






Cloud security threats in 2026 rarely start with a movie-villain exploit.
They start with access that should have expired. A storage bucket nobody owns. An API token sitting in a CI job. A restored database was copied into the test, but with weaker controls. A CVE that was patched upstream two years ago but still lives inside your container base image.
That is the part vendor decks tend to smooth over. The real CISO question is not “what scary new attack might hit us next?” It is messier and more useful: which known weakness is already reachable, tied to production data, and missing a clear owner?
This guide is based on Cloudaware team experience, including insights from DevOps experts Valentin Kel and Igor K., plus what we see across enterprise security teams running multicloud and hybrid environments. We collected the threats that show up most often, the ones teams can realistically plan for, and the defenses that still work when ownership, evidence, and remediation get messy.
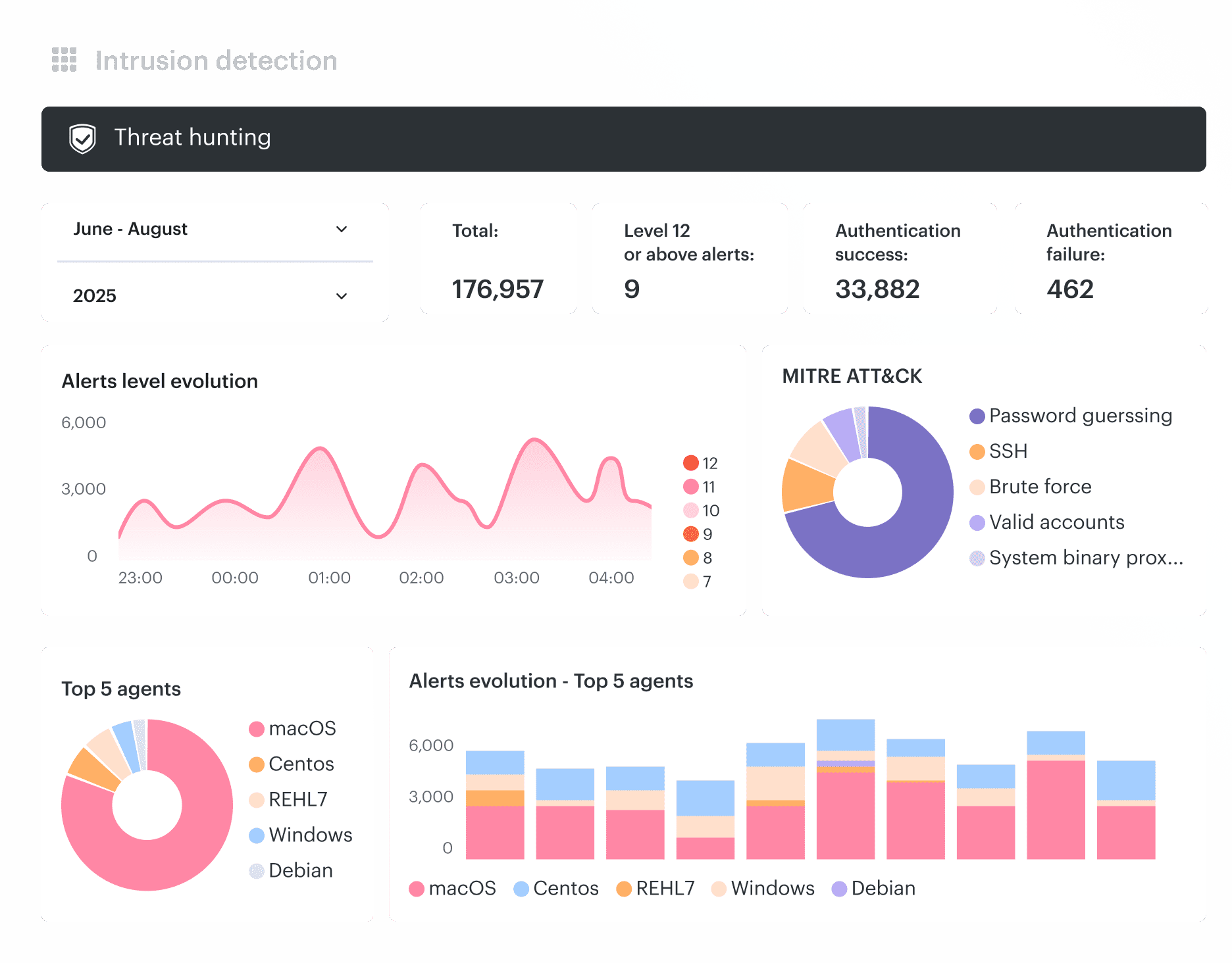
The average breach now costs USD 4.44 million. Software vulnerabilities now start 31% of breaches, overtaking stolen passwords as the top entry path. And the same cloud computing security threats keep coming back: misconfiguration, IAM gaps, insecure APIs, third-party risk, weak software supply-chain controls, limited visibility, and advanced persistent threats.
Boring? Maybe.
But boring is precisely why these threats land. They hide inside normal cloud operations until one exception, one stale identity, or one unmonitored workload becomes an open path to customer data.
- So what is the first thing that actually breaks in AWS, Azure, GCP, Kubernetes, and hybrid environments?
- Which detection signals do teams miss while every tool says it is “monitoring”?
- Where does visibility collapse between cloud and on-prem?
- How do mature security teams turn scattered findings into defensible action before the ticket queue becomes a graveyard?
That is what this guide covers.
Key insights on cloud security threats in 2026
- The biggest cloud security threats in 2026 still look painfully ordinary. A stale access key. A public bucket. A security group opened for a “temporary” test. More than 80% of cloud breaches in the draft trace back to compromised credentials or misconfiguration, not zero-day cinematic attacks.
- Start with the boring six before chasing the shiny stuff. Misconfiguration, IAM failure, insecure APIs, data loss, insider activity, and supply-chain compromise keep showing up in CSA, Verizon, IBM, and Mandiant-style threat research.
- Hybrid cloud does not create a new threat universe. It creates blind spots between teams. The same identity, API, data, and configuration risks stretch across AWS, Azure, GCP, Kubernetes, VMware, and on-prem. The real danger is the seam where one team thinks another team owns the asset.
- Cloud computing security threats move through legitimate access paths. Data exfiltration often happens through signed URLs, S3 replication, partner egress, CI/CD service roles, or an identity that technically has permission. Encryption at rest does not save you when the attacker is using approved access.
- Detection is not a telemetry problem anymore. It is a correlation problem. The clues are already held in CloudTrail, Azure Activity Logs, GCP Audit Logs, VPC Flow Logs, scanner findings, and host events. The gap is connecting those clues to the same asset, owner, environment, exposure, and business consequence before 277 days quietly pass.
- CVSS-only prioritization will bury the team in the wrong work. A Critical CVE on an internal workload may matter less than a Medium vulnerability on an internet-facing service that touches regulated data. Security teams need CVE-to-exposure-to-owner correlation, not another flat export from a scanner.
- The defensible response starts with one asset graph. Every workload, identity, API, data store, finding, policy breach, log event, and exception needs the same source of truth underneath it. Once that exists, CSPM, vulnerability management, SIEM, IDS, compliance, and ticketing stop acting like separate consoles and start telling one story.
What are cloud security threats?
A cloud security threat is any event, actor, or condition that could compromise the confidentiality, integrity, or availability of something running in your cloud. That's the textbook line. The reason it matters more than the textbook makes it sound is that cloud threats don't behave like the on-prem ones most senior security people have experience with.
Two structural reasons for that:
- Shared responsibility model. AWS, Azure, and Google handle the floor. Everything inside your tenancy is yours. Most of the breaches that make the news aren't because something broke inside the hyperscaler. They happen because something in the customer's IAM, configuration, or workload was just sitting there, waiting to be found.
- The control plane. In a data center, you needed network access plus a credential to do anything administrative. In the cloud, the control plane is an API endpoint reachable from anywhere on the internet. A misconfigured S3 bucket and a leaked access key are one HTTP request away from a customer-data exfiltration event. That collapses the time between "small mistake" and "incident in the news" from weeks to seconds.
While we're here, let's make a quick distinction that comes up in every audit conversation.
Threat vs. vulnerability vs. risk
Three terms get conflated in every audit conversation, and they refer to three different things.
- Threat is — the WHO or WHAT. The adversary, the event, and the condition that could cause harm. A phisher holding stolen credentials. A bot is scanning the internet for open S3. A nation-state crew targeting your control plane. Threats exist whether your environment is vulnerable to them or not.
- Vulnerability is — the HOW. The specific weakness that a threat exploits. An unpatched CVE on a public-facing workload. An IAM role with
*actions. An admin endpoint is exposed to0.0.0.0/0. Vulnerabilities are what you patch, configure, or harden away. See our Cloud Security Vulnerabilities deep dive for the operational layer. - Risk is — the SO WHAT. The math. Likelihood (threat × vulnerability) multiplied by Impact (what it would actually cost you if it lands). A Critical CVE on an internal-only test workload sits lower on the priority list than a Medium CVE on an internet-facing service holding regulated data.

A phisher (the threat) lands a compromised admin credential (the vulnerability) on a production account holding PII (the impact), and that combination is what makes the risk high. The rest of this article focuses on the first term.
6 common cloud security threats: the CSA top threats framework

The Cloud Security Alliance has been publishing a Top Threats report since 2010, and the most recent revision (Pandemic 11, with 2024 updates) names a tight set of categories that have stayed remarkably stable.
Here they are, in roughly the order most security teams need to care about them:
- Misconfiguration and inadequate change control
- Identity and access management failures
- Insecure APIs and interfaces
- Data exfiltration and loss
- Insider activity and account hijacking
- Advanced persistent threats and supply-chain compromises
What follows is what each one actually looks like in production environments, what makes it land, and what the teams catching it early do differently.
1. Misconfiguration and inadequate change control
Misconfiguration tops every credible 2024 dataset. Not because security teams are careless. Configuration drift accumulates faster than humans can audit it.
Here's how this scenario plays out in real environments: An engineer ships a Terraform module at 11 pm to unblock a release. Two days later, somebody patches a security group inline to debug a connectivity problem. The patch never makes it back into IaC. A week after that, a third teammate who wasn't on the original thread opens the same security group wider to test an integration.
Now you've got a port reachable from the public internet. None of the original three remember that, and your security team has no way to know without crawling every account manually.
Scanners on the internet find these within minutes. We've watched it happen with new customers during onboarding. Fresh buckets get probed within seconds of being created. Open ports get discovered before the next standup.
The defensive move is continuous configuration assessment against a known baseline. The frameworks most enterprises care about are CIS Benchmarks for AWS, Azure, GCP, and Oracle, plus NIST CSF, PCI DSS, HIPAA, and ISO 27001 mappings.
Continuous CSPM runs those evaluations on a schedule you control and routes the failures to the team that owns the asset. Drift stops being a six-month problem and starts being a six-hour one.
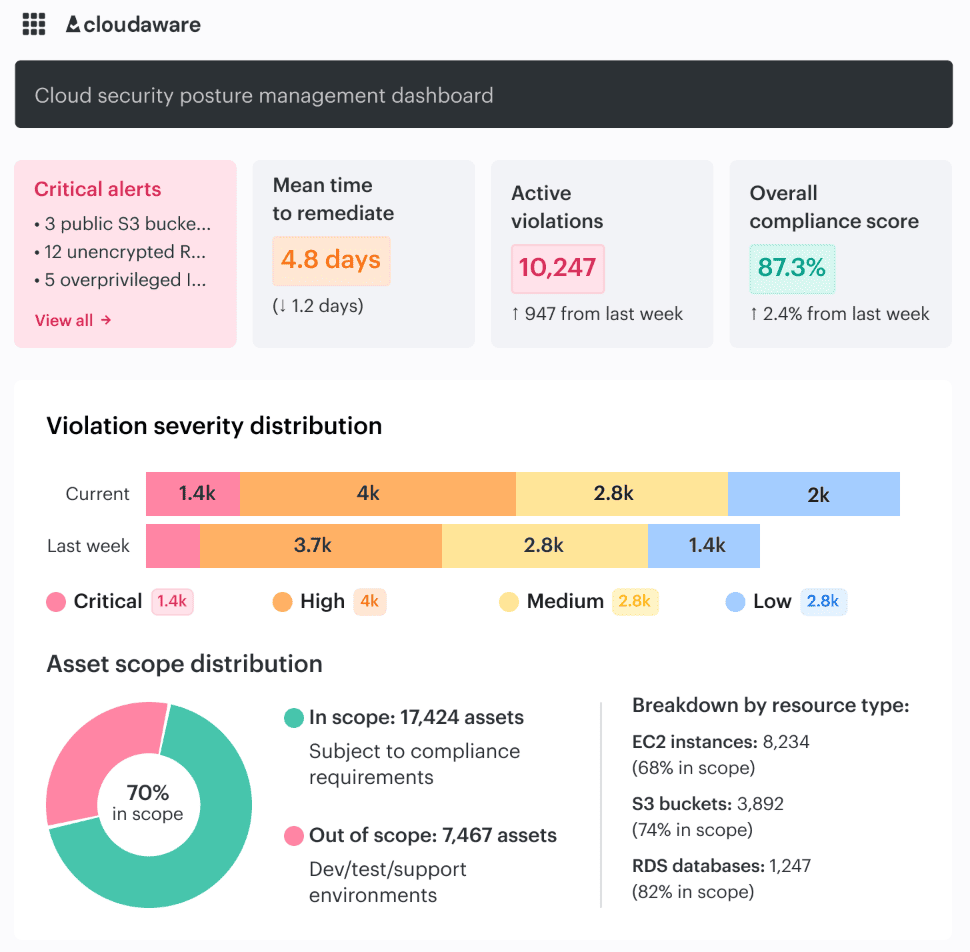
CSPM report element in Cloudaware. Schedule a demo to see it live.
What works in practice:
- Scope policies by environment, not by account.
- Prod runs against the strictest CIS baseline. Dev gets a looser one.
- Boundary badges on resources tell developers which cloud security controls apply before they ship, so the conversation happens in PR review instead of in a postmortem.
- Every failed check gets pushed into Jira or ServiceNow with the application owner pre-filled, so it can't sit in a queue waiting for triage.
- The ticket closes bidirectionally when the fix lands, which means the security dashboard stays in lockstep with the actual state of the environment instead of slowly drifting from it.
Read also: How to Perform a Cloud Security Risk Assessment in 2026
2. Identity and access management failures
If misconfiguration is the most common threat, IAM is the most damaging. Verizon's 2024 DBIR puts stolen credentials at the top of initial access vectors across every breach category, and the share is higher in cloud incidents than in traditional ones.
Four patterns show up over and over in enterprise environments:
- Long-lived access keys are everywhere. The 90-day rotation policy on the wiki and the actual keys in production rarely match. Most teams discover, in their first inventory pass, keys older than 18 months tied to workloads nobody currently owns.
- MFA coverage is the second pattern. Console logins are usually protected. Programmatic access is where attackers actually operate, and that's protected by a static key, not by a factor. If your incident-response runbook assumes MFA blocks the worst outcomes, it doesn't.
- Privilege escalation paths come third. The classic trap is a low-privilege role with permission to modify its own cloud security policy, attach a broader managed policy, or assume a more powerful role downstream. Static reviews miss these. What matters is the graph of "what could this identity become," not the snapshot of what it is right now.
- Identity sprawl from third parties. OIDC federations, SaaS integrations, CI/CD service accounts. Each one adds a trust path into your cloud, and very few teams audit them after the original onboarding.
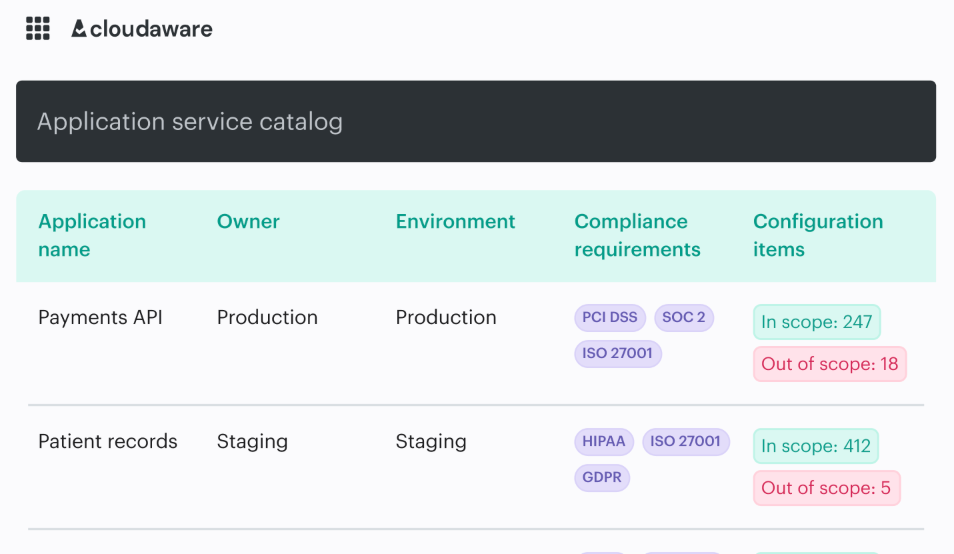
Application service catalog report element in Cloudaware. Schedule a demo to see it live.
Cloud Infrastructure Entitlement Management (CIEM) is the category that emerged to address this. The honest take is that CIEM only pays off when it sits on top of a complete asset graph, because identity context is meaningless unless you can see every resource the identity touches. Otherwise, you're only seeing part of it.
3. Insecure APIs and interfaces
The cloud control plane is an API. Your services are APIs. Anything you call internally is, usually, an API. So when we talk about insecure interfaces as a top cloud security threat, we're talking about the thing that connects almost everything you run.
Four classic failure modes:
- Unauthenticated or weakly authenticated endpoints that are reachable from the public internet. The classic AWS S3 with object-level ACLs that turned out not to mean what someone assumed. The Azure storage account was exposed for a one-time data share that never got revoked.
- Broken object-level authorization. The application checks that you're logged in, then doesn't check that the object ID you're requesting actually is yours. OWASP ranks BOLA as the number one API vulnerability for a reason. It's incredibly common and incredibly damaging.
- Server-side request forgery against instance metadata endpoints. The IMDSv1 problem on AWS, with equivalents in every other cloud. If an attacker can convince a workload to hit its metadata endpoint and return the response, they walk away with that workload's credentials.
- Shadow APIs. A developer publishes a service for an internal demo, never registers it, and three months later you discover it through an external pentest because someone outside the company found it first.
The detection move is continuous discovery against your actual environment, not against last quarter's architecture diagram. Pair that with the OWASP API Top 10 as the baseline checklist, and fold web application testing into CI so that obvious authentication and authorization failures are caught before deployment, not after.
Read also: Cloud Security Automation: Framework, Tools & Best Practices
4. Cloud data exfiltration and loss security threats
Security threats to cloud data come in three patterns, and they almost always exploit something legitimate rather than something broken.
1️⃣ The first one looks like this: an attacker reaches a privileged identity, enumerates the data stores that identity can access, and moves data out through channels you authorized:
- Signed URLs
- S3 replication
- SFTP egress route that exists for a partner integration
Encryption at rest is useless against this attack because the attacker holds keys.
2️⃣ In the second pattern, the entry point is rarely the database itself. It's a low-value workload (a marketing landing page, a build agent) that happens to have read-only IAM access to an S3 prefix it shouldn't reach. The attacker pivots from a low-sensitivity foothold to a high-sensitivity target without ever touching the production database directly.
3️⃣ Then there's the insider variant. Sometimes malicious. More often careless. The engineer who pulls a copy of a production table to "test locally" and forgets it on a laptop that gets stolen six weeks later.
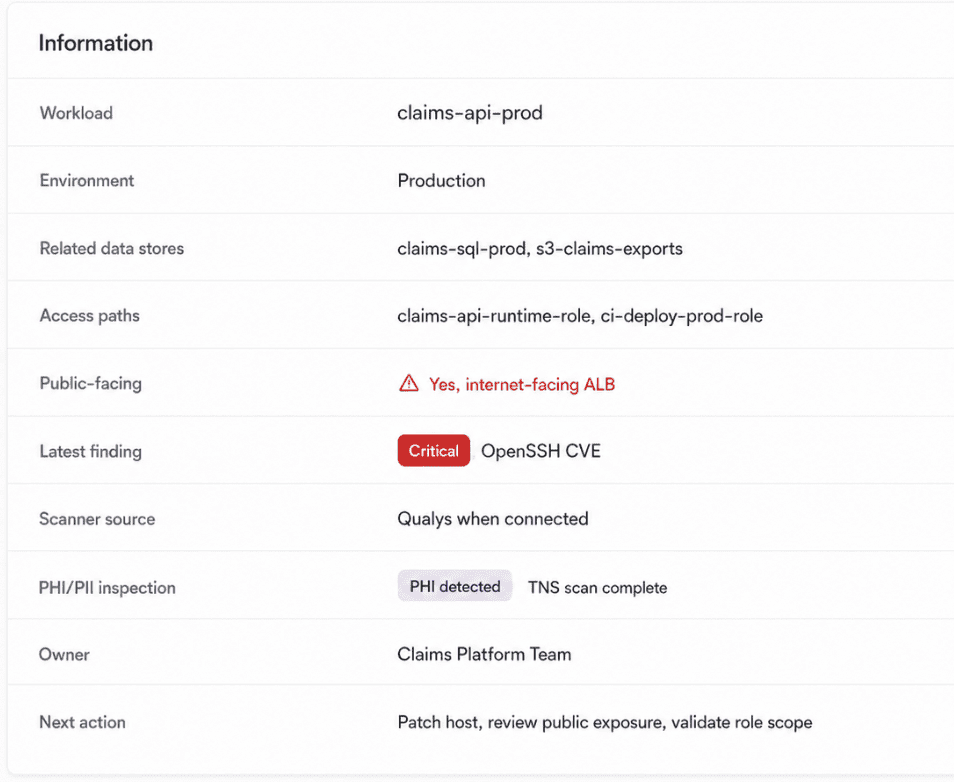
This is an element of the CI report in Cloudaware. Schedule a demo to see it live.
Real-world defense looks like a combination of things working together:
- Data content inspection runs against data stores so you actually know which buckets and tables hold PHI or PII, instead of inferring from naming conventions.
- Network egress monitoring through VPC Flow Logs catches movement to unfamiliar destinations.
- File integrity monitoring on workloads near sensitive data picks up the read patterns of an attacker enumerating before they move.
- And a vulnerability scan that updates every fifteen minutes matters here, because the workload an attacker walks in through is probably one that picked up a critical CVE between yesterday's scan and right now.
Read also: Healthcare Data Security: Full 2026 Guide
5. Insider threats and account hijacking
Two phenomena collapse into one in cloud telemetry. That's what makes them so hard to catch.
A genuine insider, whether malicious or just sloppy, looks like an authorized user doing authorized things. So does an external attacker who hijacked that user's session through a phishing email, an MFA push-bombing attack, or a session token lifted out of a developer's laptop.
From the cloud's perspective, the requests use the right credential to sign them and hit endpoints that the credential is allowed to access. The control plane has no opinion about who's actually behind the keyboard.
Patterns worth watching for.
- Impossible-travel logins. Amsterdam at 9:00 am and Tokyo at 9:07 am.
- Brand-new role chains. A user assumes a role they've never assumed before.
- Sudden privilege elevation. Permissions widen, then there's unusual activity in a different account.
- MFA challenge anomalies. Failures bunched together, followed by a success.
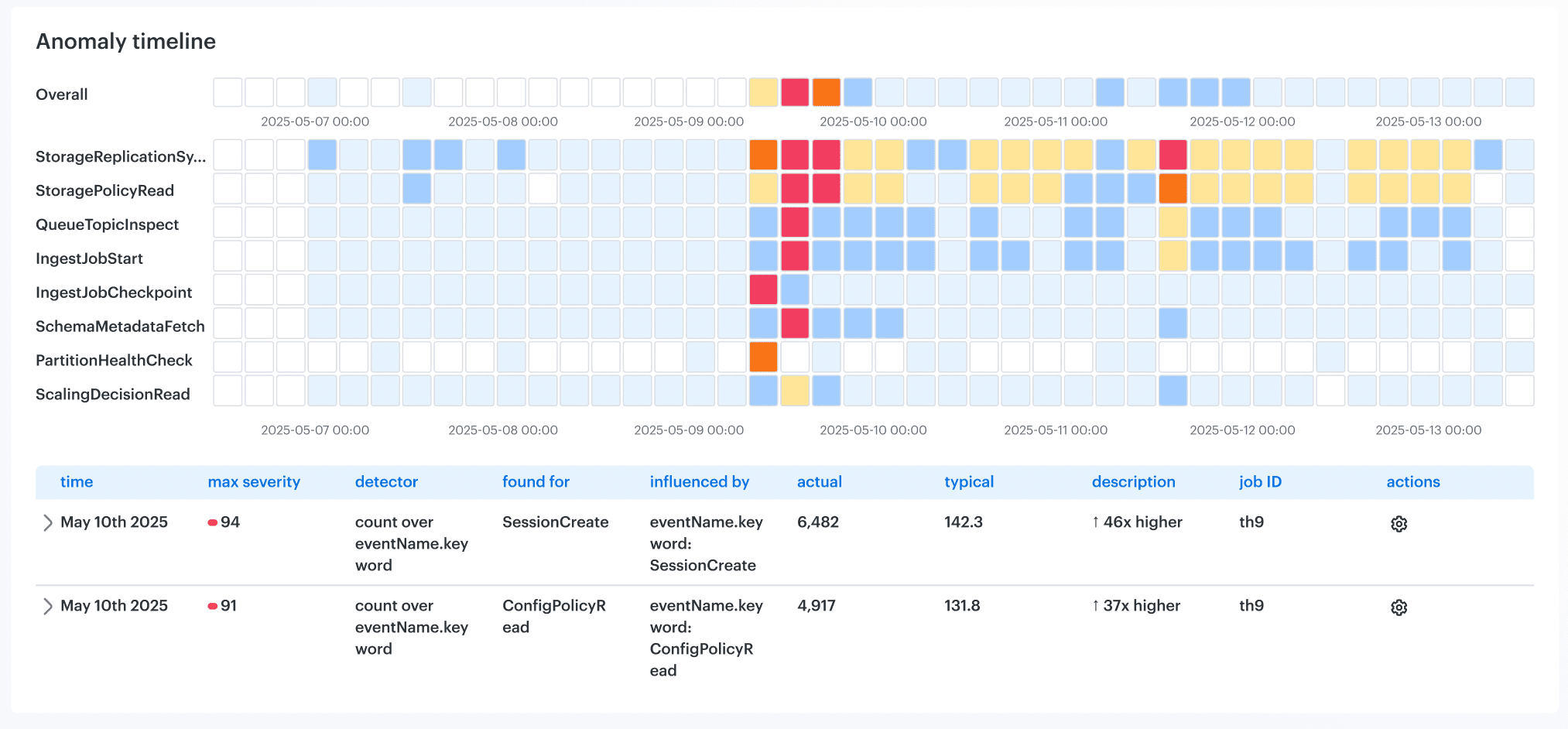
This is an element of the anomaly timeline report in Cloudaware. Schedule a demo to see it live
The security teams that catch these early are the ones that enrich every log event with context at ingestion. Owner. Application. Environment. So the moment "user X assumed role Y" lands in the SIEM, no one has to pause and look up whether user X is supposed to be doing that. The event already says so.
Read also: Cloud Data Security Challenges: 10 Issues & Fixes
6. Advanced persistent threats and supply-chain attacks
Among all cyber security threats in cloud computing, this category gets the smallest share of operational attention relative to its impact. Because it's rare. When it lands, it's catastrophic.
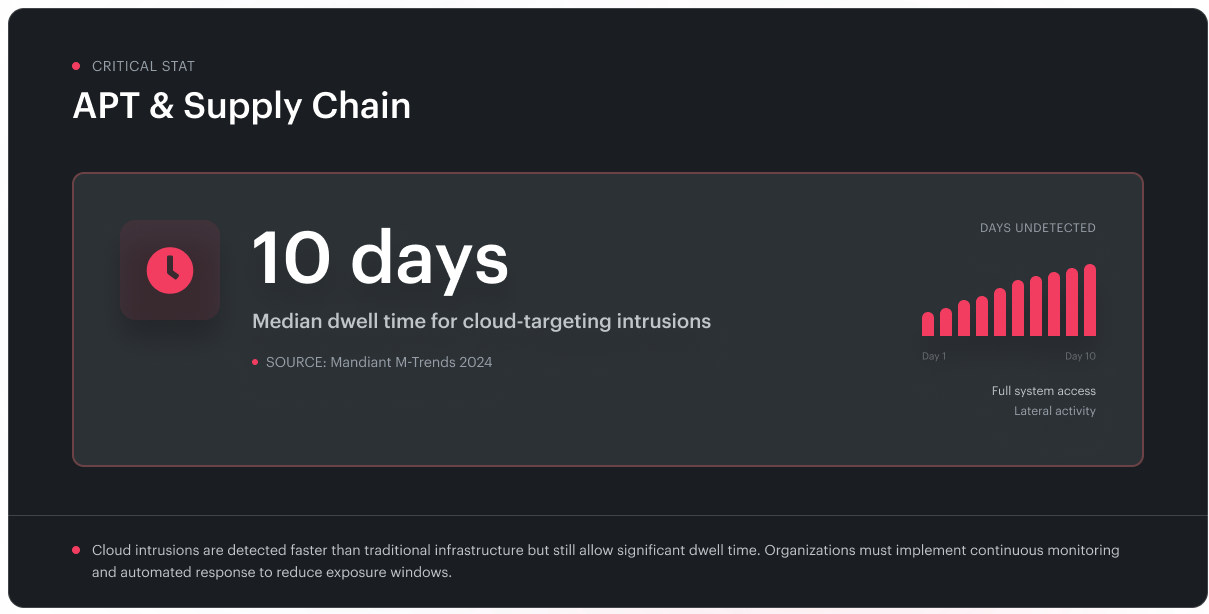
Nation-state actors increasingly target the cloud control plane directly. The math is on their side: compromise one admin identity in one tenant, and you've replaced a campaign that would have needed thousands of endpoint footholds.
Supply-chain attacks are a close relative:
- A compromised npm package. A maintainer's account gets compromised and pushes a backdoored release.
- A backdoored Docker base image. Every workload downstream inherits the implant.
- A trusted third party. A SaaS integration with broad scopes into your tenancy, where the vendor gets breached.
- The CI/CD pipeline. A build agent with IAM roles attached that pushes code into production every fifteen minutes.
Defensive posture for this category is different from the others. APTs and supply-chain attacks don't usually look like a single anomalous event. They look like patient, legitimate-seeming activity over time. So detection needs retention, correlation across long time windows, and the ability to look back and ask, "Did anything happen on this resource in the last 90 days that looks suspicious now?"
That means log retention isn't optional. The current month plus the previous two kept hot for fast searching are the realistic minimum. Older data auto-archived to cheaper storage, with the ability to pull it back when an investigation calls for it.
Container image scanning, dependency analysis against OWASP-grade lists, and SBOM inventory feeding the same asset graph as your runtime workloads. The MITRE ATT&CK Cloud Matrix is the working reference for what to detect.
Hybrid cloud security threats where the risk surface compounds
Hybrid cloud security threats are not a new species of threat. They are the same IAM, logging, configuration, vulnerability, and data-access problems, stretched across environments that were never designed to be investigated together.
Identity is where the blast radius gets ugly
Most enterprise hybrid setups connect an on-premise identity provider, often Active Directory, into a cloud IdP. That trust path is normal on Monday morning. It is also the path an attacker wants after compromising a domain admin account, service account, or federation rule.
The failure mode is rarely dramatic. An admin logs into an on-prem VM. A few minutes later, a role is assumed in AWS. Then a privileged command runs on an Azure VM. Each event may look explainable in its own console, but together they tell a different story.
Where hybrid visibility breaks
This is where hybrid visibility usually falls apart. The on-prem team watches Syslog and Beats. The cloud team watches CloudTrail, Azure Activity Logs, and GCP Audit Logs. Kubernetes events sit somewhere else.
Asset ownership may live in:
- a CMDB
- a spreadsheet
- a tag policy
- somebody’s memory
By the time an analyst connects the chain, the investigation has already turned into a three-tool, three-ticket, three-team scavenger hunt.
A better operating pattern
A better operating pattern is simpler: one inventory view for every host and workload, with owner, environment, source, and last-seen timestamp attached from the start.
Then layer privileged identity activity over that same asset list. Now the analyst is not looking at isolated events across separate consoles. They can see the relationship between the identity, the asset, the environment, and the team responsible for fixing it.
In a Cloudaware, that looks like on-prem VMs, AWS EC2, Azure VMs, GCP Compute, and Kubernetes workloads side by side. An analyst filters by owner or environment, sees which source reported the asset, and follows the identity ribbon across systems: admin login on dc-vm-021, role assumed on claims-api-prod, privileged command on billing-worker-7.
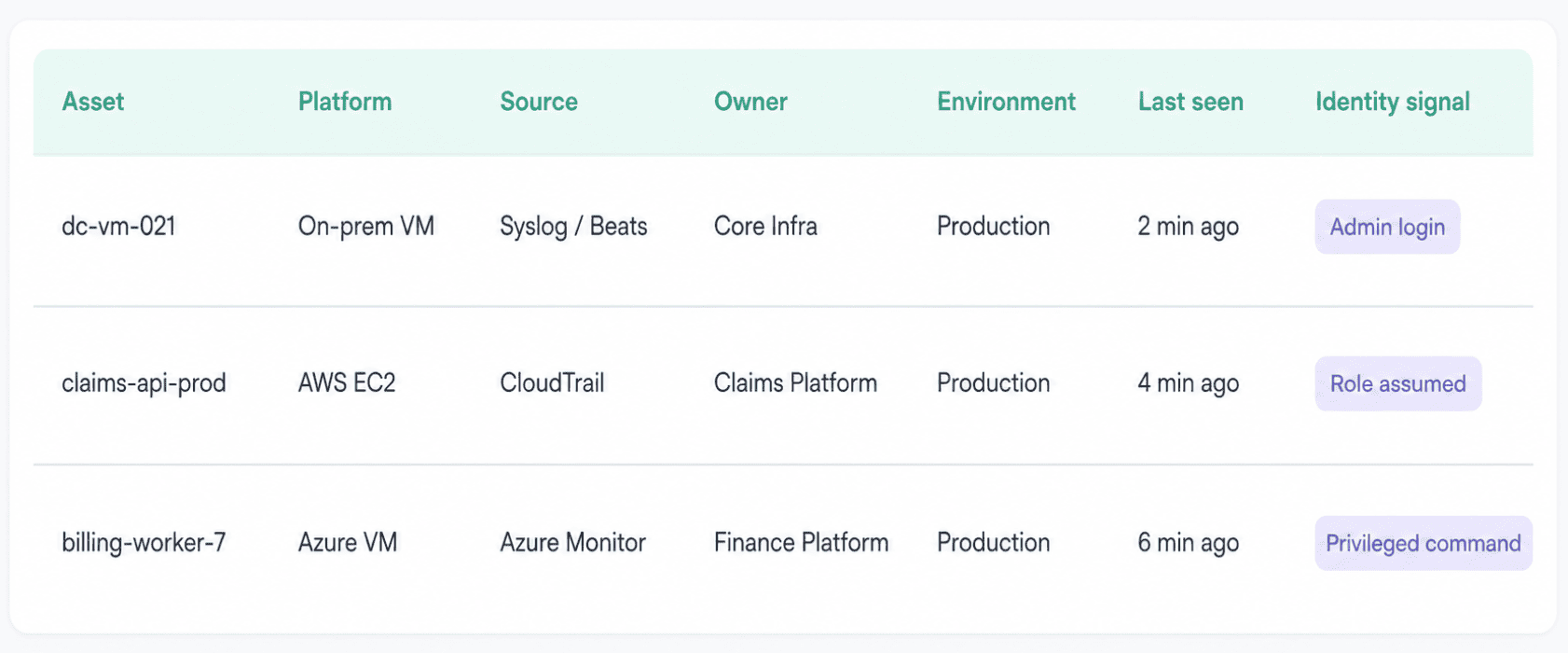
This is an element of the cloud security report in Cloudaware. Schedule a demo to see it live.
That is the practical defense. Not “more visibility” as a slogan. A timeline where the cross-environment chain is visible before everyone starts arguing about which team owns the first clue.
For the architecture side of this conversation, including segmentation, identity boundaries, and control placement, see our Hybrid Cloud Security Architecture guide.
Read also: What Are Cloud Security Services? Types, Use Cases, and How to Choose
Detecting cloud security threats before they become breaches
Detecting cloud security threats in 2026 is not about collecting more alerts.
Most teams already have the raw signals. CloudTrail knows who assumed the role. Azure Activity Logs show the privileged action. GCP Audit Logs capture service-account use. VPC Flow Logs show egress. The vulnerability scanner has the CVE. The host agent sees the file change.
The breach window opens when those signals stay separate.
A practical detection model needs five layers stitched to the same asset, owner, environment, and ticket path.
1. Configuration drift signals
Configuration drift usually fires early. A security group opens to 0.0.0.0/0. Logging gets disabled on a production bucket. An IAM policy changes from a narrow inline rule to a broader managed policy. A Kubernetes workload starts running with a privilege pattern that does not match the baseline.
One change may be routine.
Three changes on the same workload within 20 minutes is not routine.
This is where continuous CSPM checks matter most: not as a monthly posture score, but as a drift detector. The useful alert is not “policy failed.” It is “this production asset just moved away from its approved state, and here is the owner, environment, and related change.”
2. Identity behavior signals
Identity is where cloud investigations get real. Watch for new role chains, unusual service-account activity, MFA failures clustered in time, privilege changes near deployment windows, and admin actions from a user or workload that does not normally touch that environment.
The key detail is context at ingestion.
When user_x assumes claims-prod-admin-role, the analyst should not have to open three tabs to answer basic questions:
| Question | Why it matters |
|---|---|
| Is this role tied to production? | Changes triage priority immediately. |
| Which app owns the asset? | Decides who gets paged or ticketed. |
| Is the asset internet-facing? | Changes blast-radius thinking. |
| Was there recent configuration drift? | Shows whether this is part of a chain. |
| Is there an open vulnerability on the same asset? | Turns a weak signal into a stronger one. |
In a Cloudaware-style SIEM view, those answers sit on the event because the log is enriched from the CMDB:

3. Network telemetry
Network telemetry answers a different question: where did the workload talk after the identity or configuration change? For cloud teams, that usually means VPC Flow Logs, DNS query logs, ELB access logs, firewall logs, and cloud-native network signals.
Look for patterns practitioners actually investigate:
- Unusual egress to a new ASN or region;
- DNS queries with high entropy or strange volume;
- Lateral movement across peered VPCs or connected VNets;
- Traffic from a workload that normally stays internal;
- Access from a test environment to production services.
None of this activity is exotic. The problem is that network logs often live far away from IAM logs and CSPM findings.
Detection gets sharper when the same asset record shows a role assumed, a security group widened, a new egress pattern, and a vulnerable package present.
4. CVE-to-exposure correlation
This is where many vulnerability programs waste the most time. A Critical CVE on an internal-only workload behind strong segmentation may be less urgent than a Medium CVE on an internet-facing API that touches regulated data. The scanner cannot make that call by itself.
The decision needs more than CVSS. It needs:

A good dashboard does not ask the analyst to stitch the information together manually. It shows the CVE next to exposure, data sensitivity, identity path, and owner. That is the difference between “we have 4,000 findings” and “these 12 need action today.”
5. Host and workload signals
Cloud-control-plane logs do not see everything. Host-layer and workload telemetry catch what happens after access lands on the machine or container.
- File integrity monitoring can flag a production binary changed by the wrong process.
- Log inspection can catch privilege escalation, suspicious service changes, rootkit indicators, and authentication abuse.
- Container monitoring can surface privileged containers, shell sessions, risky mounts, and abnormal process behavior.
For network-level inspection, signature and protocol analysis, such as Snort-based detection, can add another layer where teams need deeper packet or traffic pattern visibility.
This layer matters because attackers do not stay in the control plane. They move into workloads.
What the operating model looks like
The detection model only works if alerts become owned and work fast.
In mature cloud teams, the flow looks like this:
- Signal lands from SIEM, CSPM, vulnerability scanning, IDS, or host monitoring.
- The event is enriched with CMDB context: owner, app, environment, account, region, asset criticality.
- Related signals on the same asset are grouped into one investigation view.
- The finding routes to Jira or ServiceNow with the right team already selected.
- Status syncs back when the fix lands, so the security team is not chasing screenshots.
That is the practical version of “faster detection.” Not more dashboards. Not more severity labels. A shorter path from signal to owner to fix.
Read also: Healthcare Data Security Challenges. The 4 Biggest Threats Facing Hospitals and Health Plans in 2026
Cloud security threats and solutions: how Cloudaware closes the gap
Most cloud security failures do not happen because the signal was missing.
The misconfigured bucket existed. The orphaned role existed. The exposed workload had a scanner finding. The suspicious login was already in the logs. The problem was simpler and uglier: nobody connected the signal to the asset, owner, environment, and blast radius fast enough.
That is the real gap between cloud security threats and solutions. Not “more cloud security tools.” A cleaner operating model.
Start with inventory security teams can actually use
A useful inventory is not a spreadsheet with cloud IDs.
It shows AWS, Azure, GCP, Kubernetes, VMware, and on-prem assets in one place, with owner, app, environment, region, tags, and relationships attached. When a new production resource appears, the question should not be “who owns this?” The owner should already be on the record.
Run posture checks against that inventory
Posture management gets useful when policies understand scope.
Prod and dev should not be treated the same. Public-facing and internal-only assets should not be scored the same. Regulated workloads need different evidence than sandbox workloads.
In a Cloudaware-style CSPM workflow, failed controls become routed findings with owner, severity, SLA, evidence, and Jira or ServiceNow handoff. Exceptions are time-boxed, reviewed, and visible, so “temporary” does not become architecture.
Prioritize vulnerabilities by exposure, not scanner noise
CVSS is not enough. A Critical CVE on an internal workload may wait. A Medium CVE on an internet-facing API touching regulated data may need action today.
The practical view joins scanner findings with exposure, environment, IAM path, data sensitivity, and owner. Scanner source still matters, whether it is Nessus, Wiz, AWS Inspector, Tenable, Qualys, Snyk, or CrowdStrike when connected. It just stops being the only thing driving priority.
Correlate logs against the same asset graph
Logs get sharper when they inherit CMDB context. A CloudTrail event, Azure Activity Log, GCP Audit Log, VPC Flow Log, Syslog event, or Beats signal should arrive with owner, app, environment, account, and region already attached. Then a rule can ask a real security question:
“Did a production, PCI-in-scope resource get a console login from a new IP after a configuration drift event?”
That is the difference between log storage and detection.
The operating point
The stack works when every finding points to the same asset record. CSPM finds drift. The scanner finds the CVE. SIEM catches the identity event. IDS or host monitor sees workload-level behavior. The CMDB ties them together with owner, environment, exposure, and business context.
That is the part practitioners care about. Not another dashboard. A shorter path from signal to owner to fix.