist only the CIDRs and accounts needed for discovery
- Tag your bastions as Tier 0 CIs in the CMDB, with service ownership and audit policy
Bastion hygiene isn’t just about hardening. It’s observability for your CMDB discovery infrastructure. If that path’s dirty, everything downstream — including asset data — is suspect.”
Read also: What is ITSM configuration management: Expert Guide for IT Heroes
3. Pre-Clean Everything Before It Hits the CMDB
Iurii Khokhriakov, Technical Account Manager:
“Cloud APIs don’t care about your schema — they’ll hand you raw JSON straight from the firehose, and it’s up to you to decide what’s garbage and what’s gold.
That’s why we never let raw discovery data go straight into the CMDB service. It goes through a preprocessing layer first.
For one finance client, we found 14 different variations of the same app name (app_billing, AppBilling, Billing App, etc.) because Azure returned inconsistent tag keys across regions.
The auto discovery CMDB turned into spaghetti.
Now they run all discovery payloads through a Cloud Function that:
- Normalizes tag casing and keys (like
Owner,owner,OWNR) to a canonical format - Strips empty or deprecated fields from legacy asset types
- Enriches missing metadata using Git commit info, repo links, or the last IAM principal who modified it
- Maps regions, service names, and environments to internal enums (
us-west-2→region:west,prod→env:production) - Adds a
**discovered_by**field so we know which method (API, agent, passive) sourced the record
This isn't a cleanup step — it's a gatekeeper. If business doesn't clean before ingestion, they spend months rewriting reports, dashboards, and alerts to account for inconsistent structure.
Your CMDB software information should be clean at the source, not after the fact.”
4. Only Reconcile What Changes
Anna, ITAM expert at Cloudaware:
“Don’t keep rescanning everything daily. It’s a waste of compute, API quota, and human attention. Set up hash-based diffs — we use SHA256 to hash config blocks and only reconcile if something’s changed. You’ll stop flooding your team with redundant tickets.
We rolled this out for a customer with a noisy IaC pipeline and it cut their CMDB update queue from 10,000 down to 600 per day.
Now every delta matters — and they actually review each one.”
5. Track Discovery Like an SLO
Daria, ITAM expert:
“Your CMDB based application discovery jobs need observability. Period. We treat them like uptime. One of our clients built a Grafana board that tracks:
- % of subnets under coverage
- age of last discovery run per region
- credential failure rates
- CMDB ingestion lag
They use it in monthly reliability reviews. If discovery health drops below 95% in regulated zones, it auto-escalates to their incident board.
That’s how you make asset tracking as real as uptime.”
6. Make Discovery Part of CI/CD
Anna, ITAM expert at Cloudaware:
“If discovery’s not wired into your deployment pipeline, you’re losing visibility before assets even hit production. Every terraform apply, helm upgrade, or GitHub Actions deploy should trigger a scoped discovery job automatically. Include metadata like commit SHA, repo name, service ID, and deployer email.
Push it into your CMDB as part of the enrichment step.
We recommend using post-deploy webhooks or event-based triggers from your CI/CD tool. That way, every asset spun up gets tied to the code and human that deployed it.
When SecOps asks who launched an unencrypted disk or an open S3 bucket, you’re not guessing. You’ve got the full audit trail in one place — and discovery becomes part of your governance process, not an afterthought.”
Read also: ITIL CMDB Superpowers: 7 Processes That Just Got Smarter
7. Organize Discovery by Service, Not Cloud
And this is insight from my personal experience:
“Stop thinking in accounts. Think in services. I had assisted one client who switched their CMDB model from region/account to service ownership. Now, when they look up payments-api, they see its EC2s, load balancers, Lambda triggers, DNS entries — across clouds. All tied together by a service slug that comes from Git repos and deployment manifests.
That’s how they run blast radius reports and cost management breakdowns without chasing tags.”
8. Watch the Network for What You Miss
Iurii Khokhriakov, Technical Account Manager:
_“_API CMDB discovery tools only show what’s declared — what someone provisioned ‘correctly.’ But real environments are noisy. Stuff gets spun up outside of Terraform, cloned, mis-tagged, or just... forgotten. That’s where passive discovery comes in. You watch the network instead of the console.
Here’s what we do:
- Enable VPC Flow Logs (or NetFlow if you’re on-prem) for all prod and staging subnets
- Stream those logs to BigQuery or Amazon Athena
- Correlate IPs and hostnames with your CMDB inventory
If something’s talking to known assets but doesn’t exist in the CMDB, flag it. One client found 47 unknown hosts this way — some were ghost Jenkins agents, one was a contractor’s personal sandbox left connected to a prod DB.
Now they treat passive discovery as a control surface. If it talks and it’s not declared, it’s a ticket, a tag, or a teardown. No exceptions.”
9. Validate in Staging First
Anna, ITAM expert at Cloudaware:
“New discovery methods — especially credential or agent-based ones — can blow things up if you’re not careful.
One client ran a misconfigured agent job that spiked outbound bandwidth and triggered a traffic alert on their Kafka brokers. In prod. Now they require all discovery configs to pass sandbox validation: API limits, credential scopes, tagging logic, and runtime load. It’s part of their release checklist for infra changes.”
10. Align Cadence to Business Events
Kristina S., Senior Technical Account Manager at Cloudaware:
“Discovery shouldn’t just run on a cron job. It should run in rhythm with your organization. Environments don’t grow linearly — they spike around re-orgs, big releases, contract renewals, and vendor onboarding. That’s when your CMDB gets out of sync.
With one fintech client, we helped them map discovery schedules to their internal calendar. Now they:
- Run deep discovery jobs (including credential scans and passive log correlation) after quarterly infra changes and vendor renewals
- Schedule weekly API-based discovery for standard asset visibility
- Pause non-essential jobs during change freezes and Black Friday-style events
They also track what changes between runs and review delta reports in sprint planning. It keeps SecOps looped in without flooding them.
Don’t run discovery just because it’s Thursday. Run it when ownership shifts, new apps ship, or platform debt builds. Discovery should follow the flow of your business, not a static calendar.”
Read also: 9 Configuration Management Best Practices for Multi-Cloud Setups
Top 5 CMDB discovery tools for your 2025
I’ve tested the top tools, dug through Capterra reviews, and talked to real users to cut through the noise. Here’s the breakdown of the best five, no fluff — just what actually works.
The top CMDB discovery tools in 2025:
- Cloudaware,
- Axonius,
- ServiceNow Discovery,
- Device42,
- and Asset Panda.
Let's dive into the details 👇
Cloudaware
If managing IT assets across multiple clouds and on-prem feels like wrangling a runaway circus, Cloudaware CMDB discovery tool built to bring order to the chaos. Designed for enterprises with sprawling IT environments — think thousands of servers, accounts, and applications — it delivers real-time CMDB discovery to give you an accurate, up-to-date view of your entire infrastructure.
But here’s the real magic — Cloudaware doesn’t just collect data; it enriches every CI with third-party insights.
Need to track related items, vulnerabilities, or CPU usage? Done.
It even maps relationships between assets, making it easy to see how your entire ecosystem connects. Built on a secure, scalable Salesforce foundation, it ensures business continuity with minimal risk.
Key features of the Cloudaware auto discovery CMDB:
- Continuous asset discovery for hybrid environments (multi-cloud + on-prem)
- Automated workflows to streamline tagging, compliance, and IT service management
- 50+ integrations with tools like AWS, Azure, Jira, and Slack
- Real-time dashboards and custom reporting tailored to your needs
- Enterprise-grade security, including encryption and role-based access control
Pricing starts at $400/month for 100 servers, with tiered pricing and discounts for larger environments. Plus, there’s a 30-day free trial to test it out.
Axonius
Axonius is like your IT asset detective, constantly scanning for every device, software, and service across your hybrid environment. If you’re managing thousands of accounts, servers, and endpoints, this tool helps eliminate blind spots and automates IT asset discovery so you always have the full picture.
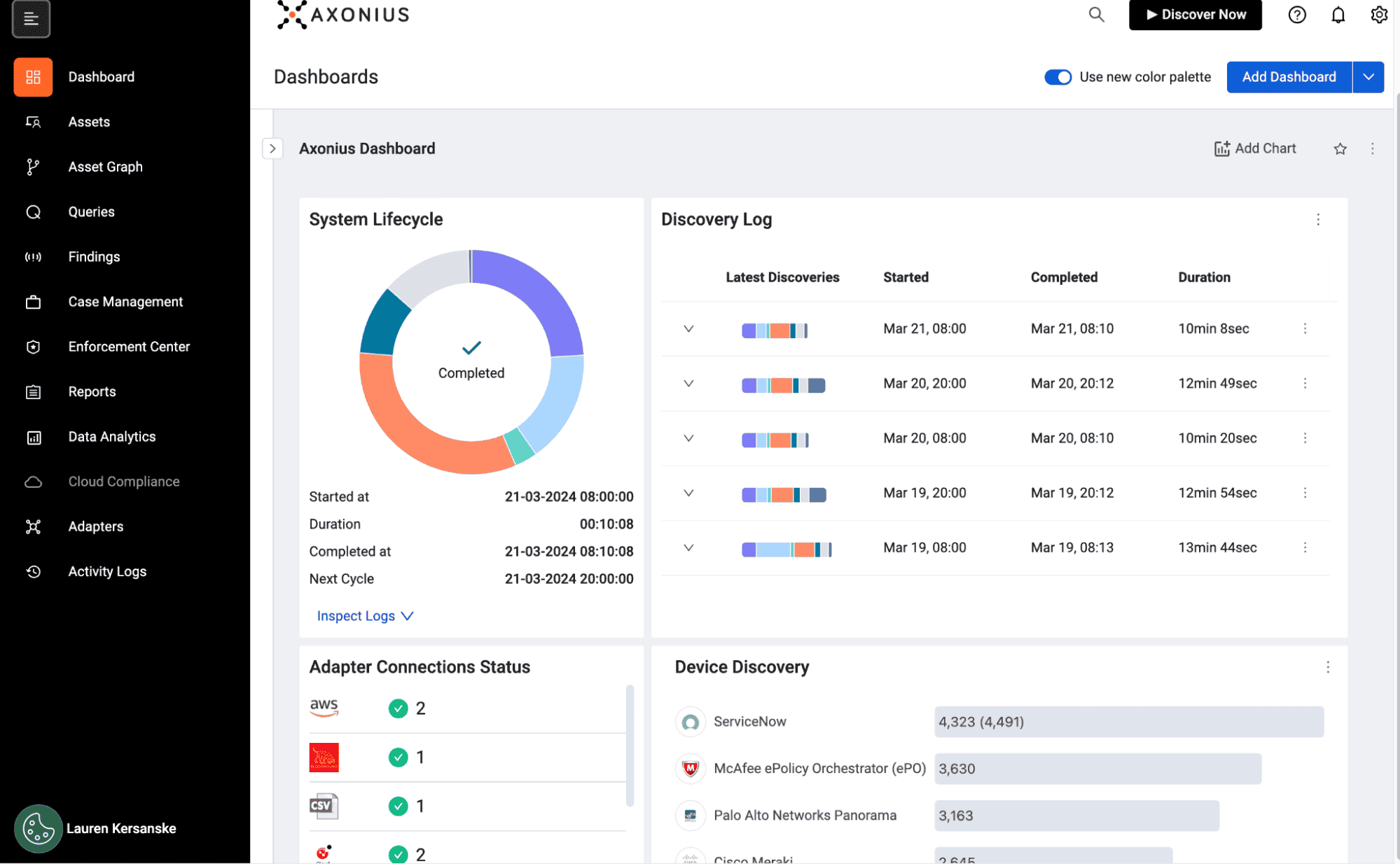
It integrates with 500+ security and IT tools, centralizing CMDB data from cloud, SaaS, and on-prem environments. Whether you’re hunting down unmanaged devices, tracking dependencies, or ensuring compliance, CMDB based application discovery helps you stay ahead.
Why IT leaders love Axonius:
- Agentless asset discovery across multi-cloud and on-prem environments
- 500+ integrations (AWS, Azure, Okta, ServiceNow, CrowdStrike, and more)
- Automated security enforcement — fix compliance gaps instantly
- Customizable reports with real-time information on assets and risk
- Fast deployment — plug it in, get insights immediately
Pricing scales based on asset count, with flexible tiers. There’s also a free trial, so you can test it out before committing.
ServiceNow
When you’re running a hybrid IT infrastructure, keeping track of configuration items across multiple clouds and on-prem systems can feel like managing a digital wild west. ServiceNow CMDB brings structure to the chaos, acting as a centralized source of truth for all your assets, dependencies, and IT services.
What makes ServiceNow auto discovery CMDB stand out?
- Data aggregation via Service Graph Connectors — standardizing CMDB discovery
- Dependency mapping to visualize how assets impact business services
- Automated IT workflows for ticketing, change management, and compliance
- Custom dashboards with real-time configuration and business insights
While powerful, ServiceNow CMDB requires a structured implementation process and may not provide real-time updates as some competitors do. Pricing is customized based on your organization’s needs, so reaching out to their team is the best way to get an exact quote.
Read also: Key Differences CMDB Vs Asset Management (ITAM): Why You Need Both
Device42
Taming hybrid infrastructure means dealing with constant change. Device42 auto discovery CMDB makes configuration management easy by automatically discovering, tracking, and mapping dependencies across your on-prem, cloud, and virtual resources. If you need granular visibility into your environment, this is one to consider.
Why enterprises choose Device42:
- Agentless discovery — no need to install software on every device
- Application dependency mapping to track relationships between CIs
- 30+ integrations with ServiceNow, Jira, Datadog, and other IT tools
- Customizable reports & visualizations, from rack diagrams to impact analysis
- Built-in compliance tracking with audit-ready logs
Pricing starts at $1,499/year for up to 100 nodes, with a 30-day free trial so you can test its capabilities firsthand.
Asset Panda
If tracking IT assets feels like managing a fleet of rogue drones, Asset Panda steps in as a user-friendly asset management solution. While not a full CMDB discovery tool, it does offer valuable tracking features, especially when paired with discovery integrations.
Key features:
- Comprehensive asset tracking — hardware, software, lifecycle details
- Integration with Lansweeper for automated discovery
- Custom workflows to match your business processes
- Mobile accessibility, including barcode scanning for quick updates
While Asset Panda excels at asset tracking, it lacks advanced CI relationship mapping and real-time dependency analysis found in specialized CMDB tools. Pricing is flexible based on company size.
Read also: 13 CMDB tools - Choose the best configuration management database
How to choose the right CMDB discovery tools
Not all IT asset discovery tools are built the same. Some are glorified spreadsheets. Others are slow, clunky, or require a degree in wizardry to set up. And the worst ones? They drag your system performance down while scanning. Hard pass.
So, what should you look for? Let’s break it down.
- Agentless Discovery. If your discovery software requires installing agents on every machine, you’re signing up for a management headache. Agentless discovery gathers data without impacting system performance, making it an absolute must for business-scale IT management.
Look for a CMDB discovery tool that works across cloud, on-prem, and virtual environments without slowing things down. - Real-Time Updates. What’s the point of IT asset discovery if it’s showing last week’s inventory? Your tool needs continuous, real-time discovery to keep your CMDB up to date. Outdated information leads to bad decisions, security gaps, and troubleshooting nightmares.
- Dependency Mapping. Your infrastructure isn’t just a list of assets — it’s an interconnected web of services, applications, and dependencies. A proper CMDB software should include dependency mapping so you can see how everything interacts. When something breaks (because it will), you’ll instantly know what’s affected.
- Integrations with Your Existing Tools. You already use IT management software — AWS, Azure, ServiceNow, Jira, security platforms, the list goes on. A solid CMDB discovery tool should integrate with your existing business services, pulling in data from every corner of your infrastructure.
- Automation (Because No One Has Time for Manual Work). Tagging assets manually? Checking compliance by hand? Running reports like it’s 1999? Nope. A good discovery and management tool should automate workflows — from tagging resources to flagging misconfigurations and triggering incident responses.
- Security & Compliance (Because, Well… You Know Why). Your CMDB holds everything about your IT assets, which means enterprise-grade security is non-negotiable. Look for software that includes encryption, role-based access control, and detailed audit logs.
Picking the right IT asset discovery tool isn’t just about “getting a CMDB.” It’s about taking control of your IT infrastructure before it takes control of you. Get a CMDB discovery tool that’s agentless, real-time, automated, and scalable — not just another thing to babysit.