






You ever open a cloud dashboard and feel that sinking oh no when you realize half the assets running weren’t even there last week? And don’t get me started on on-prem. Servers humming away in forgotten racks. Shadow IT spinning up rogue instances. And someone, somewhere, still swearing that spreadsheet-based tracking totally works.
We’ve been there. My team and I have spent years wrangling IT inventory management across sprawling, multi-cloud, and on-prem environments. Thousands of assets. Scattered dependencies. Constant change. And if there’s one thing we’ve learned? Inventory management isn’t just about tracking what you have. It’s about knowing where, why, and how everything connects. So when something breaks, scales, or needs a security patch, you’re not left scrambling.
This guide isn’t theory. It’s hard-won experience from the trenches. Let’s break down what actually works. What doesn’t. And how to build an IT inventory management system that gives you control instead of chaos.
What is an IT asset inventory?
An IT asset inventory is a living record of everything your organization runs, owns, or pays for in IT. Not just devices. Not just software. Everything that exists in your environment right now and keeps changing while you read this sentence.
In modern setups, that scope is wider than most teams expect. A real IT asset inventory includes:
- cloud resources like virtual machines,
- managed databases,
- load balancers,
- storage accounts,
- containers that live for minutes, not years,
- SaaS licenses tied to users and teams, not just contracts.
- Endpoints are still there.
- Network components too.
- Gateways, firewalls, subnets, routing rules.
All of it counts.
Where I see teams struggle is treating inventory as a list. Lists work for devices. They fall apart in cloud-native environments. Assets appear and disappear. Ownership shifts. Costs move with usage. A VM created for a test can quietly run for months. A SaaS tool can be adopted by one team and paid for by another. If your inventory doesn’t update continuously, it drifts out of reality fast.
For IT asset management, the inventory is about confidence. Could you please clarify what is running when security inquires? Can you trace ownership when finance questions are spent? Are you able to demonstrate control during an audit without any last-minute rush?
That’s why today, an IT asset inventory has to be cloud-aware by default. If it only tracks devices and installed software, it’s already incomplete. And an incomplete inventory isn’t a neutral state. It actively increases risk.
Read also: 📌 Decoding configuration management vs change management in a multi-cloud environment
IT inventory management vs simple asset lists
A simple asset list is a snapshot. It tells you what was true when someone exported it. That’s useful for a point-in-time audit. It’s also how teams end up arguing in meetings because the environment changed and the list didn’t.
IT inventory management is different. It’s lifecycle plus updates plus accountability. The inventory is expected to change, so the process is built to keep up. Assets get added, modified, reassigned, retired. Someone owns the record. Someone can answer for the cost and the risk.
One example. A VM gets created for a short-lived test. In a list, it’s just “vm-1234.” In managed inventory, it has an owner, a purpose tag, a creation date, a planned end date, and a status that can move from active to scheduled for retirement. If it’s still running after the deadline, that’s not a mystery. That’s a failure you can catch.
Here are the maturity levels.
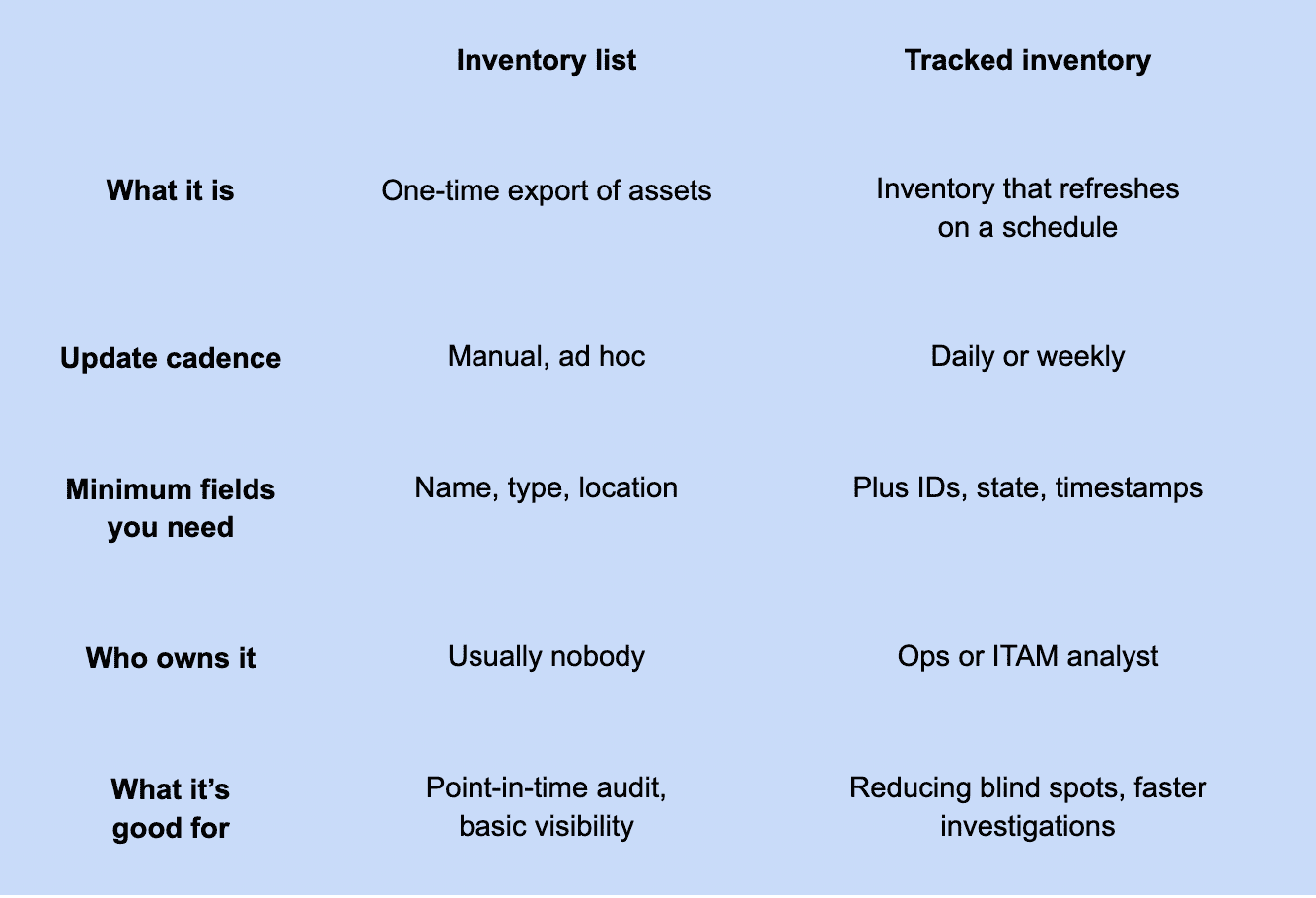
If you want a quick test: ask “who owns this asset and when should it be gone?” If the best answer is silence or a Slack thread, you’re looking at a list. If you can provide an answer within seconds, it indicates that you have effective inventory management.
Read also: 📌 Master Cloud Configuration Management: Tools & Tips
IT software inventory: What you need to track and why it’s hard
If hardware inventory involves simply counting items, then IT software inventory requires counting items that constantly change form.
Software no longer falls into a single category. It’s installed, subscribed, and spun up as a managed service. It’s a browser tab somebody swears is “just for this one project.” And the second you try to pin it down, it moves.
Here’s what you actually need to track if you want your inventory to hold up under finance questions, security reviews, or a license true-up.
- Installed software
Classic stuff. Agents, packages, versions, patch levels, where it’s installed, and on what device or server.
The catch: in enterprise environments, “installed” doesn’t mean “used.” You’ll find versions that haven’t been launched in months, and you’ll find critical apps running on that one forgotten jump box nobody owns.
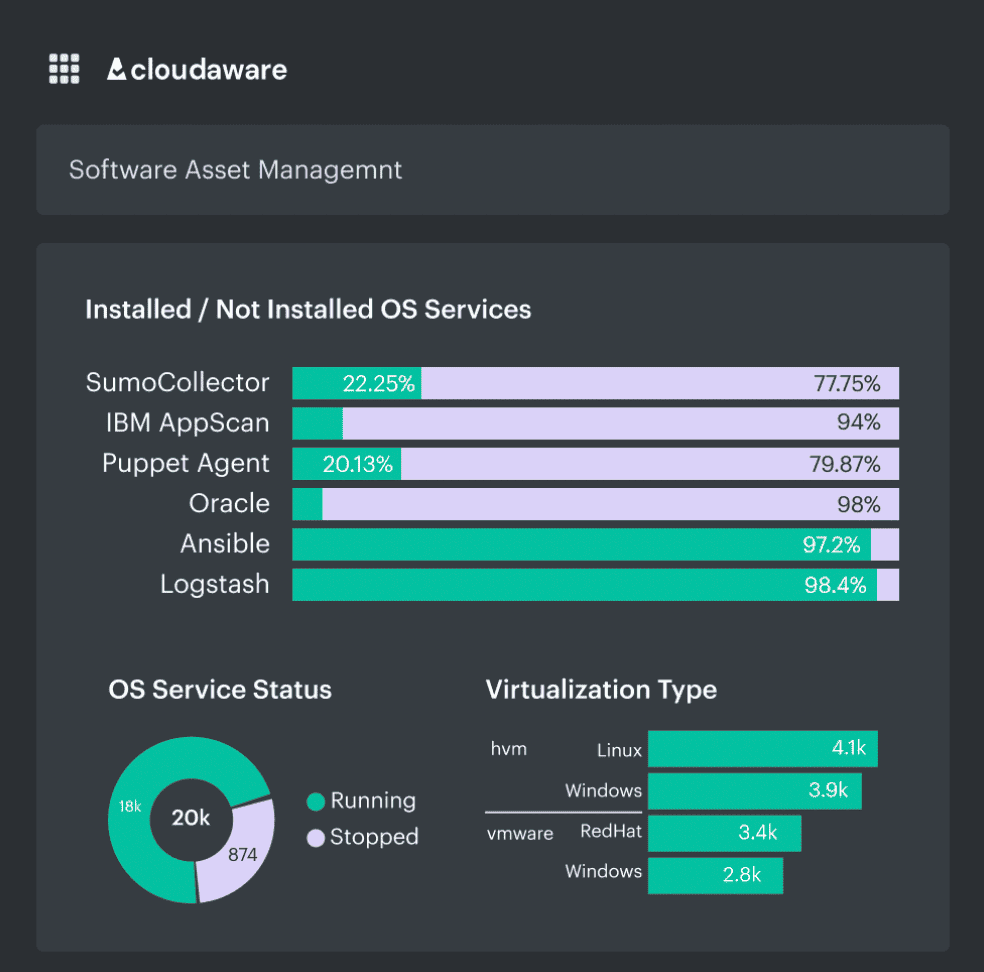
For example, one of the dashboards of how it looks like in Cloudaware:
- SaaS subscriptions
This is where inventories go to die.
SaaS isn’t deployed. It’s subscribed. That changes everything. Your source of truth isn’t an endpoint scanner. It’s identity, billing, SSO logs, and admin consoles.
Track:
- which SaaS tools exist
- who has seats
- who is active
- which department pays
- what plan you’re on
- renewal dates and contract owners
If you only track “we have Salesforce,” you’ve missed the real story. The real story is 600 seats purchased, 340 active users, and 70 accounts that should’ve been deprovisioned when people left.
Read also: 📌 7 Strategies for CMDB Application Mapping Success in Hybrid IT Infrastructure
- Cloud-native services
Software isn’t just what runs on servers anymore. It’s the managed services you turn on in AWS/Azure/GCP and forget are software at all.
Think managed databases, message queues, Kubernetes add-ons, API gateways, secret managers, monitoring stacks. They have configurations, versions, access policies, and cost curves. They also have blast radius.
If your software inventory ignores cloud services, it’s incomplete by design.
- Shadow IT
Shadow IT isn’t always malicious. It’s often a team trying to move fast. A designer signs up for a tool with a card. A PM connects a free integration. Somebody shares credentials. Now you have software in production that procurement never reviewed, security never approved, and ITAM can’t even see.
This is why a good inventory can’t rely on one data source. You need signals from SSO, finance, browser-based app discovery, and vendor admin portals.
- License ownership vs usage
This is the part that gets expensive fast. Ownership answers “who is assigned a license" and usage answers “who actually used the product.”
Those are not the same thing, and vendors price you on ownership. A software IT inventory that doesn’t separate assigned seats from active users will always look healthy right up until renewal season.
Why IT software inventory is hard
- APIs change. Vendors revise endpoints, permissions, and data models. Your integrations need maintenance or your inventory quietly goes stale.
- Tags drift. Names, owners, environments, and cost centers degrade over time. People clone resources, copy bad tags, skip tagging in a hurry. Then reporting lies.
- SaaS is subscription-driven. You don’t “discover” it like a server. You reconcile identity, billing, and usage. That’s a different job with different failure modes.
This is exactly why most competitors barely scratch the surface. They treat software like a list of installed apps. That’s 2012 inventory logic. Modern inventory lives across endpoints, identity, cloud platforms, and finance systems, whether we like it or not.
Read also: 📌 ITIL CMDB Insights: Simplify 7 Processes Across Hybrid Environments
How to build an IT asset inventory that stays accurate
The hard part isn’t creating an inventory. It’s keeping it from turning into a comforting lie.
The first time you’ll feel it is predictable. A security ticket asks which assets were internet-facing last Tuesday. Finance asks why spend jumped. You pull the “inventory” and it’s missing half the cloud resources that were created after the last export. That’s not a tooling problem. That’s a process problem.
Here’s how I build IT inventory tracking that survives real environments.
1) Use automated discovery because every method has blind spots
If you rely on one source, you’ll build an inventory shaped like that source.
What works in practice:
- Cloud APIs for AWS, Azure, and GCP so you get actual state, region, account, tags, and configuration.
- Endpoint management for laptops, servers, and installed software.
- Identity and SaaS admin consoles for subscription reality, such as seats, assignments, and sign-ins.
- Billing exports as your “truth serum” because spending always reveals what teams forgot to tell you.
That's exactly what Cloudaware does when collecting data about CIs from your multi-cloud infrastructure.

Real-life example: billing shows charges for a “small” SaaS tool nobody recognizes. Identity shows 47 users signing in. Procurement has no contract record. That’s shadow IT with a receipt.
2) Set update frequency by asset volatility
Monthly refresh is fine for office chairs. It’s not fine for cloud. Rules I use:
- Assets that autoscale or redeploy often need hourly or event-driven updates
- Core cloud infrastructure can usually refresh daily
- Endpoints can refresh daily or weekly, but every record needs a last-seen timestamp
If an asset has no last-seen time, it’s not inventory. It’s trivia.
Read also: 📌 The best configuration management software: Top 10 tools review
3) Make ownership survivable: assign to teams, not people
Ownership is where inventories become enforceable.
Two patterns that hold up:
- Service ownership: assets roll up to an application or service, then that service has a team owner
- Account ownership: every AWS account, Azure subscription, and GCP project has a named owner and a backup owner
Real-life example: “Owner = Jane” works until Jane leaves. “Owner = Payments Platform team” survives reorgs and on-call rotations.
Read also: 📌 What Is Configuration Management? Definition. Processes. Recommendations
4) Handle ephemeral cloud assets like events with history
Ephemeral assets are supposed to be short-lived. Your inventory still needs to explain them. Track:
- what it was while it existed
- what created it, such as autoscaling group, node pool, pipeline, image ID
- lifecycle status like running, terminated, replaced
- a history window long enough for investigations
Example: an autoscaling group spins 200 nodes during a traffic spike. You don’t need to keep every node forever. You do need to preserve “what existed during the incident” for at least 30–90 days, or you’ll never explain cost spikes and security alerts.
5) Normalize across clouds or your reporting will turn into translation work
AWS, Azure, and GCP all name things differently. Your auditors and leadership don’t care. They want one answer.
Define a common model:
- resource type
- environment
- owner
- lifecycle status
- account or subscription
- region
- cost center
- exposure flags like public IP, open ports, internet-facing
Then map provider fields into that model. Normalization is what lets you ask one question such as “show me all prod compute with public exposure” and get a trustworthy cross-cloud result.
How to choose the best IT asset inventory management software
When you’re researching an IT asset inventory management system, you’re basically doing due diligence on one thing: will this tool give you an inventory you can trust on a random Tuesday, not just the day after onboarding?
Here’s the shortlist I use when I’m comparing tools. It’s feature-led on purpose, because that’s how vendor pages are written. The difference is you’ll know why each feature matters, so you don’t get distracted by shiny extras.
✅ Does it auto-discover assets across cloud, on-prem, endpoints, and SaaS? Can it run continuously or on a schedule? Does it store “last seen”? Manual inventories don’t stay accurate. Cloud resources appear and disappear. Laptops get reimaged. SaaS gets adopted quietly. If discovery isn’t automated, the inventory becomes a screenshot, then a myth.
✅ Can it pull inventory from AWS, Azure, and GCP without separate workflows? Can you run one query/report across all of them? Does it normalize resource types and metadata? Multi-cloud isn’t three inventories. It’s one inventory with three dialects. If you can’t ask “show me all prod compute with public exposure” across clouds in one go, you’re not managing inventory. You’re translating.
✅ Can it track endpoints and servers, plus installed software, plus cloud-native services, plus SaaS subscriptions? Hardware-only inventories miss SaaS and managed services. Software-only inventories miss the endpoints running the software. Real-world ITAM sits in the middle, because a license, a laptop, and an identity account are usually part of the same cost and risk story.
✅ Does it support owner as a team, service, or cost center, not just a person? Can you enforce ownership as required for certain asset classes? Can you report on “unknown owner”? Unowned assets are where waste and risk hide. And personal ownership breaks the minute someone leaves. Tools that treat ownership as optional end up producing beautiful inventories that nobody can act on.
✅ Can you see what changed, when, and by whom (or by what process)? Does it keep configuration history for key fields such as tags, exposure, network settings, instance state, and permissions? The most urgent questions are time-based. What changed before the outage. When the security group opened a port. When that VM got a public IP. A static inventory can’t answer that. Change tracking turns inventory into evidence.
✅ Can you filter fast and export cleanly to CSV/PDF/API? Are reports flexible enough for security, finance, and audit without custom work every time? Inventory that can’t leave the tool doesn’t help the people making decisions. Security teams need evidence. Finance needs allocation views. Audit needs repeatable exports. Ops needs cleanup lists. If reporting is clunky, teams go back to spreadsheets. Then you’re paying twice.
Here are 10 IT asset discovery tools review to start your research. Or there is a proven option below 👇
Use Cloudaware to go beyond IT asset inventory
There’s one thing I’ve learned from our ITAM managers while working with Cloudaware CMDB, it’s this — an IT assets inventory isn’t just about knowing what exists. It’s about structuring that knowledge so you can actually use it. So, let’s talk about how to do it right.
Step 1: Start with automated asset discovery
If you don’t know what exists, you can’t manage it. The first step in any IT inventory management process is setting up automated discovery across clouds and on-prem infrastructure.
With Cloudaware CMDB, this means:
✅ Integrating with your cloud providers. AWS, Azure, GCP, OCI, Alibaba — pulling real-time data from every service, region, and account.
✅ Deploying Breeze Agent for on-prem servers. Giving you visibility into your hardware assets, virtual machines, and network devices.
✅ Scanning Kubernetes clusters. Mapping pods, nodes, services, and dependencies so nothing is hidden.
This isn’t just dumping assets into a list. It’s about tracking metadata, configurations, and relationships so your IT inventory management software is actionable from day one.
Step 2: Structure your inventory
Throwing raw data into a database doesn’t give you clarity — it gives you a mess. That’s why your IT asset inventory management process needs a structured CMDB model.
With Cloudaware, your assets don’t just float in a massive list. They’re organized into CIs with relationships and dependencies, structured like this:
- Business Services → High-level apps that teams rely on.
- Application Groups → Compute, databases, and storage supporting those services.
- CIs → The specific instances, security groups, software, and networking components.
Example:
Business Service: Customer Payments Portal
Application Group: API Gateway
CIs: Load balancers, security groups, ingress rules
Application Group: Backend Services
CIs: Kubernetes clusters, microservices, authentication layers
Now, when an issue happens, you’re not hunting through logs — you can see exactly how your assets are connected.
Step 3: Implement change management
Change is the #1 cause of outages.
Ever had a database go down because someone modified a security group? Or a new deployment break production because a critical dependency wasn’t updated?
With Cloudaware CMDB, every asset change is logged, tracked, and auditable.
✔️ Who changed it? – The exact user or process.
✔️ What changed? – The before-and-after configuration.
✔️ When did it change? – Timestamped for audits and troubleshooting.
✔️ How did it impact dependencies? – Did it break networking, access, or performance?
When a Sev-1 incident happens, you don’t waste hours debugging — you trace the change immediately and roll back if needed.
Step 4: Tag everything & enforce it
Unstructured IT assets inventory = chaos. Without strict tagging policies, your inventory management tools turn into a pile of unstructured data.
With Cloudaware IT asset inventory, we enforce:
✅ Ownership tags – (owner: devops, owner: finance)
✅ Environment tags – (env: production, env: dev, env: staging)
✅ Cost center tags – (cost_center: engineering, cost_center: compliance)
✅ Security compliance tags – (data_classification: confidential)
And here’s the kicker — if an asset doesn’t meet tagging standards, it gets flagged automatically.
No more “Whose database is this?” conversations. Every resource has a clear owner and a purpose.
Step 5: Identify related items
One of our clients once deleted a seemingly unused Kubernetes node. What they didn’t realize? It was running a background service tied to the production login system. Thousands of users locked out.
With Cloudaware CMDB, you can quickly view an asset’s related items — such as connected instances, associated IAM roles, or linked cloud services — helping you assess the bigger picture before making changes.
When an issue arises, you know exactly what’s connected — so you don’t accidentally pull the plug on something critical.
Step 6: Automate alerts & security policies
A good IT inventory management software isn’t just a reference — it acts when something goes wrong.
With Cloudaware CMDB, you set automated alerts for:
🚨 Misconfigurations – Public S3 buckets, unencrypted databases, open ports.
🚨 Security threats – IAM role drift, unused but active credentials.
🚨 Policy violations – Dev workloads in production, compliance misalignment.
Example: A security policy requires all external-facing EC2 instances to have encryption enabled. If an engineer spins up a new instance without encryption, Cloudaware flags it immediately — and can even trigger an auto-remediation workflow.
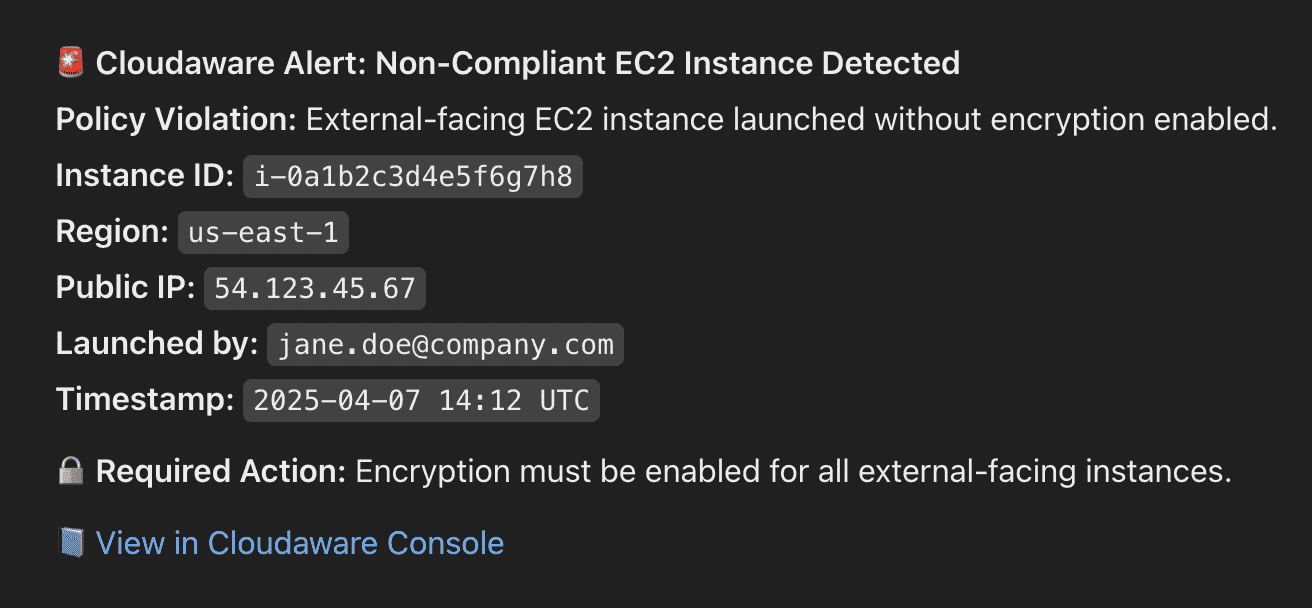
This means security issues get fixed before they become incidents.
Step 7: Scheduled Analytics & ITAM Manager Assistance
Once your IT assets inventory management is in place, it’s not set and forget. You need continuous monitoring and reporting to keep things clean.
With Cloudaware CMDB, you can:
- Schedule automated analytics reports – Get weekly insights on asset growth, cost trends, and compliance status.
- Track asset lifecycle – Know which servers, instances, and licenses need renewal or decommissioning.
- Leverage ITAM managers for strategic insights – Use asset intelligence to optimize cloud costs, enforce policies, and improve efficiency.